- The paper introduces VersaVogue, a unified framework that merges garment generation and virtual dressing via a multi-condition synthesis pipeline.
- It leverages a trait-routing attention module with a mixture-of-experts strategy to enhance feature disentanglement and achieve superior performance on metrics like FID, LPIPS, and SSIM.
- The approach incorporates automated multi-perspective preference optimization to align outputs with human preferences, resulting in enhanced realism and precise attribute control.
Unified Controllable Fashion Image Synthesis via VersaVogue
The VersaVogue framework is designed to address two fundamental yet previously disconnected tasks in fashion synthesis: garment generation and virtual dressing. Garment generation refers to creating high-fidelity apparel designs from multimodal specifications, while virtual dressing involves the photorealistic rendering of these designs on human models. Prior approaches treat these as distinct problems, resulting in fragmented workflows, limited flexibility, and inefficient end-to-end solutions. A core technical challenge arises from synthesizing images conditioned on complex, heterogeneous inputs (e.g., multiple garments, structural priors, textual descriptions) while preserving precise attribute control, avoiding semantic interference, and maintaining visual fidelity.
VersaVogue proposes a unified multi-condition controllable synthesis formulation, capable of seamlessly bridging garment creation and dressing in a single pipeline. This redefines fashion synthesis as a dynamic, multi-attribute generative process, aligning technical development with industry workflows.
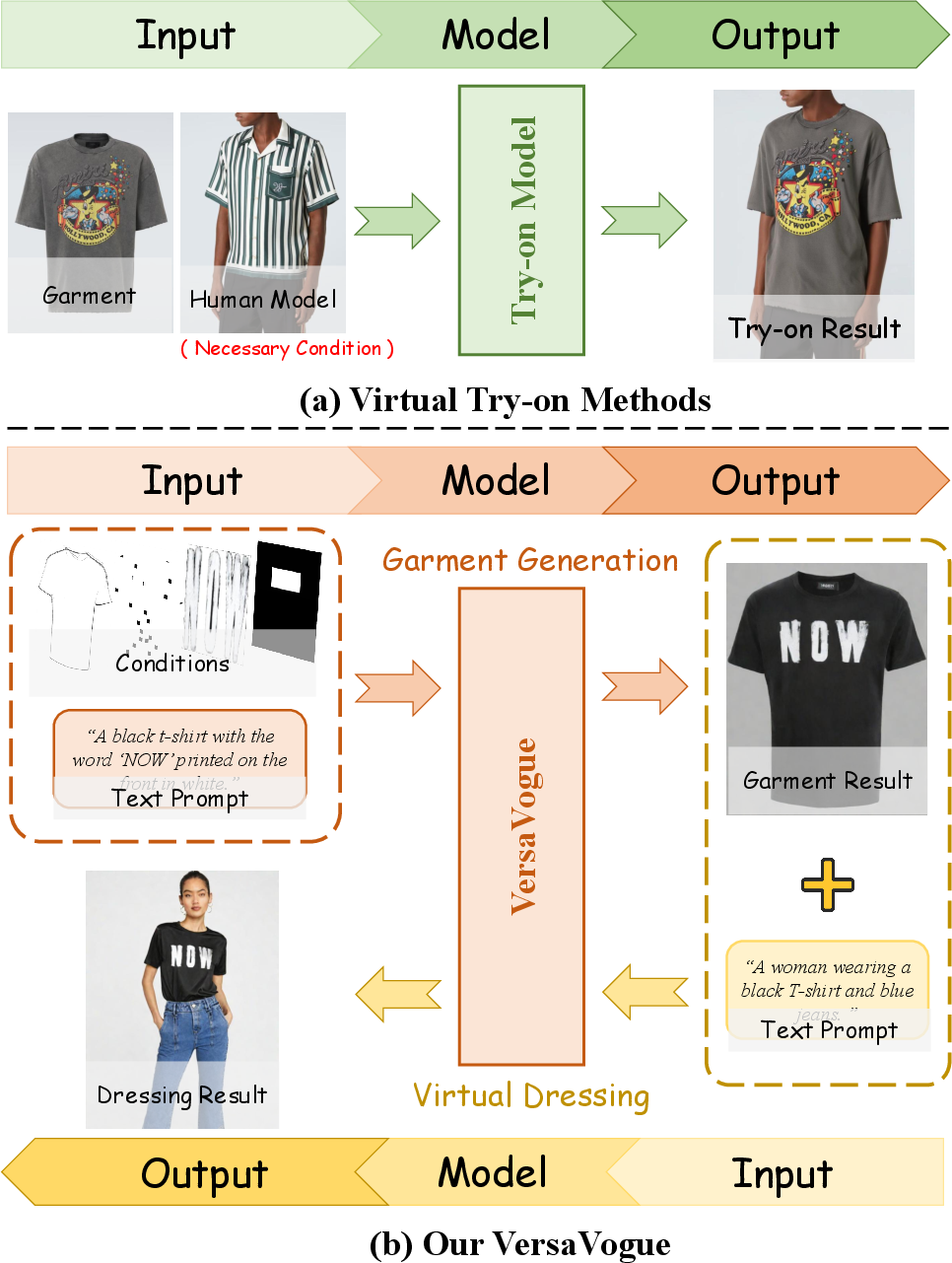
Figure 1: Comparison of workflows and input conditions: virtual try-on methods restrict the pipeline to showcase stages, whereas VersaVogue synthesizes on-body results directly from multimodal specifications.
