- The paper introduces hdpocolor, a novel RL protocol that decouples accuracy and efficiency rewards to overcome blind tool invocation.
- It employs a dual-stage training pipeline combining supervised fine-tuning and RL to enforce execution fidelity and strategic tool use.
- Empirical results show that metiscolor drastically reduces tool calls while improving accuracy across high-resolution and complex reasoning tasks.
Motivation and Problem Analysis
The proliferation of agentic multimodal LLMs (MLLMs) has substantially advanced the state of active visual reasoning across a diverse set of tasks. These systems increasingly operate via multi-turn interaction with external tools, combining parametric knowledge with code execution, web search, and visual retrieval. However, these agentic frameworks are typically afflicted by a fundamental meta-cognitive deficit: an inability to strategically arbitrate between direct, model-based reasoning and external tool invocation. This deficit manifests empirically as excessive, reflexive tool use—"blind tool invocation"—which introduces significant computational inefficiency and injects environmental noise, degrading ultimate task performance.
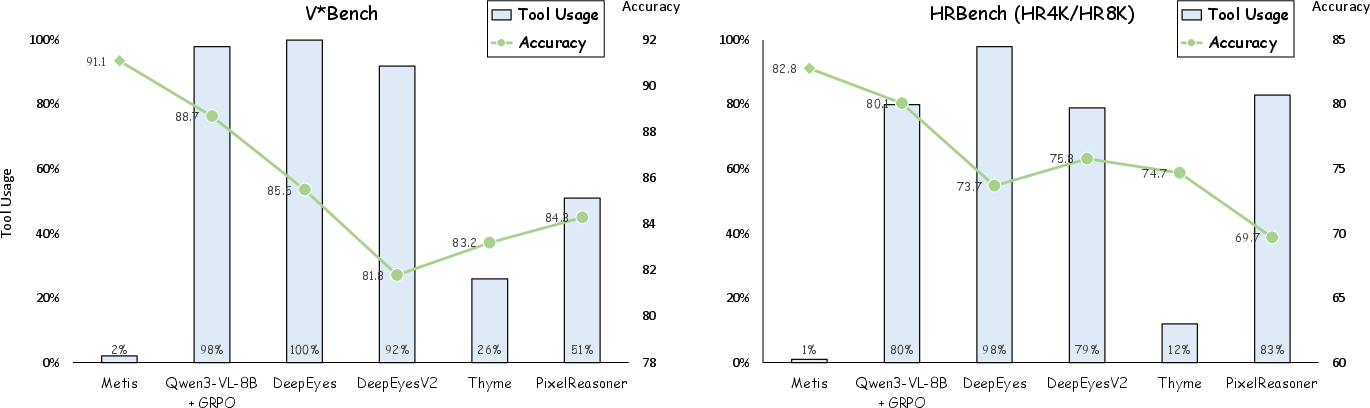
Figure 1: Comparison of tool-use efficiency and task performance. Existing methods rely heavily on tool calls, reflecting limited efficiency awareness. In contrast, our method uses tools far more selectively while achieving the best overall performance, showing that strong accuracy and high efficiency can be attained simultaneously.
Current RL-based optimization protocols for agentic MLLMs predominantly penalize tool usage via a scalarized reward coupled with accuracy, thus creating an inherent optimization dilemma: strong penalties reduce tool overuse but suppress necessary tool calls on difficult tasks, while mild penalties are overwhelmed by the variance of the accuracy signal during advantage normalization. This reward coupling leads to gradient entanglement, semantic ambiguity (confounding efficient-but-incorrect and inefficient-but-correct trajectories), and hyperparameter fragility driven by non-stationary objective covariance.
