- The paper introduces a dual adaptive sparsity mechanism combining cube-selective attention and token-selective FFN to reduce FLOPs by up to 57%.
- It leverages nucleus sampling and entropy cues to dynamically select semantically cohesive 3D cubes, preserving long-range temporal dependencies.
- Experimental results across multiple benchmarks validate AdaSpark’s efficiency in long-video understanding while maintaining or improving accuracy.
Adaptive Sparsity for Efficient Long-Video Understanding: An Expert Analysis of AdaSpark
Motivation and Preliminary Analysis
The scaling of Video-LLMs towards hour-scale, high-resolution video presents acute computational bottlenecks—primarily the quadratic complexity of causal self-attention and the activation cost of FFN layers. Existing efficiency methods typically employ frame sampling, token pruning, or rigid local attention patterns, leading to irreversible loss of fine-grained features or deterioration of long-range temporal dependencies. AdaSpark addresses these deficiencies via context-adaptive sparsity applied hierarchically at both the spatio-temporal cube and token levels.
The authors begin with a quantitative analysis of attention score distributions and FFN norm changes in the Qwen2.5-VL model. They observe that video attention exhibits intrinsic sparsity with only a subset of vision tokens capturing the majority of attention probability, and that FFN layers transform text tokens far more dynamically than visual tokens.
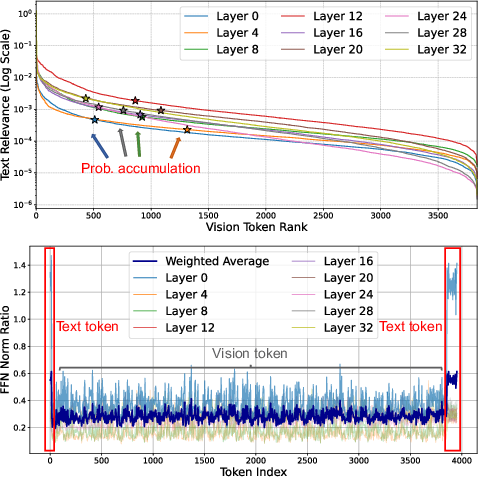
Figure 1: Internal layer distributions demonstrate high sparsity in attention and inert FFN transformations for vision tokens.
These observations motivate the dual adaptive sparse design: 1) adaptively selecting cubes for attention, and 2) selectively activating FFN computation for salient tokens within cubes, thereby minimizing redundant FLOPs and preserving critical detail and connectivity.
Methodology: Cube-Token Hierarchical Sparsity
AdaSpark partitions video inputs into semantically cohesive 3D cubes defined over spatial and temporal axes. Sparse computation is then applied per cube via two entropy-guided modules:
Adaptive Cube-Selective Attention (AdaS-Attn)
Each query token determines relevance to preceding cubes via attention scores aggregated over mean key vectors. Nucleus (Top-p) sampling is used to generate context-aware sparse cube selection, ensuring layer-dynamism and adaptivity to input complexity. Attention is always fully computed for the local cube context.
Adaptive Token-Selective FFN (AdaS-FFN)
Within each cube, token importance is calculated via normalized L2-norms of embeddings. Using the Top-p mechanism, only the most salient tokens are processed through full FFN; the remainder are updated via mean compensation strategies. All text tokens are processed densely due to their semantic importance.
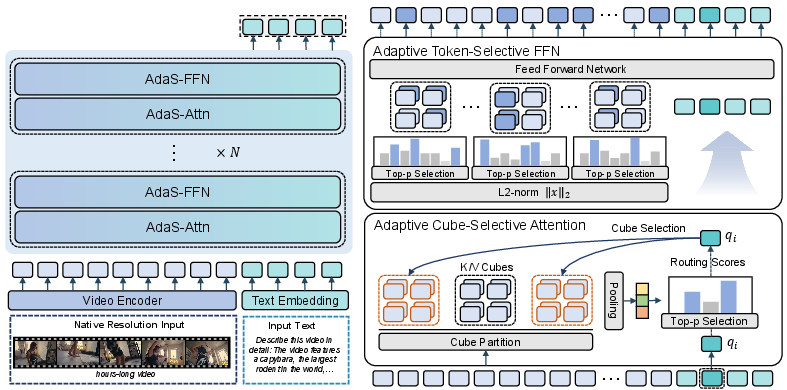
Figure 2: End-to-end AdaSpark framework including cube partitioning, AdaS-Attn, and AdaS-FFN mechanisms.
