- The paper introduces the GuarantRAG framework that decouples parametric reasoning from evidence integration via a joint decoding mechanism to address integration failures.
- It employs a dual-path answer generation with a Contrastive DPO objective to mitigate hallucinations and enforce grounding in retrieved documents.
- Experimental results across several QA benchmarks show up to 12.1% accuracy improvement and 16.3% reduction in hallucination rate, demonstrating its robust performance.
GuarantRAG: Explicit Decoupling and Joint Decoding for Reliable Knowledge Integration in Retrieval-Augmented Generation
Motivation and Background
Retrieval-Augmented Generation (RAG) architectures have become essential for enhancing LLMs' factuality by supplementing parametric knowledge with external references. However, a fundamental bottleneck has persisted: integration failures when LLMs must reconcile retrieved evidence with latent priors, frequently resulting in hallucinations or incoherence. Prior work primarily focused on optimizing retrieval precision or adaptive triggering, yet empirical analysis reveals that 67.3% of RAG responses still suffer from critical integration failures, dominated by information omission, contradictions, and fact blending. This exposes a structural limitation in prevailing approaches, which treat knowledge fusion as a single-pass implicit process, often resulting in parametric overrides or disjointed insertions.
GuarantRAG Framework
GuarantRAG introduces an explicit multi-stage pipeline, decoupling reasoning (parametric) and evidence integration (non-parametric) before fusing these through a Joint Decoding mechanism. The framework consists of three distinct phases:
- Knowledge Decision: A lightweight estimator predicts whether retrieval is necessary, based on query temporal relevance and specificity metrics, optimizing computational efficiency.
- Dual-Path Answer Generation:
- Inner-Answer Generation: The base LLM produces a response from parametric memory, maximizing logical coherence and instruction-following, but not guaranteed factuality.
- Refer-Answer Generation: Initialized from the inner-answer model, Refer-Answer is generated via a novel Contrastive DPO objective, which explicitly penalizes parametric hallucinations and forces grounding in retrieved evidence. Preference pairs are constructed using the retrieved document as a positive and inner-answer as a negative constraint. Auxiliary regularization aligns refer-answer length and semantic relevance to the query.
