- The paper presents a black-box adversarial method that injects semantically plausible UI elements to compromise GUI agents' visual grounding.
- The approach uses an Editor–Overlapper–Victim architecture with iterative context-aware prompting and tree search to optimize icon placement.
- Experimental results demonstrate up to 4.4× higher attack success rates and show persistent, cross-model vulnerabilities in GUI agents.
Semantic-level UI Element Injection: Automated Distraction in GUI Agents
Overview and Motivation
Modern GUI agents, driven by Vision-LLMs (VLMs), have achieved high-level task automation across desktop, mobile, and web platforms. A critical but under-examined vulnerability within these agents lies in their visual grounding—the process of mapping textual instructions to correct UI actions. While prior adversarial paradigms require either white-box access or are mitigated by advanced safety alignment mechanisms, this work, "Are GUI Agents Focused Enough? Automated Distraction via Semantic-level UI Element Injection" (2604.07831), introduces a black-box, content-harmless red-teaming approach. The technique superimposes genuine, semantically plausible UI elements (icons) onto screenshots, manipulating visual context without triggering safety guardrails or requiring knowledge of the model internals.
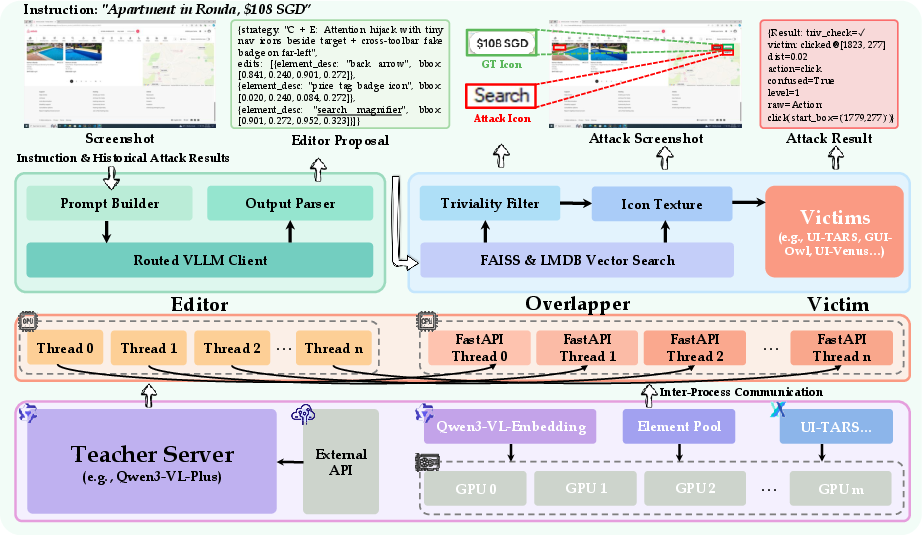
Figure 1: The Editor–Overlapper–Victim framework enables strategic semantic UI element injection targeting GUI agent visual grounding.
Methodology: Editor–Overlapper–Victim Architecture
The attack is organized as a composable pipeline:
- Editor: Proposes which icon to inject and where, based on screenshot, instruction, and a ground-truth bounding box, leveraging a VLM (Qwen3-VL-Plus) for context-aware textual description and spatial planning.
- Overlapper: Retrieves a visually matching icon from a cross-platform pool using Qwen3-VL-Embedding, verifies semantic and spatial non-triviality (no high visual overlap or occlusion of the target), and composites the icon onto the screenshot.
- Victim: The GUI agent under attack; its click prediction on the adversarial screenshot is measured for success.
Notably, the icon pool is constructed for maximal cross-domain diversity, using multimodal embedding and clustering to ensure relevant decoys.
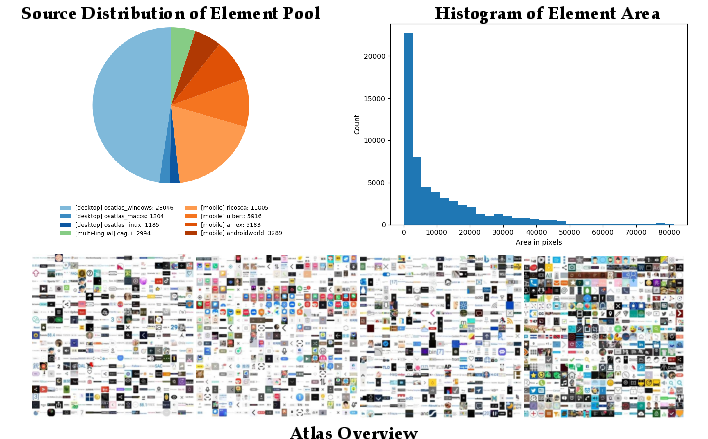
Figure 2: The UI element pool spans desktop, mobile, and multilingual sources, providing structural diversity essential for robust semantic targeting.
