- The paper introduces ViVa, a video-generative value model that integrates video diffusion Transformers with proprioceptive prediction to capture future embodied dynamics.
- It achieves enhanced task performance, demonstrating a 73% success rate and improved throughput on complex scenarios like box assembly through precise temporal credit assignment.
- ViVa exhibits robust out-of-domain generalization and fine-grained error detection, offering a scalable approach for reliable policy improvement in robotic manipulation.
ViVa: A Video-Generative Value Model for Robot Reinforcement Learning
Motivation and Problem Context
The integration of vision-language-action (VLA) models into robotic manipulation pipelines has enabled progress toward generalist robots that act in complex real-world environments by leveraging large-scale pretraining. However, these models are limited by their static visual nature and inability to capture temporal evolution, which is critical in real-world robotic settings characterized by partial observability and delayed feedback. Value estimation—central to reinforcement learning (RL)—is fundamentally a predictive task: the value function must anticipate future outcomes to guide effective policy improvement, particularly in long-horizon settings. Existing value functions built upon discriminative vision-LLMs (VLMs) underperform on temporally extended tasks due to their inability to explicitly reason about dynamics.
Method: ViVa Architecture and Training
ViVa (Video-generative Value model) addresses the limitations of existing VLM-based value estimators by leveraging a pretrained video diffusion Transformer (Wan2.2), thereby grounding value estimation in predicted embodiment dynamics rather than static snapshots. The approach augments the video generator with additional modalities—robot proprioception and scalar value—mapped into the model’s latent space using repeat padding and broadcast operations, respectively.
Given current observations, ViVa constructs a latent sequence with clean conditioning frames (blank token, proprioception, multi-view images) and noisy target frames (future proprioception and value). The denoiser, conditioned on the clean prefix, jointly predicts the future embodied state and scalar value via a flow matching loss, aligning the denoised latent with ground-truth trajectories based on anticipated dynamics.
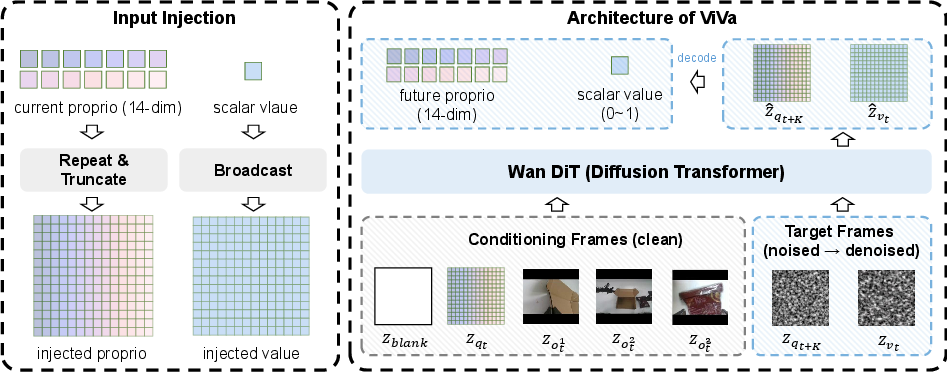
Figure 1: The ViVa architecture injects proprioceptive and scalar value information into the latent sequence of a video diffusion Transformer, coupling value prediction with foresight.
To train the value model, supervision signals are constructed from episode-level annotations by encoding both temporal progress and task outcome into a discriminative step-wise reward, ensuring constant separation between successful and failed trajectories. The full value regression target at each step is the cumulative future reward, which serves as the direct supervision for value prediction. Inclusion of future proprioception prediction jointly regularizes the learning process and improves the model’s sensitivity to fine-grained embodiment errors.
Experimental Evaluation
Evaluation is conducted on three real-world manipulation tasks: shirt folding, box assembly, and toilet paper organization, with the box assembly representing the most complex, long-horizon scenario. The comparison involves several baselines: pure imitation learning policies (π0.5, Gigabrain-0), RECAP with a VLM-based value function, and RECAP equipped with ViVa.

Figure 2: Real-world tasks include shirt folding, box assembly, and toilet paper organization.
