- The paper demonstrates that both scaffolding mechanisms yield similar diagnostic accuracy despite distinct engagement patterns.
- It details a rigorous three-phase experimental paradigm using stateful LLM agents to alternate between structured data collection and open-ended hypothesis generation.
- Findings suggest that future adaptive, hybrid scaffolding strategies could better balance procedural reliability with deep conceptual reasoning.
Structuring versus Problematizing: How LLM-based Agents Scaffold Learning in Diagnostic Reasoning
Introduction
The proliferation of LLMs in pedagogical applications catalyzes a re-examination of cognitive scaffolding, especially in high-complexity domains such as diagnostic reasoning. The paper "Structuring versus Problematizing: How LLM-based Agents Scaffold Learning in Diagnostic Reasoning" (2604.09158) investigates the instantiation and comparative efficacy of two canonical forms of scaffolding—structuring and problematizing—operationalized within PharmaSim Switch, an LA- and LLM-augmented scenario-based simulation for pharmacy technician apprentices. The authors leverage a rigorously annotated discourse framework, fine-grained behavioral logging, and a three-phase experimental paradigm (learning, near-transfer, far-transfer) to dissect strategy adoption, transfer efficacy, and engagement typologies as functions of scaffolding granularity and style.
System Design and Implementation
PharmaSim Switch encapsulates a multi-agent, multi-module environment:
- Client Inquiry and Research Module: Implements stateful, rule-based client agents anchored to an expert-validated knowledge base for deterministic case progression and adherence tracking (LINDAFF checklist).
- Pedagogical Module: A GPT-4o-based LLM pharmacist agent, orchestrated as a state machine, distinguishes two control flows—data collection and data interpretation—regulated by Student Model Agents (Fig. 2). These agents dynamically gate the transition logic ensuring alignment with checklist completion and hypothesis generation.
- The LLM employs context-restricted prompting, segmenting conversation history (last five turns) and embedding scaffolding-specific system prompts to reliably elicit structuring or problematizing utterance types (Fig. 3).

Figure 1: The PharmaSim Switch interface, integrating the client inquiry/research and LLM-driven pedagogical module for conversational agents.

Figure 2: Backend architecture highlighting client (rule-based) and pharmacist (LLM) agent separation, coordinated by Student Model Agents.
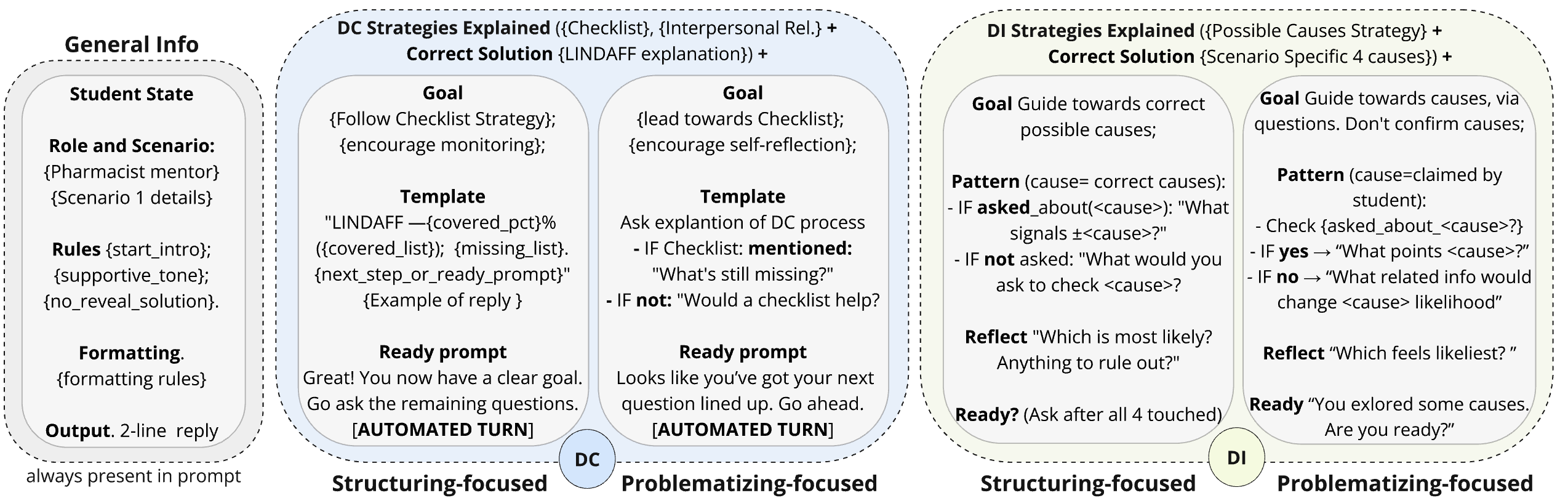
Figure 3: Scaffolding-specific prompt design sets for controlling the behavior of LLM pharmacist agents during data collection and interpretation.
