- The paper introduces PokeGym, a benchmark that evaluates embodied VLMs in a realistic 3D game environment using raw RGB observations and automated AOB memory scanning.
- The experimental evaluation reveals that models like Gemini-3-Pro significantly improve in semantic reasoning with guided instructions, demonstrating the impact of prompt design on success rates.
- The benchmark identifies deadlock recovery as the primary bottleneck, highlighting the need for enhanced spatial intuition, collision reasoning, and adaptive long-horizon control in VLMs.
PokeGym: A Visually-Driven Long-Horizon Benchmark for Vision-LLMs
Benchmark Motivation and Design
PokeGym establishes a new standard for evaluating embodied Vision-LLMs (VLMs) by targeting the limitations observed in prior benchmarks—namely, over-reliance on passive perception, trivial 2D environments, privileged state leakage, and expensive human evaluation. PokeGym is instantiated within Pokémon Legends: Z-A, offering a visually complex and structurally nuanced 3D open-world game environment. The benchmark enforces strict separation between agent and evaluator at the code level, ensuring agents operate solely on raw RGB visual observations, while success verification is performed by an independent evaluator using AOB memory scanning, thus precluding state leakage and enabling scalable, automated assessment.
PokeGym comprises 30 tasks (path lengths 30–220 steps) derived from 10 quests, spanning navigation, interaction, and mixed scenarios. Tasks are organized under three instruction granularities: Visual-Guided (explicit visual anchors), Step-Guided (procedural sub-goals), and Goal-Only (sparse objectives), enabling systematic dissection of visual grounding, semantic reasoning, and autonomous exploration. This design delivers a powerful diagnostic instrument for probing specific embodied VLM capabilities.
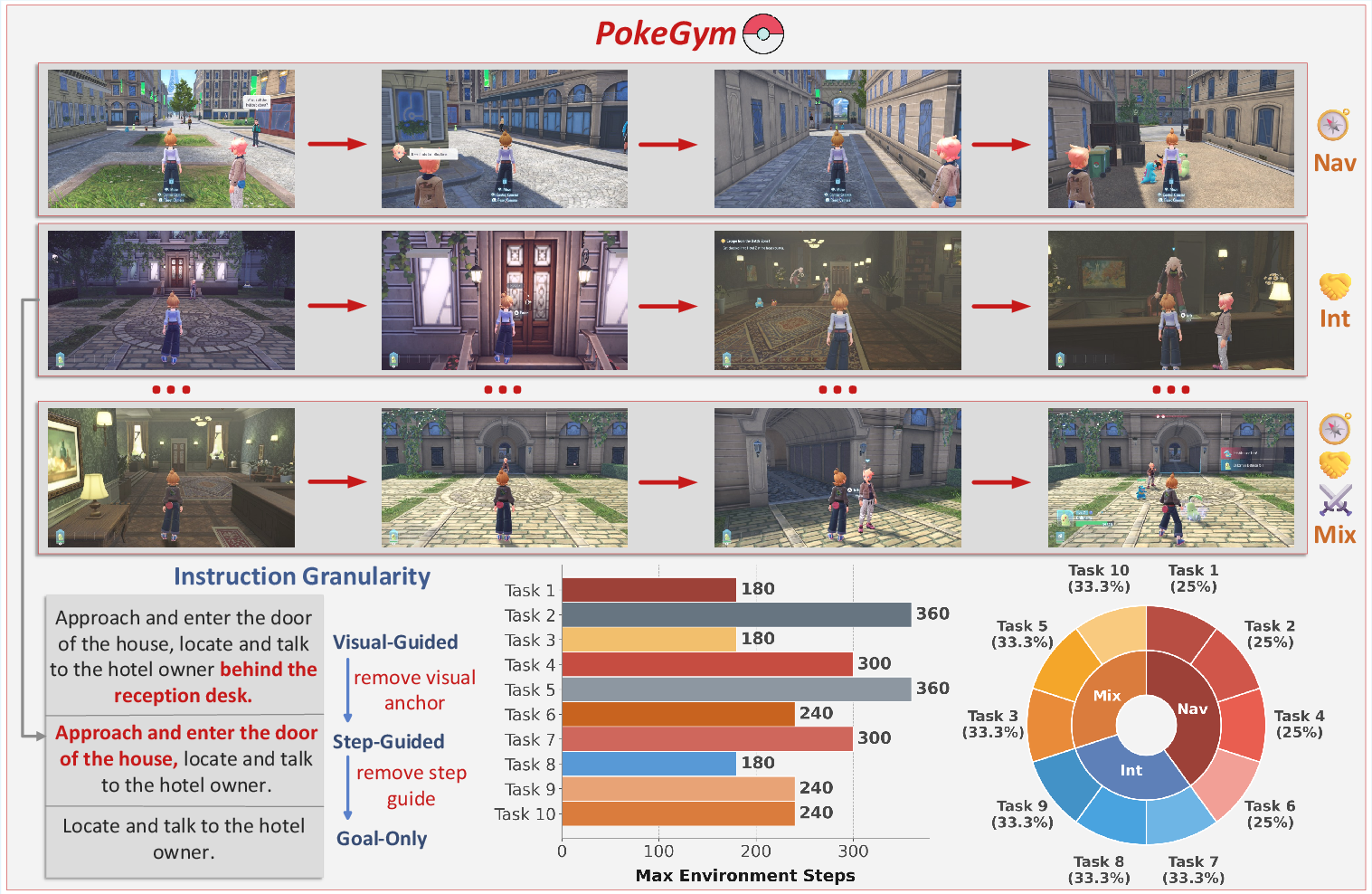
Figure 1: Visual trajectories for navigation, interaction, and mixed tasks; illustration of instruction granularities and step budgets for all quests.
System Architecture
