- The paper introduces SBBTS that jointly calibrates drift and stochastic volatility for more accurate synthetic financial time series generation.
- The framework employs dynamic programming and neural Brownian bridge sampling to capture complex temporal dependencies and non-Markovian features.
- Empirical results on Heston models and S&P 500 data demonstrate superior parameter recovery, forecasting performance, and risk metric fidelity.
SBBTS: A Unified Schrödinger–Bass Framework for Synthetic Financial Time Series
Introduction and Motivation
The paper proposes the Schrödinger–Bass Bridge for Time Series (SBBTS), establishing a generative framework that models both drift and stochastic volatility in financial time series, bridging the classical Schrödinger Bridge (SB) and Bass optimal transport paradigms. This framework addresses the main limitation of prior SB approaches, which fix volatility a priori and hence fail to capture stochastic volatility and correlation structures, and of Bass models, which ignore drift entirely and thus omit temporal dependencies critical to forecasting. SBBTS achieves joint calibration over the multi-marginal distribution of time series, making it practical for scenarios where realistic synthetic sample generation is required (e.g., data augmentation, risk modeling, stress testing).
Theoretical Contributions
SBBTS generalizes the SB–Bass problem by expanding from the classical two-marginal transport formulation to multi-marginal time series, enabling the construction of a diffusion process whose drift and volatility are jointly learned to match prescribed marginals and their temporal correlations. The framework leverages a dynamic programming factorization, decomposing the overall optimization into sequential conditional transport steps—each interval is solved via classical semimartingale optimal transport, then concatenated to recover the full process.
The optimization in SBBTS is expressed as
J(P)=EP[∫0T∥αt∥2+β∥σt−Id∥2dt],
where both drift αt and volatility σt are learned, interpolating between SB (σt fixed, drift learned) and Bass (αt=0, volatility learned) regimes by tuning β. This explicit interpolation enables SBBTS to represent both regime behaviors and the intermediate case, overcoming the degeneracies of traditional approaches.
The solution involves learning auxiliary map triples (h,ν,Y) satisfying backward-forward-transport recursions, and the process can be sampled via Brownian bridge constructions and nonlinear score-based diffusion, which is efficiently implemented via neural networks.
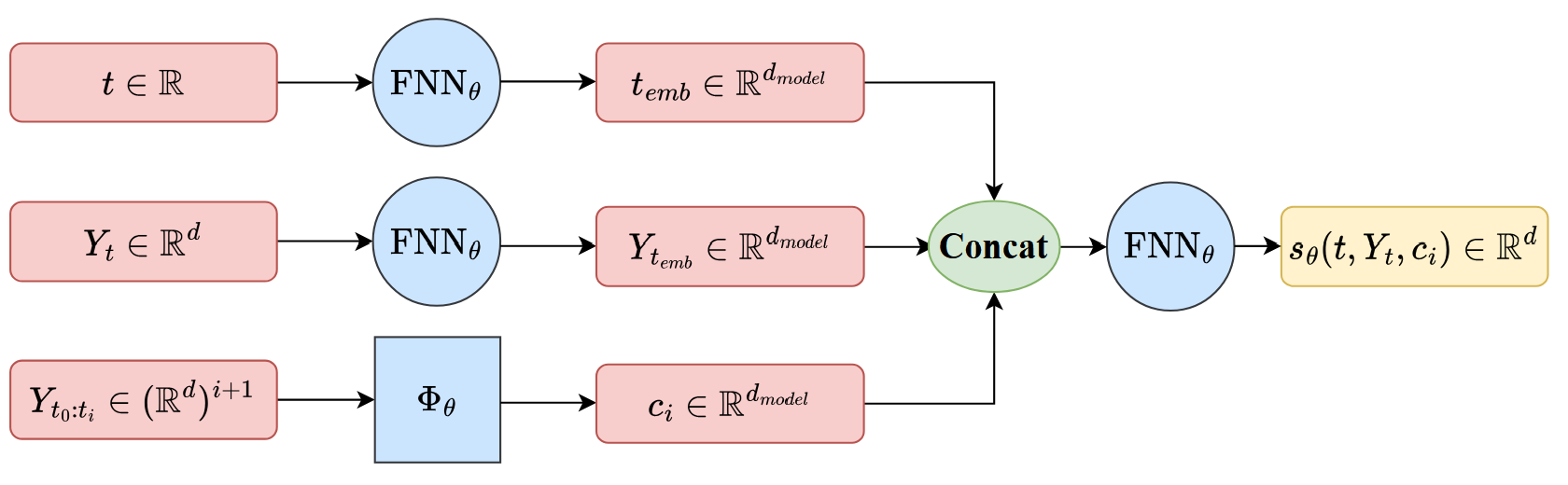
Figure 1: Architecture of sθ, the neural network modeling path-dependent drift in SBBTS.
