- The paper finds that structured behavioral scaffolding incurs significant coordination overhead, leading to lower document quality and submission rates.
- It demonstrates that cognitive scaffolding, through partnership training, increases the odds of achieving perfect outputs despite average score ceiling effects.
- The study highlights that intervention effectiveness depends on workflow fit, measurement methodology, and user mental model shifts.
Scaffolding Human–AI Collaboration: A Field Experiment on Behavioral Protocols and Cognitive Reframing
Introduction
This study systematically evaluates two distinct intervention paradigms for organizational human–AI collaboration: behavioral scaffolding, which imposes structured protocols on AI-mediated work, and cognitive scaffolding, which aims to reframe end-users' mental models through partnership-oriented training. Conducted as a randomized field experiment with 388 Gap Inc. employees, the research seeks to disentangle the process-level factors that modulate the effectiveness of generative AI adoption at scale—moving beyond simple access to AI toward the “how” of integration within actual workflows.
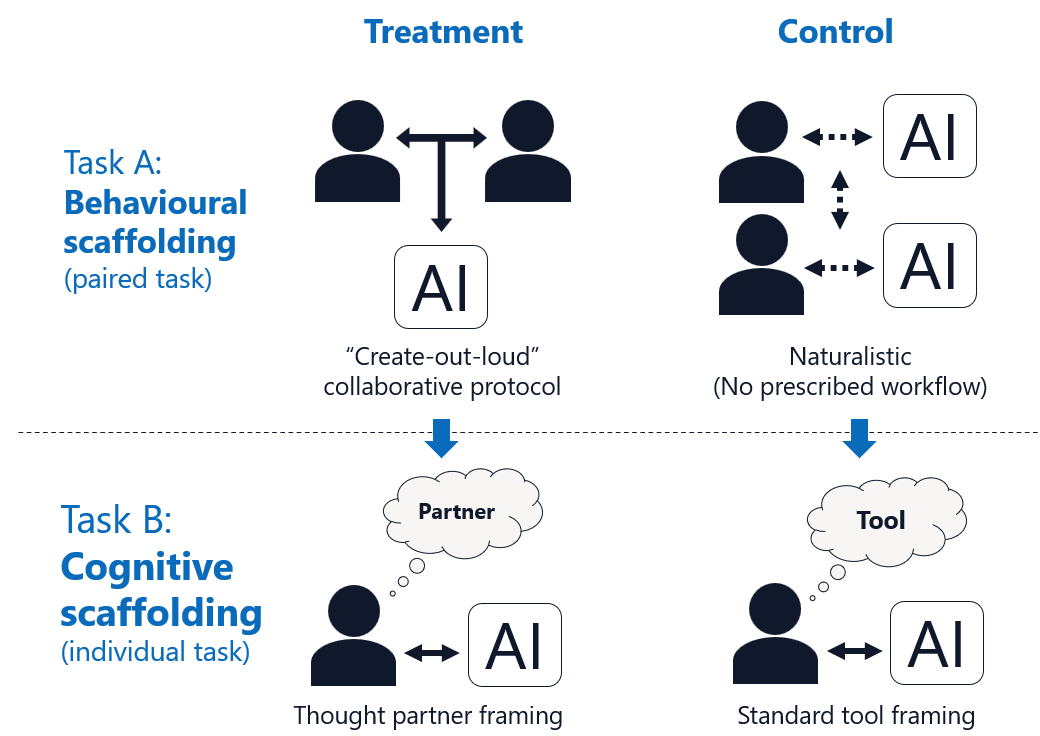
Figure 1: Experimental design contrasting behavioral and cognitive scaffolding in two sequential tasks with equivalent technical access across arms.
Experimental Design and Interventions
A pair-level stratified randomization assigned participants to either a treatment or control arm. Both arms had equal access to Microsoft Copilot. Task A (pair-based) measured the effects of a structured “Create-Out-Loud” protocol requiring synchronous joint AI use (treatment) versus naturalistic, unstructured AI use (control). Task B (individual-based) compared partnership training designed to reframe AI as a thought partner (treatment) against standard technical training (control). Primary outcomes included LLM-graded document quality, self-reported experience, and changes in beliefs regarding AI.