Architectural Advances: Trait-Routing Attention and Mixture-of-Experts
To dynamically orchestrate the synthesis of complex apparel images, VersaVogue introduces a trait-routing attention (TA) module rooted in the mixture-of-experts (MoE) paradigm. The system leverages a fitting UNet equipped with isolated self-attention layers for independent extraction of each conditional input, maintaining semantic integrity and avoiding information bleed. These feature streams are subsequently fused through the TA module, which performs token-wise cross-attention between denoising latents and condition features. The MoE mechanism enables adaptive (top-k) routing of tokens to specialized expert branches, mitigating feature entanglement and facilitating attribute disentanglement across SDXL layers. This enhances controllability over texture, shape, and chromaticity, supporting the injection of highly entangled and interdependent apparel attributes.
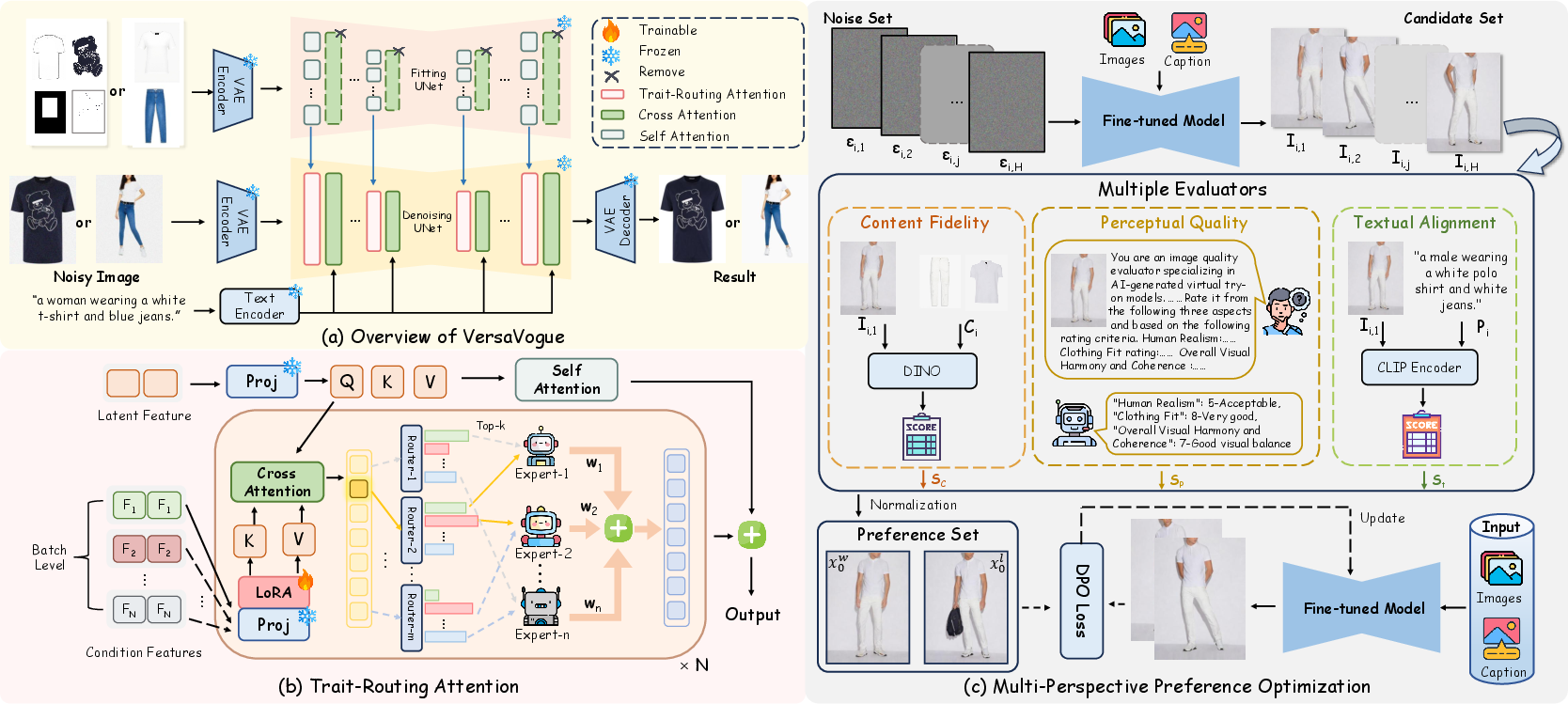
Figure 2: Overview of architecture: distinct condition extraction, dynamic feature routing with Top-k MoE, and multi-perspective optimization.
