- The paper introduces a novel dual-attention framework that uses differential cross-modal attention to reduce bias towards real content.
- It employs multi-scale self-attention to capture temporal context and effectively fuse audio-visual signals.
- Experimental evaluation on FakeAVCeleb shows state-of-the-art performance with 98.75% accuracy and 98.83% AUC.
MSCT: Differential Cross-Modal Attention for Deepfake Detection
Introduction
The proliferation of generative models such as VAEs, GANs, and diffusion-based methods has significantly lowered the barriers for the creation of highly realistic synthetic audiovisual content. In response, deepfake detection research has rapidly evolved, with a particular focus on leveraging multi-modal cues due to the limited robustness of unimodal detectors. However, existing audio-visual (AV) deepfake detectors predominantly rely on modal alignment through cross-modal similarity measurement, which may inadvertently bias attention towards real content and undermine sensitivity to forged regions. This work introduces the Multi-Scale Cross-Modal Transformer (MSCT), a novel architecture featuring two task-specific attention modules—differential cross-modal attention (DCA) and multi-scale self-attention (MSSA)—to address the nuanced challenges of feature extraction and modal alignment deviation inherent in deepfake detection.
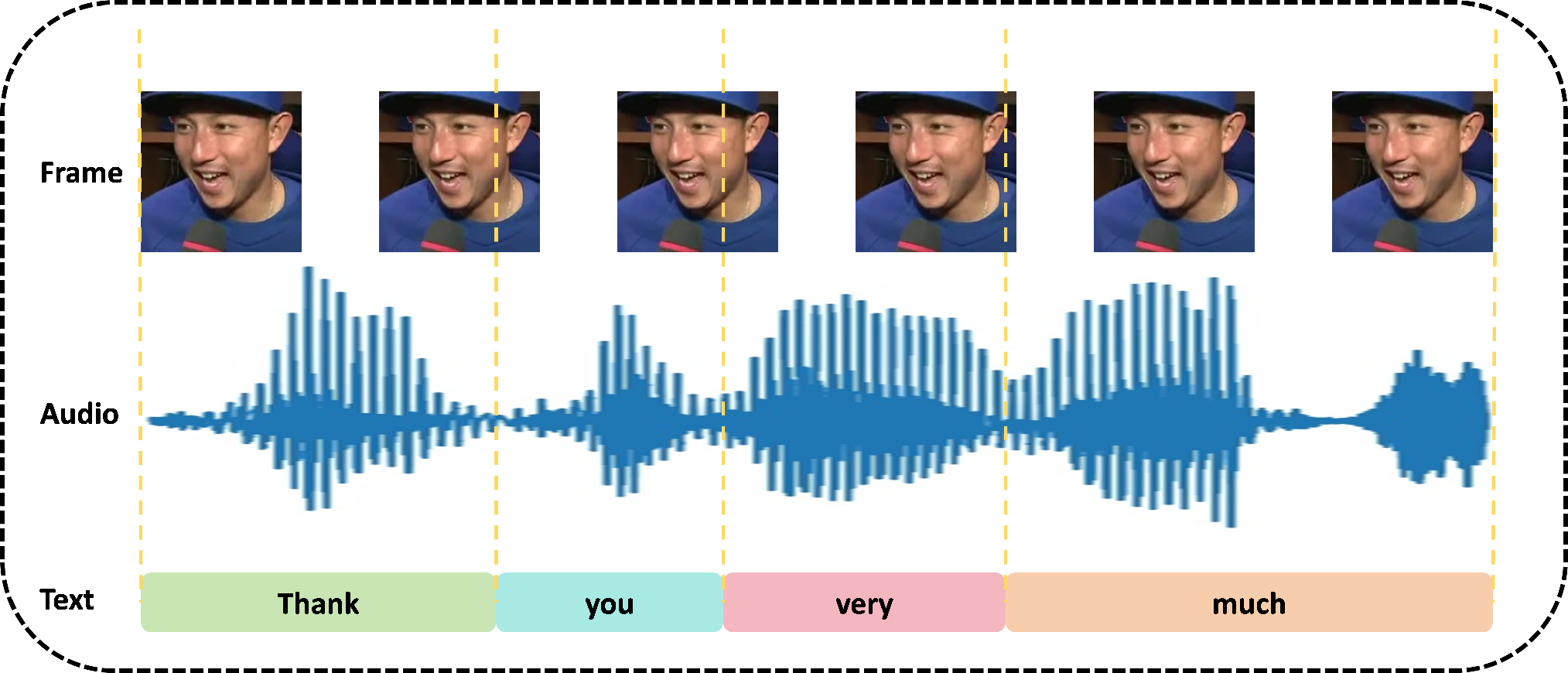
Figure 1: The video and audio parts corresponding to each frame contain incomplete text information, necessitating temporal context integration.