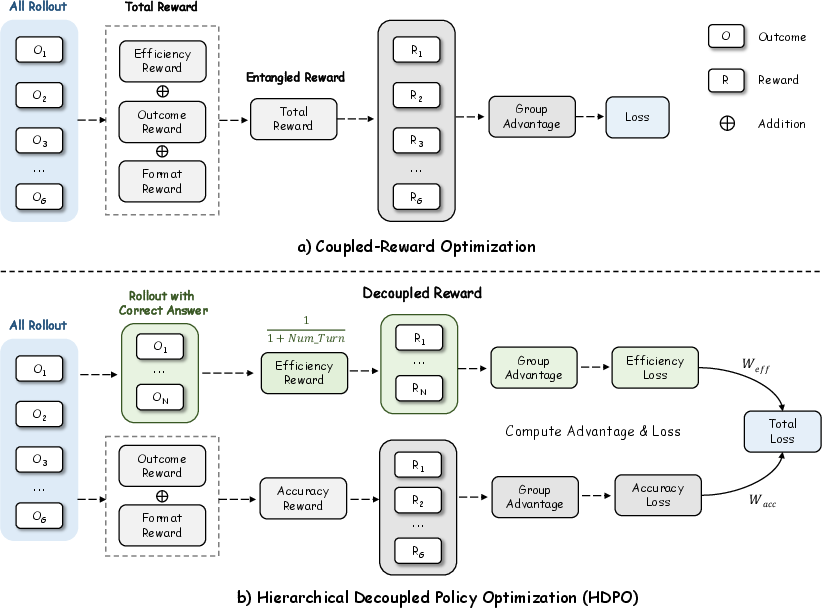
Figure 2: Comparison between coupled-reward optimization and hdpocolor. Existing methods entangle accuracy and efficiency into a single reward signal, while hdpocolor decouples them into separate branches and combines them only at the final loss, enabling more strategic tool use.
The hdpocolor Framework
The paper introduces Hierarchical Decoupled Policy Optimization (hdpocolor), which eschews the single-channel, scalarized reward in favor of two orthogonal optimization branches: a global accuracy channel and an efficiency channel conditioned strictly on accurate trajectories. The accuracy channel maximizes correct completion across all rollouts, while the efficiency channel penalizes tool use only among correct solutions, computed with a conditional advantage relative exclusively to successful trajectories.
This decomposition induces a natural cognitive curriculum. The agent first learns to prioritize correctness; only upon attaining reliable task resolution does it begin to optimize for tool parsimony. Gradient interference between task completion and latency reduction is eliminated. The efficiency reward is strictly monotonic in the number of tool calls and, critically, delivers feedback only when extrinsic reasoning is genuinely required.
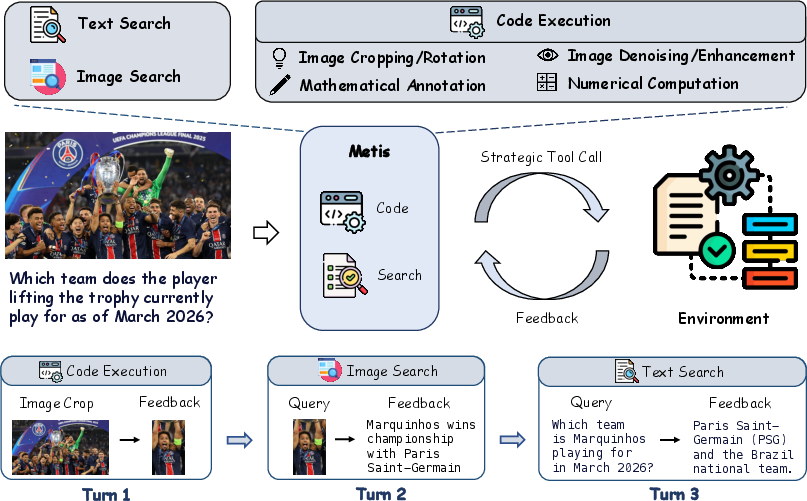
Figure 3: Overview of metiscolor. A strategic multimodal reasoning agent that selectively invokes code execution, text search, and image search tools during multi-turn reasoning. Rather than invoking tools by default, metiscolor adaptively determines when tool interactions provide genuinely useful evidence, and otherwise reasons directly from the available context to obtain the final answer.
System Implementation: metiscolor
Building on hdpocolor, the authors implement metiscolor, a strategic agentic MLLM based on Qwen3-VL-8B. metiscolor is equipped with code execution, text, and image search tools, and is trained through a dual-stage pipeline: rigorous curation for both supervised fine-tuning (SFT) and RL, including execution fidelity checks, solvability filtering, and meta-cognitive quality enforcement. Data with hallucinated environmental dynamics, or with tool use rendered unnecessary due to increased model capacity, is aggressively filtered from both SFT and RL phases.