PokeGym's architecture is modular and robust, comprising four main components: (i) a visual observation interface extracting RGB images directly from GPU textures, (ii) a VLM-based decision module supporting optional self-reflection, (iii) an action interface for both high-level and parametric controls, and (iv) an evaluator for progress tracking and success verification. Agents receive configurable visual contexts (including peripheral and temporal images), and action abstraction is decoupled from environment steps, allowing flexible control paradigms without confounding step budgets. Memory scanning ensures objective, automated evaluation.
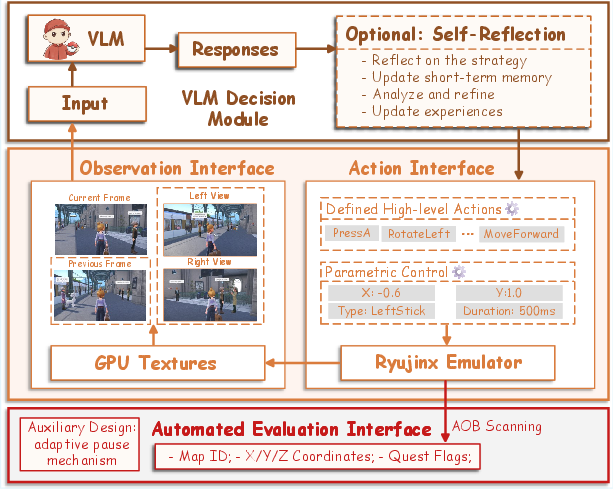
Figure 2: Architectural overview of the PokeGym benchmark, from observation to action and evaluation.
Experimental Evaluation and Model Capabilities
PokeGym is used to rigorously evaluate a suite of VLMs, both proprietary (e.g., Gemini-3-Pro, GPT-5.2, Claude-Sonnet-4.6) and open-weight (e.g., GLM-4.6V, Qwen3-VL-30B, Qwen3.5-Plus). The experiments differentiate models by embodied cognitive abilities—visual grounding, semantic reasoning, and long-horizon planning—across instruction granularities. Notably, Gemini-3-Pro outperforms other models in semantic reasoning (Step-Guided), demonstrating a jump in Success Rate (SR) from 44.45% (Visual-Guided) to 74.44% (Step-Guided). Closed-source models consistently exhibit higher SRs, particularly in interaction and mixed tasks, than their open-source counterparts.
Contradictory trends are identified: Gemini-3-Pro improves in navigation with reduced visual anchoring, while Qwen models degrade when explicit cues are removed, revealing varying dependencies on prompt design and grounding strategies.
Diagnosis of Physical Bottlenecks and Failure Types
Empirical analysis uncovers a primary physical bottleneck: deadlock recovery supersedes high-level planning as the failure mode restricting task success. Ineffective Moves (IM)—movement actions resulting in zero displacement due to collisions—show a strong negative Pearson correlation with Success Rate across all instruction granularities (r=−0.57 to r=−0.65, p<0.001).
