- The paper presents DRIFT, an algorithm–architecture co-design framework that exploits diffusion models’ fault tolerance to improve efficiency.
- It introduces resilience-aware DVFS and rollback-ABFT error mitigation to manage bit errors while maintaining generative fidelity.
- Experimental evaluations demonstrate up to 36% energy savings and 1.7x speedup with negligible quality loss across various diffusion models.
DRIFT: Harnessing Inherent Fault Tolerance for Efficient and Reliable Diffusion Model Inference
Introduction
Diffusion models have established state-of-the-art performance for various generative tasks, particularly in high-fidelity image synthesis. However, their iterative denoising algorithms necessitate substantial compute resources, leading to significant challenges in deployment due to high energy consumption and inference latency. While task-specific accelerators and model compression techniques have partially alleviated these bottlenecks, dynamic voltage and frequency scaling (DVFS)—a direct hardware-level lever for efficiency—remains underutilized in this context, chiefly due to the risk of computation errors degrading model performance.
DRIFT ("Harnessing Inherent Fault Tolerance for Efficient and Reliable Diffusion Model Inference" (2604.09073)) introduces an algorithm-architecture co-design framework to address this gap. By characterizing the resilience of diffusion models to various forms of bit errors and exploiting inherent error tolerance, the framework achieves substantial energy savings and latency reduction while preserving generative quality. DRIFT orchestrates fine-grained, resilience-aware DVFS alongside a tailored rollback-ABFT (Algorithm-Based Fault Tolerance) error mitigation architecture, and further optimizes memory operations to control system overhead.