Architecture and Methodology
The proposed MSCT framework integrates a sophisticated encoder and classification pipeline that exploits both unimodal and cross-modal discriminative signals. The encoder is composed of pre-encoders for audio and video streams and a transformer module engineered with two specialized attention mechanisms. Modal branches are regularized both individually and jointly via cross-entropy and cross-modal alignment losses to preserve the integrity of modality-specific features and encourage robust fusion.
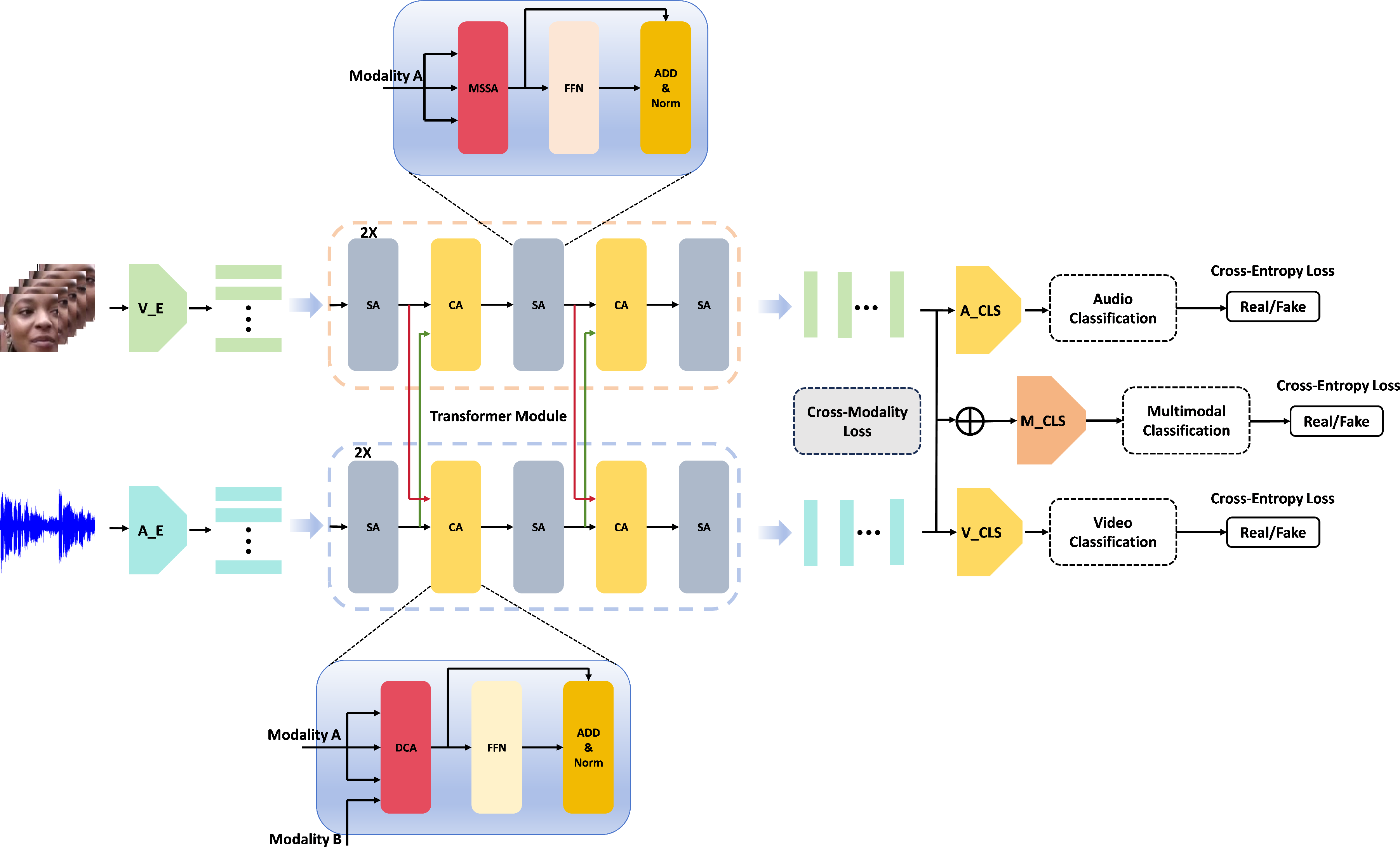
Figure 2: MSCT architecture, comprising pre-encoders and a transformer module with self- and cross-attention blocks for effective fusion and classification.
Differential Cross-Modal Attention (DCA)
DCA is explicitly designed to mitigate the real-content bias of conventional cross-modal attention. It operates by subtracting cross-modal attention matrices from self-attention matrices, amplifying the focus on