The architecture allows interleaving of structured scenario-based querying and open-ended diagnostic conversations. The iterative student loop alternates between client probing, external resource consulting, and pharmacist consultation, simulating real-world clinical reasoning workflows.
Experimental Paradigm and Measurement
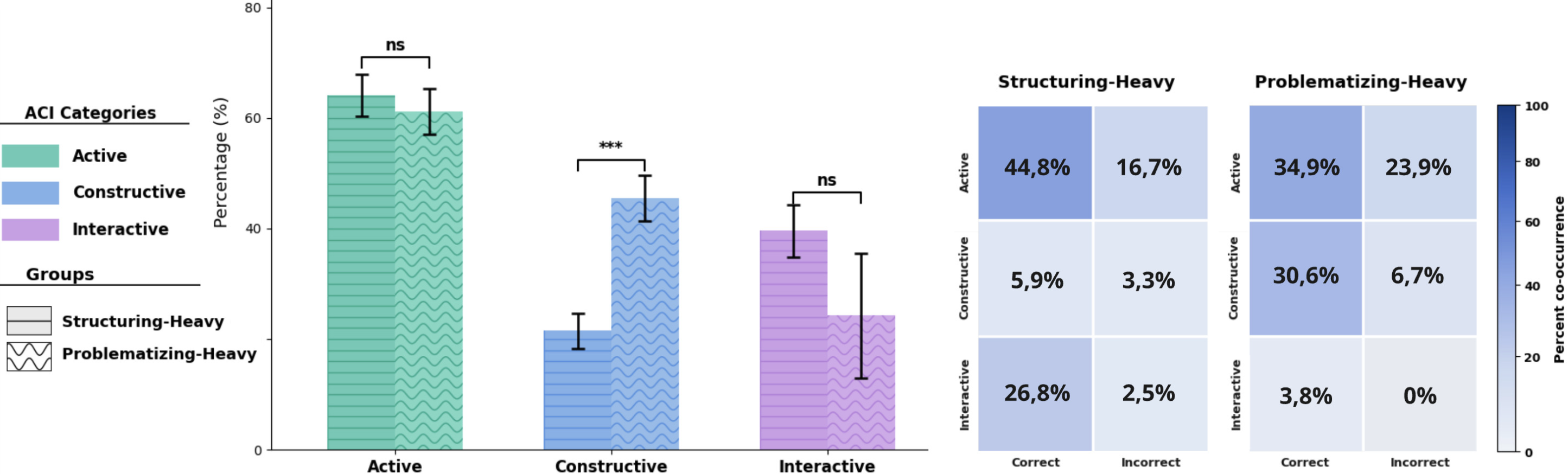
The study utilizes a randomized between-groups design (N=63), stratified by instructional condition (Structuring-heavy, Problematizing-heavy). Phase 1 consists of a learning scenario, Phases 2 and 3 implement near and far transfer scenarios, respectively. Critical variables include quantitative scenario-specific post-tests (identification, justification, and likelihood assessment of differential diagnoses), LA-derived behavioral logs, and discourse annotation using the ICAP (Active, Constructive, Interactive, Correct/Incorrect) and Reiser Scaffolding (Structuring, Problematizing, subcategories) schemes.