Limitations of Conventional DVFS in Diffusion Model Inference
Traditional DVFS strategies can yield energy improvements when applied judiciously, but aggressive scaling often introduces timing violations, increasing bit error rates (BER) in arithmetic pathways. Experimental evidence demonstrates that as BER increases, the performance of diffusion models (e.g., DiT, PixArt) degrades sharply, with even minor BER increments leading to perceptible quality loss in generated images.
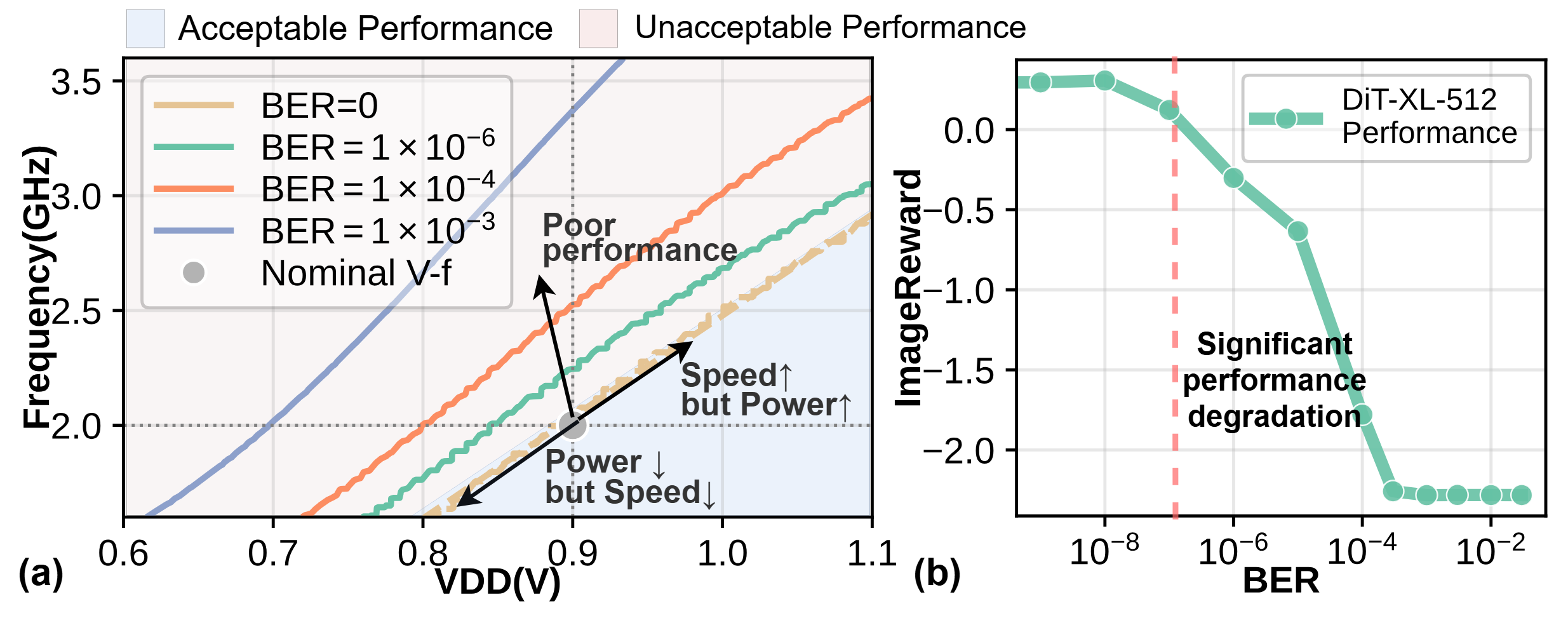
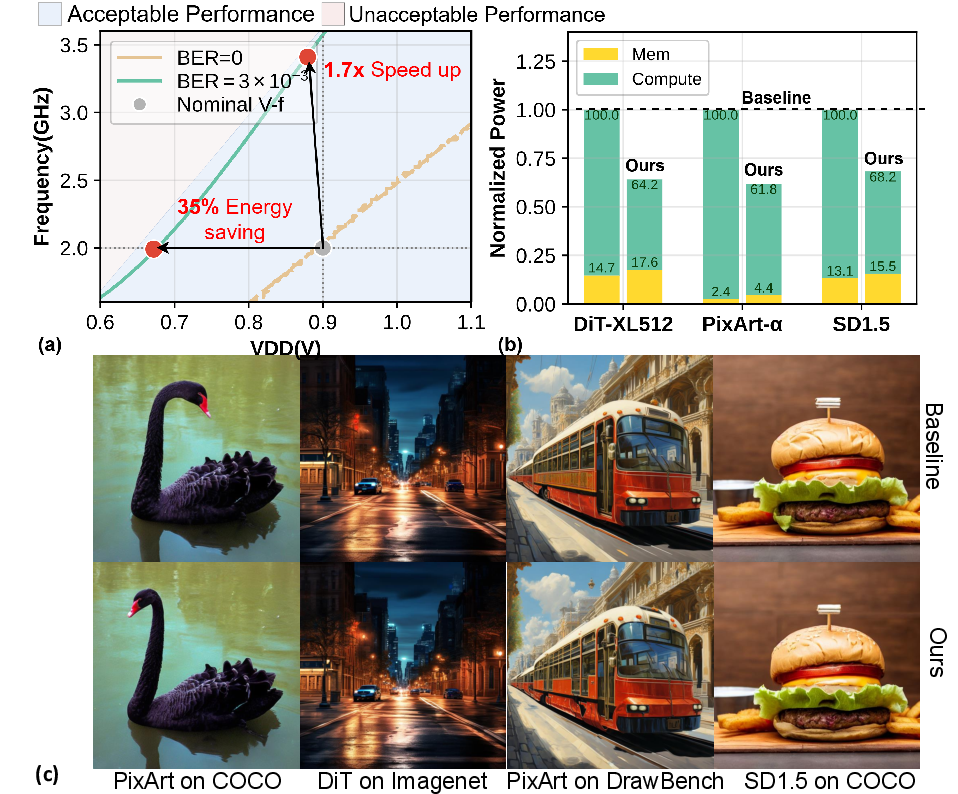
Figure 1: DVFS in diffusion models is limited by rapid BER-induced model degradation, as depicted using 14nm PDK synthesis results.
This efficiency–reliability tradeoff severely constrains the operational envelope for inference accelerators, limiting both energy reduction and throughput improvements. Existing error tolerance and ABFT approaches, though effective for general DNN inference, do not efficiently balance resilience and efficiency when adapted to the unique iterative denoising of diffusion models.
Fault Tolerance and Temporal Resilience in Diffusion Models
DRIFT is motivated by the hypothesis that the progressive, multi-step nature of diffusion model inference endows it with non-uniform and nuanced error resilience. To quantify this, a comprehensive error injection campaign targets both Transformer-based and UNet-based diffusion architectures, specifically benchmarking the sensitivity of generative quality to artificial bit-flips at diverse positions, network locations, and timesteps.
Key findings include:
- Bit-level sensitivity: Low-order bit errors yield negligible impact, while high-order bit errors have more pronounced effects, but only above certain thresholds.