Key Results
Behavioral Scaffolding: Coordination Overhead and Output Degradation
Pairs subjected to the structured Create-Out-Loud protocol produced documents of significantly lower quality (mean difference −4.96, p<0.001) and with drastically reduced submission rates (OR =0.12) compared to unstructured controls. This effect was robust to worst-case attrition analyses (Lee bounds) and consistent across all rubric dimensions. Analyses revealed that word-count sensitivity of the LLM grader mediated approximately 33% of observed effects, but a significant quality gap persisted after controlling for document length.
Task A’s protocol imposed real-world coordination costs—synchronous scheduling, protocol compliance, and cognitive load for AI mediation without cross-organizational knowledge context—negating collaboration’s hypothesized aggregation benefits. Descriptive compliance subgroup analyses confirmed internal heterogeneity: even among those who fully implemented the protocol, documents fell short of controls, with “Parallel Play” subgroups performing worst.
The AM/PM session confound (control in the morning, treatment in the afternoon) was systematically tested: the treatment effect’s magnitude far exceeded plausible circadian or session-timing artifacts.
Cognitive Scaffolding: Partnership Framing and Top-End Output Shifts
For Task B, where individuals received partnership training, ITT analyses on continuous LLM-graded scores yielded no significant differences due to ceiling effects: 68% of participants, regardless of group, received maximum possible scores. However, a pre-registered exploratory binary analysis showed that treatment participants were significantly more likely to achieve perfect-quality outputs (OR =2.07, p=0.022), with effects consistent across high-scoring thresholds (18-20 out of 20).
Belief Change and Mental Models
Belief inventories administered post-task revealed greater positive change in “Exploration & Experimentation” beliefs among treatment subjects (BH-adjusted p=0.013), with analogous trends for composite scores (BH-adjusted p=0.047). However, ANCOVA models that adjusted for post-Task A baseline (already affected by protocol friction) suggested that observed shifts reflected recovery from prior negative experience, not direct training-induced reframing.
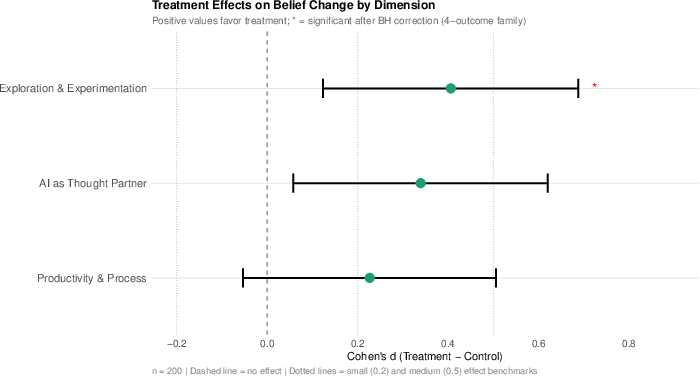
Figure 2: Treatment effects on belief change by dimension (Cohen's d), highlighting significance for the Exploration & Experimentation subscale.
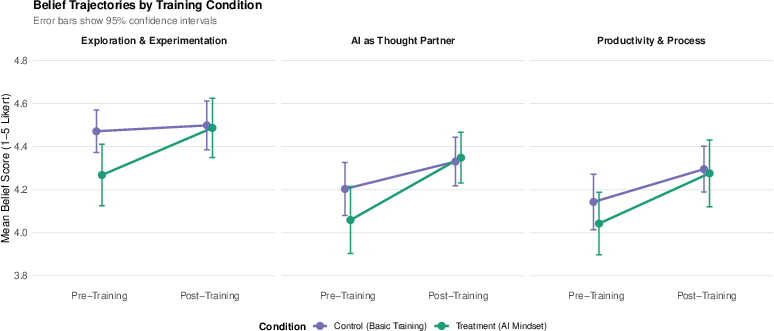
Figure 3: Belief trajectories show steeper gains for treatment, but low starting points due to Task A-induced friction.
