- The paper shows that SNIP’s cross-modal alignment is not effectively exploited during symbolic regression.
- It applies dual transformer encoders with a contrastive InfoNCE objective to map symbolic and numeric modalities into a continuous latent space.
- Empirical results reveal that the alignment remains too coarse for reliable symbolic retrieval, highlighting a critical gap for future research.
Multi-Modal Learning and Genetic Programming: An Examination of Alignment in Latent Space Optimization
Introduction
The intersection of symbolic regression (SR) and multi-modal representation learning has introduced new strategies for program synthesis, particularly via Latent Space Optimization Genetic Programming (LSO-GP). Methods in this class leverage neural encoders to map symbolic structures into continuous latent spaces, recasting the discrete search over equation space as a tractable continuous optimization problem. Recent efforts, exemplified by SNIP, extend this paradigm by jointly modeling both symbolic (genotypic) and numeric (phenotypic) modalities, seeking to encode and utilize the complex mapping between these domains. The central hypothesis is that improved alignment across these modalities allows continuous optimization in one (numeric) space to implicitly guide effective symbolic search.
This essay provides an expert summary and analysis of the paper "Multi-Modal Learning meets Genetic Programming: Analyzing Alignment in Latent Space Optimization" (2604.08324), emphasizing the empirical results on SNIP's optimization dynamics, the granularity of cross-modal alignment, and the implications for future research at the multi-modal/GP interface.
Theoretical Framework and Models
Traditional GP employs combinatorial search over symbolic trees, which rapidly becomes intractable as equation complexity increases. LSO-GP circumvents this by training autoencoders on expressions to yield structured latent spaces where diverse black-box optimizers can operate. However, these prior methods privilege symbolic structure, inadequately modeling phenotypic value behavior.
SNIP extends this by employing parallel transformer encoders for each modality: one for symbolic tokens and one for numeric input/output pairs. The encoders are trained with a contrastive InfoNCE objective to maximize cosine similarity for matched symbolic/numeric representations while minimizing it for mismatched ones. Symbolic regression proceeds via optimization in the numeric latent space, with the hypothesis that the learned symbolic-numeric alignment acts as a surrogate heuristic for more effective symbolic optimization.
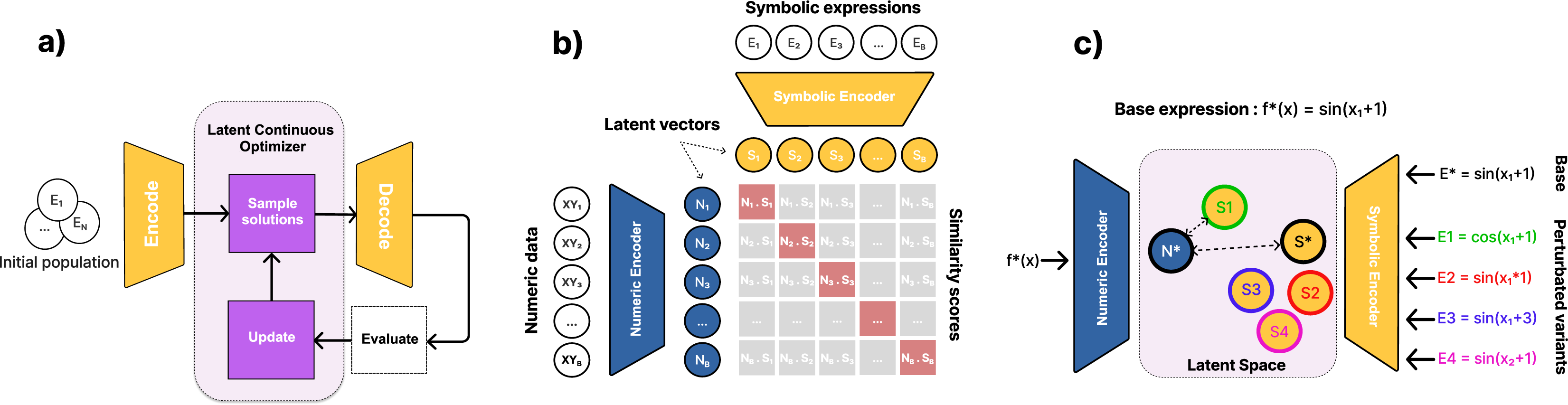
Figure 1: Overview of LSO-GP frameworks and SNIP's multi-modal alignment setup, including an illustration of alignment granularity limitations.
Empirical Study 1: Algorithmic Exploitation of Alignment
The first experimental question evaluates whether SNIP's LSO algorithm actually exploits learned cross-modal alignment during iterative optimization. Optimization trajectories are tracked on canonical benchmark datasets (Feynman and Strogatz equations), measuring both R2 (fitness) and symbolic-numeric alignment for the best individual at each search iteration.