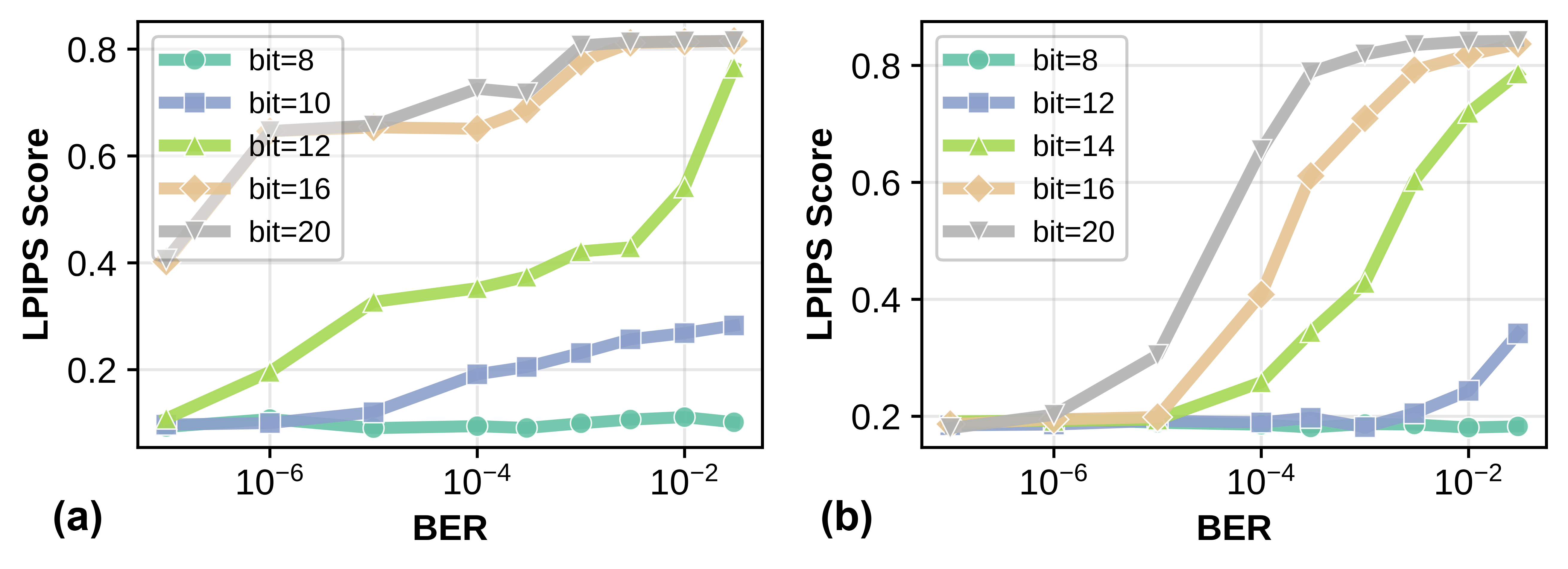
Figure 3: Bit-level resilience characterization on DiT and PixArt; performance loss is most severe for high-order bit flips.
- Temporal (timestep-level) sensitivity: Early denoising steps are more vulnerable to errors, as they construct global semantics and spatial structure. Later steps, responsible for detail refinement, demonstrate much higher error tolerance.
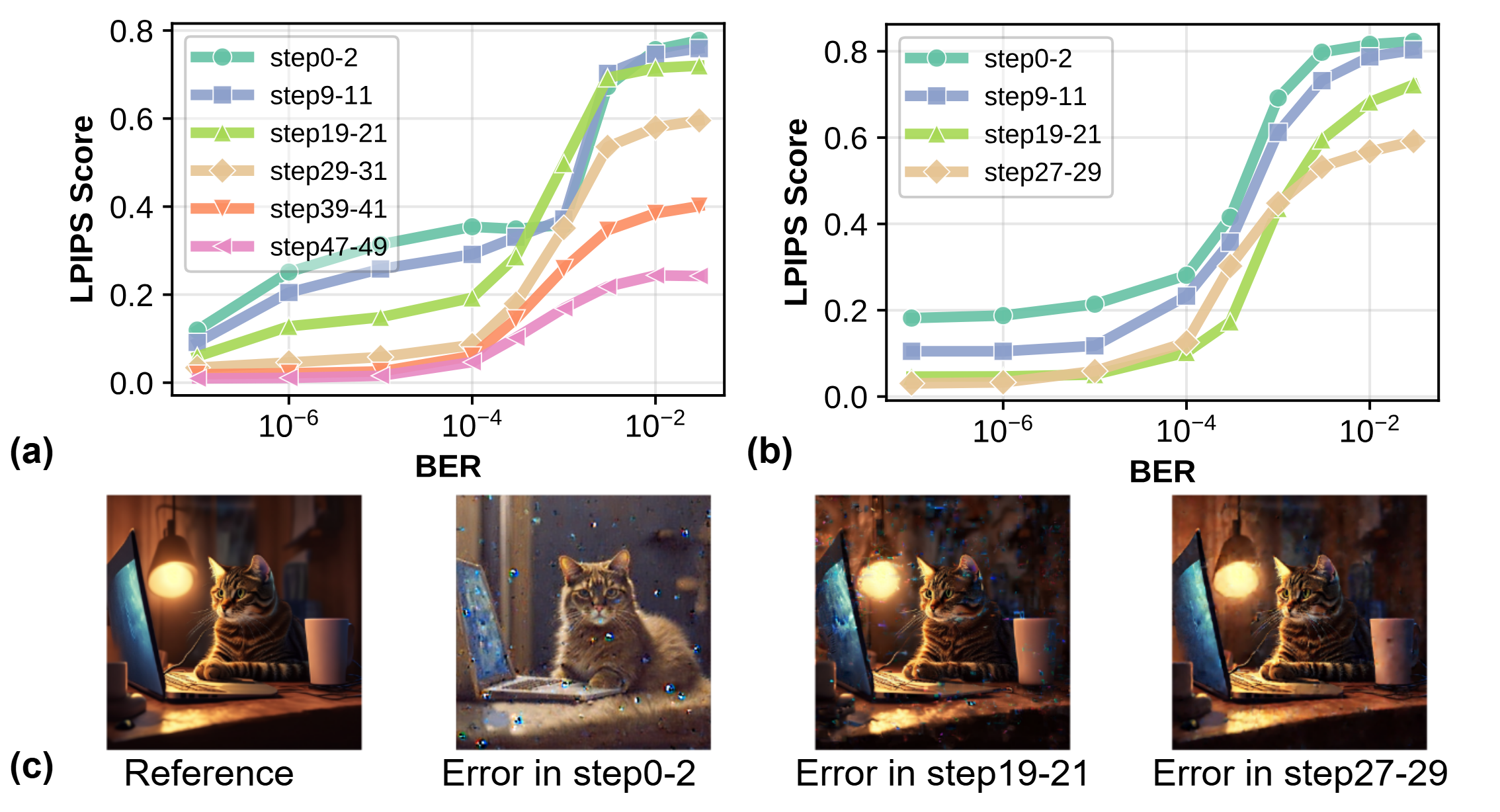
Figure 5: Early timesteps are critical for preserving structure—errors here yield greater LPIPS degradation.
