- The paper introduces AVPF, a self-supervised framework that creates pseudo-fake samples by deliberately engineering inter- and intra-modal inconsistencies from authentic videos.
- The paper employs Audio-Visual Self-Blending (AVSB) and Self-Splicing (AVSS) techniques to simulate realistic forgery artifacts without relying on annotated fake data.
- The paper achieves superior cross-dataset generalization with up to 6.7% AUC and 8.0% AP improvements, demonstrating robust detection even under heavy image degradations.
Generalizing Video DeepFake Detection by Self-generated Audio-Visual Pseudo-Fakes
Introduction and Motivation
This work introduces AVPF, a self-supervised paradigm for video deepfake detection targeting the persistent generalization failures observed in real-world audio-visual forgery detection systems. The central insight is that existing detection models are biased by the limited distribution of publicly available deepfake datasets and lack robustness to previously unseen manipulation patterns. Instead of depending on annotated fake videos, AVPF synthesizes "pseudo-fake" samples from authentic video content by deliberately engineering inter- and intra-modal audio-visual inconsistencies. This approach enables effective modeling of both cross-modal and intra-modal forgeries without explicit supervision from manipulated data, exposing the model to a far richer set of anomaly priors.
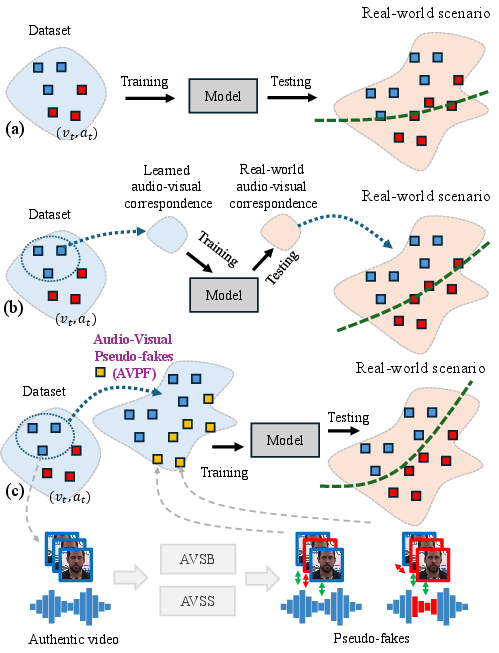
Figure 1: Schematic comparing training protocols: (a) standard real and fake supervision, (b) self-supervised learning with authentic data, and (c) AVPF with self-generated pseudo-fakes that match the complexity of diverse real-world manipulations.
Methodology Overview
Audio-Visual Self-Blending (AVSB)
AVSB targets inter-modality inconsistencies—cases where either audio or visual streams are manipulated independently, which are common in deepfake generation pipelines. The core process involves temporally shifting either the audio (converted to Mel-spectrograms) or the frame sequence and blending the shifted segment within a localized temporal window. Blending is adversarially subtle, constrained to the convex hull of detected face landmarks, with elastic deformation and smoothing functions deployed to produce visually plausible artifacts that correspond to actual forgeries observed in the wild.
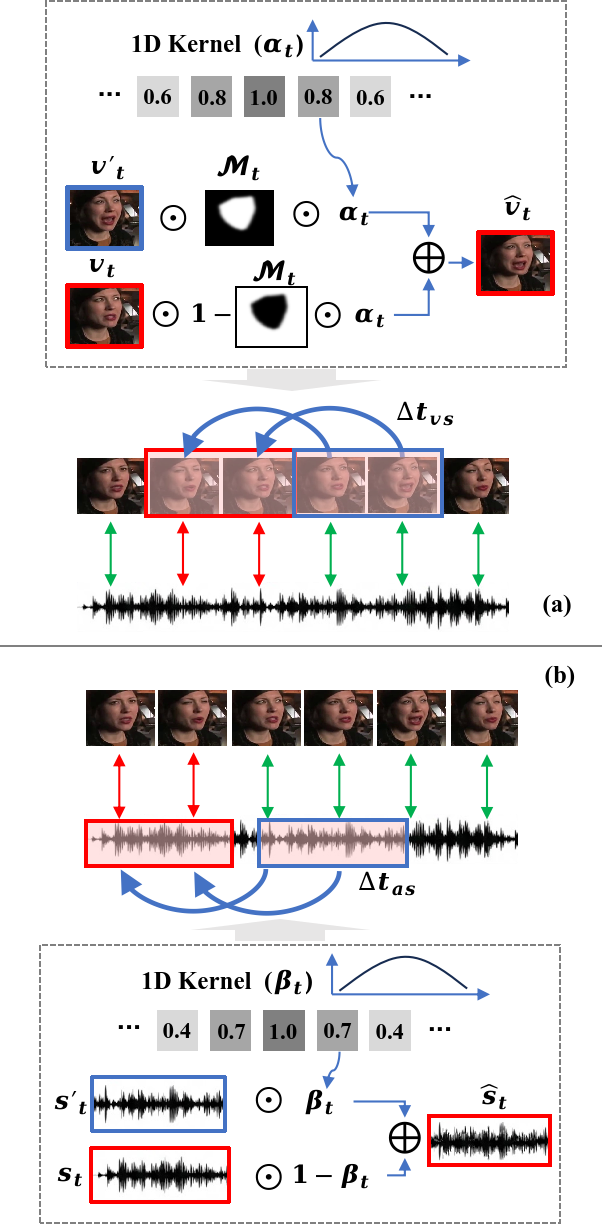
Figure 2: Audio-Visual Self-Blending (AVSB): (a) visual self-blending, (b) audio self-blending; local windowed manipulations yield cross-modal inconsistencies.