Numerical fitness exhibits the anticipated monotonic improvement, with R2 increasing from 0.73 to 0.99 across 80 iterations. In stark contrast, alignment between symbolic and numeric embeddings remains nearly constant or decreases, starting at 0.038 and declining to 0.001 on average. This indicates that the optimizer benefits from classic population initialization and local numerical adjustment (e.g., BFGS for constants), but not from cross-modal alignment signals. The optimization thus does not leverage the information encoded by the contrastive pretraining objective.
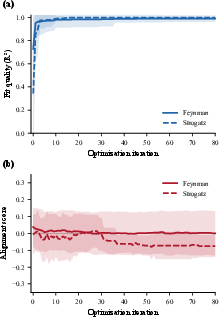
Figure 2: During optimization, R2 fitness improves monotonically (top), but cross-modal alignment remains essentially flat or decreases (bottom), highlighting the lack of explicit alignment exploitation.
Empirical Study 2: Granularity of Alignment
The second study probes whether the alignment learned by SNIP is sufficiently fine-grained to distinguish between near-equivalent but symbolically distinct expressions—a critical requirement for program synthesis. Adapting protocols from the contrastive learning literature, the authors pose a retrieval task: given a numeric target, select its exact symbolic form among a set of near-perturbations (differing by unary/binary operator, constant, or variable swap). The candidate set is rigorously constructed so that structural differences are minimal.
SNIP's retrieval accuracy is 18.3% on Feynman set cases, well below the random baseline (27.3%), and 23% on synthetic in-distribution data (matching baseline at 22.9%). The correct expression ranks first in only 18.3% of cases, and most frequently ranks second (47.6%), indicating the alignment learned is too coarse to support discriminative symbolic search.
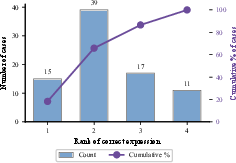
Figure 3: Rank distribution under retrieval evaluation. The most common outcome is the correct expression ranked second, evidencing insufficient discriminative alignment.
A sensitivity analysis excluding constant perturbations (a documented transformer weakness) marginally improves accuracy to 23.2%, but this is still below the new, higher random baseline (32.1%). The inability to resolve binary operator swaps further demonstrates alignment's limited discriminative power.
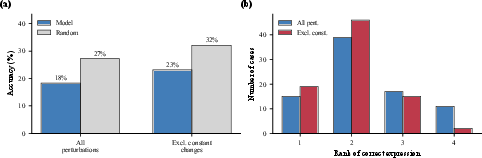
Figure 4: Removal of constant perturbations improves accuracy but not sufficiently to surpass the random baseline, highlighting persistent coarse alignment.
Critical Findings and Analysis
Contradictory to SNIP's foundational hypothesis, cross-modal alignment is neither exploited nor sufficiently fine-grained to guide symbolic optimization. Unlike CLIP in vision-language domains, where coarse semantic correspondence suffices for zero-shot tasks, symbolic regression demands representations that can resolve minimal but behaviorally significant structural changes in equations. The current contrastive pretraining approaches fail to realize this requirement.
- Even explicit optimization of the alignment metric during LSO yields no tangible gain in symbolic retrieval when the alignment signal is inherently weak.
- Model failures are concentrated around binary operator swaps (most frequent source of retrieval error), whereas variable substitutions are more easily detected—likely due to persistent variable identity biases in encoder architectures.
Implications and Future Directions
This work delineates critical bottlenecks for the future of multi-modal LSO-GP:
- Algorithmic Level: No evidence supports algorithmic exploitation of alignment by black-box optimizers as currently instantiated. Modifying such optimizers to include explicit alignment-based objectives is futile unless model-level discriminative capacity improves.
- Model Level: Advances in contrastive learning for vision-language may be instructive, but novel training protocols are needed for symbolic-numeric settings. Approaches may include domain-specific hard negative mining, auxiliary tasks emphasizing symbolic structure, or alternative regularization paradigms.
- Broader Relevance: Fine-grained cross-modal metrics could serve as new similarity or search heuristics for the SR community, improving not only LSO but also neural-guided tree-based GP and multi-objective symbolic search.
Importantly, future model development must move beyond architecture scaling and simple contrastive losses, instead focusing on training regimes that explicitly reward fine-grained symbolic discrimination. Benchmarks and evaluation protocols should prioritize not just data-fitting accuracy, but also retrieval and ranking precision among closely related expressions.
Conclusion
The findings indicate that current multi-modal LSO, realized via SNIP’s contrastive pretraining, does not fulfill its theoretical promise for symbolic regression. The search neither exploits alignment nor benefits from it, and the alignment itself is too coarse for fine-grained symbolic program synthesis. However, the explicit identification of these shortcomings, and the demonstration framework provided, chart a concrete research agenda—one centered on closing the granularity gap in alignment and integrating such improved representations into robust optimization algorithms.
Future work in multi-modal symbolic regression should prioritize end-to-end pipelines and training strategies that promote precise symbolic-numeric correspondence, thereby unlocking the theoretical advantages of rich multi-modal latent spaces for program synthesis and interpretable machine learning.

