- The paper presents a novel infinite-horizon optimal control framework that integrates barrier-Lyapunov functions with auxiliary variables to guarantee safety.
- It introduces adaptive tangential excitation to mitigate local trapping and enhance reinforcement learning convergence under disturbances.
- By extending high-order safe sets with barrier compensation, the approach ensures strict forward invariance in uncertain, safety-critical environments.
Synthesizing Safety in Infinite-Horizon Optimal Control for Disturbed High-Relative-Degree Systems via Barrier-Regulating Auxiliary Variables
Introduction and Motivation
Infinite-horizon optimal control for safety-critical nonlinear systems under disturbance and high-relative-degree constraints poses rigorous challenges in balancing long-term performance, safety enforcement, and robustness to uncertainties. Existing control barrier function (CBF)-based safety filters, while widely adopted for their pointwise safety guarantees, are fundamentally myopic and susceptible to local trapping, particularly when the safeguarding action conflicts with the nominal optimal controller. These shortcomings motivate the development of frameworks that integrate safety, performance, and robustness in a unified, non-myopic manner over an infinite horizon.
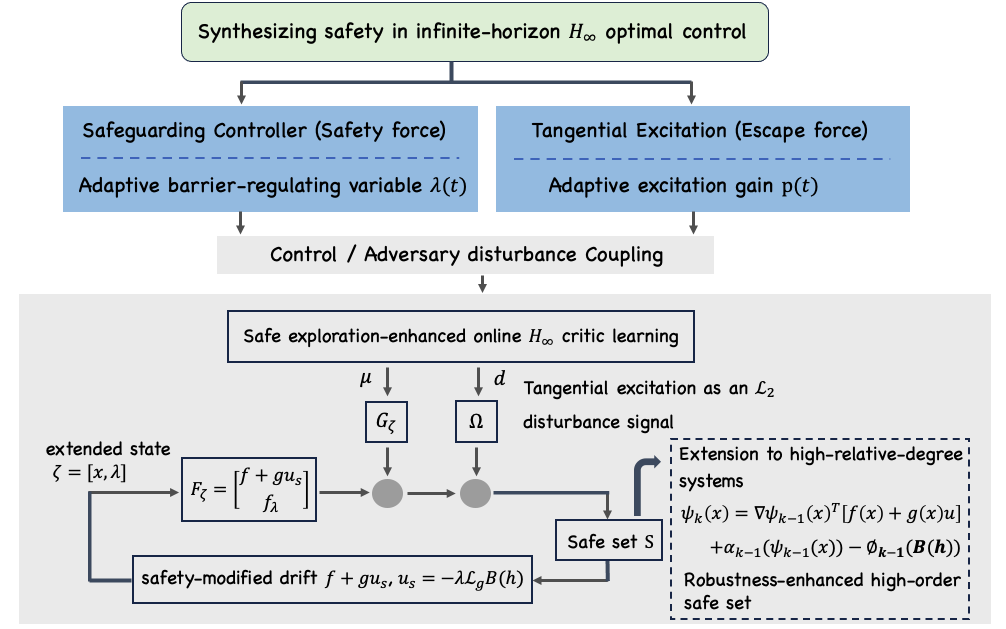
Figure 1: Barrier-regulating variable-enhanced optimal control; the schematic shows how safeguarding with an auxiliary variable augments traditional optimal control policies.
This work introduces a safety-aware infinite-horizon optimal control framework leveraging barrier-Lyapunov functions (BLFs) and auxiliary variables regulating the safety-performance trade-off. The framework systematically embeds safety constraints into unconstrained infinite-horizon problems, even for disturbed nonlinear systems with high relative degree, and approaches their solution via safe-exploration-enhanced reinforcement learning (RL). This approach forms a cohesive synthesis of robust control, safe RL, and high-order CBF theory.
Safety Embedding via Barrier-Lyapunov Functions and Auxiliary Variables
The core architecture reformulates the original state-constrained problem as an unconstrained control problem over an extended state space. By embedding the BLF-induced safeguarding control into the closed-loop system dynamics, the approach yields an optimal controller of the form u=uo+us, where uo is the infinite-horizon nominal controller and us=−λ∗(x)∇B(x) is the barrier-regulated safeguarding action. Analysis leveraging the stationary HJB and KKT conditions reveals that the Lagrange multiplier λ∗(x) naturally encodes the required safety enforcement; crucially, safety can be guaranteed as long as λ(x)>0, decoupling exact multiplier computation from real-time safety guarantees.