- Block-level heterogeneity: Fault sensitivity is concentrated in early transformer blocks and embedding layers, which propagate errors widely through cross-attention mechanisms. Deeper layers are dominated by residual pathways with higher representational redundancy.
- Self-correction: Intriguingly, the iterative denoising exhibits self-recovery: moderate errors introduced at intermediate steps tend to be partially or fully corrected in subsequent steps, limiting lasting distortion in the output.
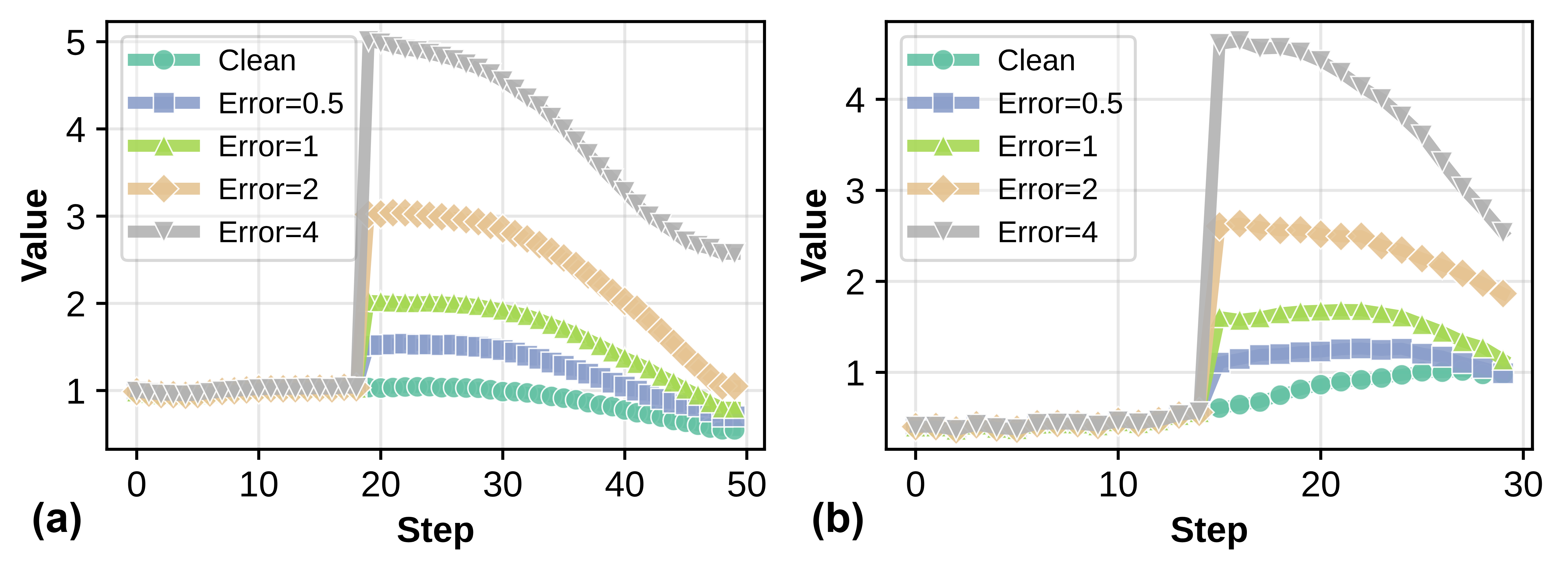
Figure 2: Diffusion process exhibits self-correcting behavior, where error impacts diminish over timesteps.