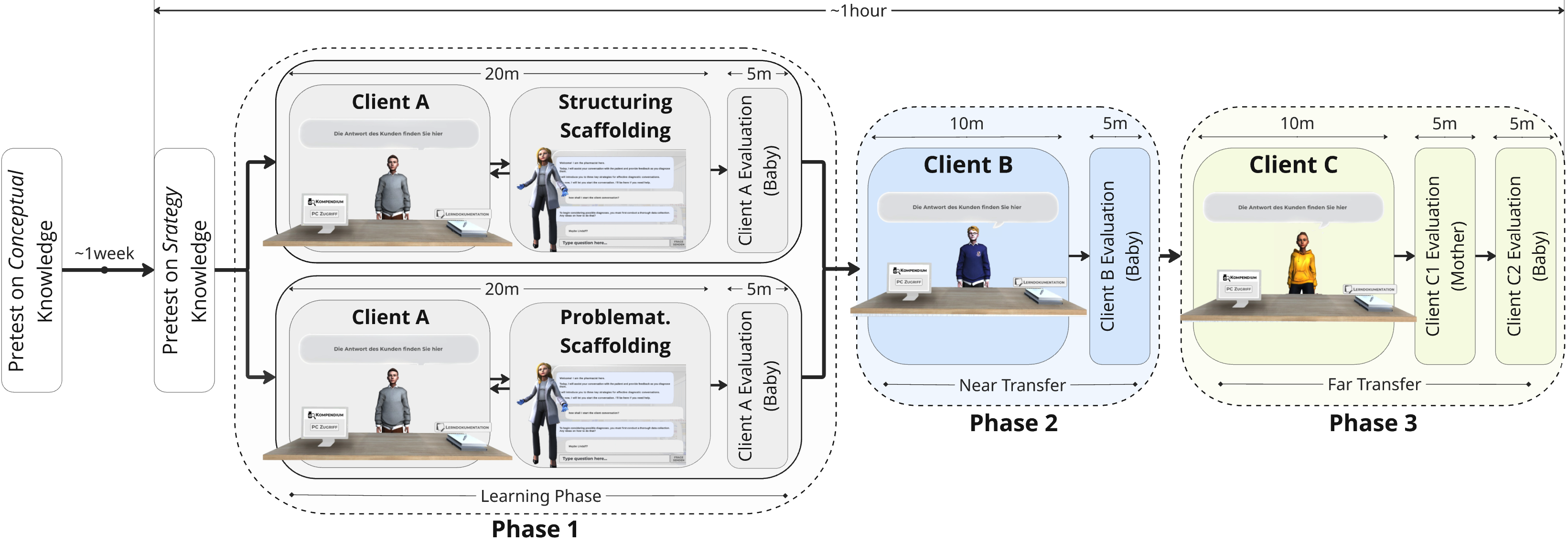
Figure 4: Experimental timeline: pretest, learning with structured/problematized scaffolding, then sequential transfer assessment (near, far).
Scaffolding Fidelity and LLM Agent Alignment
Empirical rubric-based annotation demonstrates high fidelity in agent behavior, with significant separation between conditions for both scaffolding mechanism (structuring in Structuring-heavy, problematizing in Problematizing-heavy; p<.001) and pedagogical discourse subcategory distributions (monitoring and focusing for structuring, articulation and decision elicitation for problematizing).