On the box assembly task, ViVa delivers substantial improvements, outperforming prior baselines in both success rate (73% vs. 58% with the VLM-based value) and throughput (14 vs. 11 successful tasks per hour). These results decisively demonstrate the strength of spatiotemporal priors for credit assignment, with ViVa providing value estimates tightly aligned with actual task progress and able to detect deviations or errors in manipulation—a capability the VLM-based approach lacks.
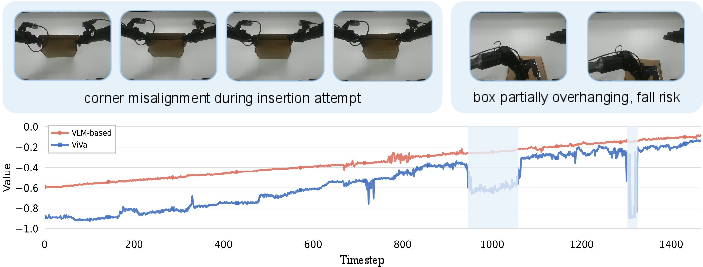
Figure 3: In box assembly, ViVa's value estimation demonstrates higher sensitivity to failure events compared to VLM.
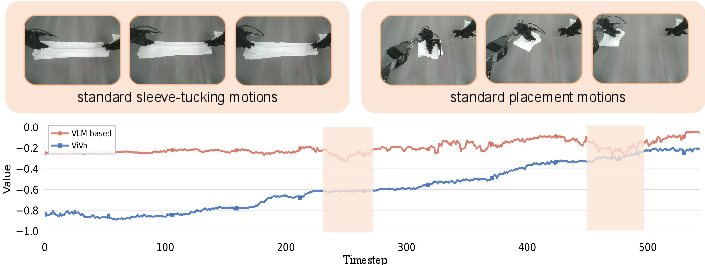
Figure 4: During shirt folding, ViVa achieves stable, monotonic value progression, reflecting incremental task advancement missed by VLM.
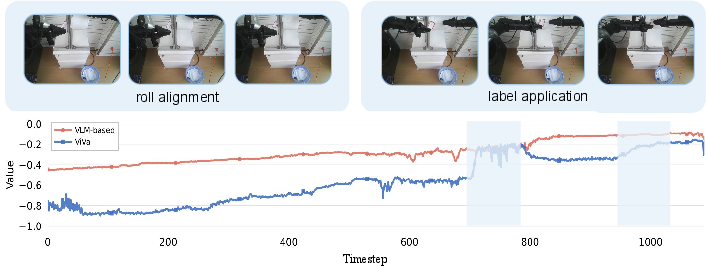
Figure 5: In toilet paper organization, ViVa’s value signal responds precisely to execution milestones, while VLM is insensitive to key sub-tasks.
Out-of-Domain Generalization
An essential property of value models in robotics is their transferability to new objects or scenarios. ViVa demonstrates robust generalization on the unseen pants folding task, maintaining smooth value trajectories that capture critical execution milestones, in contrast to VLM-based estimators which fail to register or monotonically misalign with true progress.
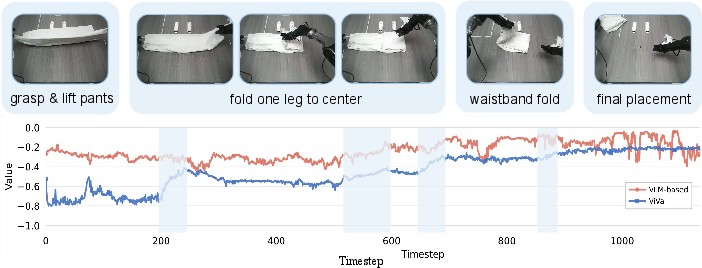
Figure 6: ViVa generalizes to pants folding, aligning value increases with manipulation milestones in unseen scenarios.
Ablation Studies
Ablation analyses investigate backbone selection, proprioceptive prediction, and prediction horizon hyperparameters.
- Backbone: Swapping the VLM-based backbone for a video generation backbone (without proprioceptive prediction) already yields a stronger value trend, confirming the critical role of spatiotemporal reasoning.
