- The paper presents the Expected Safety Impact (ESI) framework to quantify parameter-level safety contributions in LLMs.
- The study demonstrates that targeted tuning with SET and SPA achieves over 50% reduction in safety breaches while preserving core capabilities.
- Architectural analysis reveals that safety-critical weights concentrate in specific layers, guiding model-specific intervention strategies.
Safety-Critical Parameter Identification and Intervention in LLMs via Expected Safety Impact
Motivation and Overview
Accurate safety alignment in LLMs remains challenging, particularly during downstream adaptation and under adversarial pressure. Existing approaches often lack fine-grained control, underexplore internal safety mechanisms, and rely on coarse methods for safety preservation, leading to fragility and inefficiency. "Towards Identification and Intervention of Safety-Critical Parameters in LLMs" (2604.08297) addresses these gaps by introducing the Expected Safety Impact (ESI) framework, which quantifies parameter-level contributions to model safety and operationalizes this analysis for targeted intervention. The framework systematically identifies safety-critical weights, characterizes their architectural distribution, and deploys two specialized tuning paradigms—Safety Enhancement Tuning (SET) and Safety Preserving Adaptation (SPA)—for rapid, efficient, and minimally disruptive safety alignment.
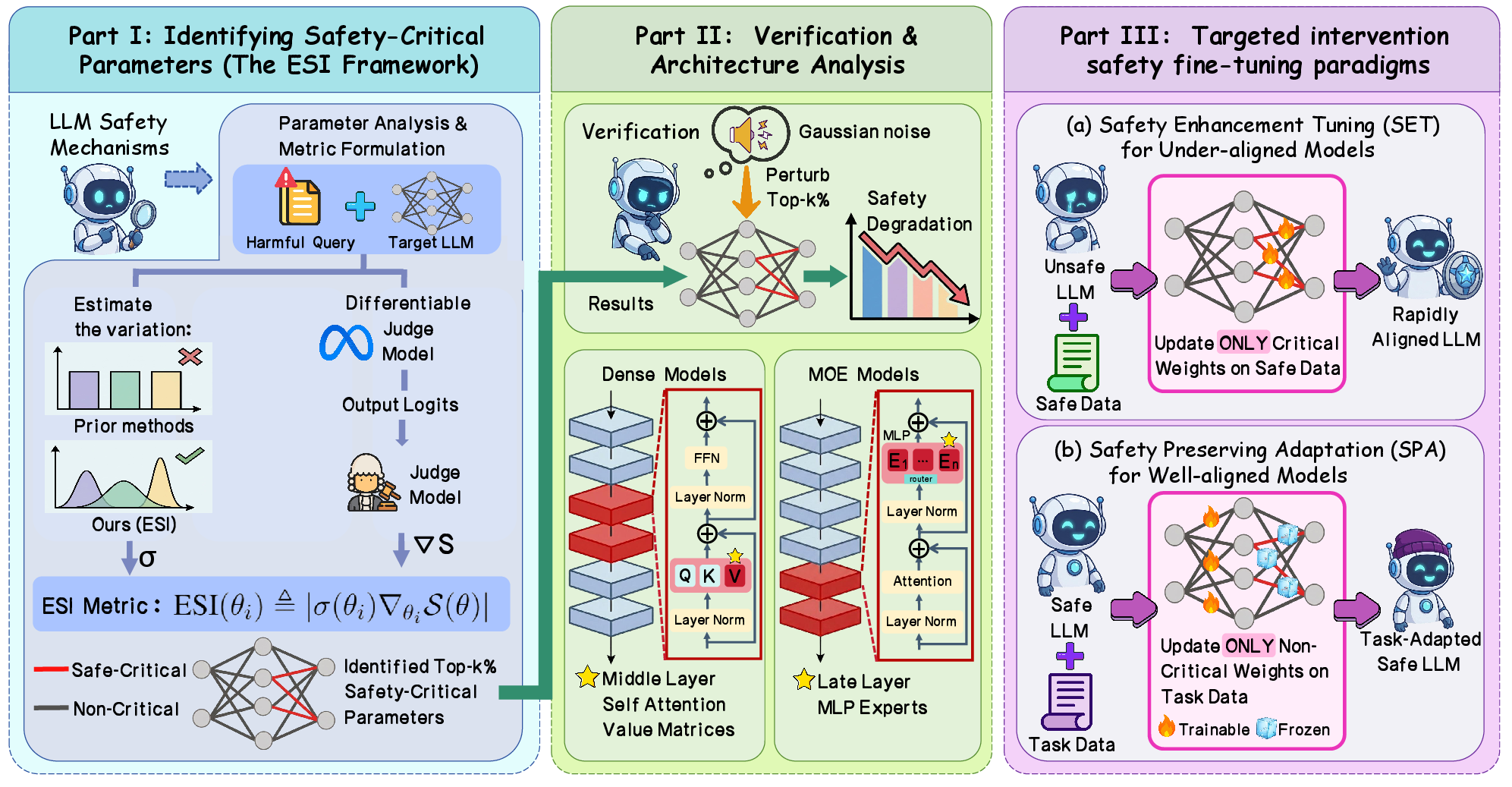
Figure 1: Overview of the proposed framework, consisting of parameter identification via ESI (Part I), architectural safety pattern analysis (Part II), and targeted intervention paradigms (Part III).