These insights directly inform a selective protection strategy, rather than the uniform worst-case provisioning typical in fault-tolerant accelerator design.
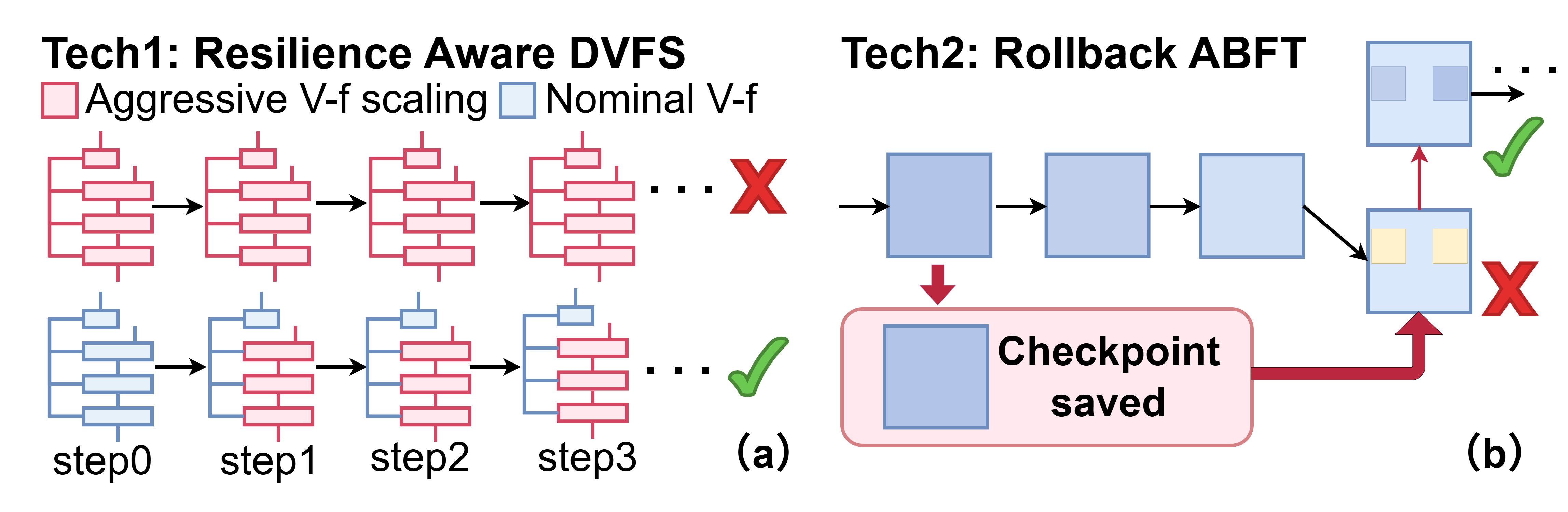
DRIFT Framework: Algorithm-Architecture Co-Design
The DRIFT framework comprises two synergistic hardware–software innovations, tailored for TPU-style accelerators executing quantized diffusion models.
These mechanisms are realized by specialized architectural support: auxiliary checksum circuits wrapping systolic arrays, reconfigurable DVFS modules, data layout repacking logic, and a runtime error monitoring controller, all orchestrated to minimize latency and off-chip memory usage. Checkpointing frequency and correction thresholds are selected through careful design space exploration.