Introducing a dynamic auxiliary system for λ allows its adaptive regulation according to a state-dependent lower bound λref(x), guarding against degradation near safety boundaries. This auxiliary variable is treated as a virtual subsystem, with dynamics permitting integration into standard infinite-horizon optimal control formulations on the extended state ζ=[x⊤,λ]⊤.
Overcoming Local Trapping: Adaptive Tangential Excitation
Despite robustifying the normal component, BLF-based safeguarding controllers are susceptible to local trapping in nonconvex safe sets when the nominal and safeguarding directions are closely aligned, resulting in stagnation away from the goal. The framework introduces an adaptive tangential excitation orthogonal to the barrier gradient, activated based on the alignment measure between the nominal and safeguarding directions, thereby creating a structured L2-norm disturbance channel for safe exploration.
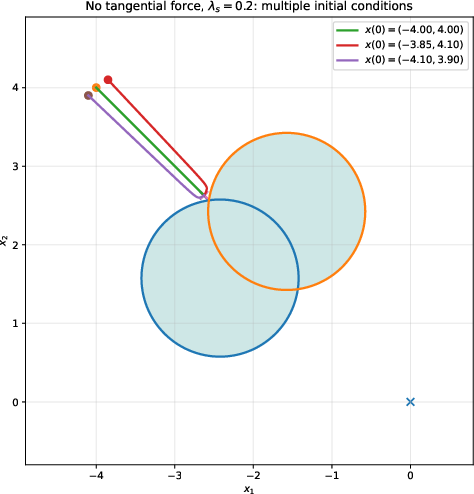
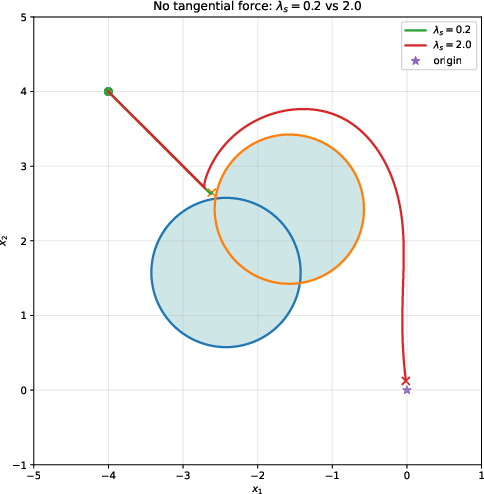
Figure 2: Effect of safeguarding gain without tangential excitation. Left: Low λ leads to local trapping; right: higher uo0 avoids trapping and ensures convergence.
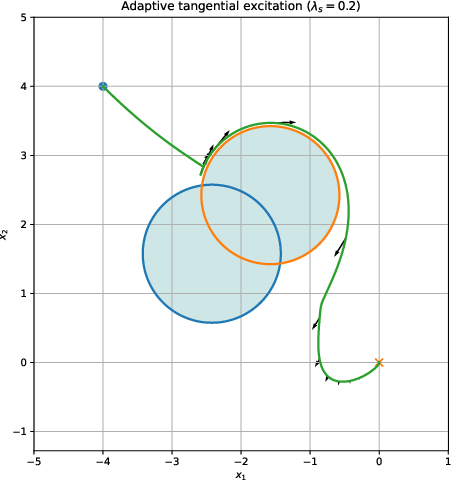
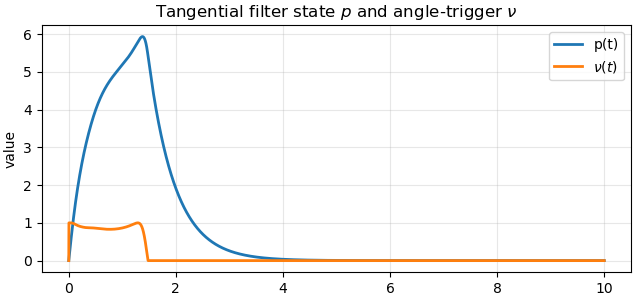
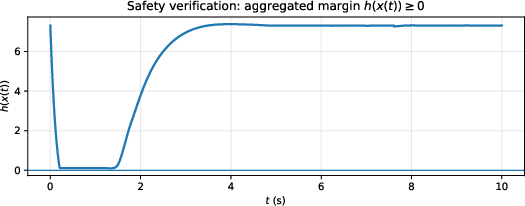
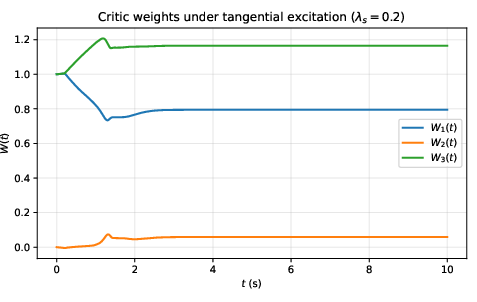
Figure 3: Adaptive tangential excitation under a weak safeguarding gain; arrows show tangential disturbance, with learning dynamics and safety margins over time.