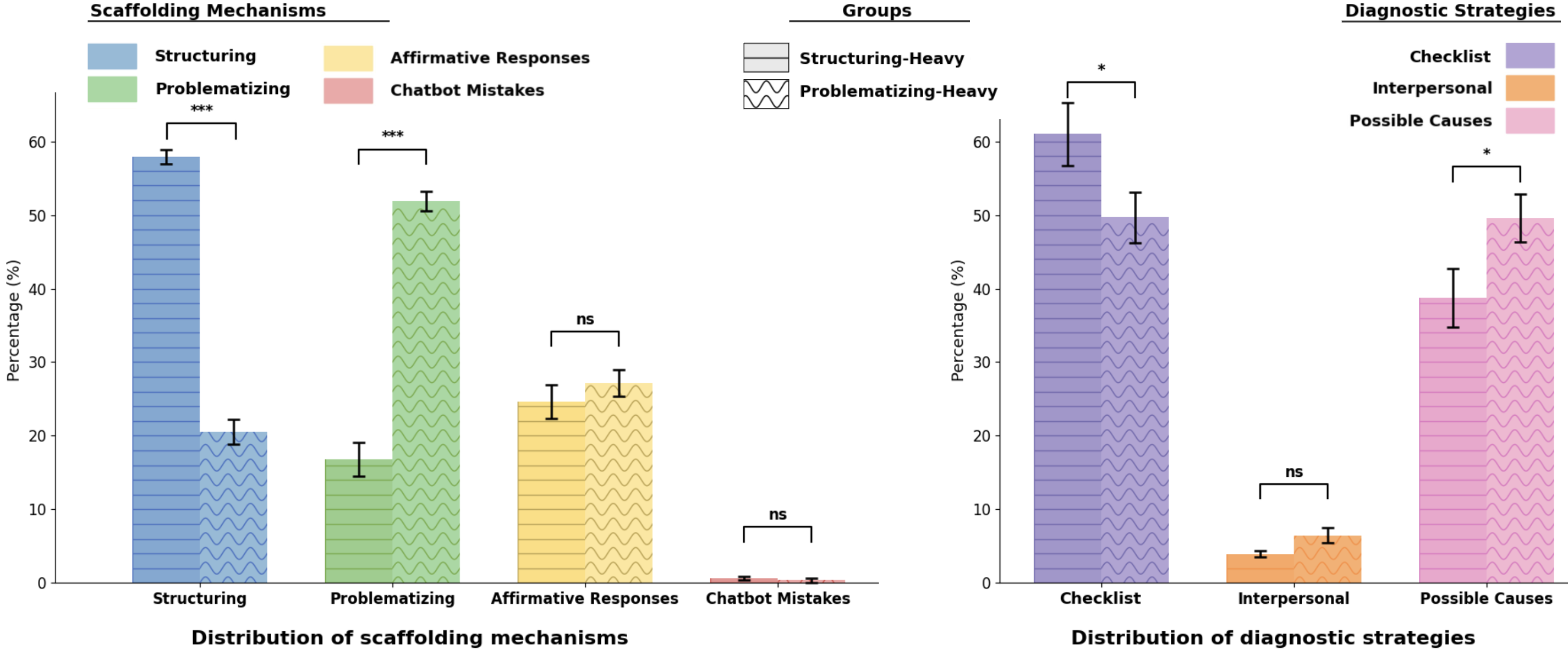
Figure 5: Distribution of scaffolding mechanisms and diagnostic strategies by group; significant divergence in structuring vs. problematizing moves is evidenced.