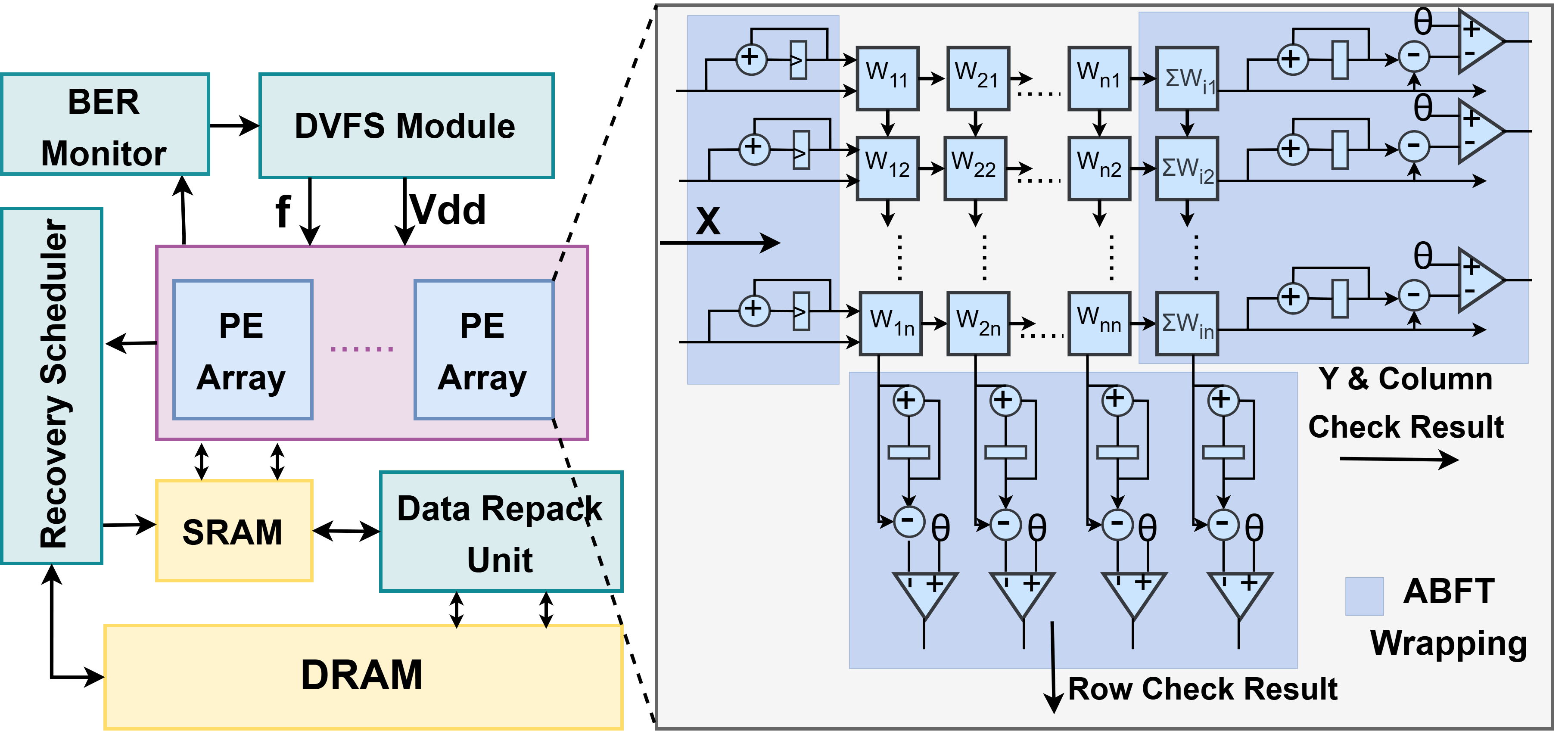
Figure 9: System-level architectural diagram for DRIFT-enabled topic-specific accelerator.
Memory access optimization is particularly crucial: data repacking ensures tiles required for rollback are stored contiguously, minimizing DRAM row activations and associated retrieval energy/latency. Furthermore, checkpoint offloading occurs at a coarse interval (e.g., every 10 steps), leveraging high activation similarity across adjacent timesteps, thus amortizing DRAM access cost.