ESI formalizes parameter safety-criticality as ∣σ(θi)∇θiS(θ)∣, where S(θ) is the expected safety score under a harmful input distribution, σ(θi) is the parameter-wise standard deviation, and ∇θiS(θ) is the parameter gradient of the safety objective. This approach yields two advantages: (1) the magnitude scaling via σ(θi) captures statistical variability and expected perturbation, and (2) the explicit focus on safety scores, rather than generic cross-entropy or loss-driven metrics, enables precise task-relevant analysis.
The estimation of ∇θS(θ) leverages a differentiable judge model J, using Gumbel-Softmax relaxation and a vocabulary-projection matrix to enable end-to-end gradient computation. The effectiveness of ESI is validated via perturbation-based sensitivity analysis, where Gaussian noise applied to top-ranked ESI parameters produces marked, architecture-agnostic increases in Attack Success Rate (ASR), substantially exceeding both random perturbation and prior importance metrics (SN, GMT, Wanda, SNIP).
Architectural Insights: Distribution of Safety-Critical Weights
Layer-wise aggregation of ESI reveals distinct architectural safety patterns. In dense transformer models (e.g., Llama3, Qwen2.5), safety-critical parameters are largely concentrated in middle layers, specifically within self-attention value matrices. In contrast, Mixture-of-Experts (MoE) LLMs (e.g., Qwen3, Mixtral) exhibit a marked shift, with late-layer MLP experts dominating safety sensitivity.
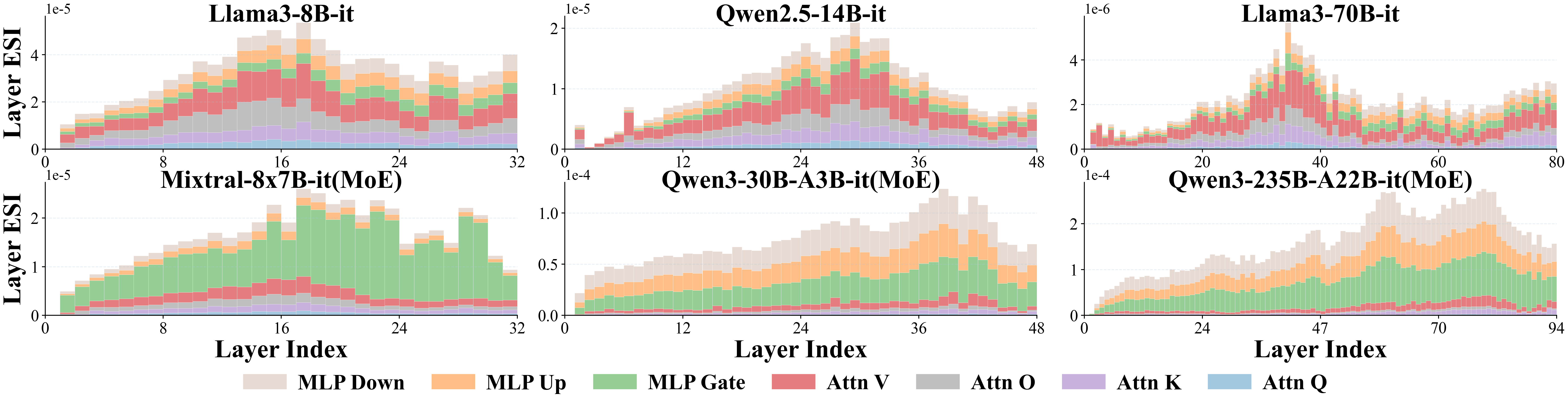
Figure 2: Layer-wise ESI aggregation, indicating concentration of safety-critical parameters in middle layers for dense models and late-layer MLPs for MoE models.
