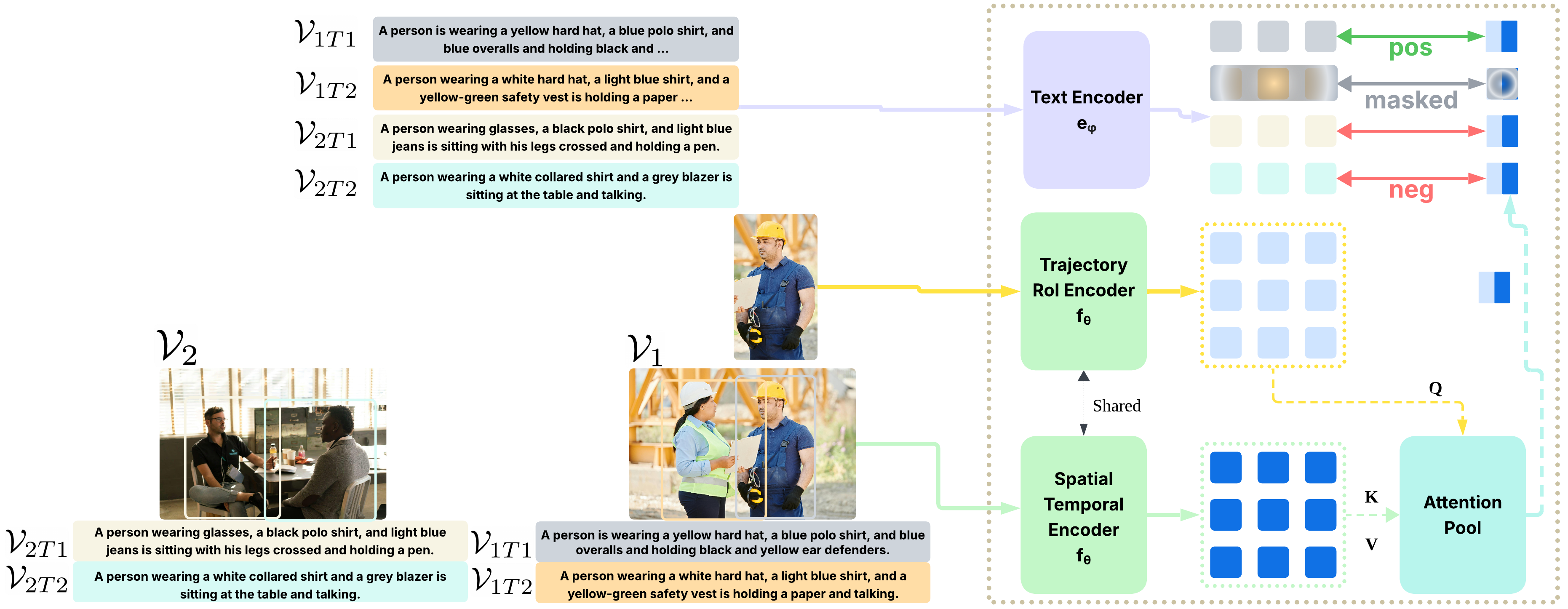
- The paper introduces an instance-aware pre-training framework that integrates both global and instance-level alignment to improve spatial-temporal understanding.
- It employs a teacher-student Vision Transformer with cross-attention mechanisms to fuse cropped instance features with full-context representations.
- Extensive experiments show significant gains, with notable improvements in retrieval metrics and IoU scores compared to traditional global-only methods.
Instance-Aware Vision-Language Pre-Training for Spatial-Temporal Understanding: An Analysis of InstAP
Introduction and Motivation
Despite significant advances in vision-language pre-training (VLP), most approaches are limited by their focus on coarse, global video-text alignments, an impediment for downstream tasks that demand precise grounding of textual mentions in spatio-temporal visual evidence. Such deficiencies inhibit the performance of VLP models in retrieval, video question answering, and spatial-temporal grounding tasks, where isolated instance disambiguation and localization are essential. The studied paper—"InstAP: Instance-Aware Vision-Language Pre-Train for Spatial-Temporal Understanding" (2604.08337)—directly addresses this bottleneck by introducing an instance-level alignment paradigm and a supporting large-scale, dual-granularity annotated dataset (InstVL).