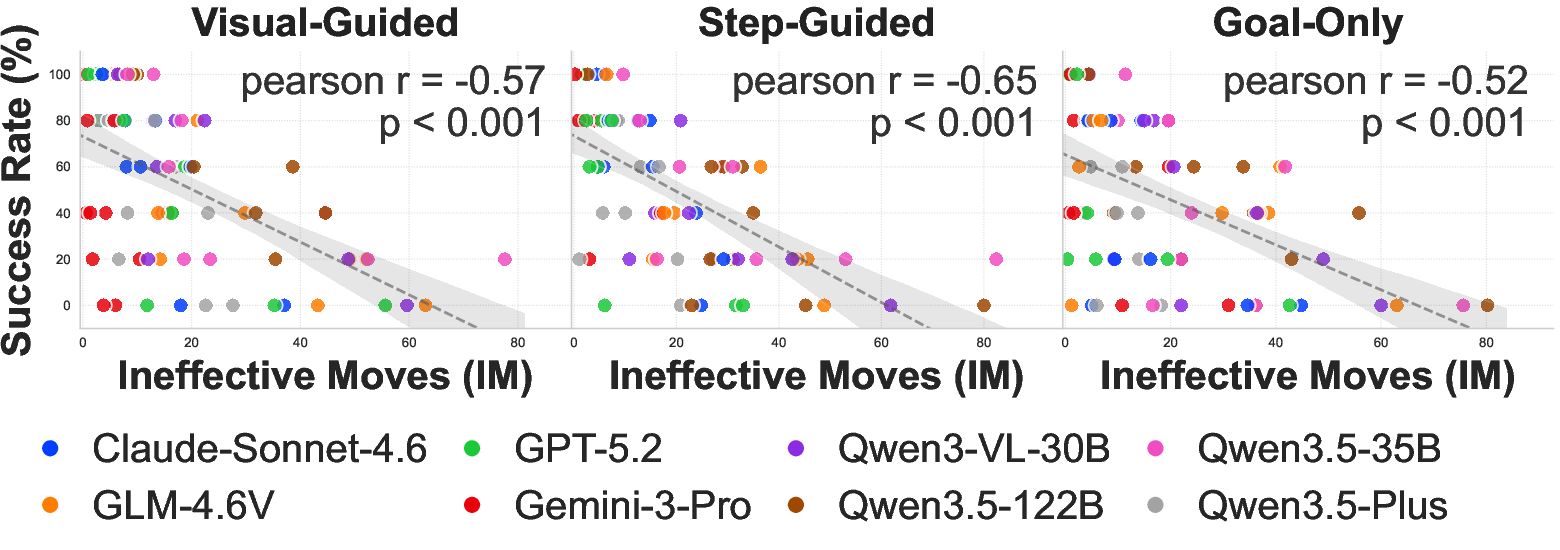
Figure 3: Linear correlation between task success rates and ineffective move rates across all tested VLMs, stratified by task.
Furthermore, a divergence emerges between weaker and stronger VLMs upon encountering deadlocks: weaker models tend to hallucinate progress (Unaware Deadlocks), while stronger models recognize entrapment but fail to recover (Aware Deadlocks), indicating a metacognitive divide. Case studies categorize failures into four types: Unaware Deadlock, Aware Deadlock, Lost, and Execution Failure, each defined by agent reasoning logs contrasted with objective states.
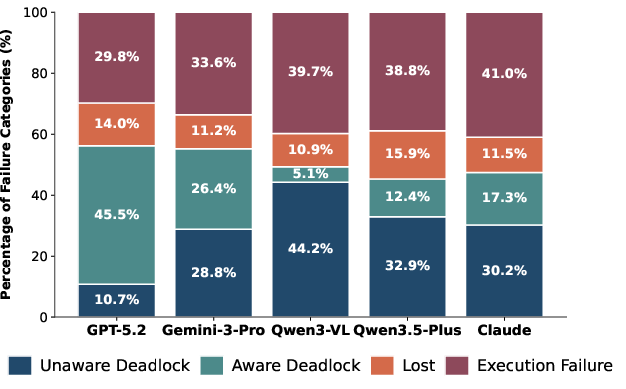
Figure 4: Proportions of each failure category across different VLM architectures.