This distributional shift has direct implications for parameter-efficient and architecture-specific intervention, underscoring the necessity to tailor safety tuning strategies according to model typology.
ESI-Guided Safety Enhancement Tuning (SET)
SET operationalizes ESI for under-aligned models by selectively updating only the top-k% safety-critical parameters, optimizing a safety alignment loss over dedicated safe-response datasets (CB-Safety, R1-Safety). Compared to baselines (Random, SN-tune, LoRA, SafeLoRA), SET consistently achieves the lowest post-tuning ASR scores, reducing safety violations by over 50% in major benchmarks with minimal training iterations and parameter updates.
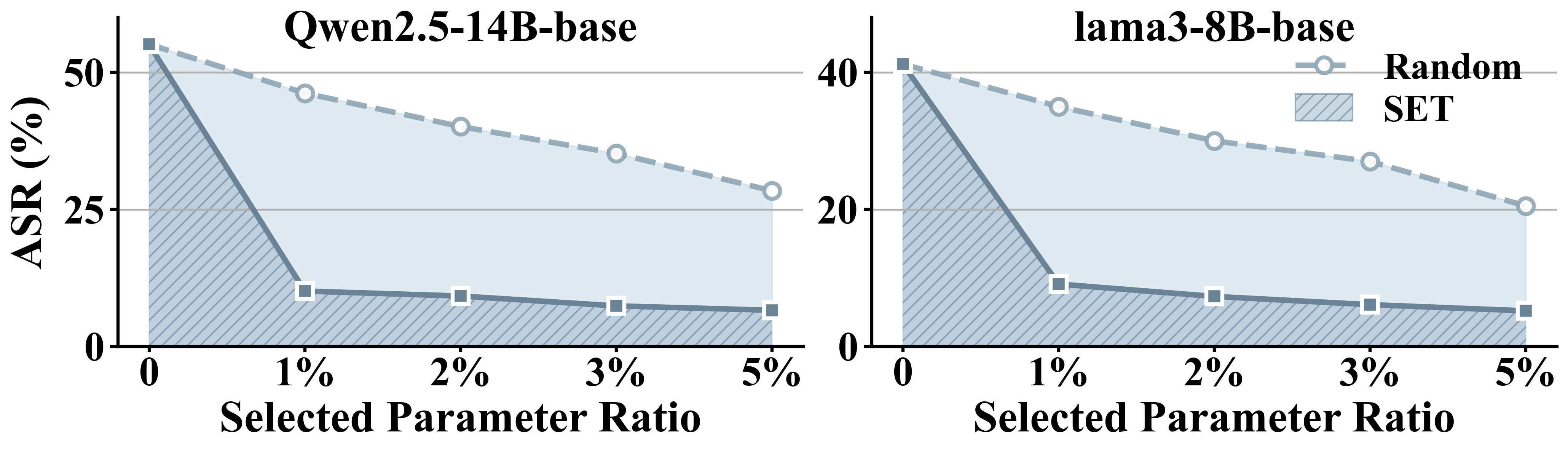
Figure 3: ASR trajectory on HarmBench as a function of parameter selection ratio for SET versus random selection.
A critical facet of SET is its ability to preserve general model capabilities. Task evaluation on GSM8K, MMLU, and HumanEval demonstrates that SET maintains reasoning, knowledge, and coding abilities at baseline levels, whereas unrestricted full fine-tuning induces catastrophic forgetting and utility deterioration.