Ablation studies demonstrate that the (E4, K2) configuration achieves the optimal trade-off between feature diversity and fidelity. Both dense MoE and naive direct injection degrade performance, underscoring the necessity for sparse, adaptive feature routing.
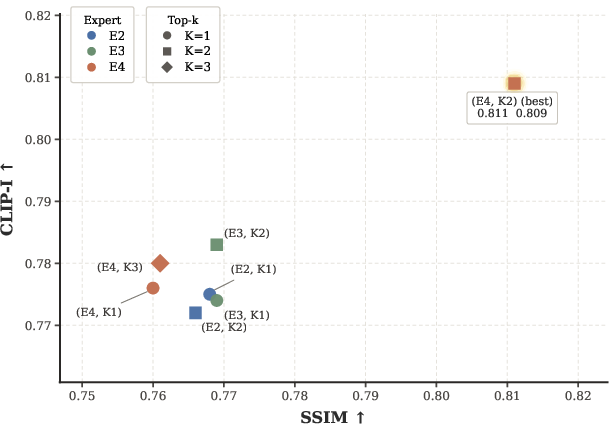
Figure 3: Ablation on expert count and routing parameters, showing that four experts and top-two routing maximize alignment and fidelity.
Preference Alignment via Automated Multi-Perspective Optimization
To further drive the synthesis toward outputs preferred by humans, VersaVogue incorporates a multi-perspective preference optimization (MPO) mechanism. This pipeline automates the construction of preference pairs by evaluating candidate images across three axes—content fidelity (via DINO embeddings), perceptual quality (using CogVLM with structured prompts), and text-image alignment (via CLIP similarity). Winner-loser pairs are selected by aggregating normalized scores, enabling robust dataset generation without human annotation or specialized reward models.
Direct preference optimization (DPO) is used to align the generative model toward these preferences, formally maximizing the margin between likelihoods for preferred/dispreferred samples as measured by weighted MSE of noise prediction within the diffusion process. This refines both realism and controllability beyond the reach of conventional single-metric tuning.
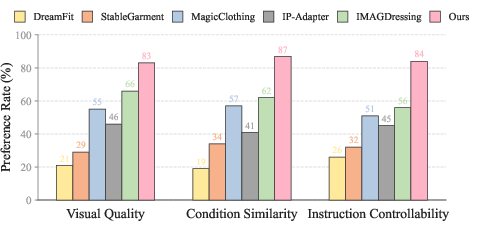
Figure 4: User study results validate that VersaVogue achieves the highest scores for realism and preference across multiple criteria.

Figure 5: Examples from the automatically synthesized preference dataset used for DPO-based alignment.
Experimental Evaluation
Qualitative and Quantitative Results
Comprehensive benchmarks across garment generation (GarmentBench) and virtual dressing (VITON-HD, DressCode, DressCode-MR) demonstrate that VersaVogue outperforms a broad spectrum of SOTA baselines. In garment synthesis, it achieves pronounced gains in LLA, CSS, FID, and LPIPS, substantiating both local detail preservation and global harmony. Notably, adapter-based methods and simple concatenation strategies fail at multi-condition scenarios, suffering from attribute entanglement and quality loss.
For single- and multi-garment virtual dressing, VersaVogue excels in photorealism and structural logic while maintaining fine-grained semantic alignment and consistent control under heterogeneous inputs. It achieves the best FID, CLIP-I, SSIM, and LPIPS metrics across all datasets.