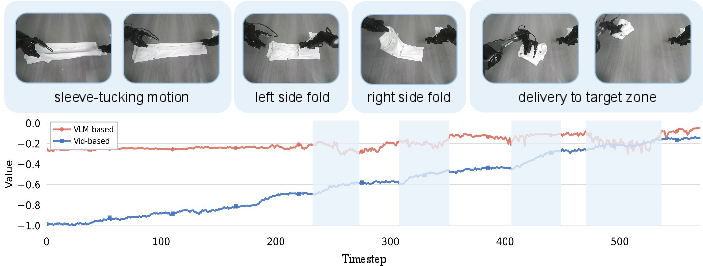
Figure 7: Video generation backbone improves task tracking granularity compared to VLM, even with matching input/output formulations.
- Proprioceptive Prediction: Removing future proprioception prediction degrades ViVa's sensitivity to suboptimal manipulation and subtle errors, as evidenced by missed value drops during anomalous actions.
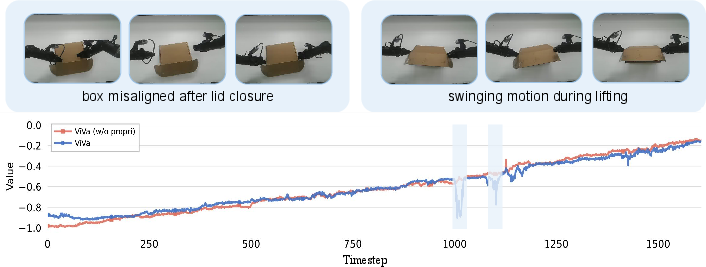
Figure 8: Full ViVa, with future proprioception prediction, exhibits enhanced sensitivity to manipulator deviations during assembly.
- Fine-Grained Error Detection: ViVa can reliably detect subtle execution failures (e.g., missed grasp, premature release) evidenced by sharp value discontinuities at error points.

Figure 9: ViVa-based value model identifies subtle error events, resulting in immediate value drops at failure points.
- Prediction Horizon: Intermediate horizons (K=50 steps) achieve the smoothest, most informative value trajectories; too short or long horizons induce instability or failure to capture critical events.
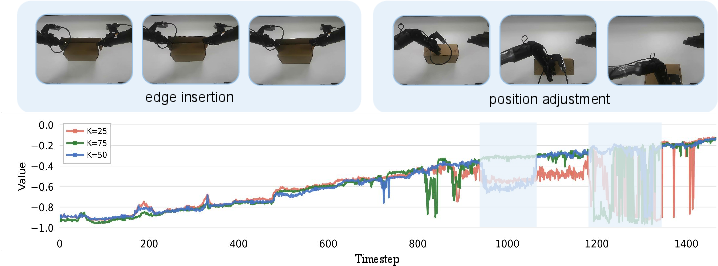
Figure 10: Horizon ablation demonstrates that intermediate future prediction length optimally balances context and signal stability for value estimation.
Computational Considerations
ViVa delivers competitive or superior performance with modest computational requirements: training is faster than VLM-based models due to efficient video backbone utilization and lightweight proprioceptive prediction; inference time is also reduced.
Implications and Future Directions
ViVa advances value modeling for embodied RL by transferring the predictive power of scalable video generators into the value function domain. The approach demonstrates practical robustness (including out-of-domain generalization and fine-grained error detection) and theoretical promise for improved temporal credit assignment and long-horizon policy refinement. The results also support reframing RL value estimation as a future prediction problem, rather than classification or ordering on static visual representations.
Practical implications include more reliable policy improvement in challenging real-world manipulation, and vis-à-vis robotics foundation models, ViVa’s architecture is readily extensible to other predictive signals beyond value or proprioception. Future research will likely scale real-robot deployment, integrate more complex predictive modalities, and unify policy and value learning in a video-generative framework.
Conclusion
ViVa establishes the utility of video generative architectures for value estimation in robot RL, providing temporally grounded value signals critical for robust long-horizon manipulation and out-of-domain generalization. By internalizing embodiment dynamics through video prediction and proprioceptive reasoning, ViVa overcomes limitations of static-visual VLMs and represents a principled path toward scalable, progress-aware value models in robotics.
Reference: "ViVa: A Video-Generative Value Model for Robot Reinforcement Learning" (2604.08168)