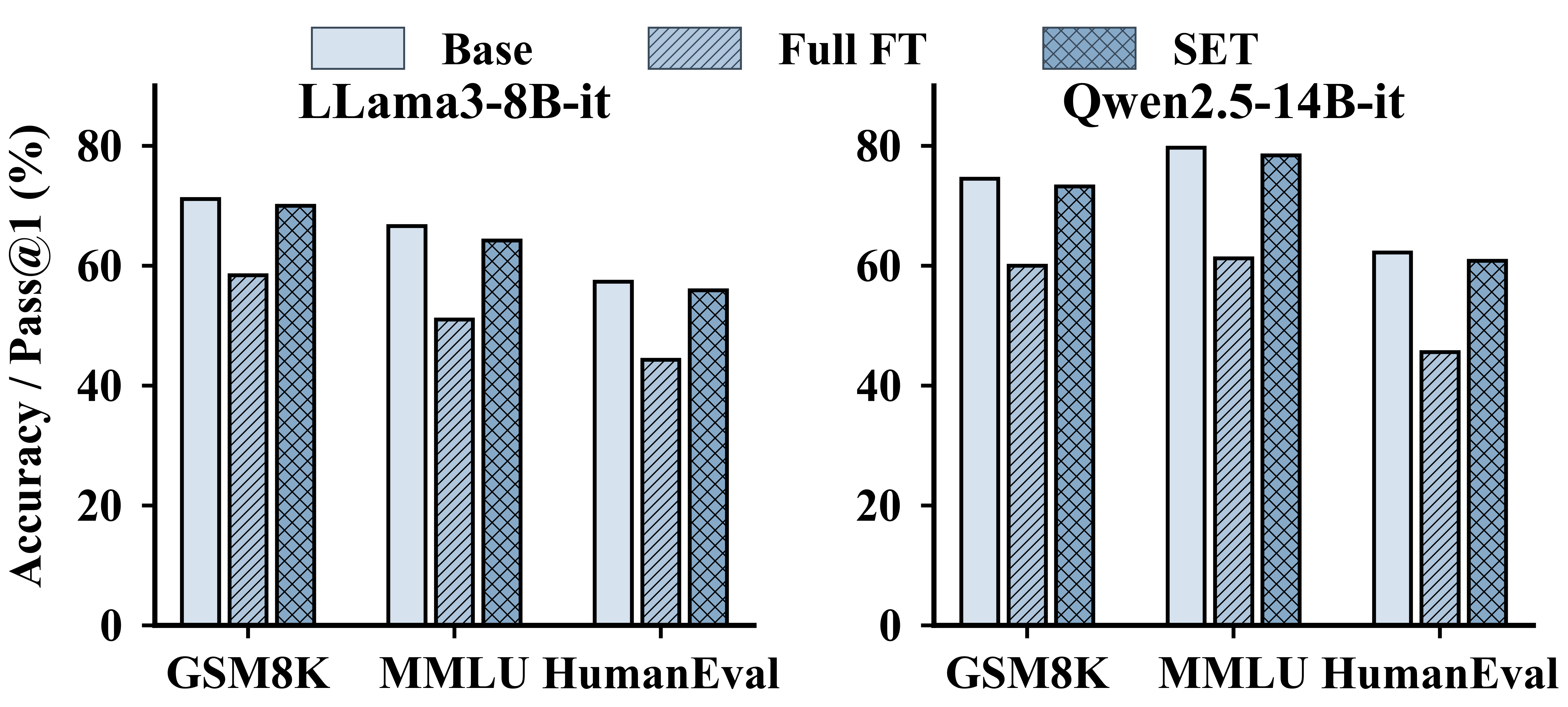
Figure 4: General capability comparison across model configurations, illustrating that SET matches base performance while full fine-tuning degrades utility.
ESI-Guided Safety Preserving Adaptation (SPA)
SPA is designed for well-aligned LLMs undergoing downstream task adaptation. It freezes the previously identified safety-critical parameters (lowest k% ESI scores) and fine-tunes only the non-safety-sensitive subset. Evaluation shows SPA constrains safety deterioration to negligible levels (≤1% increase in ASR) across diverse tasks, in stark contrast to random or RSN-Tune baselines, which markedly erode safety while acquiring new task capabilities.