InstVL Dataset: Design and Characteristics
The InstVL dataset is a novel contribution, comprising 2M images and 50K videos, developed to enable instance-aware VLP at scale. Each visual example is annotated with both holistic scene captions and multiple fine-grained descriptions, each precisely grounded to specific spatial regions or temporal trajectories. These instance annotations are generated using open-vocabulary detection (GroundingDINO), tracking (SAM2), and large vision-LLMs, with iterative manual quality control. Compared to Visual Genome or existing video datasets, InstVL provides much more linguistically diverse and temporally consistent instance grounding, overcoming the static, template-driven, or predicate-limited nature of prior resources.
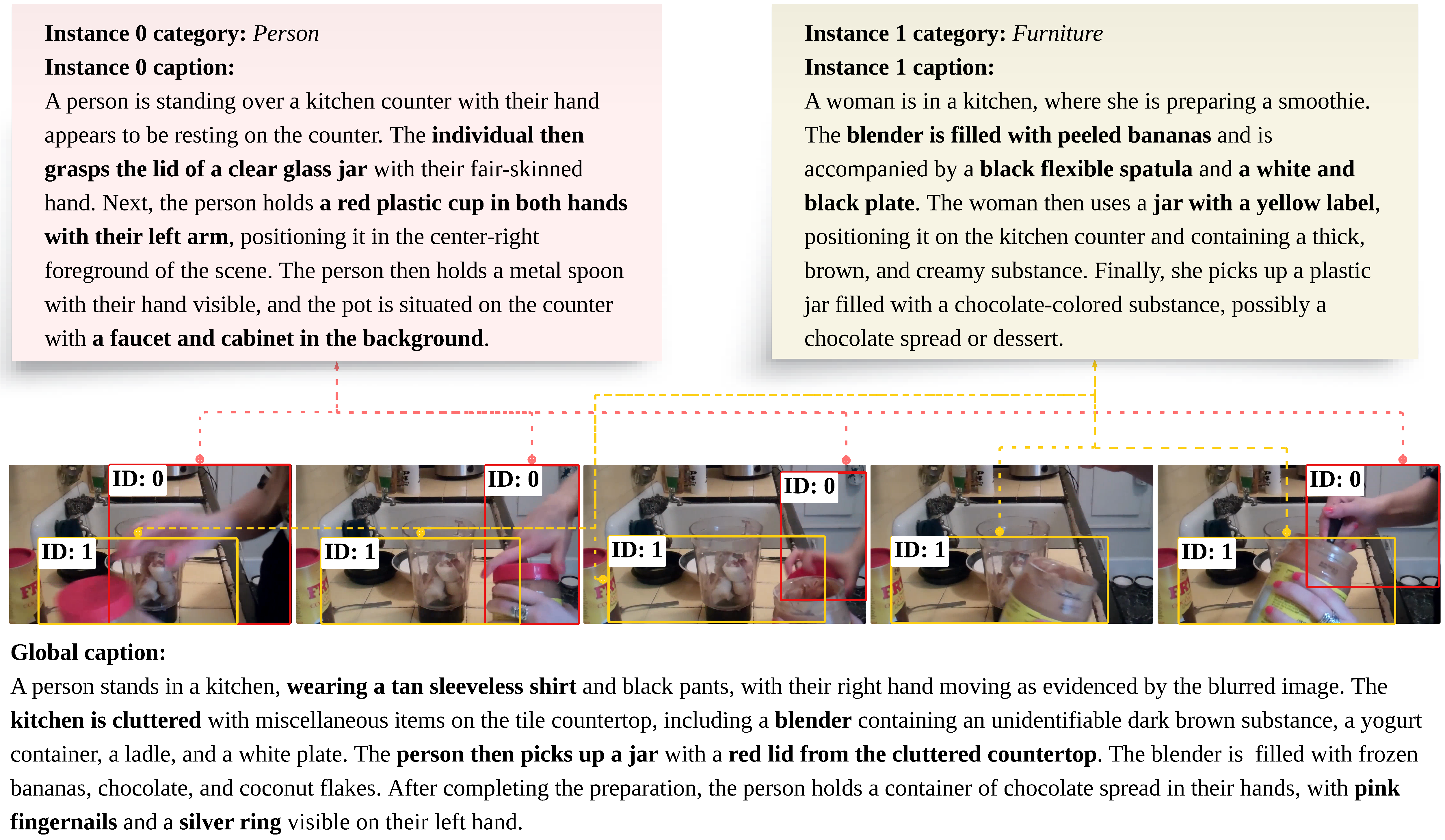
Figure 1: Illustration of the InstVL dataset—sampled frames with color-coded, temporally-consistent instance trajectories and associated instance/global captions.