Empirical Evaluation
Benchmarking is conducted across a spectrum of perception, document understanding, and mathematical reasoning tasks. metiscolor achieves orders-of-magnitude reduction in tool usage rates (e.g., from 98% to 2%) compared to standard agentic RL baselines, while simultaneously elevating accuracy on all high-resolution and complex reasoning benchmarks. For instance, on HRBench-8K, metiscolor delivers 82.0% accuracy, outperforming all 8B and 30B competitors, and yields a +26.4% absolute improvement on WeMath over its backbone.
Ablations confirm that the decoupled efficiency channel not only drastically reduces superfluous tool use but also acts as a catalyst for enhanced core reasoning accuracy—even on previously adversarial trade-offs. The optimal efficiency loss weight (0.15) sharply delineates the boundary between productive parsimony and necessary tool usage.
Qualitative Case Analysis
Representative cases illustrate the learned meta-cognitive arbitration boundary. When queries are resolvable from visual context, the agent abstains from tool invocation:

Figure 4: Direct reasoning from visual context. The query can be resolved through visual understanding and prior knowledge alone. metiscolor abstains from tool invocation and answers directly, exemplifying the meta-cognitive restraint instilled by hdpocolor.
In cases of visual ambiguity or computational necessity, metiscolor strategically invokes tools:
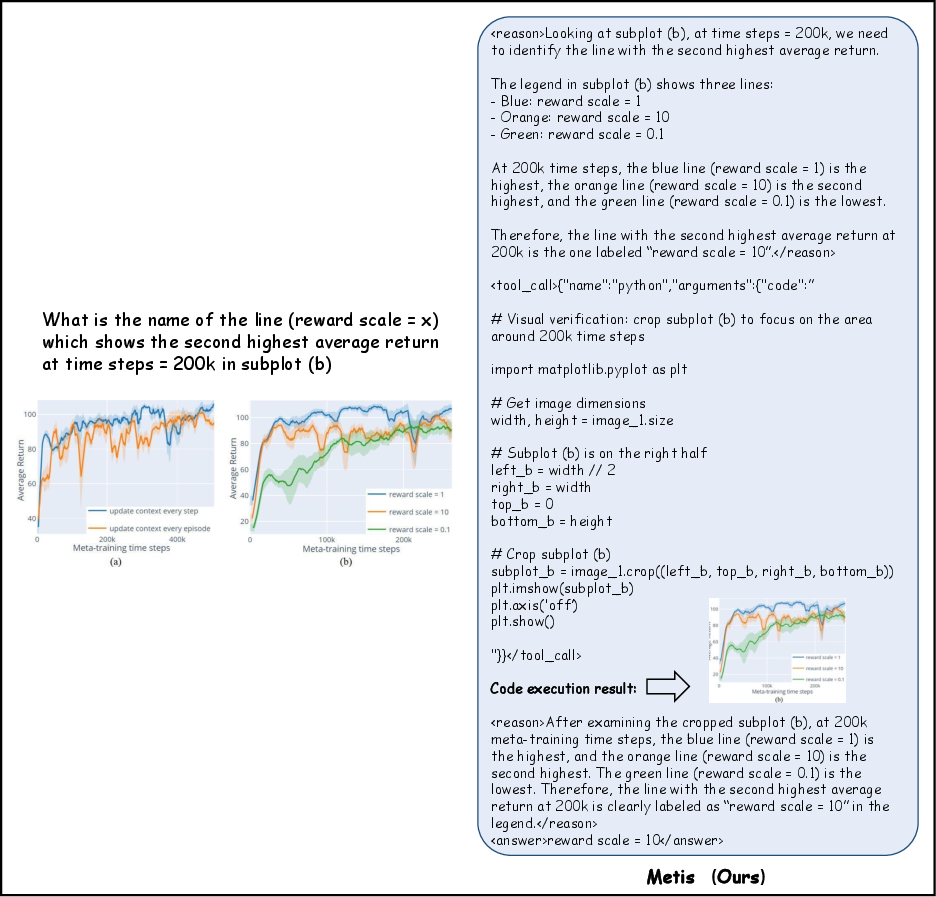
Figure 5: Targeted code execution for fine-grained visual analysis. The question requires comparing curves in a specific subplot region that is difficult to resolve at the original image scale. metiscolor invokes code to crop and enlarge the relevant area, enabling precise identification of the curve behavior near the queried time step.