The use of tangential excitation expands the set of reachable states under safe control, augments data efficiency for the RL critic, and systematically mitigates local trapping without violating safety, as the excitation is constructed orthogonally to the safety constraint direction.
Robust High-Order Safe-Set Construction under Disturbances
For high-relative-degree systems—where the input does not appear in the derivative of the safety function until order uo1—the framework generalizes BLFs into high-order BLFs (HOBLFs) through recursive CBF-based safe set construction. To address disturbances, additional barrier compensation terms uo2 are incorporated, ensuring that the barrier feedback dominates bounded disturbances near the safety boundary.
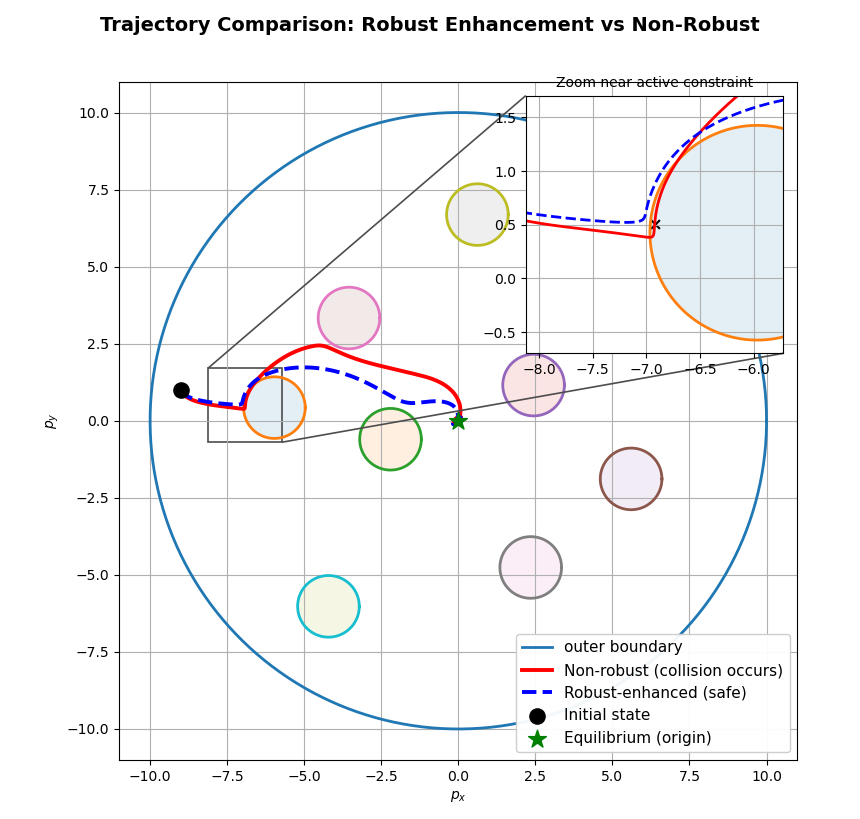
Figure 4: Trajectory comparison with and without robustness enhancement; the robustness-enhanced term prevents constraint violation near obstacles.
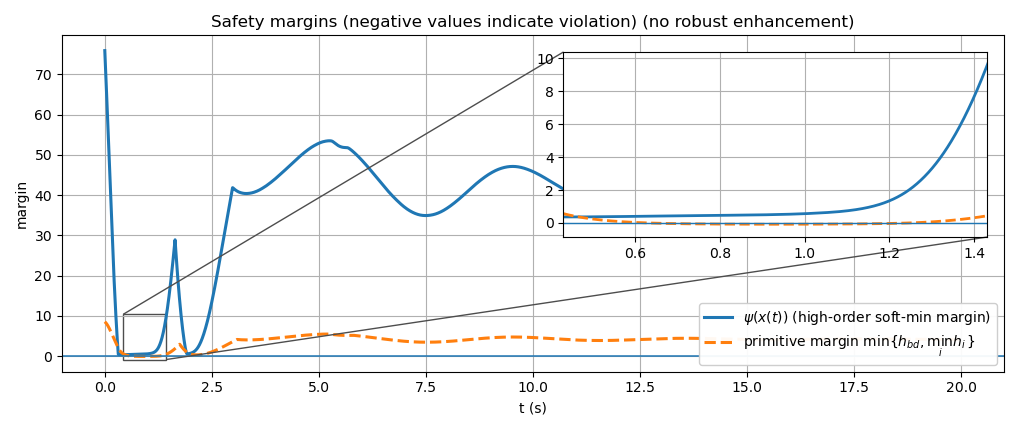
Figure 5: Evolution of safety margin without robustness enhancement showing constraint violation episodes in primitive margin.