- Joint Decoding Fusion: Rather than naive concatenation, token-level joint decoding decomposes refer-answer into atomic semantic segments using auxiliary LLMs. During generation, the model computes similarity scores between current generation context and refer-answer segments, dynamically performing soft interventions on hidden states to inject factual content whenever semantic divergence is detected (Figure 1).
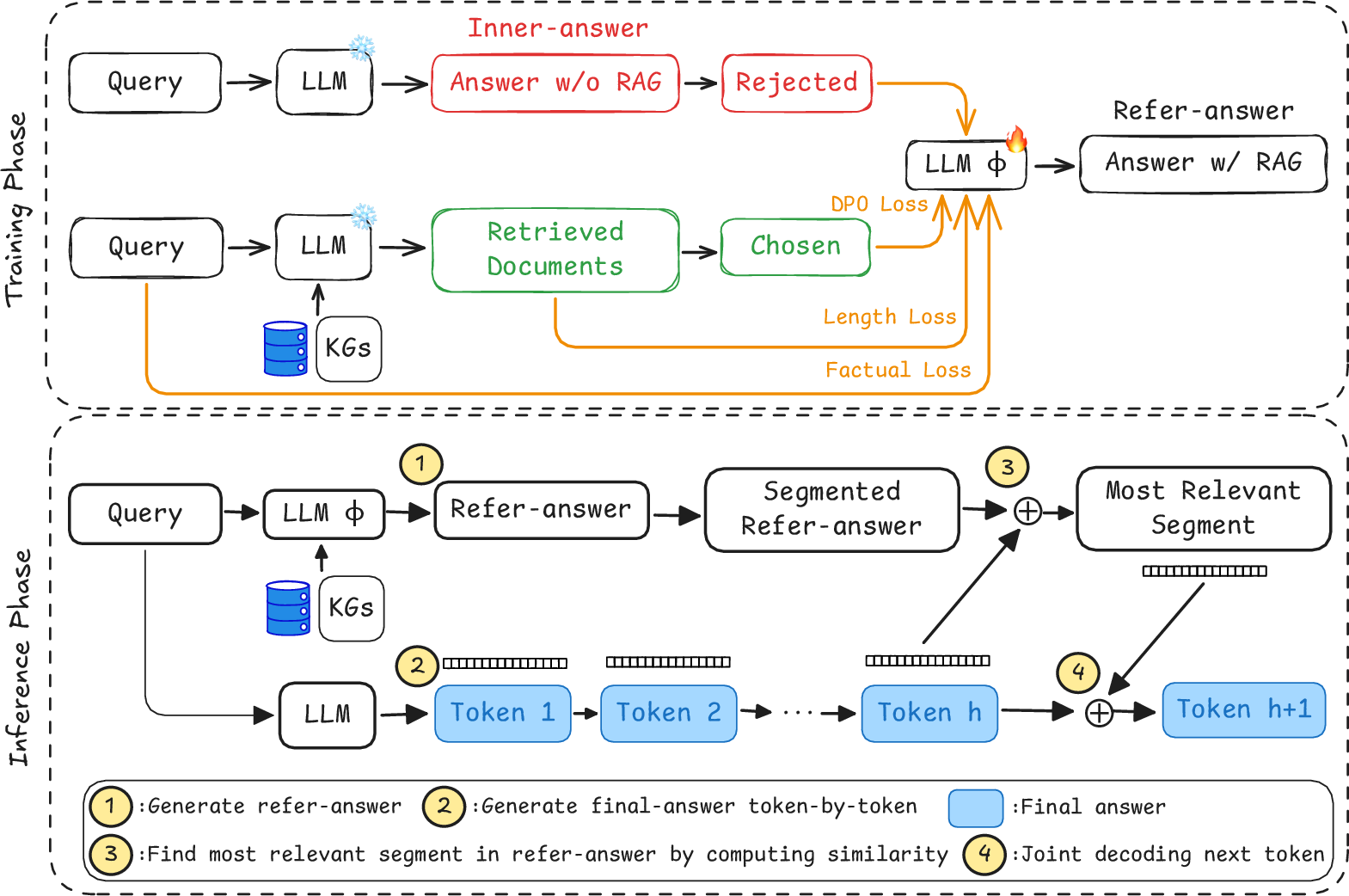
Figure 1: Overview of the GuarantRAG framework, decoupling reasoning from evidence and merging with joint decoding for precise integration.
Analysis of Knowledge Integration and Fusion Granularity
GuarantRAG’s segment-level decomposition enables fine-grained alignment between factual claims and supporting evidence, sharply improving reference usage efficiency compared to token- or sentence-level alternatives (Figure 2). Attention distribution analysis confirms that segment-level matching achieves broader and more uniform coverage of reference information, minimizing attention collapse and maximizing retrieval utility.
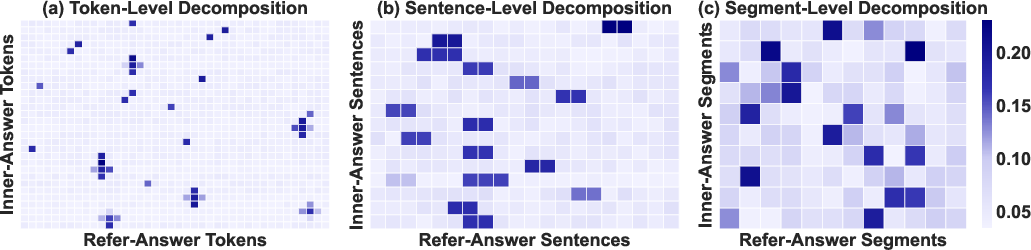
Figure 2: Attention distribution heatmaps revealing superior segment-level fusion granularity in GuarantRAG.
Experimental Evaluation
Extensive experiments across five diverse QA benchmarks (NQ, TruthfulQA, WoW, HotpotQA, ELI5) and multiple retrievers (BM25, SPLADE-v3, RetroMAE, HyDE) demonstrate that GuarantRAG sets the new standard for integration quality. Notably, GuarantRAG achieves up to 12.1% improvement in answer accuracy and 16.3% reduction in hallucination rate over advanced baselines such as SOLAR, DRAGIN, and P-RAG. Entity precision and structure coherence metrics further indicate that GuarantRAG outperforms both vanilla models and retrieval-enhanced competitors, even as model capacity grows.
Robustness studies show that GuarantRAG’s performance gains are stable across query length, reasoning complexity, and reference document lengths (Figure 3), with particularly strong improvements on complex multi-hop queries and long-form documents. Computational efficiency analysis reveals only a modest token increase (16%) and a 33% latency overhead relative to standard RAG, with substantially higher quality gains.