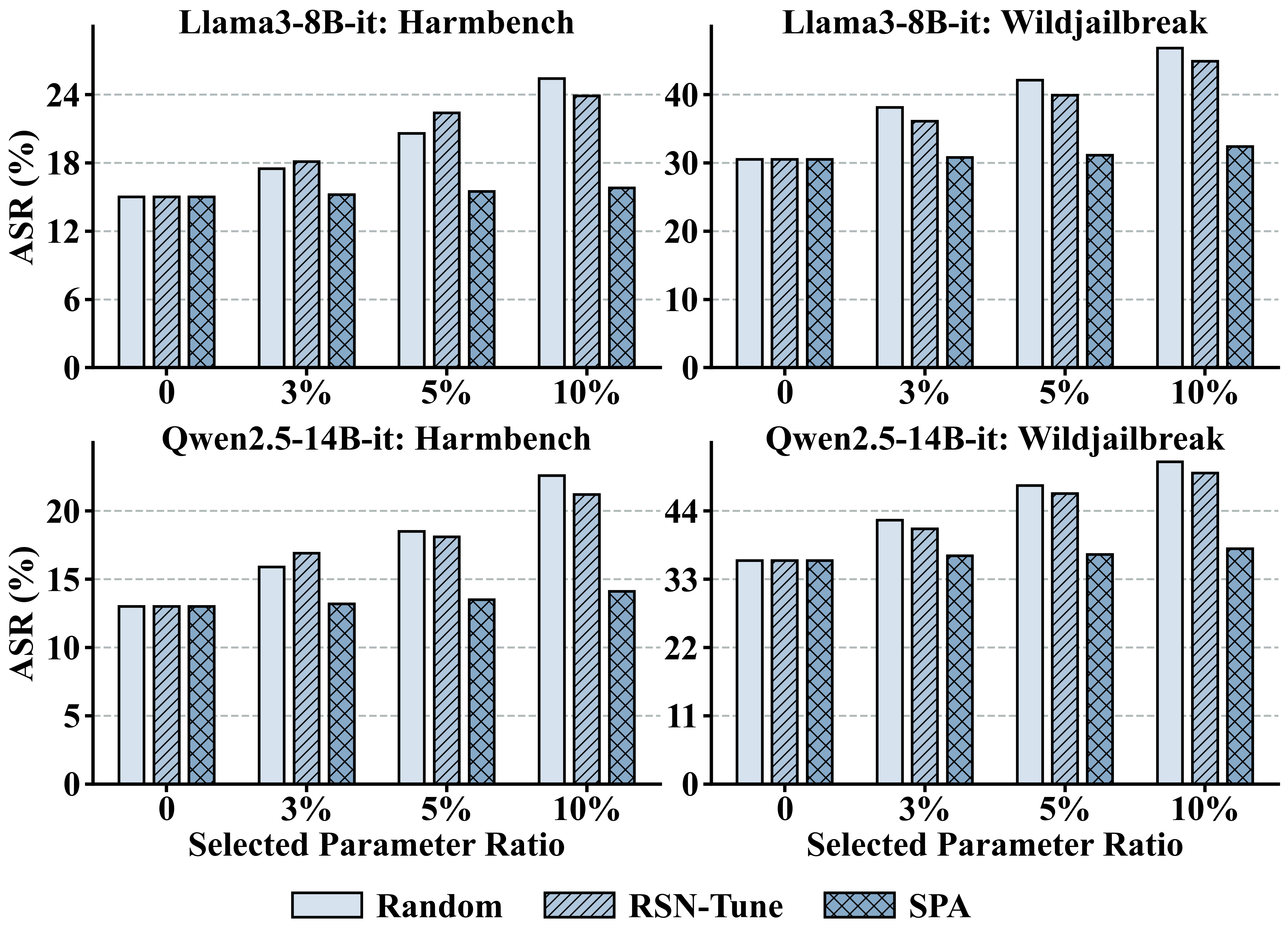
Figure 5: Impact of parameter selection ratio on safety preservation, with SPA maintaining robust safety under increased parameter updates.
Radar chart analysis further quantifies the trade-off, showing that SPA optimizes both safety and utility axes, outperforming competing methods in multi-task benchmarks.