This robustification approach demonstrates, both theoretically and empirically, that the high-order safe sets, when properly compensated, yield forward invariance and disturbance attenuation, even in adversarial environments.
Safe-Exploration-Enhanced RL: Critic Learning and Online Adaptation
The formulation leads to a zero-sum differential game described by a Hamilton-Jacobi-Isaacs (HJI) PDE, which admits no closed-form solution in general nonlinear settings. The framework adopts a neural network-based critic parameterization and a concurrent least-squares-based online adaptation law to minimize the Hamiltonian error, supported by safe exploration via the safeguarding-augmented system. Critic convergence is accelerated through persistent excitation ensured by the tangential input and safe system rollouts.
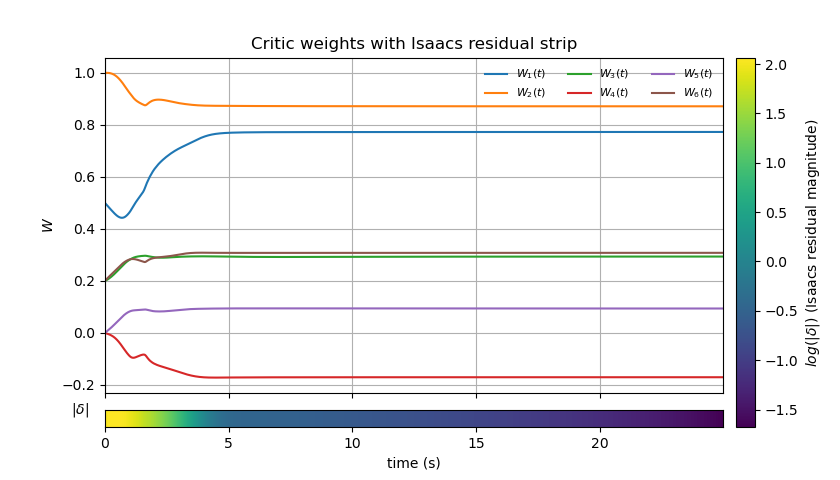
Figure 6: Critic weight evolution and Isaacs residual strip showing rapid learning and convergence under the safe RL regime.
The stability analysis confirms uniform ultimate boundedness of the joint state and critic, contingent upon satisfaction of a relaxed persistent excitation and bounded basis selection—now attainable by construction via safe exploration.
Empirical Validation and Trade-Offs
Simulations cover a spectrum of systems—2D integrators in nonconvex safe sets, disturbed relative-degree-one systems, and high-relative-degree mobile robots (planar double integrator) navigating obstacle-rich "minefields." Empirical results show the following:
- Tangential excitation prevents local trapping and enhances critic learning, even under weak safeguarding gains.
- Adaptive, state-dependent uo3 regulation allows aggressive safeguarding near constraints without persistent over-conservatism (see trajectory coloring in Figure 7).
- Barrier-compensated high-order safe sets provide strict forward invariance in the presence of disturbances, in contrast to conventional high-order CBFs.
- Safe RL enables real-time adaptation, robustness, and performance in complex, nonlinear, and disturbed environments.