Audio-Visual Self-Splicing (AVSS)
To simulate intra-modality inconsistency—artifacts that even occur when forgeries are temporally synchronized yet still phonetically or visually implausible—AVSS splices short, perceptually similar video or audio fragments from elsewhere in the same clip into a targeted location. A similarity search based on mean absolute difference ensures the spliced segments are locally coherent, resulting in hard negative pseudo-fakes that introduce only nuanced, localized temporal anomalies.
Figure 3: Audio-Visual Self-Splicing (AVSS): snippet selection and local replacement aim at intra-modal perturbations mimicking temporally consistent but not semantically consistent manipulations.
Empirical Validation
Comprehensive evaluation is conducted on four major benchmarks: FakeAVCeleb, AV-Deepfake1M, AVLips, and TalkingHeadBench, employing AV-HuBERT as the backbone. Following protocol, the detector is trained exclusively with real video (VoxCeleb2) and AVPF-generated pseudo-fakes, without any annotated forgeries. AVPF achieves superior cross-dataset generalization, outperforming audio-visual models such as AVH-Align by 6.7% AUC and 8.0% AP on average, and exceeding recent self-supervised alternatives and state-of-the-art methods trained with both real and fake data.
A particularly strong result is reported on the TalkingHeadBench challenge, where AVPF reaches 77.8% AUC/79.1% AP, vastly outperforming AVH-Align, which collapses to 28.5% AUC/44.9% AP. This highlights the benefit of structurally plausible, yet subtle, training perturbations engineered by AVSB and AVSS.
Qualitative Analysis and Robustness
Analysis of temporal correspondence matrices reveals that AVPF-generated samples yield localized, fine-grained inconsistencies closely resembling the characteristics of advanced deepfakes, as opposed to trivial, easily-learned anomalies. This direct modeling is visualized via the local audio-video similarity matrices (LAVSM) and frame-wise AV cosine similarity for authentic, deepfake, naive pseudo-fake, and AVPF-synthesized pseudo-fake videos.
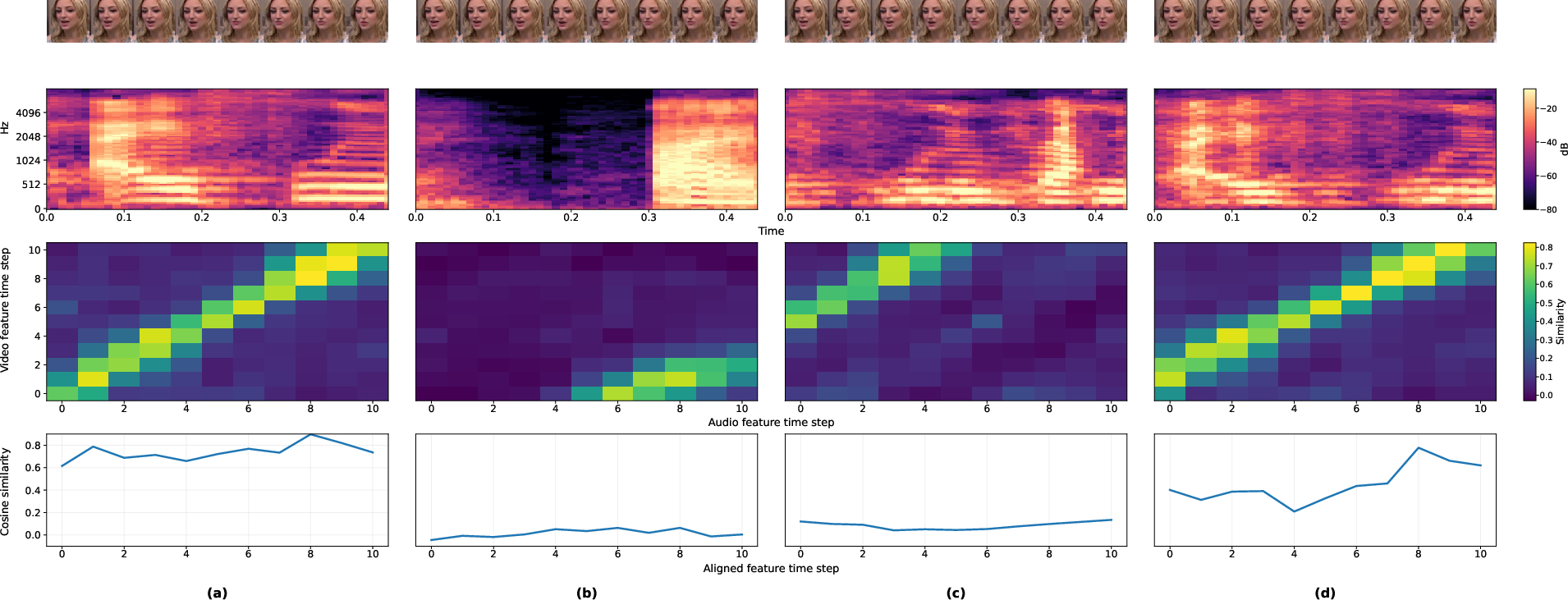
Figure 4: Local similarity matrices and frame-wise AV consistency: AVPF pseudo-fakes inject subtle perturbations that challenge the detector more similarly to hard forgeries than naïve manipulations.
Score distributions over test sets (AV1M, FAVC, AVLips) indicate that AVPF achieves much cleaner separation between authentic and fake samples, reducing overlap in the model’s output space and fostering more reliable thresholds.