subtle discrepancies characteristic of forged content. During training, the cross-modal alignment loss pushes the similarity of AV signals in fake samples toward zero, resulting in stronger constraints on the cross-attention matrices for fakes, thereby enhancing the discriminative potential of the differential attention for forgery cues.
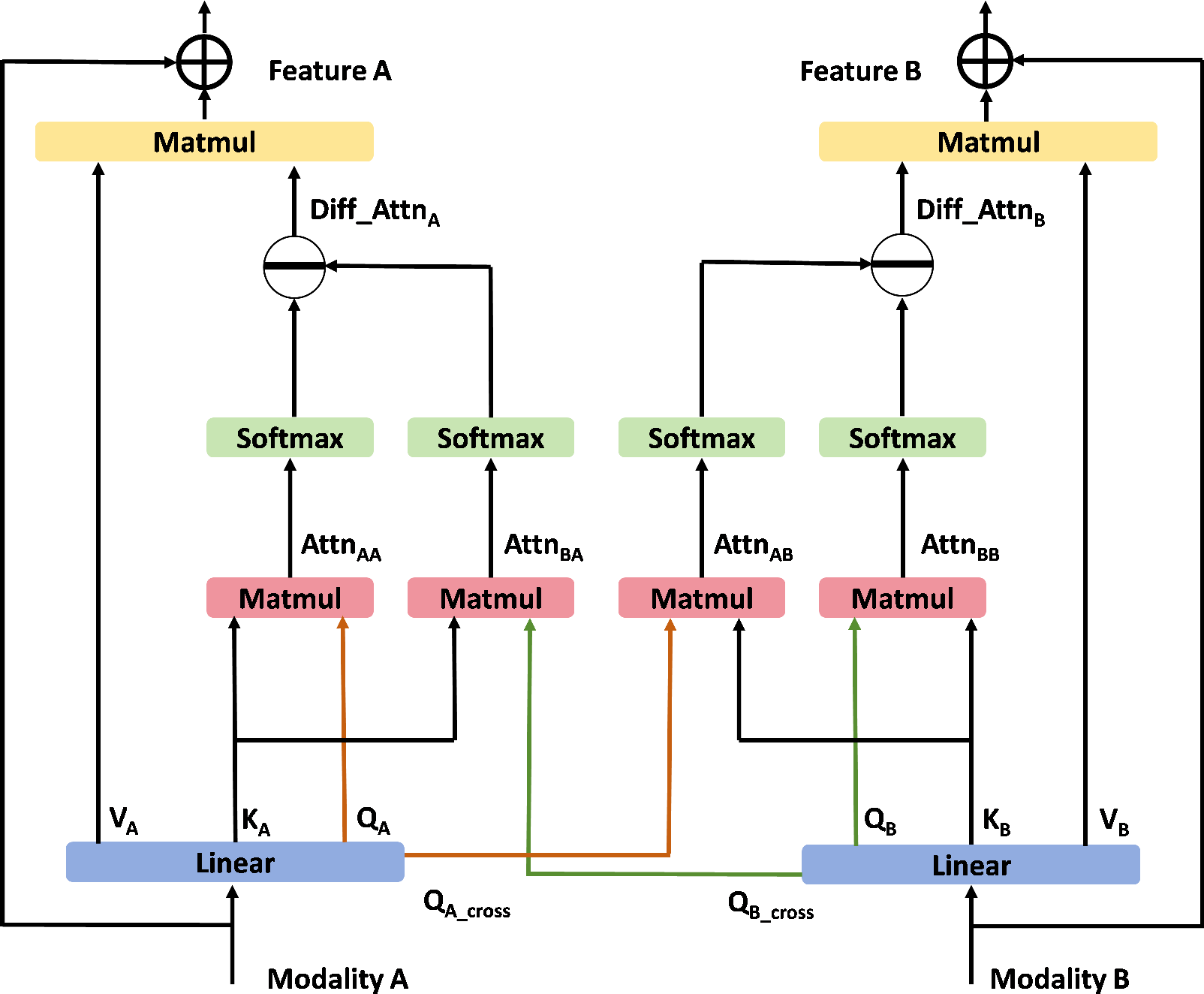
Figure 3: Differential cross-modal attention module isolates discriminative signals by contrasting self-attention and cross-attention matrices.
Multi-Scale Self-Attention (MSSA)
Conventional transformers lack the explicit mechanism to aggregate temporal features across multiple scales, a critical deficiency given that deepfake traces may reside in temporally adjacent frames. MSSA remedies this by partitioning the key matrix into multiple scales and employing scale-specific 2D convolutions, thereby equipping the transformer with multi-scale temporal receptive fields and adaptive integration of neighboring embeddings.