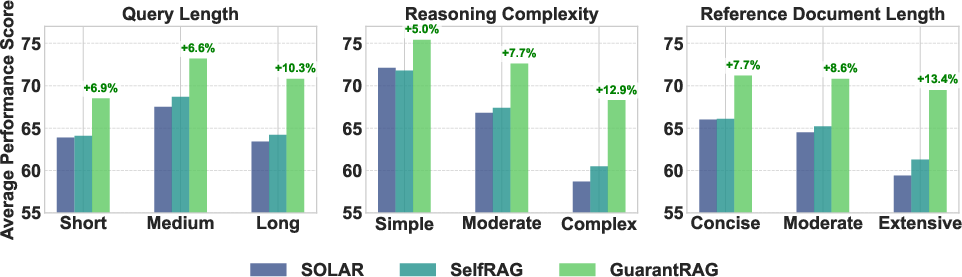
Figure 3: GuarantRAG consistently outperforms SOLAR and SelfRAG for varying queries, reasoning complexities, and document lengths.
Furthermore, GuarantRAG demonstrates resilience to noisy retrieval. Controlled injection of irrelevant documents indicates markedly less performance degradation relative to baselines, preserving 90.3% of original performance under 50% retrieval noise scenarios (Figure 4).
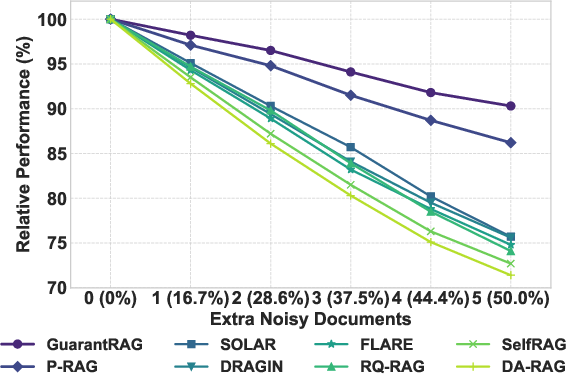
Figure 4: Performance degradation under retrieval noise, with GuarantRAG exhibiting superior robustness compared to baseline approaches.
Ablation and Component Analysis
Ablation studies confirm that length control and relevance constraints contribute most strongly to final performance, followed by DPO-based refer-answer optimization and segment-level fusion. Each component produces statistically significant gains, demonstrating individual and joint efficacy. Importantly, segment-level fusion, tested independently, enhances vanilla RAG models, confirming its generality beyond GuarantRAG.
Case studies on knowledge-intensive queries validate GuarantRAG's ability to strategically inject reference information into the narrative while maintaining structural fluency, outperforming baselines that frequently misplace facts or leave critical omissions. Inner-answer analysis on HotpotQA reveals high structural validity (~90%), confirming decoupling safety: parametric reasoning maintains logical templates even when factual grounding is missing, allowing reliable structural skeletons to be fused with external evidence.
Practical and Theoretical Implications
GuarantRAG establishes a new paradigm for knowledge integration: rather than relying on implicit fusion at the prompt or attention level, explicit complementarity and fine-grained fusion deliver optimal solutions for complex reasoning and factuality needs. The framework’s principled decomposition resolves the trade-off between factual precision and reasoning coherence that has limited RAG architectures. Segment-level contrastive fusion could prove foundational for future systems seeking robust knowledge synthesis in open-domain settings, medical QA, long-form scientific explanations, or other domains requiring precision and narrative fluency.
From a theoretical standpoint, GuarantRAG's explicit management of parametric-nonparametric conflict underscores the need for architectures capable of reasoning about provenance, contradiction, and fact entailment, extending beyond sequence modeling into explicit knowledge alignment domains. Future developments may integrate more sophisticated segmenting techniques, domain-adaptive DPO objectives, or API-accessible fusion approximations bridging hidden-state interventions and prompt-based sampling strategies.
Conclusion
GuarantRAG systematically addresses the knowledge integration bottleneck in RAG. Through explicit decoupling, contrastive evidence optimization, and dynamic fusion, it achieves significant accuracy gains, robust hallucination suppression, and structural coherence in complex QA tasks. The segment-level joint decoding paradigm provides a scalable foundation for principled knowledge integration, applicable to both open-source and commercial API-based LLMs, with minimal additional computational cost and strong resilience to retrieval noise. This establishes GuarantRAG as a more principled, practical, and scalable solution for reliable retrieval-augmented generation (2604.08046).