Entropy-based selection provides dynamic sparsity depending on attention and importance distributions, guaranteeing preservation of both fine-grained and long-range features.
Experimental Evaluation
AdaSpark is instantiated on Qwen2.5-VL-3B and Qwen2.5-VL-7B backbones and evaluated across a battery of benchmarks: VideoNIAH (extra-long), MLVU, VideoMME, LongVideoBench, LVBench (long-form), MVBench (short video), VSIBench (spatial reasoning), and CharadesSTA (video grounding).
AdaSpark achieves up to 57% reduction in FLOPs compared to dense baselines, while maintaining or improving accuracy. On VideoNIAH, AdaSpark outperforms all efficiency-focused models, retaining high retrieval accuracy across all temporal depths. On long-form tasks, AdaSpark achieves top scores, especially notable in the 7B backbone, validating the claim that adaptive sparsity preserves long-temporal dependencies with minimal cost.
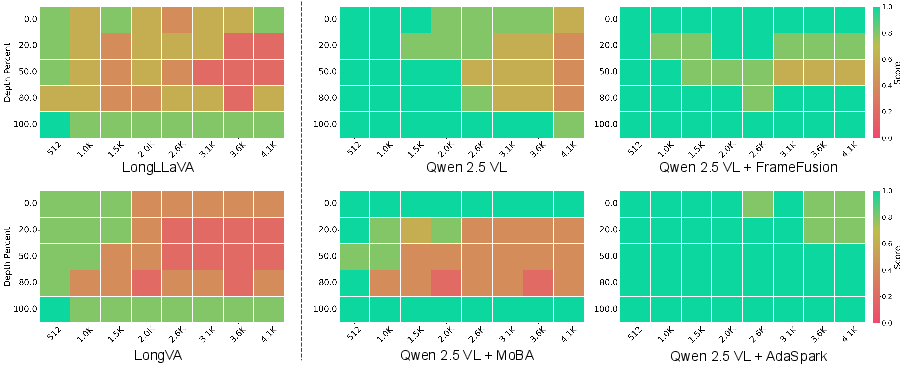
Figure 3: Needle in a Haystack benchmark results; AdaSpark exhibits robust long-range retrieval across all depths.
Ablation and Adaptive Selection Insights
A comprehensive ablation study examines the effect of AdaS-Attn, AdaS-FFN, cube shapes and sizes, mean compensation, and selection strategy. The combined modules yield maximal performance and computational savings. Balanced cube shapes and intermediate cube sizes optimize the trade-off between fine detail and sparsity; mean compensation outperforms naive bypass strategies. Crucially, entropy-based Top-p selection significantly outperforms static Top-K and uniform sampling, demonstrating the necessity of context-adaptive mechanisms.
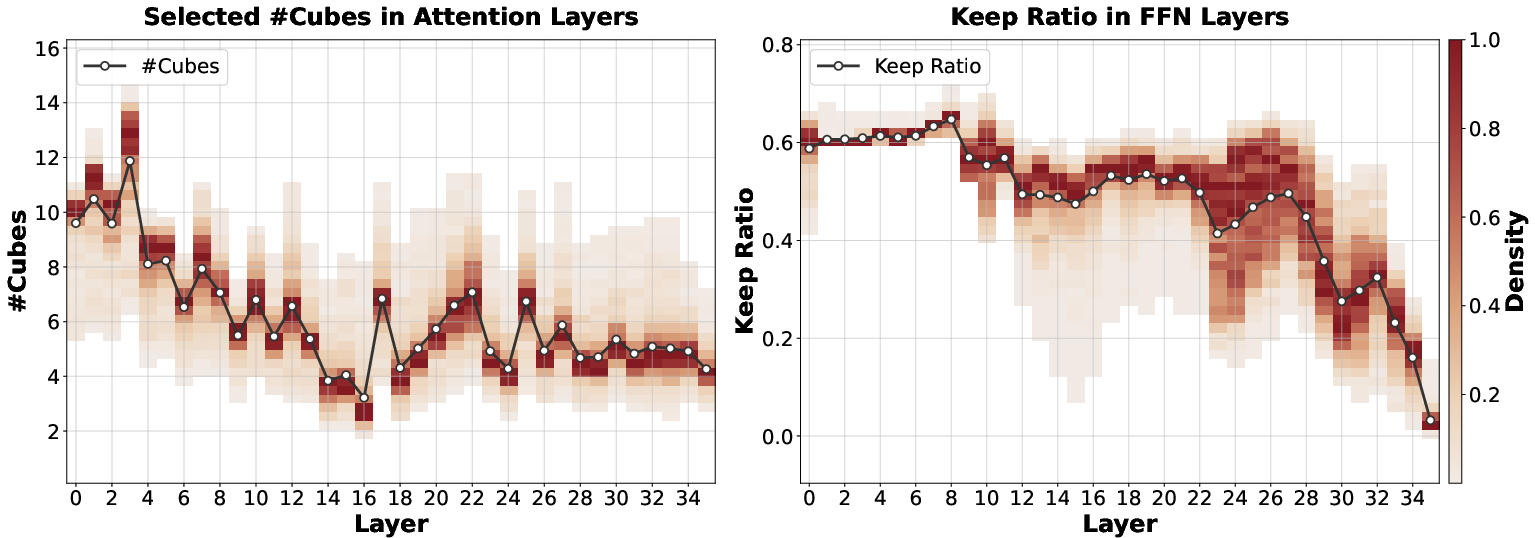
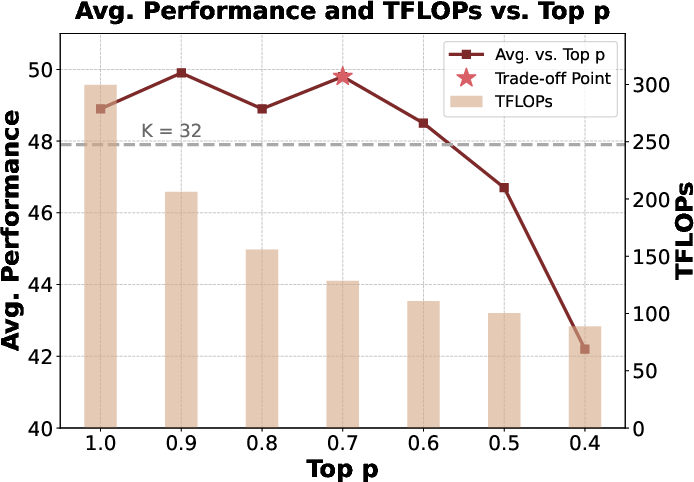
Figure 4: Layer-wise adaptive selection statistics; stronger sparsity emerges at deeper layers, with AdaS-FFN varying dynamically.