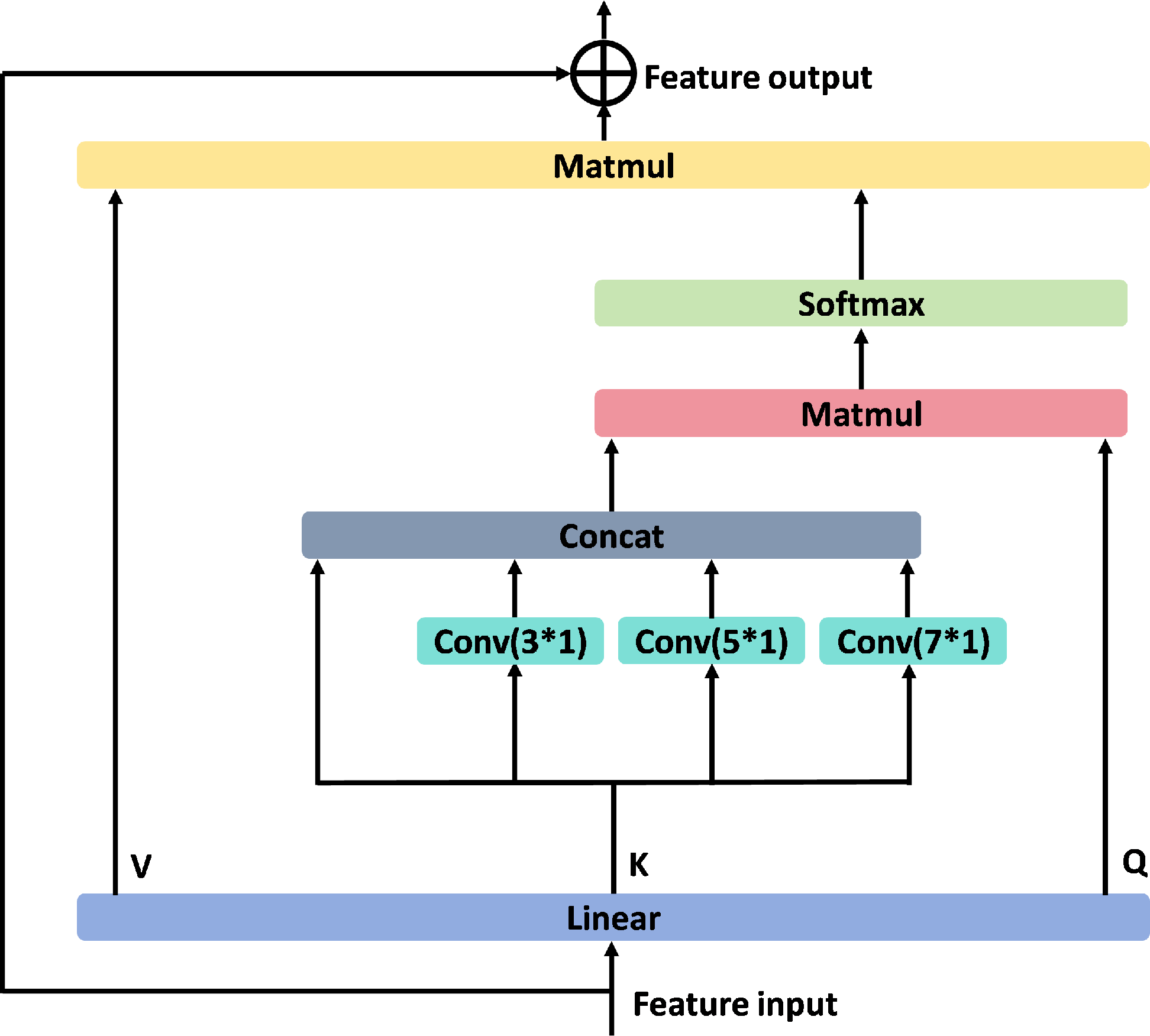
Figure 4: Multi-scale self-attention module aggregates contextual features across multiple temporal scales via convolutional processing.
Loss Functions
The loss function is a composite of cross-entropy terms for modality-specific and fused predictions, and a cross-modal alignment loss that penalizes inconsistent AV representations. The alignment loss is tailored to encourage high similarity for genuine content and low similarity for fakes. This synergy ensures both modality preservation and effective cross-modal fusion, compatible with the specialized DCA design.
Experimental Evaluation
MSCT was evaluated on the FakeAVCeleb dataset—a challenging benchmark comprising over 20,000 fake and 500 real samples, stratified across four AV manipulation types. The regime incorporates state-of-the-art pre-processing, including DLIB-driven face detection and cropping for the video stream, Res2Net with wavelet convolution for visual encoding, and linear projection for audio encoding. Feature fusion is achieved with an AV-transformer stack, optimized over 200 epochs using Adam.
Results and Ablation Analysis
MSCT achieves 98.75% accuracy and an AUC of 98.83% on FakeAVCeleb, far surpassing prior baselines such as MRDF-CE (94.05% accuracy, 92.43% AUC) and BusterX (96.30% accuracy) (2604.07741). Ablation further reveals that DCA and MSSA contribute additive gains, with their combined application yielding maximum performance. DCA provides a more substantial impact compared to MSSA, underscoring the criticality of optimized cross-modal attention in AV deepfake detection.
Representation Analysis
T-SNE visualizations demonstrate superior class separability achieved by MSCT with DCA and MSSA compared to traditional attention mechanisms. Specifically, the joint application expands the embedding discrimination across real and manipulated classes, reflecting improved alignment and fusion of AV modalities.