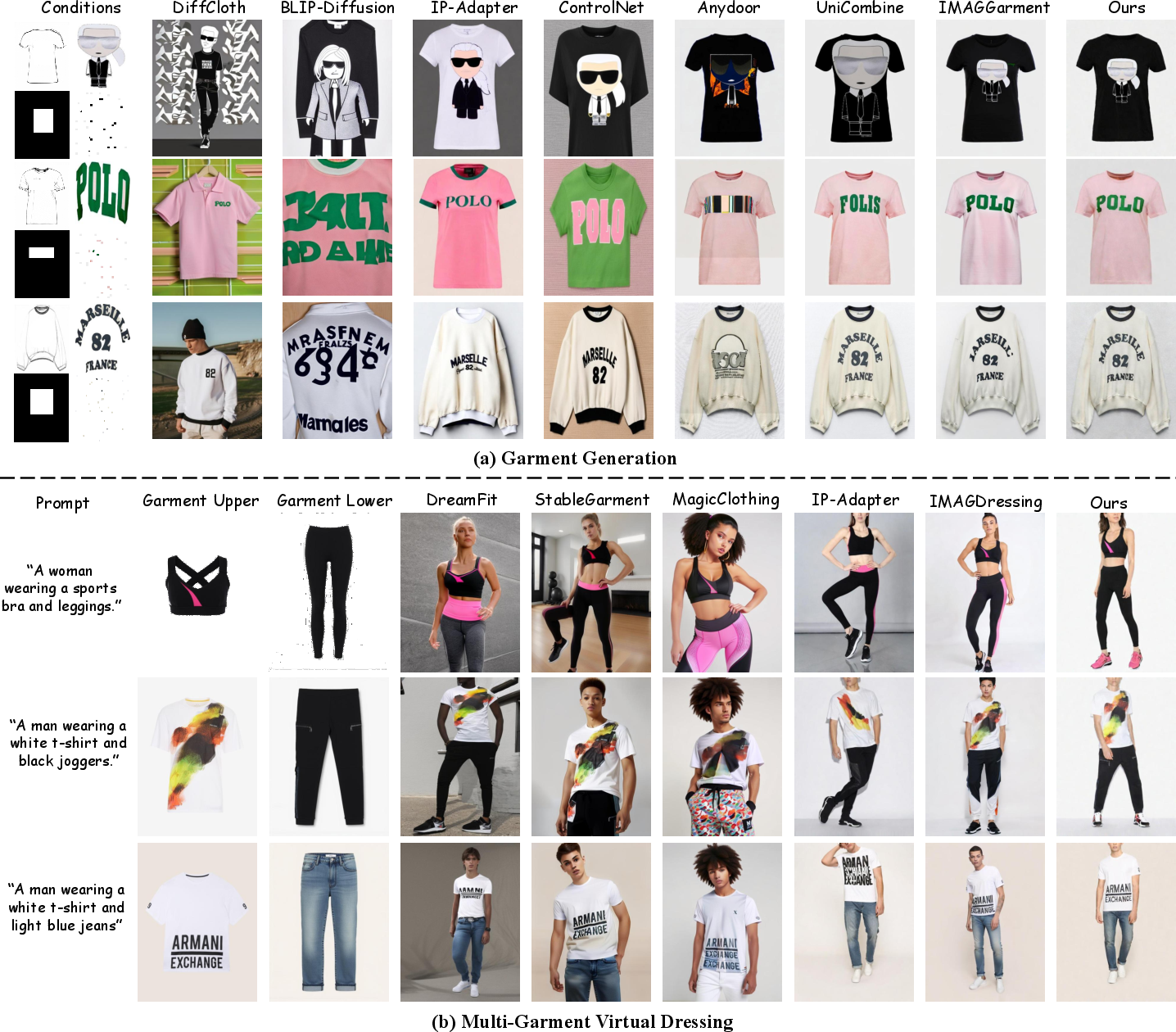
Figure 6: Qualitative comparison—VersaVogue delivers superior realism and controllability in garment generation and multi-garment virtual dressing.