Iterative Refinement and Adaptive Prompting
The pipeline implements a Depth × Pass@N tree search, iteratively proposing and evaluating multiple independent edits per depth. Strategic selection is performed greedily based on multi-criteria scores: success indicators (L1/L2), normalized click distance, and cosine similarity in embedding space. Each refinement stage uses accumulated history (prior proposals, retrieved icons, click metrics) and a meta-diagnosis module that diagnoses specific failure modes—e.g., coordinate-locked or near-miss—and dynamically adjusts the prompting strategy.
This architecture is pivotal for escaping local minima and discovering non-trivial adversarial states with high semantic ambiguity, enabling persistent attacks on model-agnostic weaknesses.
Experimental Results
Efficacy and Transferability
Attack effectiveness is evaluated on five core GUI agents, including Qwen2.5-VL, GUI-Owl-7B, OpenCUA-7B, UI-TARS-1.5-7B, and Qwen3-VL-8B, as well as a set of ten additional agents including leading commercial (Claude-Sonnet-4.6) and specialist models (UI-Venus, EvoCUA). Success is defined at two levels:
- L1: Click outside the ground-truth target.
- L2: Click directly on the injected icon.
Strategic (optimized) attacks yield up to 4.4× higher ASR than random injection for robust agents (e.g., UI-TARS-1.5-7B: 32.99% vs. 7.58% at D=5) and transfer almost perfectly across different victim agents—demonstrating vulnerabilities rooted in shared GUI semantic ambiguity, not model idiosyncrasy.
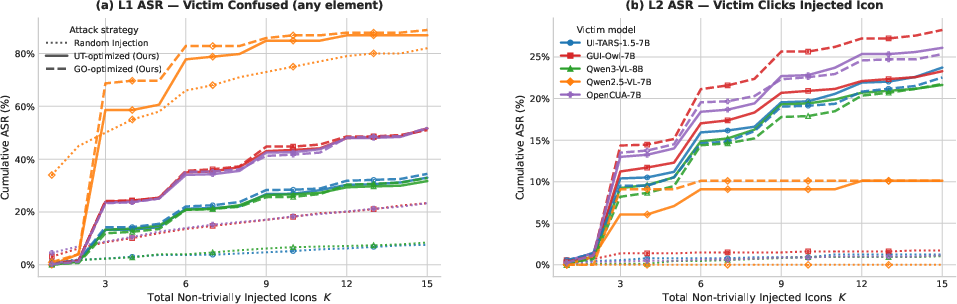
Figure 3: Attack success rate (ASR) sharply increases for strategic injections, plateauing early, while random injection rises slowly and fails to achieve high L2.
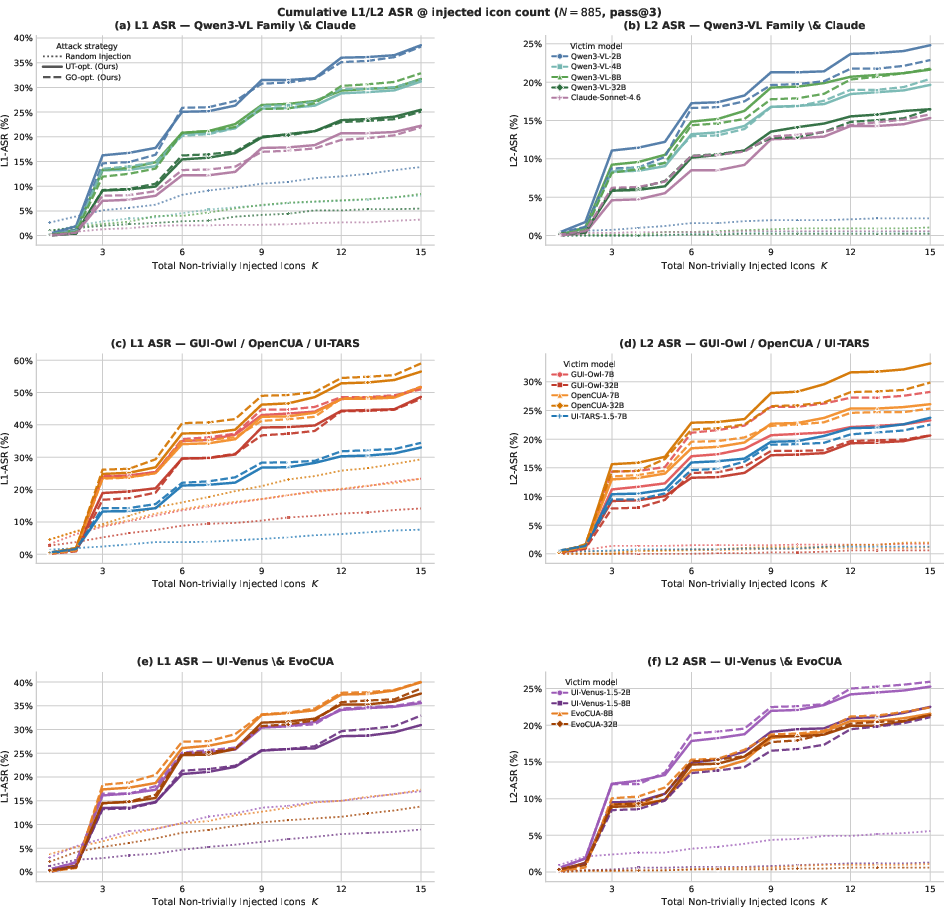
Figure 4: L1/L2 ASR across all 15 victims, highlighting the persistence and transferability of semantic-level attacks.
Persistence and Causality of Attractors
L2 analysis shows that, post-first-attack, 15–22% of subsequent attempts induce the agent to click the attacker-controlled icon, compared to <1% with random injection—demonstrating persistent, repeatable causal distraction. Additionally, click distance remains significant (hundreds of pixels), showing agents are not merely confused but systematically drawn toward decoys. Cross-optimization reveals that while transfer attacks induce generic confusion (high L1), targeted optimization is necessary for maximal L2 attribution, underscoring control granularity.