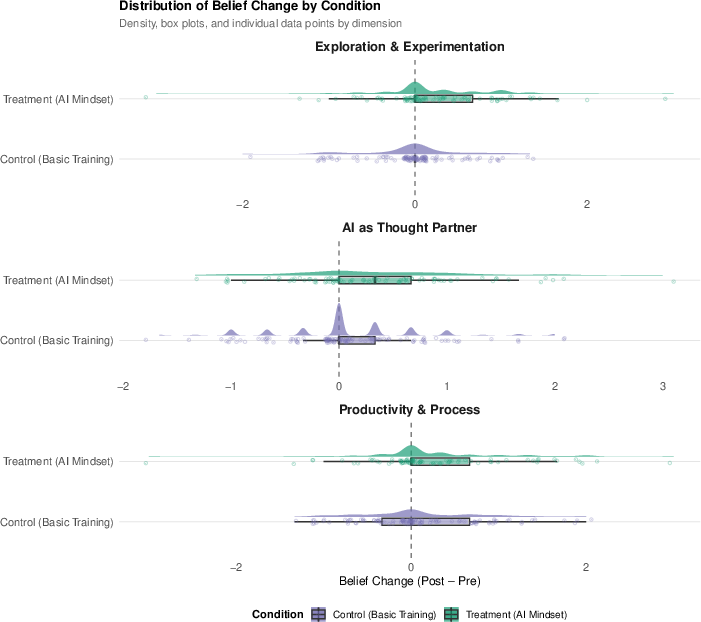
Figure 4: Distributional shifts in belief change by condition. Substantial spread and a positive skew for the treatment arm.
Heterogeneity and Robustness
No significant heterogeneity of treatment effects by prior AI experience was detected, and LLM-human grading validation revealed a consistent positive bias and word-count correlation. Symmetry across conditions minimized concern for differential grading artifacts.
Figure 5: Treatment effect heterogeneity by prior AI experience; no statistical divergence observed across strata.
Implications and Limitations
Theoretical and Organizational Implications
The results refute any blanket prescription for structured, protocol-driven collaborative AI deployment. In a typical enterprise setting characterized by uneven infrastructure and organic workflow norms, rigid behavioral scaffolding can introduce fatal coordination costs. This is congruent with socio-technical systems theory predictions: value emerges not purely from system capability but from fit between task demands, user interaction patterns, and supporting infrastructure.
Conversely, cognitive reframing interventions that shift engagement toward dialogicity (“AI as thought partner”) appear to selectively benefit high performers, at least at the distributional top end, even when average improvements are constrained by rubric saturation. This finding is consistent with the theoretical literature describing how frame alignment and “engaged augmentation” practices are necessary for realizing AI’s collaborative potential.
Methodological Contributions and Cautions
The study powerfully illustrates the transaction costs of protocol imposition, the hazards of ceiling effects in LLM-graded tasks, and the interpretive ambiguity introduced by post-treatment baselines and session confounds. Differential attrition—substantial in both primary tasks—necessitated robust bounding and mediation analyses. LLM grading exhibited prominent word-count sensitivity and positive calibration bias (but no condition asymmetry), and human validation confirmed rank preservation for open-ended strategic outputs.
The limitation of sequential task design, non-independence of belief baselines, and within-day learning transfer all restrict generalization. Furthermore, post-hoc adoption of binary analytic thresholds in response to measurement saturation, while justified, underlines the need for outcome metrics that better capture spectrum-level differences in AI-augmented work quality.
Future Directions
The evidence suggests the importance of piloting structured group protocols prior to organizational scale-up, customizing behavioral interventions to context, and prioritizing infrastructure robustness to minimize failed compliance. For cognitive scaffolding, future research should explore multi-turn, longitudinal reframing interventions and their durability, as well as interaction effects with varying levels of baseline digital literacy and AI exposure.
Advanced metrics for document quality that decouple verbosity from insight, and longitudinal measurement of attitudinal and performance shifts, will be critical to further elucidate mechanisms underlying effective human–AI collaboration.
Conclusion
This field experiment demonstrates that how organizations scaffold human–AI collaboration is consequential, but not all interventions are beneficial. Protocol-driven coordination may reduce both output rate and quality in realistic, friction-prone work environments, while mental-model reframing can enhance the likelihood of top-tier output—but predominantly for those already operating near the top of the evaluative scale. The nuanced findings place clear boundaries on the generalizability of intervention effectiveness. Task and infrastructure fit, compliance feasibility, and metric selection are essential determinants for the success of human–AI collaborative scaffolding strategies.