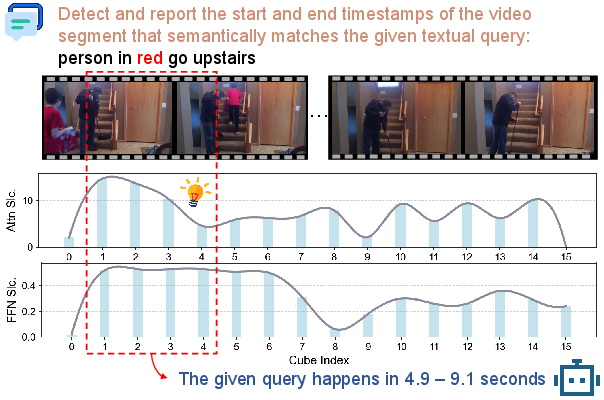
Figure 5: Case study visualization, highlighting adaptive selection of high-relevance cubes in response to query tokens.
Implications and Future Directions
AdaSpark establishes the efficacy of content-adaptive, hierarchical sparsity as a scalable paradigm for long-sequence video-LLMs. The approach avoids hardcoded, rigid sparsity, leveraging intrinsic token-level and cube-level redundancy via entropy-adaptive selection. This framework enables practical deployment of Video-LLMs for real-world, hour-scale video contexts, while maintaining task-level fidelity.
From a theoretical perspective, AdaSpark demonstrates that joint sparsity in attention and FFN layers (both guided by entropy/nucleus sampling) is optimal compared to static strategies, which uniformly degrade performance across temporal or spatial axes. Practically, these findings could inform hardware-aligned sparse architectures, progressive token reduction pipelines, and seamless integration with multimodal LLM regimes.
Future developments may explore direct multi-modal cube partitioning, further sparsity alignment with hardware primitives, and generalized extensions to omni-modal foundation models, as well as dynamic adaptation of sparsity thresholds during inference for sample-specific efficiency.
Conclusion
AdaSpark introduces a unified, entropy-adaptive sparse framework for efficient long-video understanding in Video-LLMs, achieving strong empirical performance and significant computational savings. By exploiting token- and cube-level redundancy via context-aware selection, AdaSpark validates adaptive sparsity as a scalable solution for large multimodal sequence modeling and sets a precedent for future research in dynamic sparsity and efficient transformer computation (2604.08077).