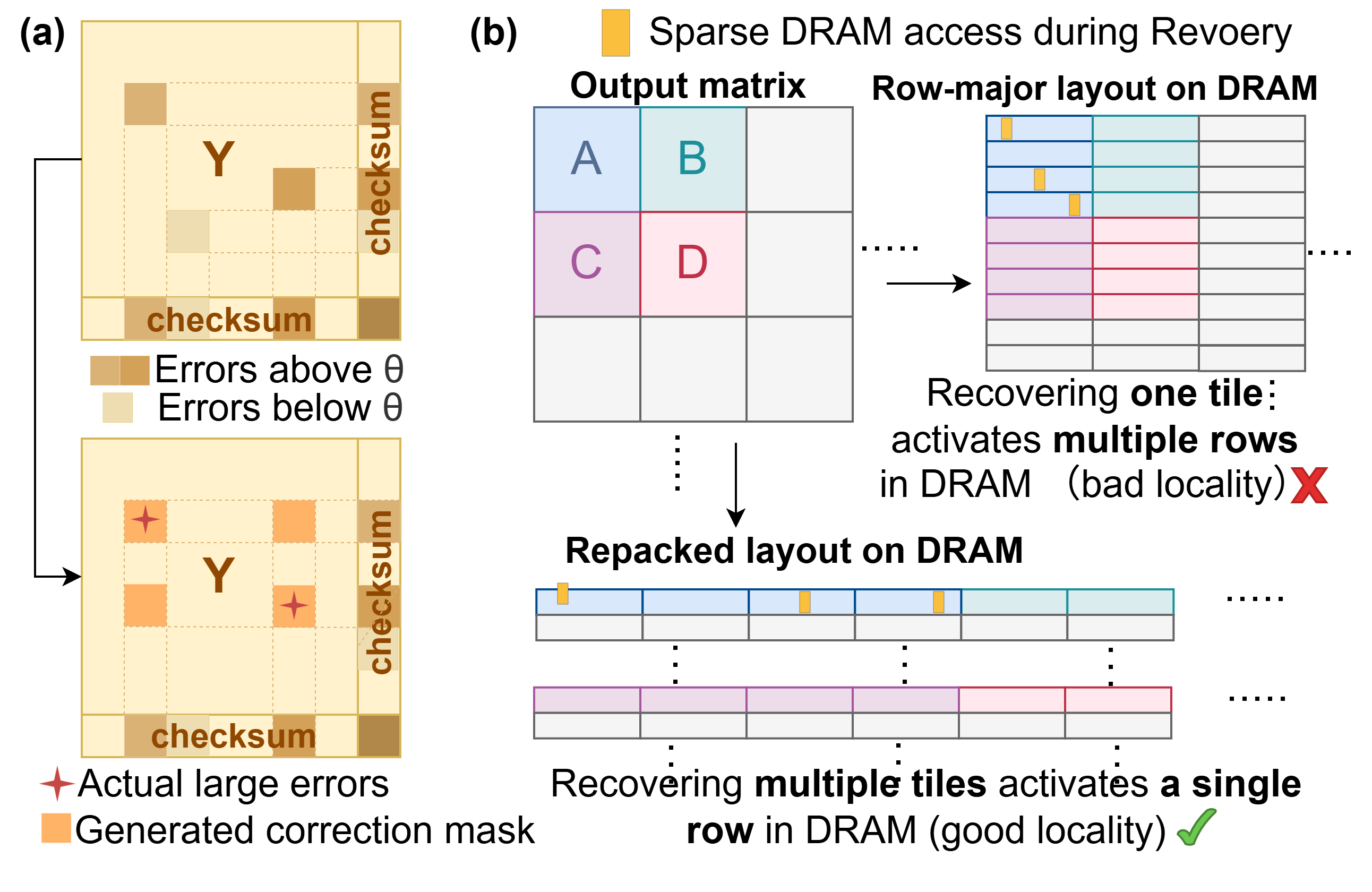
Figure 6: Correction mask construction and data repacking detail for efficient selective retrieval.
Experimental Evaluation
Across DiT, PixArt, Stable Diffusion, and multiple datasets (ImageNet, COCO, DrawBench), DRIFT achieves the following:
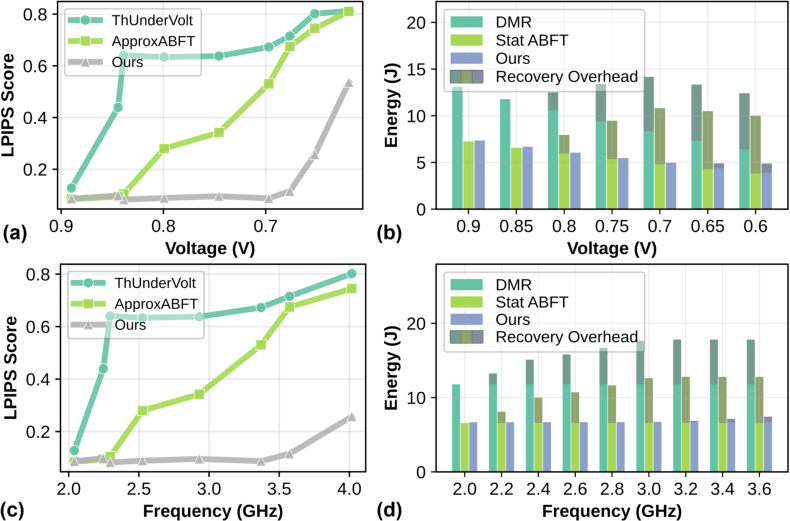
DRIFT is compared against DMR, ThUnderVolt, ApproxABFT, and statistical ABFT baselines:
Ablation study corroborates the incremental value: rollback-ABFT increases error tolerance by 100x, and data layout changes decrease DRAM row activations during recovery by over 23x.
