- The paper introduces HIFQL, replacing unimodal Gaussian policies with expressive mean flow models for hierarchical subgoal and action planning in offline GCRL.
- It leverages a LeJEPA-based encoder to generate robust, well-conditioned goal embeddings, with regularization ensuring stable training in high-dimensional settings.
- Empirical results on the OGBench benchmark demonstrate efficient one-step inference and strong performance in pixel-based and long-horizon tasks.
Efficient Hierarchical Implicit Flow Q-Learning for Offline Goal-conditioned Reinforcement Learning
Introduction
Offline goal-conditioned reinforcement learning (GCRL) aims to train agents to reach arbitrary goals utilizing only fixed, unlabeled static datasets—without further environmental interaction. A central challenge in offline GCRL is long-horizon planning: learning policies capable of reaching target states across extended temporal windows, given the high-variance structure of reward-free data and complex, often multimodal, action distributions. Existing hierarchical methods such as HIQL employ unimodal Gaussian policies, which are fundamentally limited in capacity and fail to model the behavioral richness captured in large-scale datasets.
This paper presents Hierarchical Implicit Flow Q-Learning (HIFQL), a hierarchical, mean flow-based architecture with expressive generative policies at both the subgoal and action levels, trained and deployed in a single step without iterative sampling. HIFQL incorporates a LeJEPA-based goal representation encoder to enforce well-conditioned, discriminative embeddings, which are particularly critical for subgoal generation in high-dimensional, pixel-based environments. HIFQL achieves strong empirical results on the OGBench benchmark, especially in settings demanding multimodal and long-horizon reasoning.
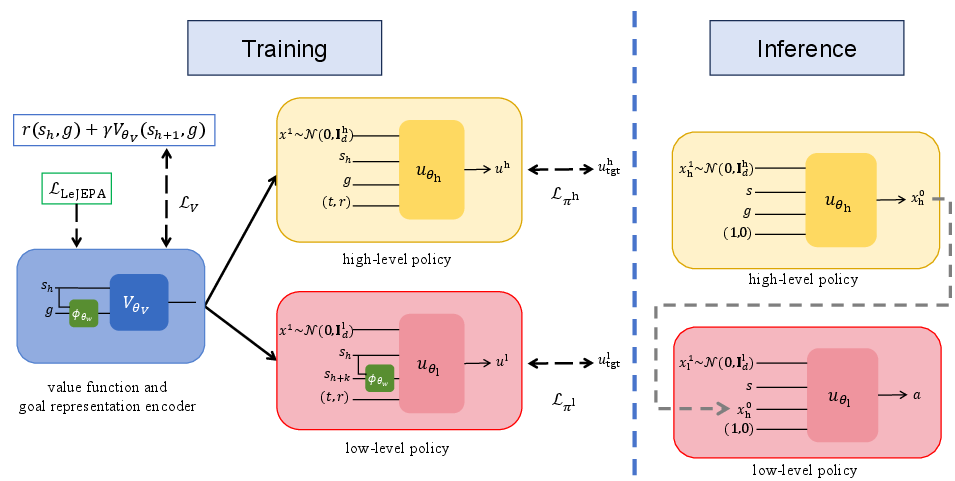
Figure 1: Overview of the HIFQL architecture, training the goal-conditioned value function and shared goal encoder, with high- and low-level mean flow policies. Inference is one-step from Gaussian noise for both levels.
Methodology
Mean Flow Policies for Hierarchical GCRL
HIFQL advances hierarchical modeling by replacing both high- and low-level Gaussian policies with mean flow models, which deterministically transport noise to complex target distributions via a learned average velocity field. The approach is inspired by recent advances in generative modeling, where mean flow enables one-step generation with significantly reduced computational complexity compared to standard flow/diffusion-based policy models.
Specifically, the high-level mean flow policy produces subgoal embeddings conditioned on the current state and task goal, while the low-level policy generates actions toward these subgoals. This joint mean flow architecture supports efficient and expressive modeling of multimodal behavior, critical for stitching disjoint trajectory segments and navigation under significant behavioral uncertainty.
LeJEPA-based Goal Representation Encoder
Hierarchical GCRL, especially in visual domains, is bottlenecked by the quality of goal representations. HIFQL integrates a LeJEPA-based encoder, leveraging objectives from the JEPA literature to produce semantically consistent and statistically well-conditioned goal embeddings. The learning objective combines a multi-view prediction loss enforcing invariant latent structure with a Sketch Isotropic Gaussian Regularization (SIGReg) ensuring global distributional regularity.
An ablation study (see below) demonstrates the critical importance of the regularization coefficient λ: omitting this term causes drastic performance drops and instability in high-dimensional settings, corroborating the necessity of regularized representation learning.