Figure 5: Case studies exemplifying the four failure types: Unaware/Aware Deadlock, Lost, and Execution Failure.
Spatial and Visual Challenges
Unaware deadlocks are not randomly distributed; they correlate with recurring obstacle patterns that highlight limitations in traversability estimation, micro-geometry reasoning, and relevance judgment. Figures demonstrate tangible collision boundaries, agent locations, and corresponding reasoning errors, underscoring the need for explicit spatial intuition and robust grounded reasoning in future VLM designs.

Figure 6: Obstacle patterns associated with deadlocks, including actual collision boundaries and agent reasoning mismatches.
Qualitative trajectories and environmental complexity further emphasize the visual, spatial, and contextual diversity confronted by embodied agents, demanding not only semantic competence but persistent spatial memory, path planning, and error recovery.

Figure 7: Examples of environmental complexities in PokeGym: partial observability, ambiguous visual cues, lighting variability, topological intricacies, and dense element interactions.

Figure 8: Long-horizon trajectory exemplars spanning navigation, interaction, and mixed scenarios.
Cross-Benchmark Correlation and Comparative Analysis
Correlation studies reveal that PokeGym's dimensions are only partially aligned with established multimodal benchmarks. Interaction tasks show strong positive correlation with general multimodal benchmarks (MMMU-Pro, VideoMMMU, ScreenSpot-Pro), whereas Navigation and Visual-Guided settings remain poorly covered, suggesting that embodied navigation, spatial memory, and precise language-to-pixel grounding are largely orthogonal to current evaluation techniques.
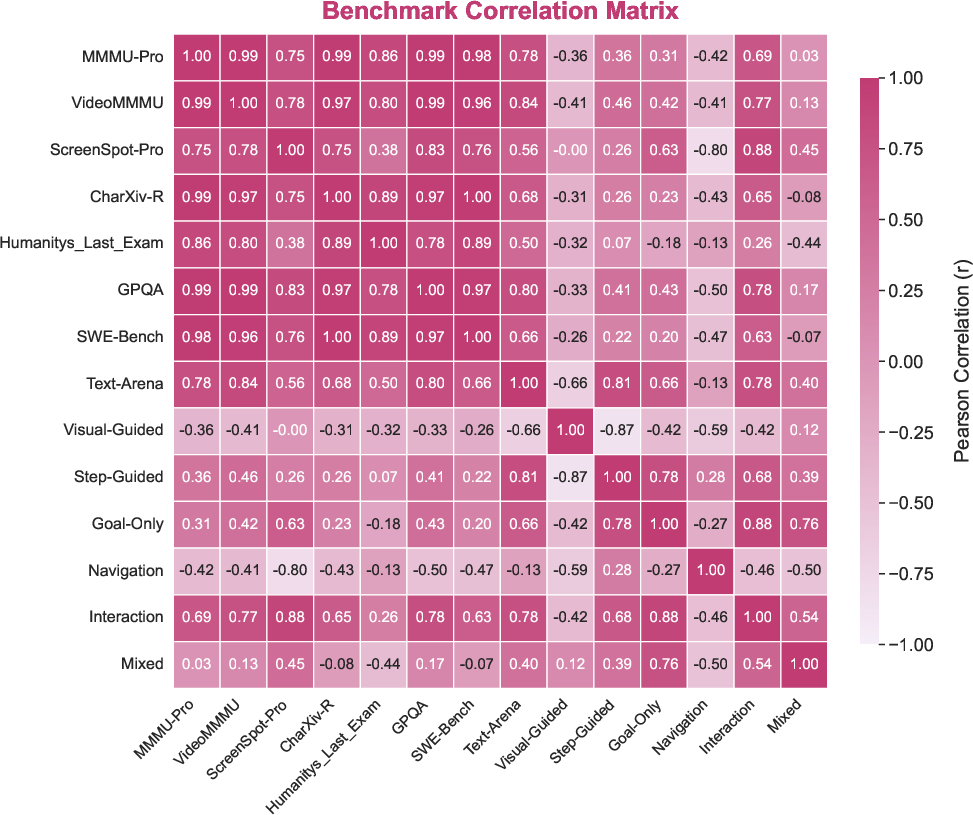
Figure 9: Cross-benchmark Pearson correlation matrix for leading VLMs against external benchmarks and PokeGym task categories.