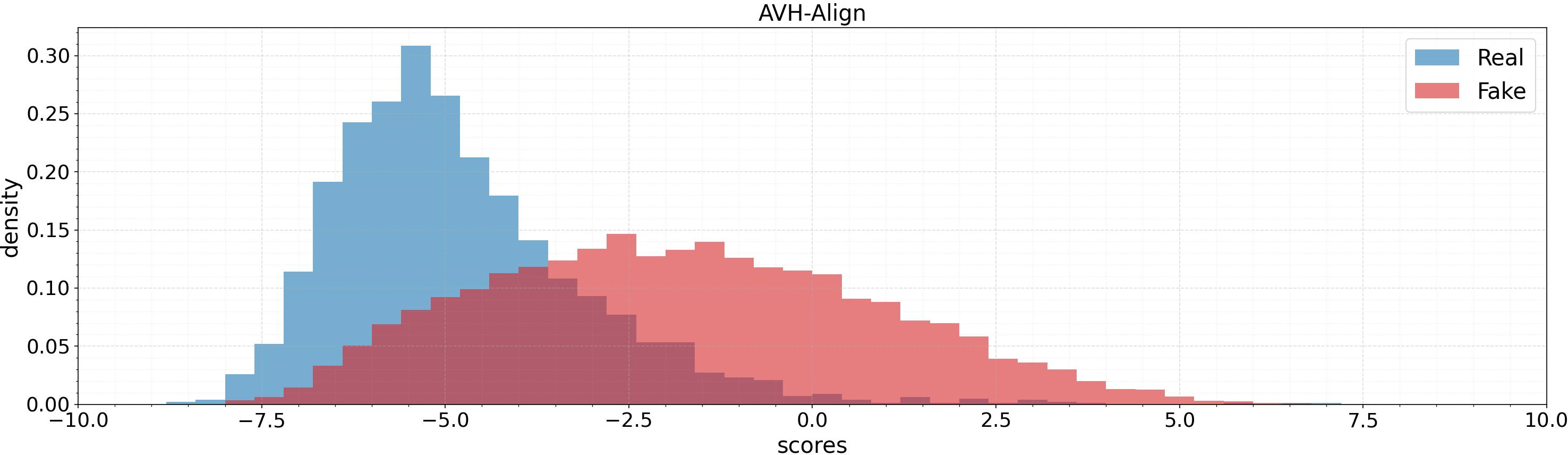
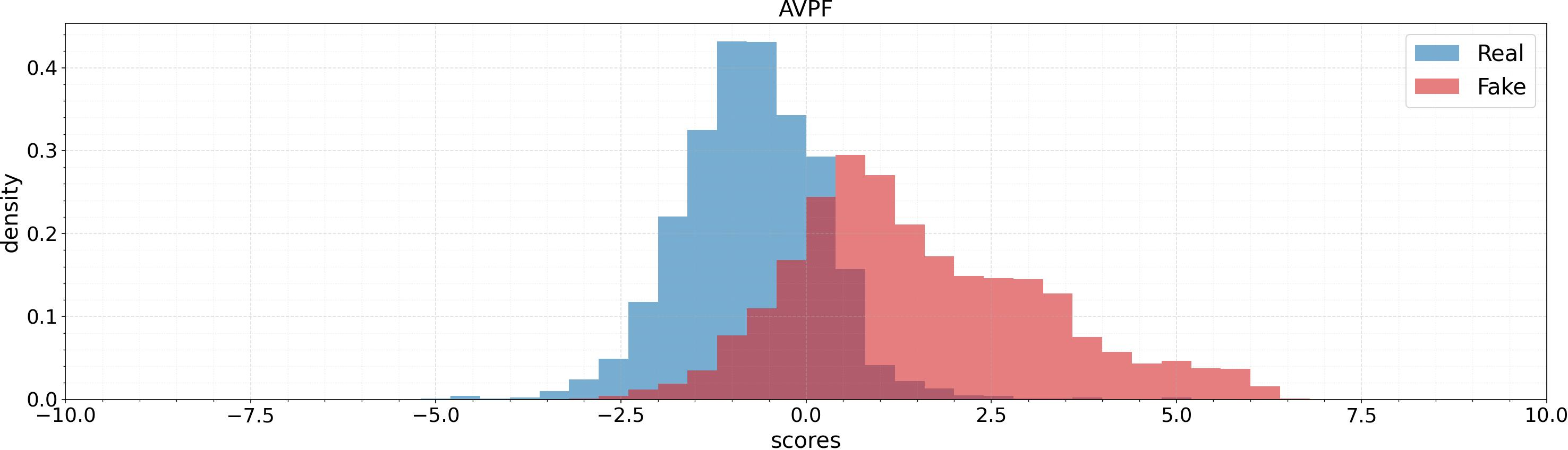
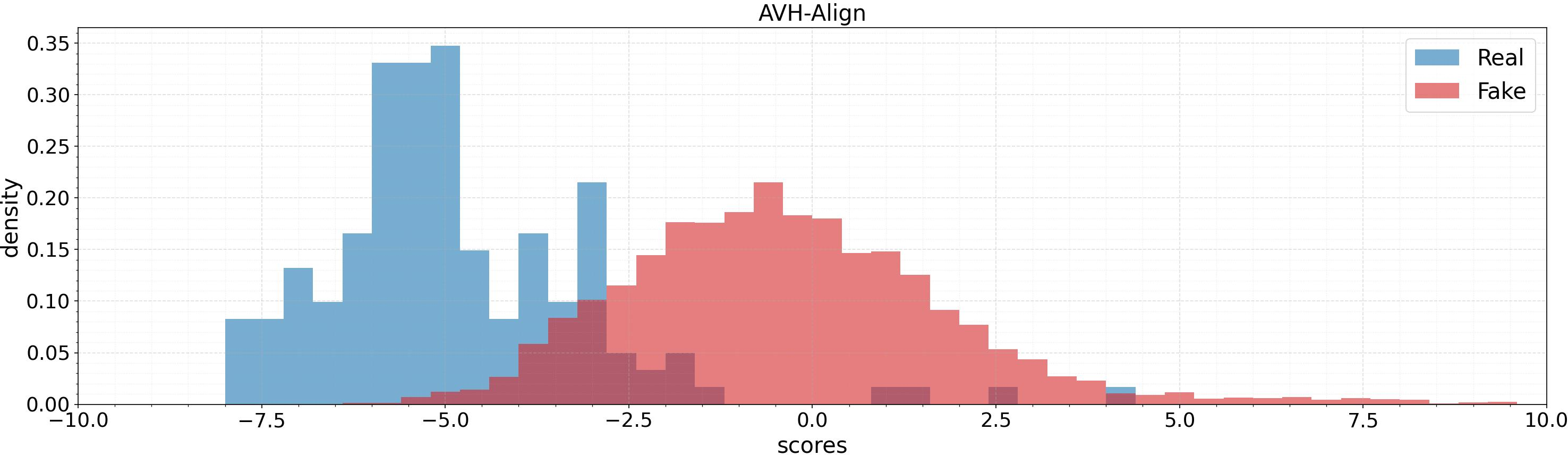
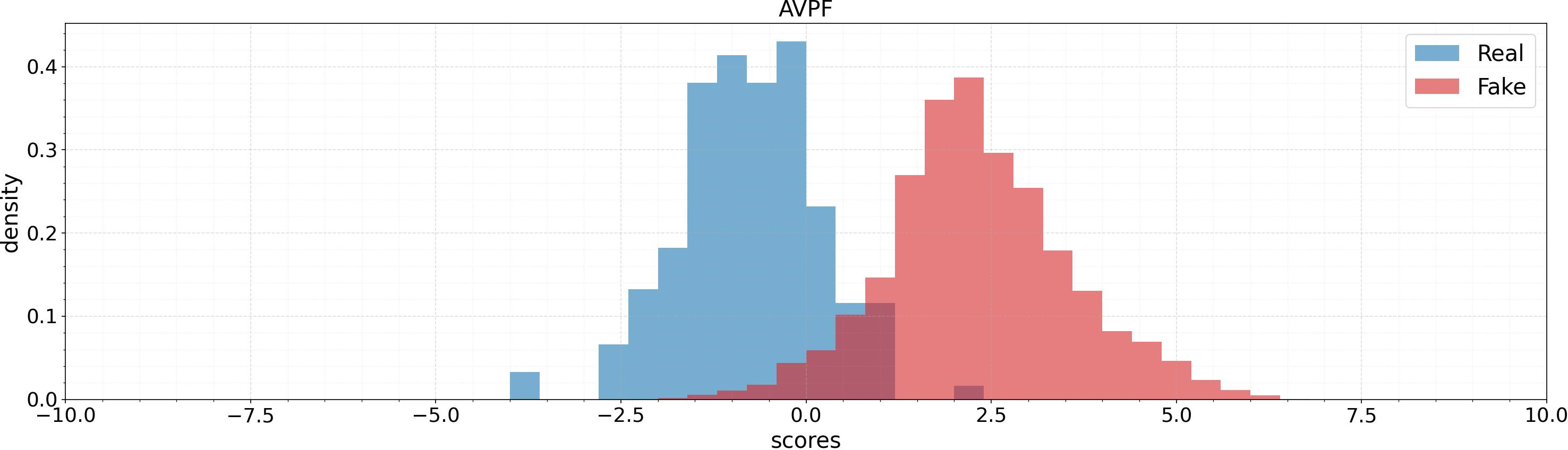
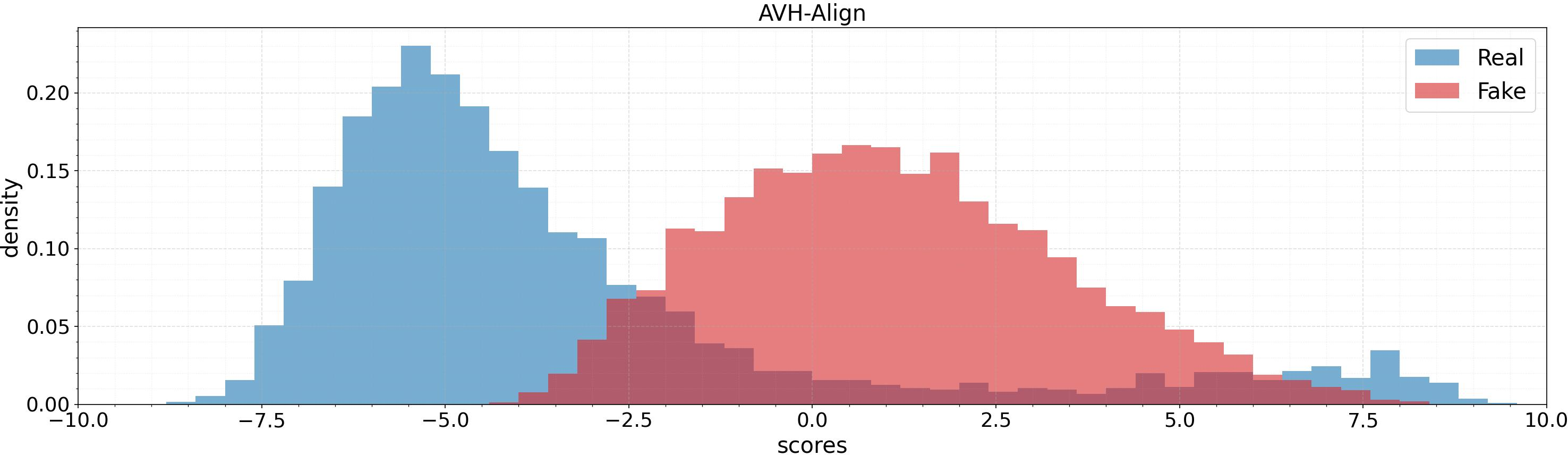
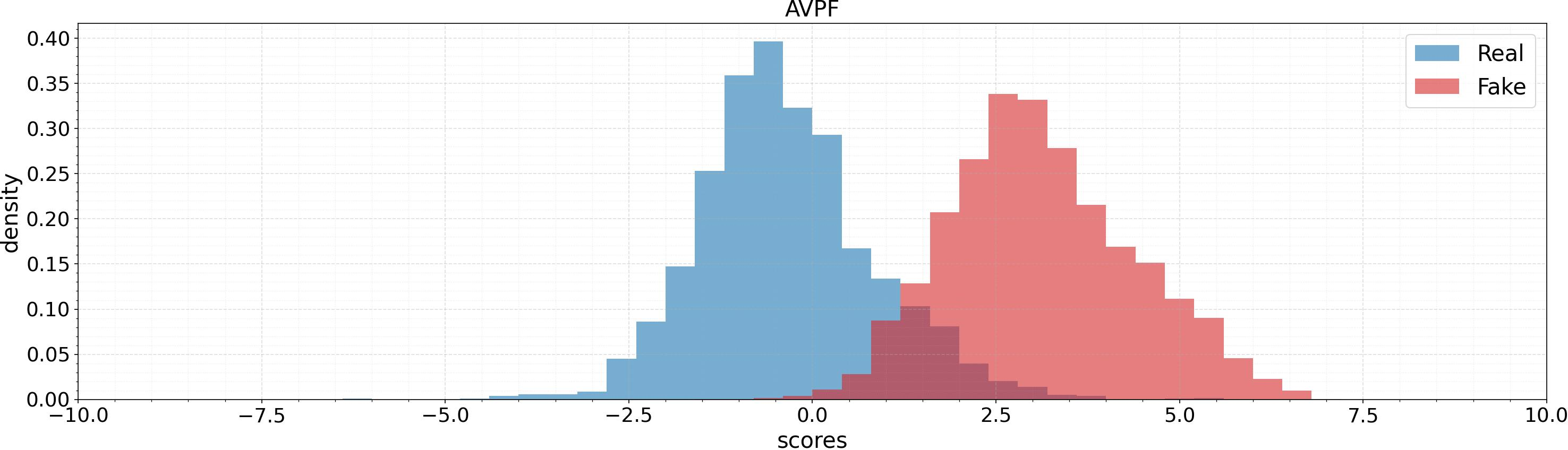
Figure 5: Score distribution comparison for AVH-Align and AVPF across datasets: AVPF provides higher fake/real separation and more robust margins.
Under heavy image degradations (JPEG, blur, noise, pixelation, color inversion), AVPF consistently maintains high Area Under the Curve (AUC) and Average Precision (AP) relative to baselines, empirically confirming robustness to post-processing that typically plagues dataset-dependent detectors.