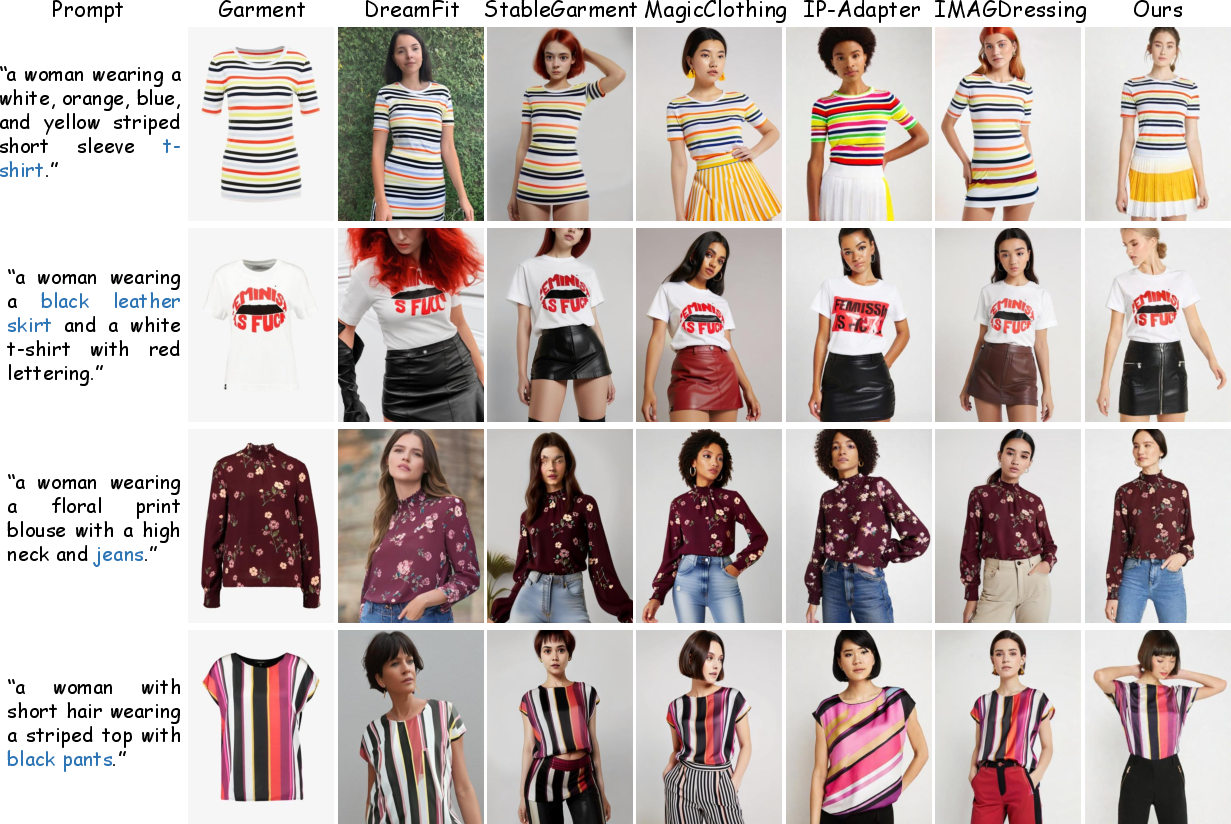
Figure 7: Comparison with SOTA methods on single-garment virtual dressing, demonstrating superior text-alignment and detail preservation.
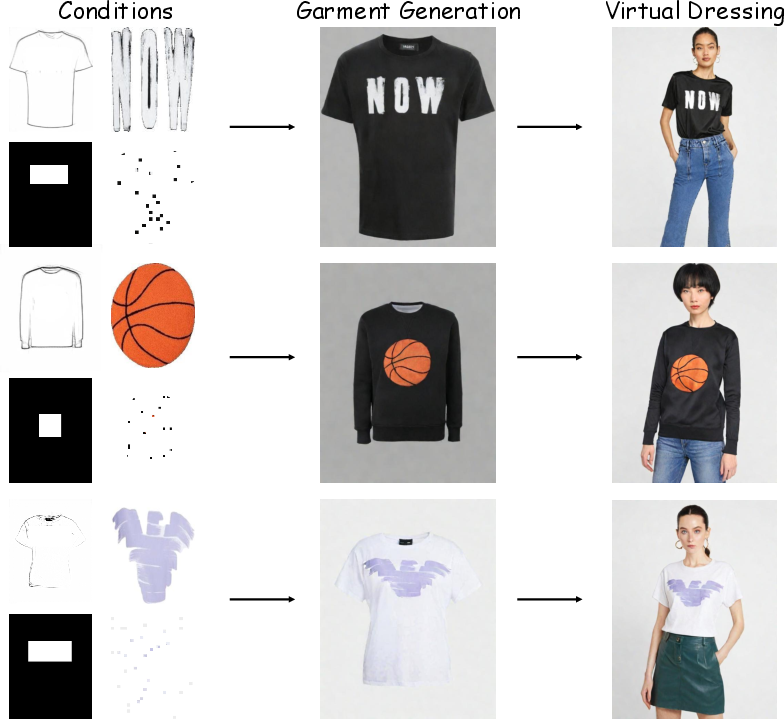
Figure 8: Real-world deployment—enables an integrated workflow from garment design to virtual dressing, supporting user-driven customization.