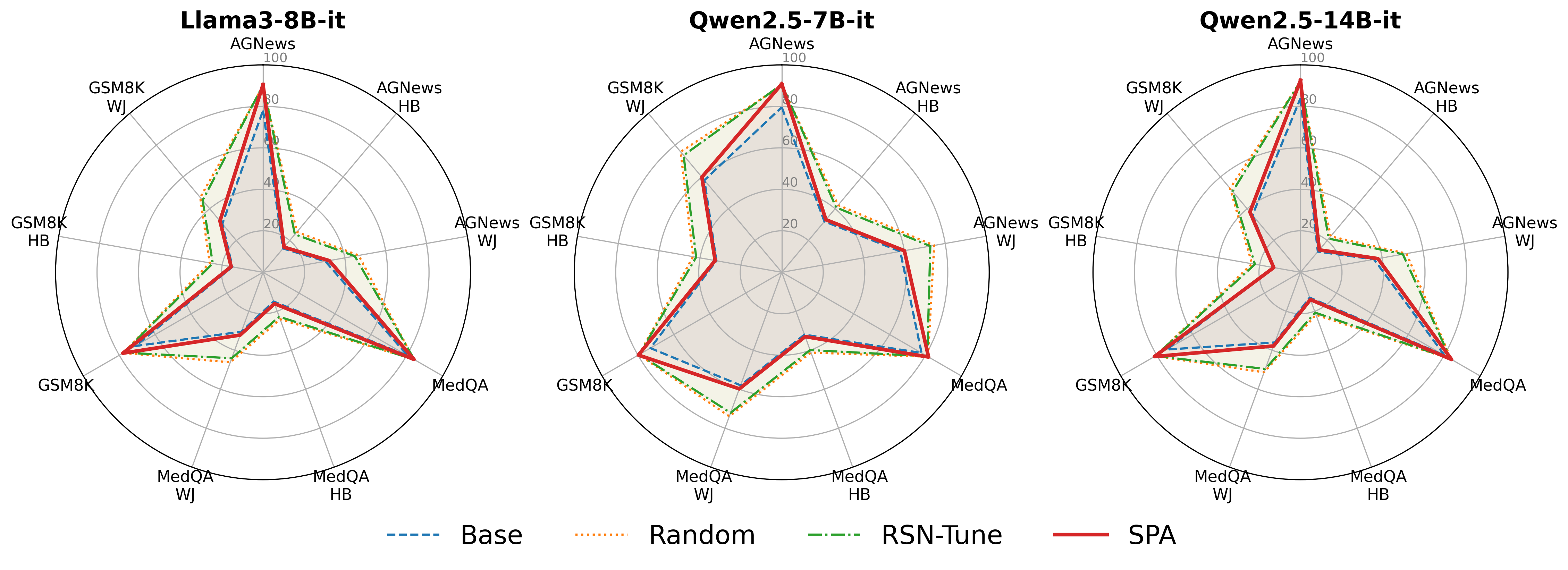
Figure 6: Radar chart mapping safety-utility trade-off across architectures, confirming that SPA achieves near-optimal performance in both dimensions.
Practical and Theoretical Implications
The targeted, parameter-efficient paradigm introduced by this work provides a lightweight pathway for rapid safety enhancement and robust safety preservation during LLM adaptation. The empirical results contradict prior tacit assumptions that safety is broadly distributed or that full-model fine-tuning is required for effective alignment. Instead, safety mechanisms are highly localized, amenable to modular intervention. The architectural insights further motivate development of task- and topology-aware safety interventions, particularly as MoE architectures proliferate.
Methodologically, ESI offers a principled metric for parameter importance, potentially extendable to other alignment domains (fairness, bias mitigation, privacy). The framework's reliance on differentiable judge models enables scalable analysis compatible with open- and closed-source LLMs, although full extension to proprietary models remains limited by internal access requirements. The analysis indicates promising directions for domain-specific safety alignment (e.g., financial, legal), modularization, and cross-model transferability of safety mechanisms.
Conclusion
The ESI framework provides a rigorous foundation for identifying and intervening on safety-critical parameters in LLMs. Empirical evaluations show that ESI-guided SET dramatically reduces safety risks in under-aligned models, while SPA preserves safety under downstream adaptation, all with minimal impact on general utility. Architectural analysis underscores the importance of topology-aware tuning. The methodology sets a new standard for precision in safety alignment, and opens multiple research avenues for modular, scalable, and domain-specialized intervention in large-scale language systems.