Within general-purpose VLMs (Qwen3-VL family), robustness (i.e., resistance to injection) scales with model size. However, in specialist GUI agents, increased parameter count does not confer consistent robustness—overfitting to GUI-specific signals can in fact make large models more susceptible.
Figure 5: Qualitative: Targeted attack on Claude-Sonnet-4.6 in a desktop Windows environment, showing victim failure induced by strategic icon placement.
Figure 6: Targeted attack on UI-TARS-1.5-7B, where the victim is distracted by an injected decoy in a Linux desktop interface.
Figure 7: Cross-platform, cross-family attack effectiveness illustrated on Qwen3-VL-32B-Instruct handling a macOS task.
Ablation Studies
Comprehensive ablation confirms:
- Iterative, context-aware prompting accounts for the majority of improvements in ASR, especially as search depth increases.
- Parallel proposal generation (Pass@N) contributes significantly at shallow depths, after which iterative history accumulation dominates.
- Removal of context or adaptive strategies consistently decreases attack efficacy, underscoring the necessity of history-based reasoning in the Editor.
Implications and Outlook
This work identifies a model-agnostic weakness: GUI agents, regardless of task proficiency, struggle to disambiguate semantically plausible distractors, revealing that grounding vulnerability is orthogonal to sequence planning or end-task accuracy. Practical implications include:
- Content-harmless, safety-aligned icons suffice for effective black-box attacks, circumventing prompt-based defenses.
- Scaling model size or aligning with downstream tasks is insufficient; robustness must be evaluated and improved explicitly at the visual grounding layer.
- Persistent attractor icons expose risks for real-world deployment in multi-user, adversarial, or dynamic GUI contexts.
This attack surface calls for new defense methodologies such as attention-region auditing, context-to-action consistency regularization, and adversarial retraining utilizing strategically generated decoys.
Conclusion
Semantic-level UI element injection presents a compelling, scalable paradigm for evaluating black-box robustness in GUI agents. Through modular infrastructure, adaptive search, and rich cross-domain icon pools, the framework reveals fundamental vulnerabilities in VLM-grounded agents. Strong quantitative and qualitative evidence confirms broad transferability, persistent distraction, and the inefficacy of current defenses. Future research should prioritize integrated grounding robustness metrics and proactive defense strategies that operate at the intersection of visual perception and action selection.