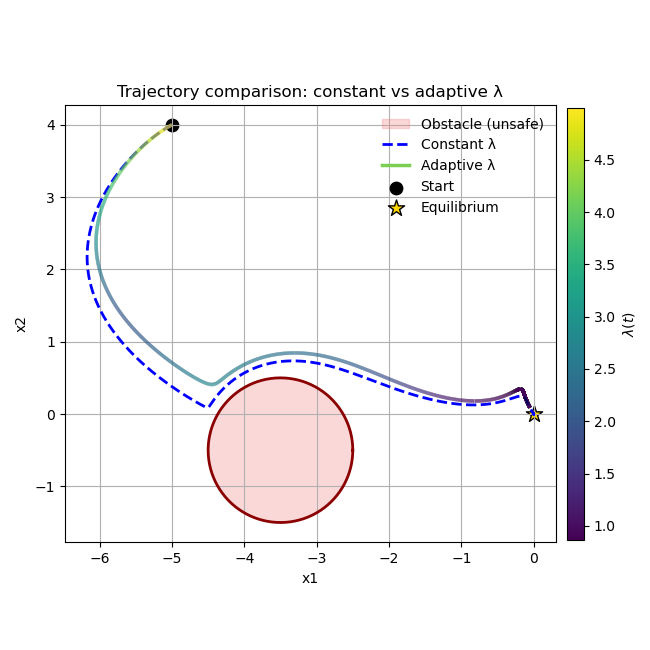
Figure 7: Trajectory comparison between constant and adaptive uo4, with adaptive strategy exhibiting earlier and more effective avoidance.
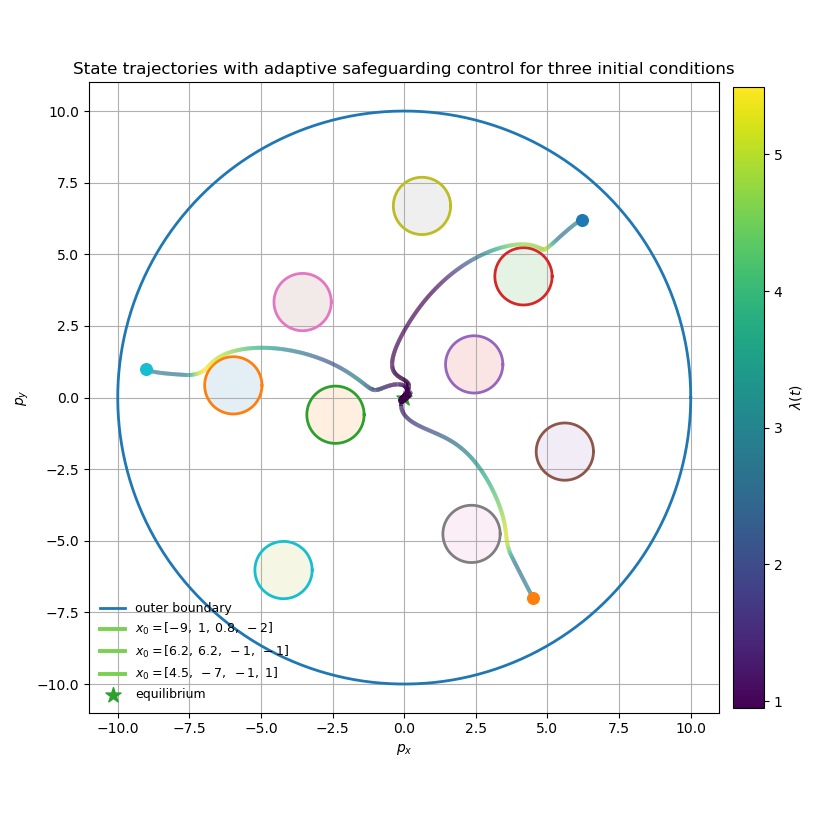
Figure 8: Minefield navigation for a high-relative-degree plant under flow-field disturbance; all trajectories maintain safety and converge toward objective.
Theoretical and Practical Implications
This framework demonstrates a principled synthesis of robust safety and infinite-horizon performance through system extension and barrier regulation. The adoption of tangential excitation as an admissible disturbance simultaneously enhances RL data richness and avoids well-documented failures of myopic filtering. The robust high-order safe-set extension is directly applicable to underactuated and multi-constraint robotic and aerospace systems.
Practically, the methodology is amenable to real-time, data-driven deployment scenarios where system dynamics are only partially known and where strict safety is non-negotiable. The architecture also naturally integrates with modern actor-critic RL paradigms, extending their safe applicability into domains characterized by nonlinearity, disturbances, and high relative degree.
Future Directions
Future work should address state-uncertainty-induced safety degradation, improve offline critic pre-training to reduce reliance on tangential excitation during deployment, and investigate further generalizations to partially observable or hybrid dynamical systems.
Conclusion
The paper presents a holistic, theoretically grounded, and practically validated approach for synthesizing strict safety within infinite-horizon optimal control for disturbed high-relative-degree nonlinear systems. Through barrier-regulated auxiliary variables, robust high-order safe sets, adaptive tangential excitation, and safe RL-based online critic learning, the framework advances the capacity of optimal control architectures to deliver both long-term performance and non-myopic safety guarantees in uncertain, dynamic environments.