Ablation and Mechanistic Analysis
Ablation studies confirm the necessity of TA and MPO modules; omission leads to dramatic drops in CLIP-I and SSIM, with hybrid conditions resulting in semantic conflation and degraded output. Routing entropy analysis reveals that token allocation is highly adaptive—tokens are neither randomly nor uniformly assigned, but routed according to garment-specific characteristics. This confirms the layer-wise attribute separation engineered by the TA module.

Figure 9: Ablation study results showing loss of attribute separation and realism in ablated configurations.
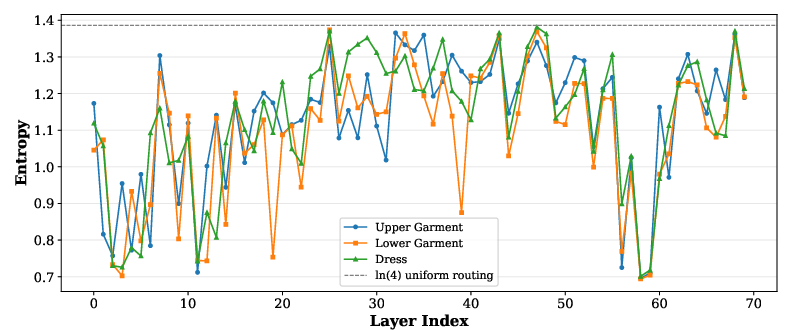
Figure 10: Routing entropy dynamics—token distribution across experts adapts to garment category and layer structure, enabling precise attribute handling.
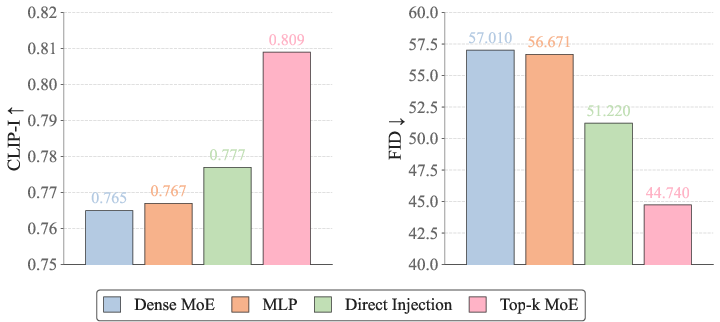
Figure 11: Injection strategy analysis—Top-k MoE maximizes text-image consistency (CLIP-I) and visual fidelity (FID).
Practical Implications and Future Directions
VersaVogue's unified formulation and dynamic routing mechanisms achieve significant gains in synthesis quality, controllability, and workflow efficiency. It supports streamlined apparel design, direct virtual try-on from textual specifications, and photorealistic on-body rendering without cumbersome intermediaries. This delivers strong potential for personalization in e-commerce, rapid product prototyping, and automated editorial processes.
The MoE design ensures computational efficiency by sparsely activating experts per token, limiting FLOPs growth despite large parameter counts. However, the method remains constrained by VRAM demands and inference latency due to parallel UNets and expert branching. Integration of acceleration techniques such as Latent Consistency Models and lighter MoE architectures would address scalability.
VersaVogue is currently limited to 2D synthesis; extension to 3D garment generation and spatial virtual try-on is a natural progression, necessary for immersive applications and accurate physical simulation. Enhancing implicit localization and feature disentanglement for highly entangled reference images is also essential.
Conclusion
VersaVogue offers a rigorous, unified approach to fashion image synthesis, explicitly bridging garment generation and virtual dressing through adaptive trait-routing attention and preference-aligned optimization. The framework achieves state-of-the-art results in visual fidelity, semantic control, and human preference alignment, validated both quantitatively and qualitatively across standard fashion benchmarks. Its methodology sets a new paradigm for future research in controllable image synthesis, and its implications for industry workflows and personalized content generation are substantial. Further developments toward efficient computation and spatial reasoning will push its applicability beyond current boundaries.