Further, the agent invokes text or image search tools only when direct evidence is unavailable:

Figure 6: Direct reasoning from visual inspection. The on-screen text is clearly legible from the raw image. metiscolor correctly extracts the answer without invoking code execution or search tools, avoiding unnecessary computational overhead.

Figure 7: Strategic image search for visual identification. The artwork cannot be reliably identified from visual features alone. metiscolor invokes image search to match the visual content against external references, then retrieves the completion year from the search results.
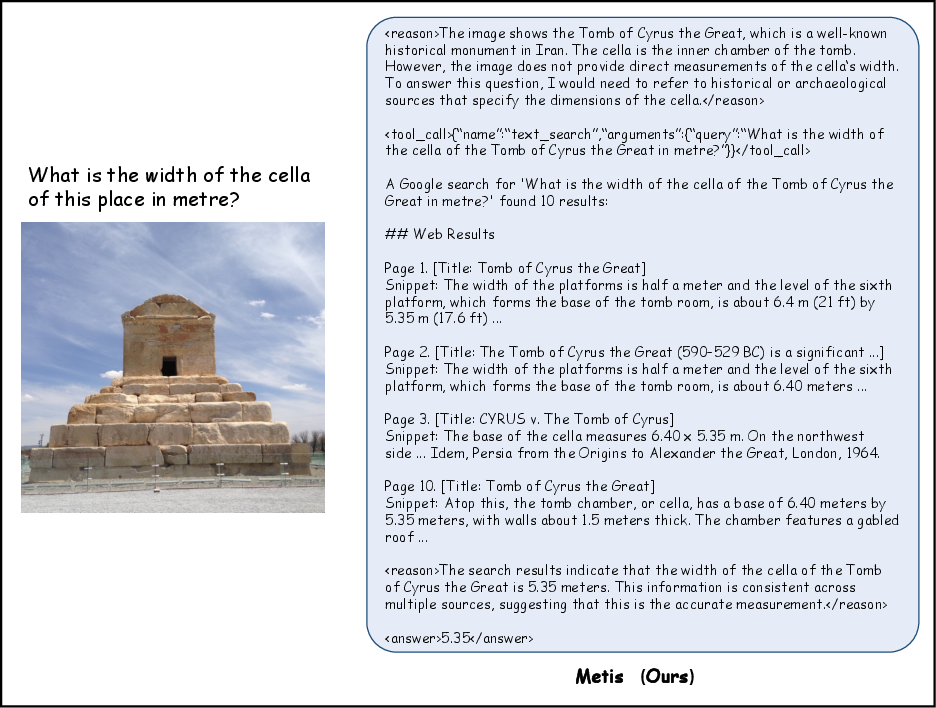
Figure 8: Strategic text search for factual knowledge. While the monument is visually identifiable, the queried measurement (cella width) cannot be inferred from the image. metiscolor recognizes this epistemic gap and invokes text search to retrieve the precise factual information from external sources.
Implications and Future Directions
The results definitively demonstrate that strong accuracy and high efficiency are not only achievable but synergistic: aggressive suppression of noisy tool calls drives, rather than compromises, state-of-the-art task completion in high-resolution and cross-modal scenarios. Theoretically, the strict decomposition of conditional advantage estimation provides a clear path for reliable credit assignment in multi-objective RL for agentic systems. Practically, the results have immediate implications for latency-sensitive, real-world deployments—enabling high-performance, scalable agentic models that abstain from computational redundancy and unnecessary environment interaction.
Future research directions include extending meta-cognitive arbitration to more open-ended, long-horizon reasoning, dynamic multi-agent collaboration, and the design of more granular introspective uncertainty estimation frameworks for both tool selection and answer abstention. The hdpocolor paradigm provides a powerful template for orthogonal credit assignment in agentic and embodied intelligence.
Conclusion
This work systematically diagnoses and remedies the blind tool invocation pathology in agentic multimodal models by introducing a hierarchically decoupled RL protocol. The metiscolor system, trained via hdpocolor, establishes that meta-cognitive tool reasoning—knowing when to abstain as well as when to act—leads to both quantitative and qualitative improvements in agentic intelligence. This challenges prevailing latency-agnostic tool-augmentation practices and establishes a new foundation for efficiency-aware agentic decision making in complex multimodal environments.