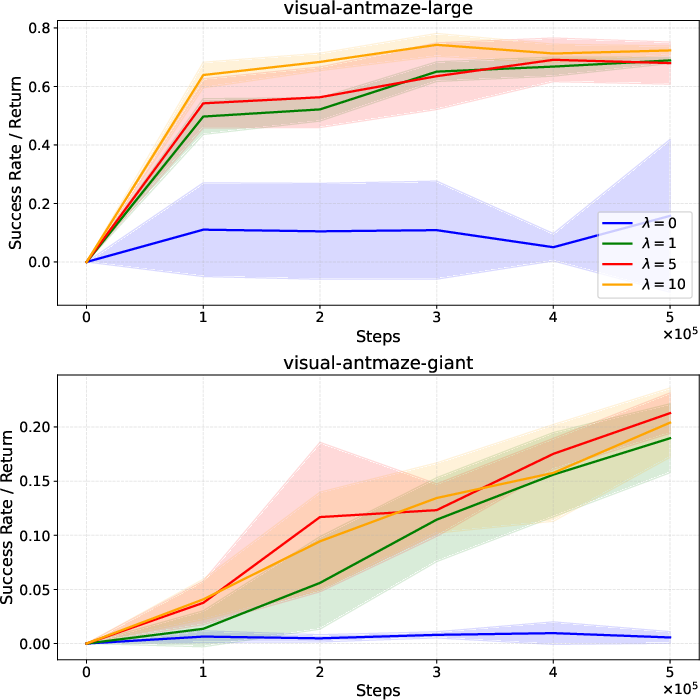
Figure 2: Ablation study indicates the necessity of non-zero λ for stable and high final scores in visual AntMaze tasks.
Training and Inference Procedure
HIFQL jointly optimizes the value function and goal encoder using expectile regression combined with LeJEPA regularization. The policy parameters are updated via a weighted mean flow regression objective, where weighting is provided by advantage estimates from the value critic, following the AWR paradigm. All flow networks are trained end-to-end using standard stochastic optimization, with target values and regularization derived efficiently using Jacobian-vector products.
At inference, both high-level (subgoal) and low-level (action) policies require only a single step of noise generation and deterministic transport, yielding orders-of-magnitude faster policy deployment relative to iterative flow-based sampling.
Empirical Results
State-based Tasks
On the OGBench suite's Maze environments—including PointMaze, AntMaze, and HumanoidMaze—HIFQL achieves the highest success rates in PointMaze settings, particularly in large-scale and stitching tasks that demand robust handling of multi-modal and long-horizon dependencies. This empirically substantiates the advantage of expressive, one-step flow models for planning in settings where high-level reasoning is the main bottleneck. However, in AntMaze and HumanoidMaze environments, where performance is more strongly constrained by low-level locomotion and complex contact physics, HIFQL does not consistently surpass HIQL, indicating the diminishing returns of increased high-level policy expressivity in these domains.
Pixel-based Tasks and Representation Regularization
On pixel-based AntMaze tasks, HIFQL outperforms HIQL in environments where the challenge primarily stems from high-dimensional goal representation and long-horizon planning. The empirical ablation (Figure 2) demonstrates that explicit representation regularization is essential: without it, hierarchical planning in pixel-based tasks becomes unreliable and learns suboptimal policies.
Theoretical and Practical Implications
The primary implication of HIFQL is that expressive, one-step generative models can effectively address the intrinsic limitations of Gaussian-based hierarchical policies in offline GCRL. The joint use of mean flow and learned goal representations enables accurate subgoal deduction and action selection in complex, long-horizon, and multimodal settings.
Practically, the method is well suited for deployment in compute-constrained or latency-sensitive scenarios, as the one-step sampling circumvents the prohibitive rollout costs of classical diffusion/flow-based methods. Theoretically, the results suggest that advanced generative modeling techniques (especially those from mean flow literature) transfer directly to hierarchical RL with strong benefits whenever high-level planning is a primary source of error, but not when low-level control dominates performance.
Future Directions
One limitation of HIFQL is in domains requiring highly complex action synthesis under physical constraints, where low-level policy constraints, rather than high-level expressivity, are dominant. Future work may explore hybrid architectures combining expressive high-level planners with specialized low-level controllers or integrating trajectory-centric regularization, as well as investigating more advanced goal representations to further close the gap on challenging visual domains.
Conclusion
HIFQL proposes an efficient, expressive, and practical approach for hierarchical policy learning in offline goal-conditioned RL, addressing major shortcomings of previous architectures. The joint adoption of mean flow policies and LeJEPA-based representations yields strong improvements for long-horizon, multimodal planning. However, gains are muted in environments dominated by low-level constraints, highlighting the need for continued research at the intersection of generative modeling and structured RL architectures.