Compatibility with algorithmic accelerations (e.g., TaylorSeer) is demonstrated: the combined system achieves a 4.4x speedup, validating DRIFT's generality and orthogonality to software-level efficiencies.
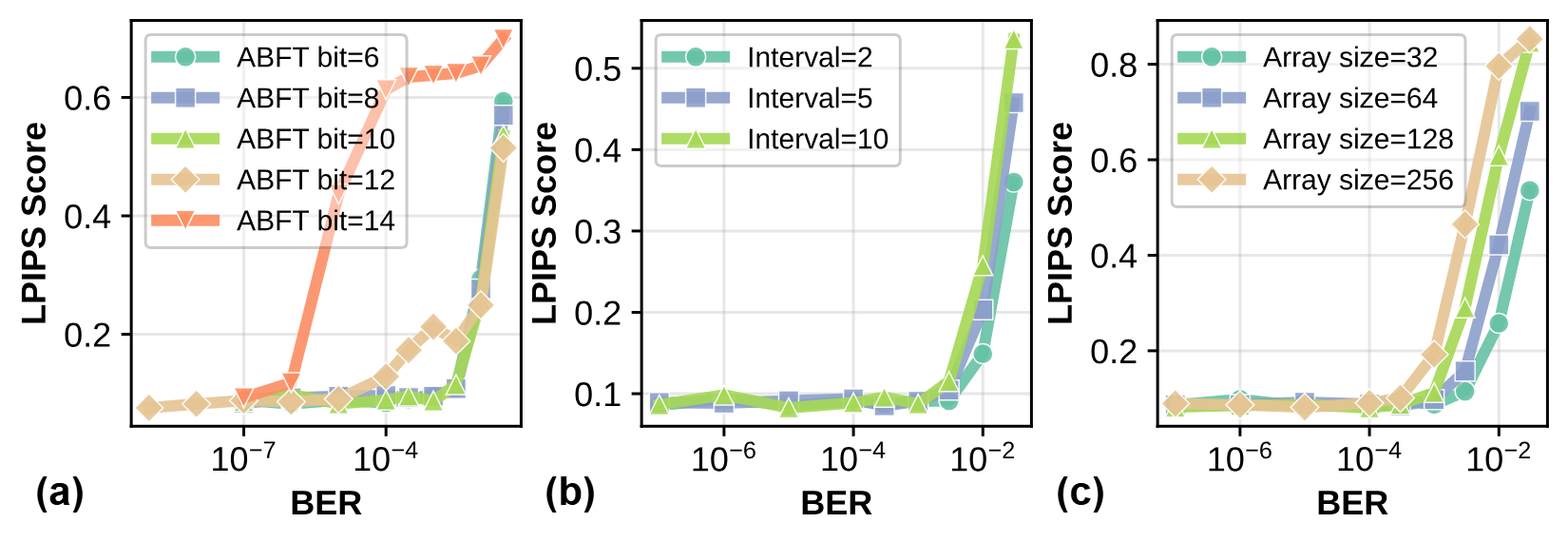
Design Parameters and Tradeoffs
Key parameters (ABFT threshold bit, checkpointing interval, systolic array size) are evaluated for robustness:
Implications and Future Directions
The theoretical implication of DRIFT is a principled shift from uniform reliability provisioning to resilience-centric, workload-aware safety margins, capitalizing on algorithmic properties—especially in generative architectures with natural correction dynamics or redundancy. Practically, DRIFT unlocks a new layer of aggressive hardware adaptation, substantially reducing energy cost and latency under industrial constraints, with minimal changes to model code or training.
Such hardware–algorithm co-design approaches will likely extend beyond diffusion models: other iterative, generative, or self-correcting inference algorithms (e.g., RNNs, autoregressive models, iterative solvers) may similarly benefit. On the resource-constrained edge, where power margins are critical, DRIFT-like frameworks could make high-quality generative AI feasible.
Further work could explore finer granularity in DVFS, more sophisticated runtime adaptation based on observed error patterns, or extensions to multi-modal, in-context, or video diffusion pipelines.
Conclusion
DRIFT demonstrates that by rigorously characterizing and then explicitly leveraging the inherent, structured fault tolerance of diffusion models, it is possible to markedly advance efficiency without incurring the semantic or perceptual penalties typically associated with aggressive hardware scaling. Its co-optimized DVFS and lightweight ABFT/rollback mechanisms offer a universal template for deploying large, compute-intensive generative models on energy- and latency-sensitive platforms, and establish a foundation for future cross-layer resilience–efficiency innovations in AI systems.