The test suite for InstVL is carefully partitioned, including held-out splits with distribution shifts (sourced from COYO), ensuring robust generalization evaluation and preventing test-set leakage.
InstAP Framework and Methodological Innovations
InstAP's architecture and training protocol are fundamentally distinguished by their unified instance-aware alignment objectives and architectural modifications. The framework incorporates:
The final joint loss integrates masked video reconstruction, global alignment, and instance-aware objectives, with careful empirical weighting.
Experimental Results
Retrieval Benchmarks:
Comprehensive comparisons on the InstVL benchmark confirm InstAP's superiority for instance retrieval across all splits. For example, in instance-level retrieval on InstVL-1K (video), InstAP attains T2V R@1 of 60.63, a significant margin over all baselines, including controlled UMT-L variants trained on identical data. Notably, these gains persist on distribution-shifted splits (img-zero), evidencing strong generalization and compositionality.
Zero-Shot Generalization:
InstAP exhibits highly competitive zero-shot results on standard benchmarks, e.g., MSR-VTT (41.1 R@1) and DiDeMo (54.0 R@1)—in fact achieving SoTA for these tasks. Unlike naive finetuning of existing models on the InstVL corpus (which often degrades global retrieval metrics due to interference or overfitting), instance-aware alignment improves both instance and global scene understanding.
Spatial-Temporal Grounding:
Adding a lightweight MLP head for spatial localization, InstAP pretrained features robustly enable spatial-temporal grounding, yielding significant gains under stringent IoU metrics compared to global-only baselines. For instance, an IoU@90 of 25.13 is achieved on InstVL-1K (video), a nearly 2x improvement.
Qualitative Analysis:
Visualization of model attention and retrieved regions confirm that InstAP's representations are tightly aligned with linguistically relevant instances, while global-only baselines often exhibit diffused or erroneous attention.
Figure 3: InstAP focuses attention on caption-relevant regions (e.g., localized license plate), unlike the global baseline's diffuse focus.

Figure 4: Instance-aware pre-training enables correct retrieval of fine-grained descriptions where global baselines fail due to distractors.
Ablation Studies:
Dissecting InstAP's improvements, the instance-aware loss (Linst) emerges as the dominant factor—accounting for +13.96 to +17.61 mean recall gains on instance-level retrieval—while learnable temperature, instance loss weighting, and explicit use of trajectories further enhance performance.
Theoretical and Practical Implications
Theoretical: InstAP validates that instance-level contrastive pre-training, when conducted end-to-end and not as an auxiliary head or post-hoc graft, is critical for building VLP encoders that generalize both holistically and at the entity level. The finding that instance-aware pre-training not only enhances instance retrieval but also robustifies global understanding challenges prior tradeoff assumptions regarding detail versus context.
Practical: The availability of InstVL and the paradigm instantiated by InstAP have significant implications for tasks such as compositional video retrieval, dense video captioning, VQA, and open-world object/scene understanding. The findings suggest that downstream specialization and fine-tuning can be replaced or augmented with better pre-training objectives and resources. The architectural simplicity—instance-awareness embedded into a shared encoder via cross-attention—facilitates practical adoption and extensibility.
Future Directions
Future research directions may include: scaling InstVL further; integrating open-vocabulary, dense-phrase grounding for all entities and actions; augmenting the fusion transformer for denser temporal reasoning and causal question answering; and exploring the interaction of instance-level and global alignment via more complex multi-task objectives. Additionally, adapting instance-aware paradigms to multi-modal and multi-lingual video-text modeling remains to be explored.
Conclusion
InstAP demonstrates that integrating instance-aware, spatial-temporal contrastive alignment into large-scale VLP not only overcomes the instance grounding limitations of prior global methods, but also enhances global representations. With its dual-granularity dataset and unified training pipeline, InstAP advances the frontier of representation learning for video-language understanding, enabling robust performance in both holistic and fine-grained downstream applications.
(2604.08337)