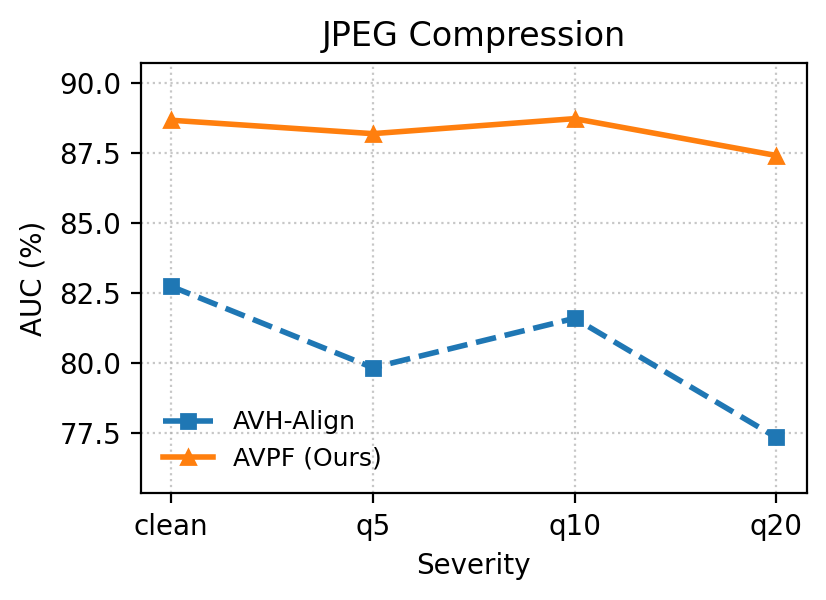
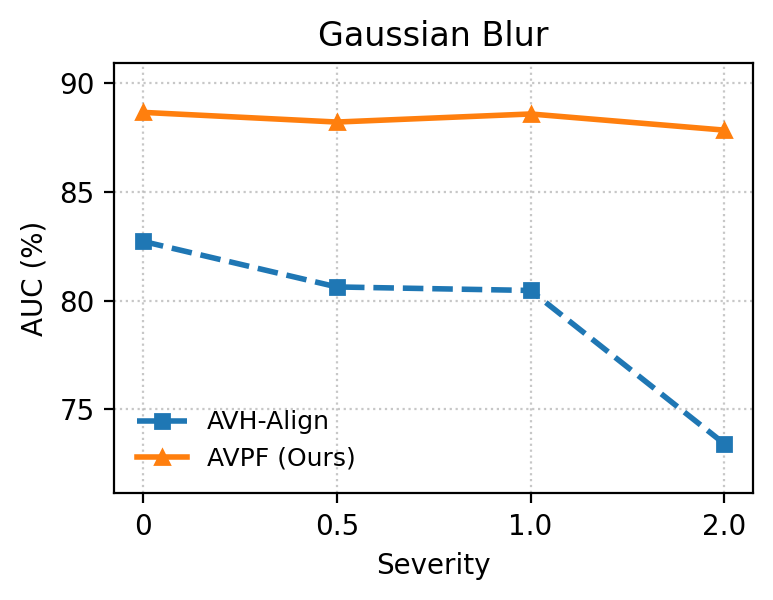
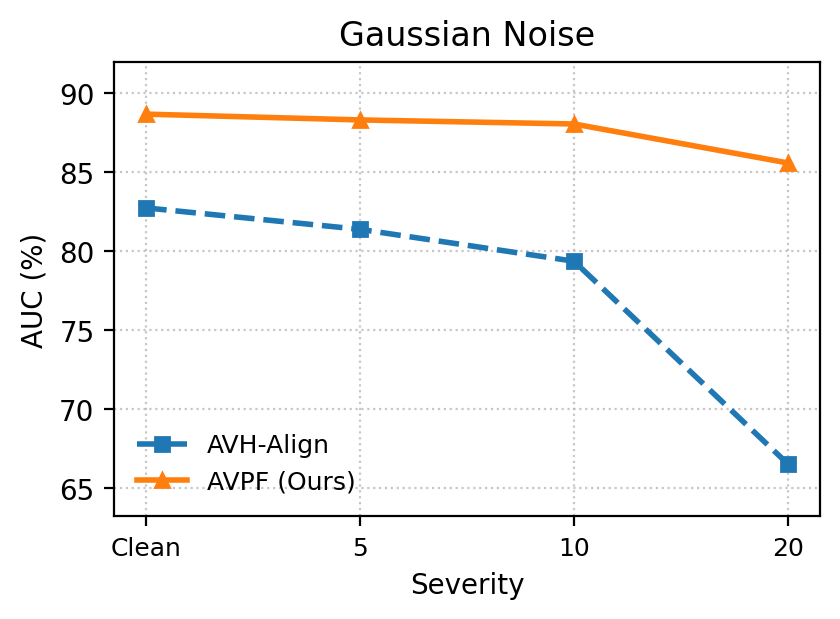
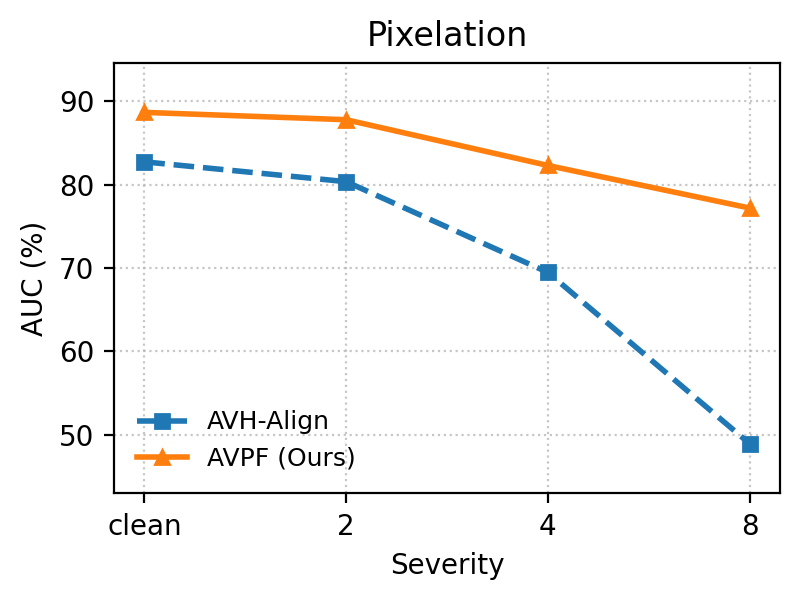
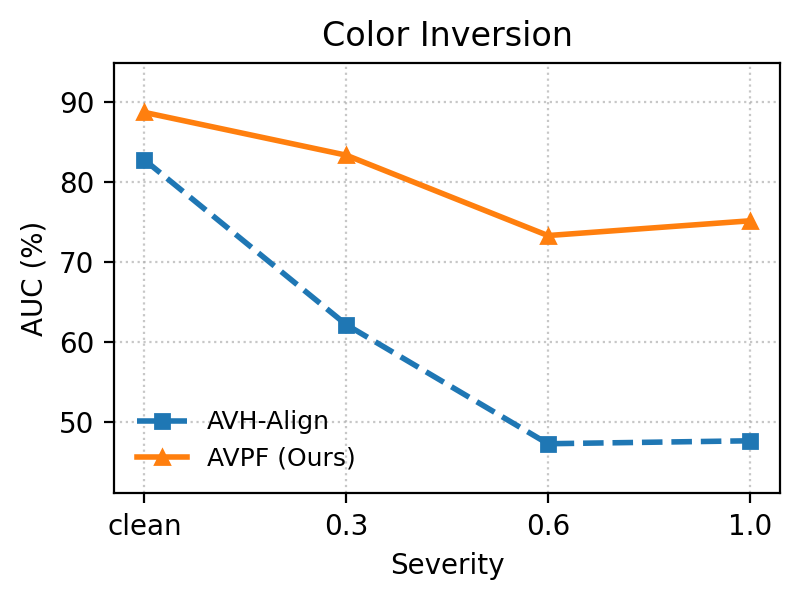
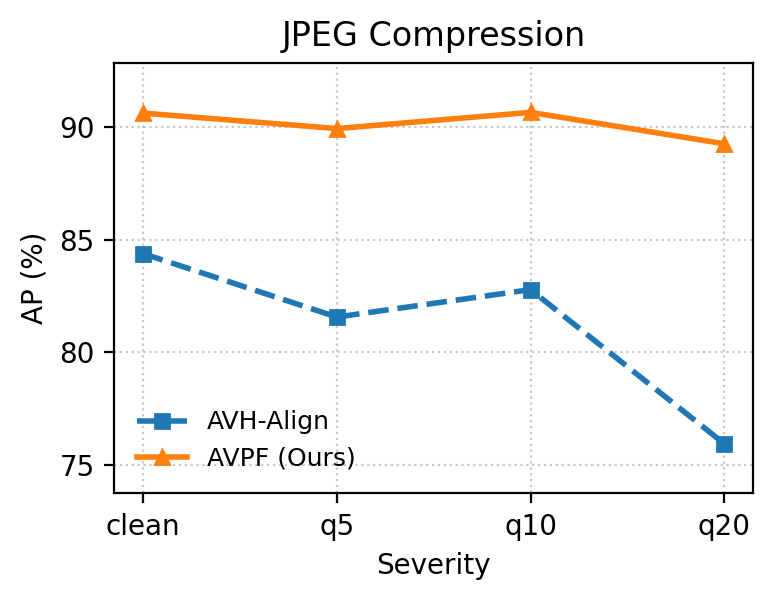
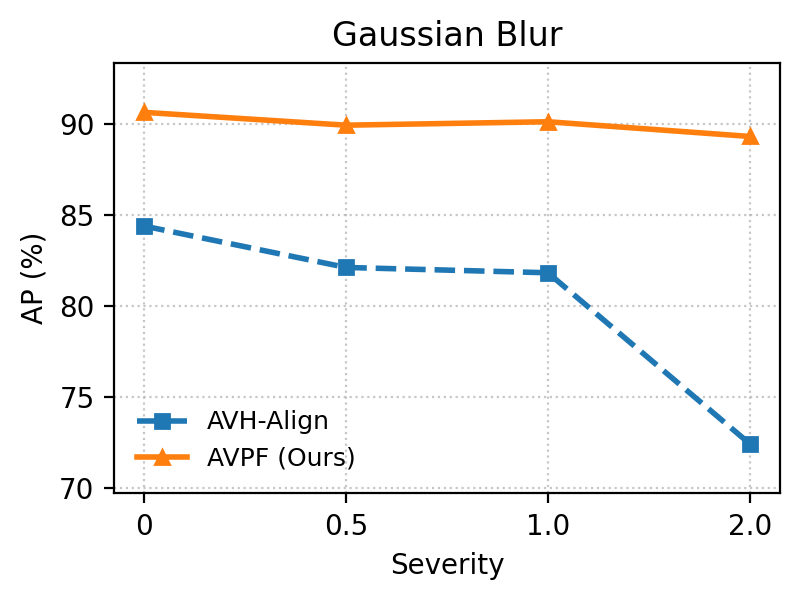
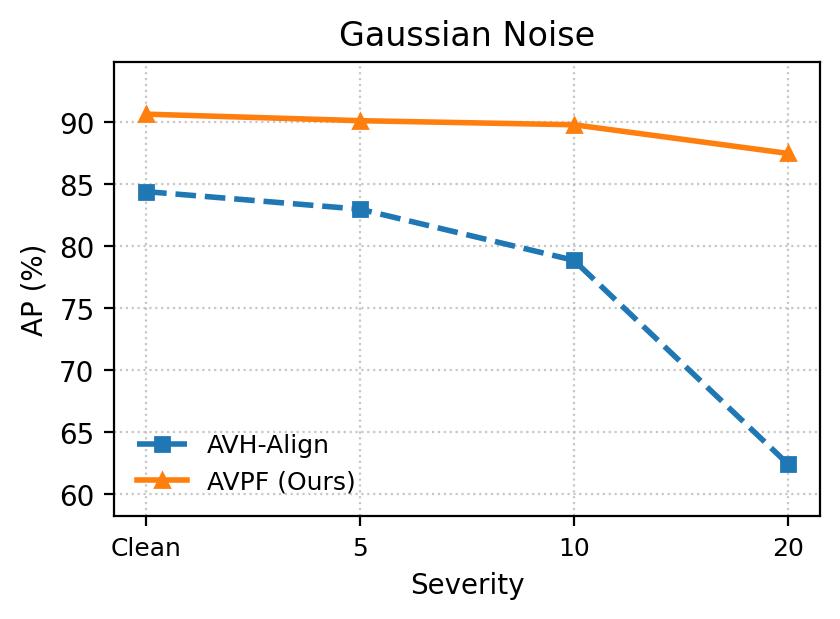
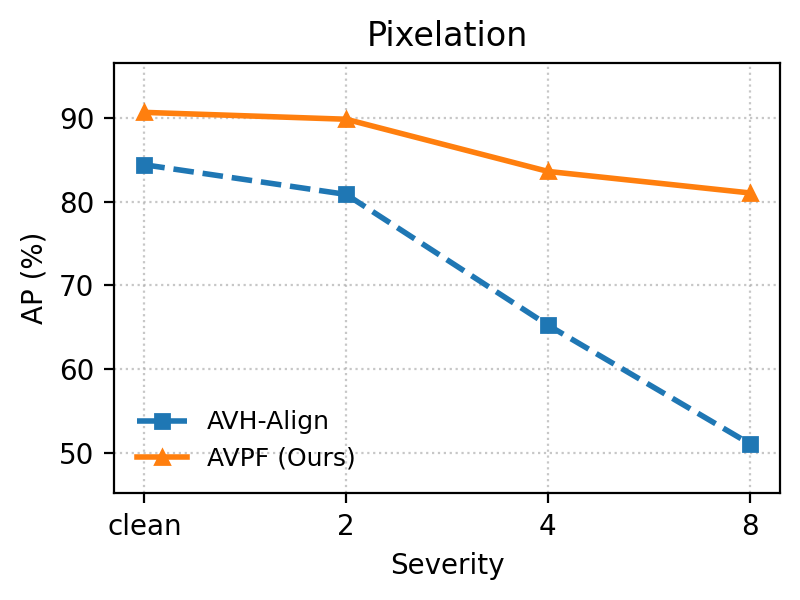
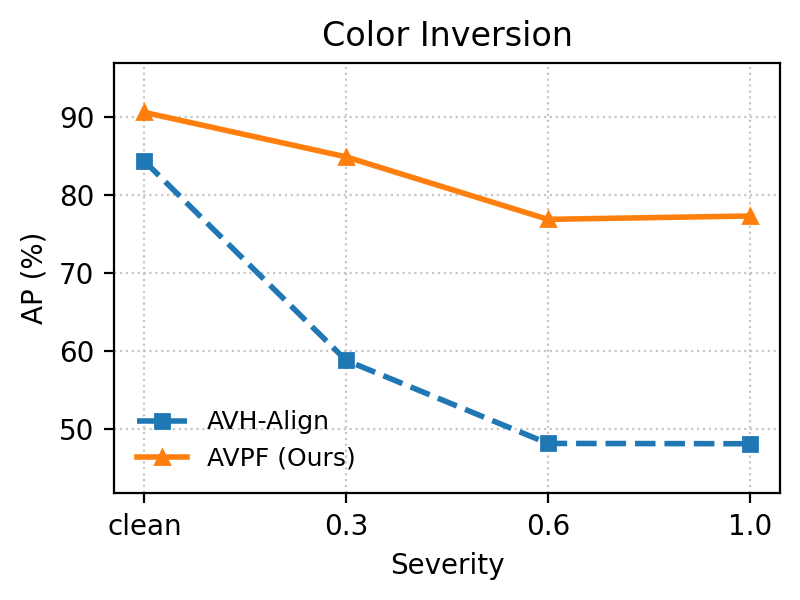
Figure 6: Robustness comparison under five perturbation types: AVPF exhibits significant stability across degradation scenarios versus AVH-Align.
Ablation Studies