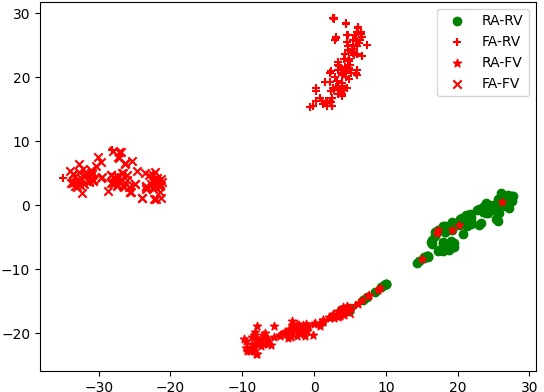
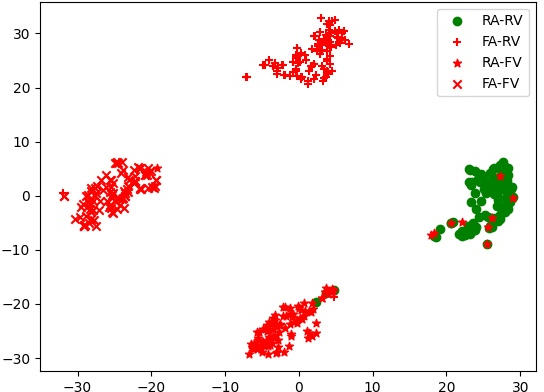
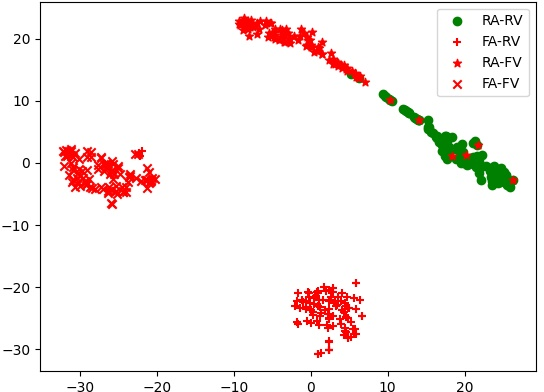
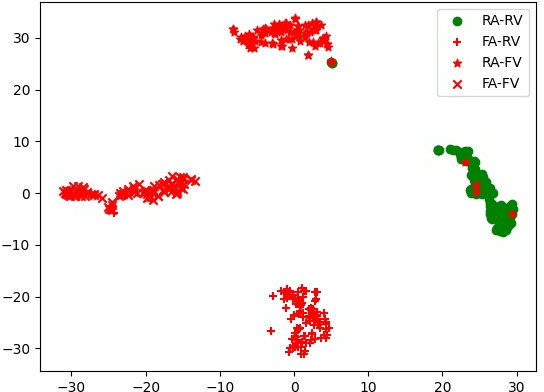
Figure 5: T-SNE results highlight the discriminative power of DCA and MSSA-enabled embeddings across various fake and real categories.
Implications and Outlook
The MSCT framework substantially advances the theoretical and practical state-of-the-art in audio-visual deepfake detection. The introduction of differential cross-modal attention aligns the optimization objective of cross-modal similarity with the attention mechanism, resolving unwanted real-content bias. Multi-scale self-attention enhances temporal robustness, critical for video analysis. The strong numerical results indicate that this paradigm is well-suited for real-world deployment scenarios requiring high precision in detecting sophisticated AV forgeries.
Potential future directions include extending MSCT to general multi-modal anomaly detection, adapting the architecture for streaming applications, and exploring interactions between additional modalities (e.g., text, sensor data). Advancements in generative manipulation will inevitably necessitate further refinements in cross-modal alignment, attention design, and explainability for robust, scalable, and interpretable detection systems.
Conclusion
MSCT introduces a principled dual-attention transformer framework for audio-visual deepfake detection, featuring differential cross-modal attention and multi-scale self-attention modules. The architecture achieves state-of-the-art discriminative performance on benchmark datasets, validating the efficacy of its design. These innovations reorient attention mechanisms for alignment with detection objectives and equip the model with enhanced temporal sensitivity, setting a new trajectory for multi-modal forgery analysis.