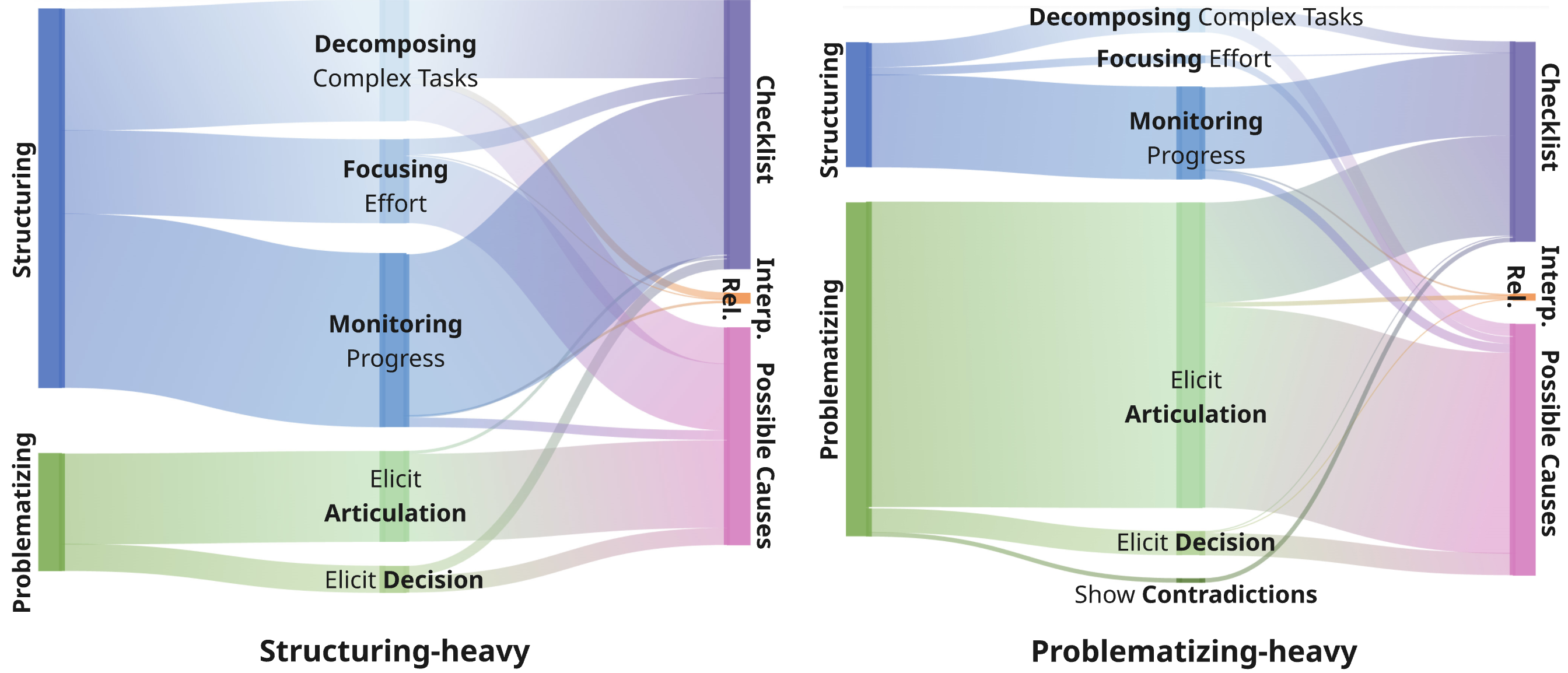
Figure 6: Flow mapping of scaffolding subcategories reveals monitoring/focusing as dominant structuring moves; articulation/decision-elicitation dominate problematizing.
Both agents demonstrate effective support for required diagnostic subskills (checklist, possible causes), though the Interpersonal Relationships strategy remains underrepresented by both agent conditions. Notably, while structuring supports procedural strategies via monitoring and decomposition, problematizing is predominantly mapped to generative hypothesis enumeration.
Contrary to conventional assumptions of differential efficacy, analysis via mixed linear models reveals no significant performance differential (accuracy in checklist, interpersonal, or hypothesis generation tasks) between scaffolding conditions across all phases (p>.05).