Component ablations confirm that both AVSB and AVSS contribute to model performance on different benchmarks, with visual self-blending providing the most direct improvements in generalization. Hyperparameter sweeps on shift magnitudes, window localization, snippet selection range, and length all reveal optimal trade-offs between perturbation realism and detection task difficulty. Incorporating similarity constraints for splicing and fine-tuning shift durations can effectively generate pseudo-fakes that maximally regularize the cross-modal encoder.
Theoretical and Practical Implications
AVPF substantiates the hypothesis that self-supervised pseudo-fake curation—if carefully constrained to mimic both inter- and intra-modal artifacts found in advanced deepfakes—is a viable and scalable alternative to annotation-reliant training in video deepfake detection. This approach establishes a blueprint for fully unsupervised yet robust forensic models, reduces the operational dependency on up-to-date manipulation datasets, and offers greater resilience to distributional shifts and adversarial post-processing.
Furthermore, the implicit exposure to subtle, non-trivial perturbations addresses the shortcut learning problem prominent in recent literature, directly augmenting the network’s feature discovery process with hard negative priors.
Future Directions
Despite the demonstrated effectiveness in detection, the current AVPF formulation does not address the spatiotemporal localization of forged regions—an essential requirement for operational forensic pipelines. Future directions could integrate explainability and localization, leveraging the synthetic pseudo-fake paradigm to supervise dense prediction tasks. Additionally, generalization could be further strengthened by integrating generative priors from emerging large-scale diffusion-based forgery methods, architectural innovations in cross-modal modeling, or online adversarial pseudo-fake generation schemes.
Conclusion
The AVPF framework presents a technically rigorous, data-efficient, and highly generalizable strategy for the detection of audio-visual deepfakes, relying solely on the engineering of pseudo-fake inconsistencies derived from authentic video data. Its empirical superiority over multiple baselines, especially in out-of-distribution and low-resource scenarios, emphasizes the utility of curriculum-style self-supervision over dataset-dependent cheat detection. This work advances the state of multimodal forensics and motivates new investigations into fully unsupervised hard-negative generation for robust forgery analysis (2604.09110).