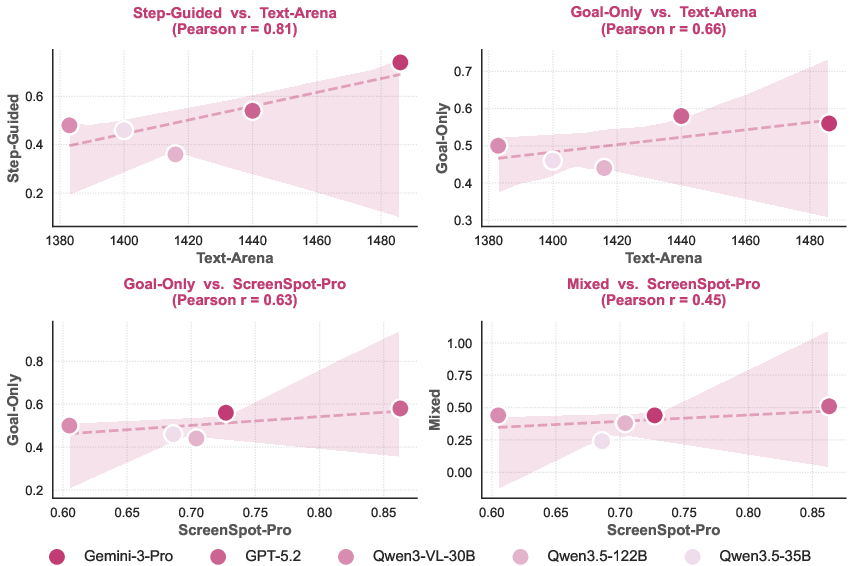
Figure 10: Scatter plots illustrating cross-domain correlations between PokeGym categories and external benchmarks.
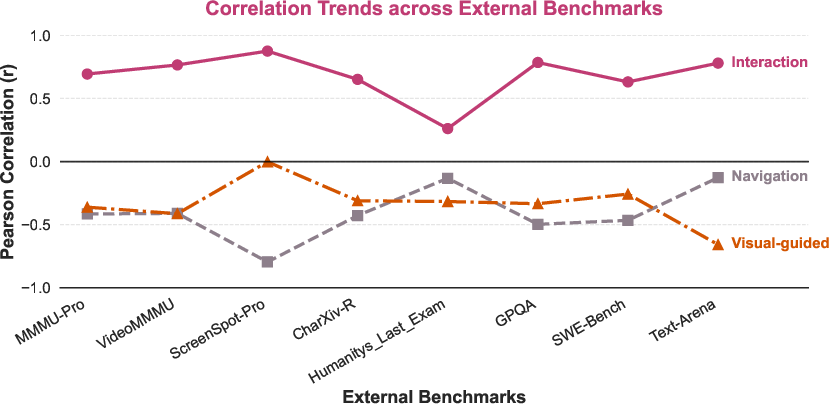
Figure 11: Trend analysis of correlation coefficients between PokeGym tasks and multiple external benchmarks.
Practical and Theoretical Implications
Automated evaluation using AOB memory scanning eliminates human subjectivity and annotation cost, setting a new standard for scalable, reproducible benchmarking of embodied agents. Fine-grained analysis exposes inherent weaknesses and capability gaps in VLMs, especially regarding spatial reasoning and physical recovery. The findings suggest that further architectural advances must incorporate explicit spatial modeling, multi-modal integration, and adaptive long-horizon control; prompt design and action abstraction emerge as leverage points for improving embodied planning. Practical extension of PokeGym to support auditory modalities, dense reward feedback, and agent training (RL/IL) will enable broader exploration and development of generalist agents.
Conclusion
PokeGym delivers a rigorous, visually-driven benchmark for embodied VLMs, resolving the tension between environmental realism and scalable automated evaluation. Analysis across diverse models establishes that physical deadlock recovery—not high-level planning—is the predominant barrier to successful embodied competence, necessitating integration of spatial intuition and collision reasoning into future architectures. Metacognitive divergence between model tiers in deadlock handling highlights the need for capability-specific bottleneck mitigation. The benchmark's comprehensive diagnostics and leaderboard establish a referential foundation for research in generalist AI agents operating in realistic, complex environments.