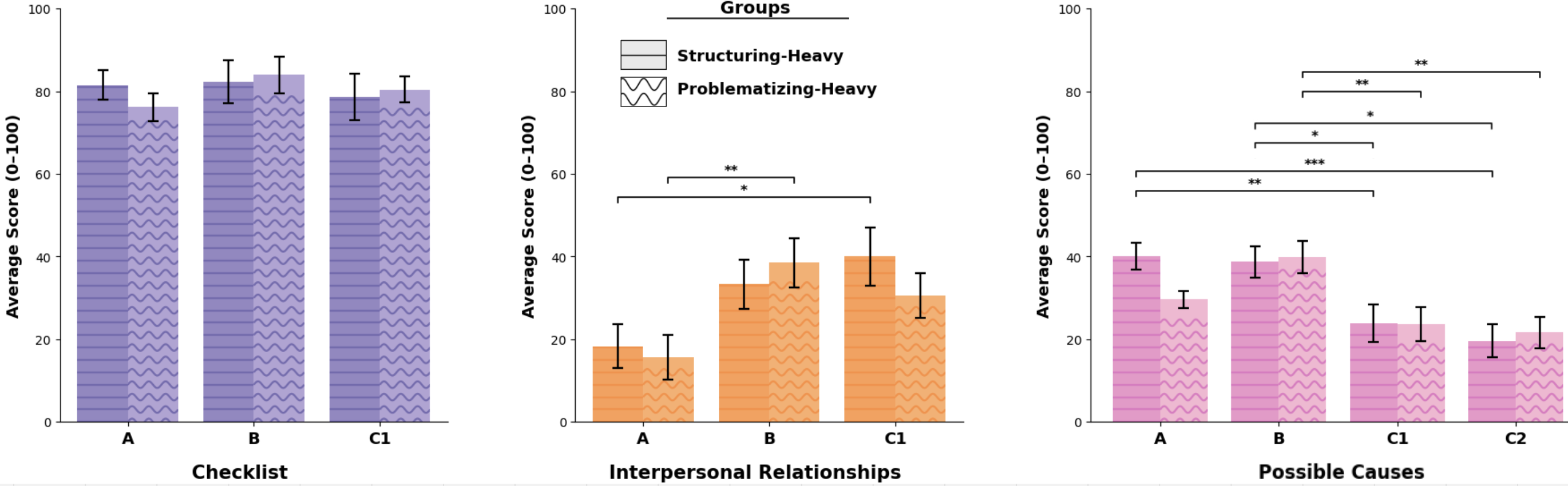
Figure 7: Diagnostic strategy performance per scenario/client, stratified by group; dominant effect is scenario complexity, not scaffold.
Performance is primarily scenario-complexity dependent, with significant degradation on far transfer cases, particularly for the possible causes strategy (structured: p<.001; problematized: p<.01). However, both scaffolding forms facilitate upward trajectory in strategy mastery across phases, as reflected by the robust performance in interpersonal relationship queries, with some group-specific nuances in strategy application durability.
Engagement Patterns: Behavioral Process Analytics
Surface-level interaction analytics underscore robust group differences:
Notably, both groups reach similar accuracy (structuring: 77.4%, problematizing: 74.8%). Problematizing scaffolding significantly raises constructive behavior (p<.001) but increases incorrect constructions, corroborating theories that productive struggle can transiently degrade accuracy while deepening procedural/conceptual engagement.
Implications and Future Directions
The evidence supports the feasibility of tightly controlled, theory-grounded pedagogical agent design using LLMs, with prompt engineering driving clear divergence in agent discourse style and process analytics confirming distinct engagement signatures. However, no superiority is observed for either scaffolding style in final diagnostic accuracy or near/far transfer, despite marked contrast in engagement type. The findings caution against naïve optimization for engagement at the expense of accuracy, instead motivating hybrid (dynamic or adaptive) scaffolding regimes that balance procedural reliability (structuring) with productive struggle (problematizing).
For future research, two axes are critical: (1) domain-general replication across other complex diagnostic domains (e.g., clinical medicine, engineering troubleshooting); (2) real-time adaptive scaffolding blending based on behavioral telemetry, with longitudinal retention/transfer outcome monitoring.
The results also signal that LLM generative variance can attenuate precise strategy modeling (under-addressed interpersonal reasoning). Therefore, more nuanced orchestration (meta-prompts, fine-tuned reward modeling) may be required for alignment in high-stakes educational applications.
Conclusion
PharmaSim Switch demonstrates that LA- and LLM-powered agents can robustly operationalize theoretically distinct scaffolding mechanisms. Structuring and problematizing scaffolds drive measurably distinct engagement behavior and process analytics, but neither exhibits superiority in short-term diagnostic performance or transfer in realistic vocational training settings. This mandates an expanded research agenda focusing on adaptive, hybrid scaffolding and holistic, longitudinal skill transfer assessment to realize the full potential of LLMs in diagnostic education (2604.09158).