Algorithmic Implementation
SBBTS is instantiated as a neural generative algorithm. The drift sθ is parameterized by a neural network, accepting current time, current state, and an embedding of the past trajectory. The training employs a loss function comparing the predicted drift to the true conditional increment in each interval, averaged over Brownian bridges between successive anchors.
Initialization is identity mapping (corresponding to pure SB), and the transport map is updated iteratively for moderate β, using large-αt0 approximation for practical tractability. Importantly, SBBTS's network architecture (see Figure 1) encodes both time and historic trajectory explicitly, allowing the generator to capture path dependencies and non-Markovian features.
Empirical Results: Synthetic and Real Data
Heston Model Parameter Recovery
Numerical experiments on the Heston stochastic volatility process demonstrate SBBTS's capacity to recover parameters that SBTS (previous SB-based method) cannot. SBBTS-generated samples preserve the distributions of all underlying model parameters—including "vol of vol" (αt1) and correlation (αt2)—in a way highly consistent with real data, while SBTS collapses to average values and fails for stochastic volatility and correlation due to fixed quadratic variation constraint.
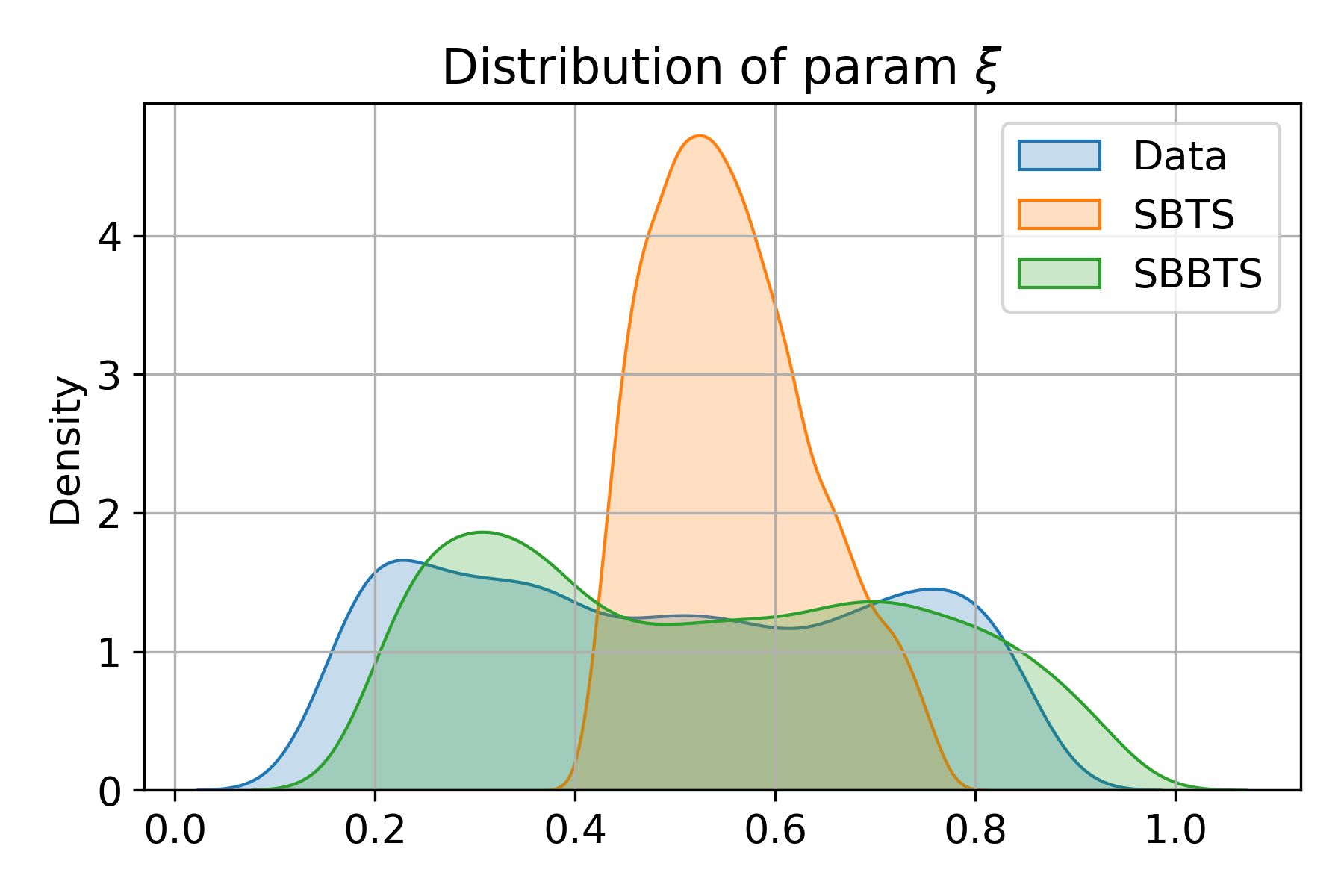
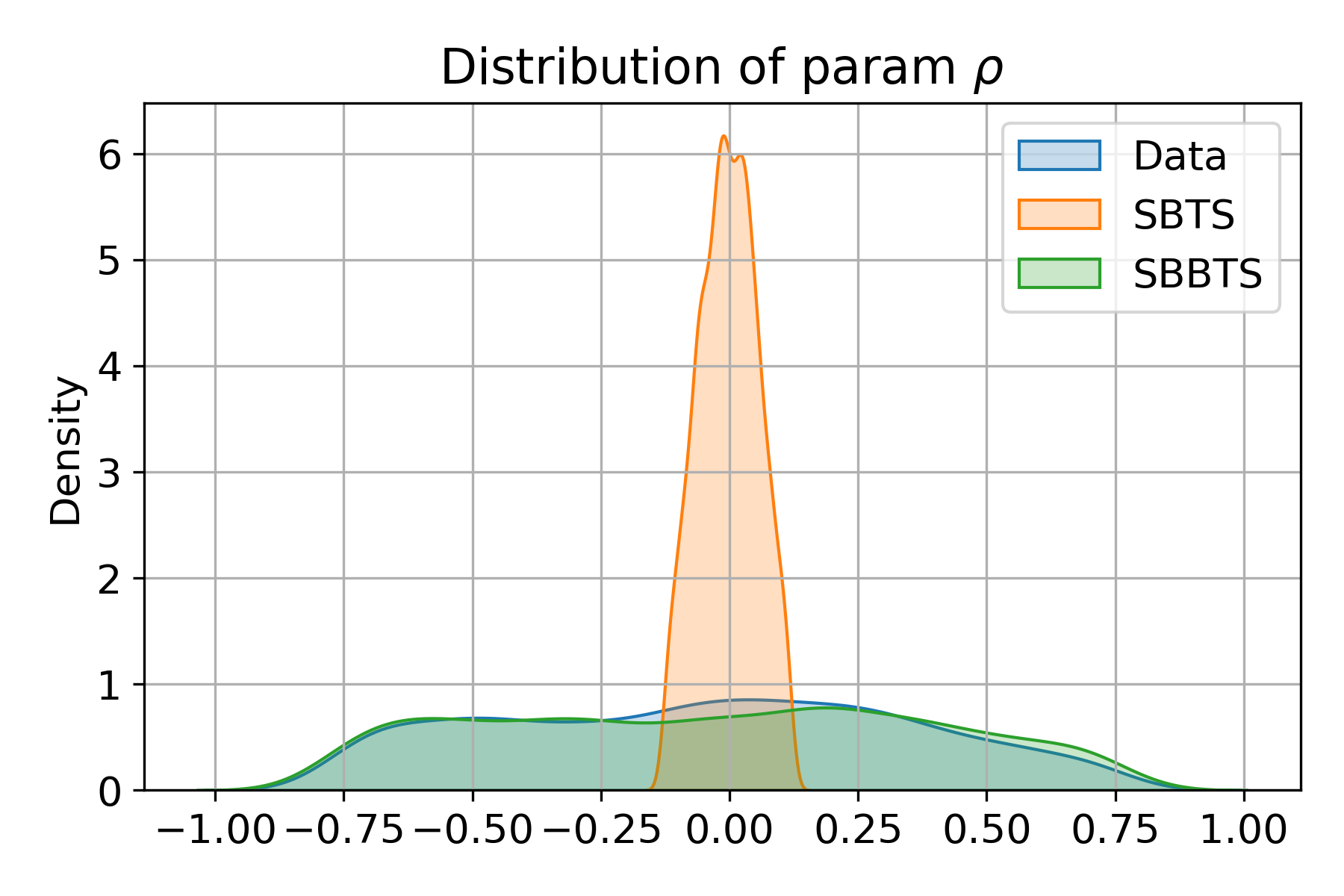
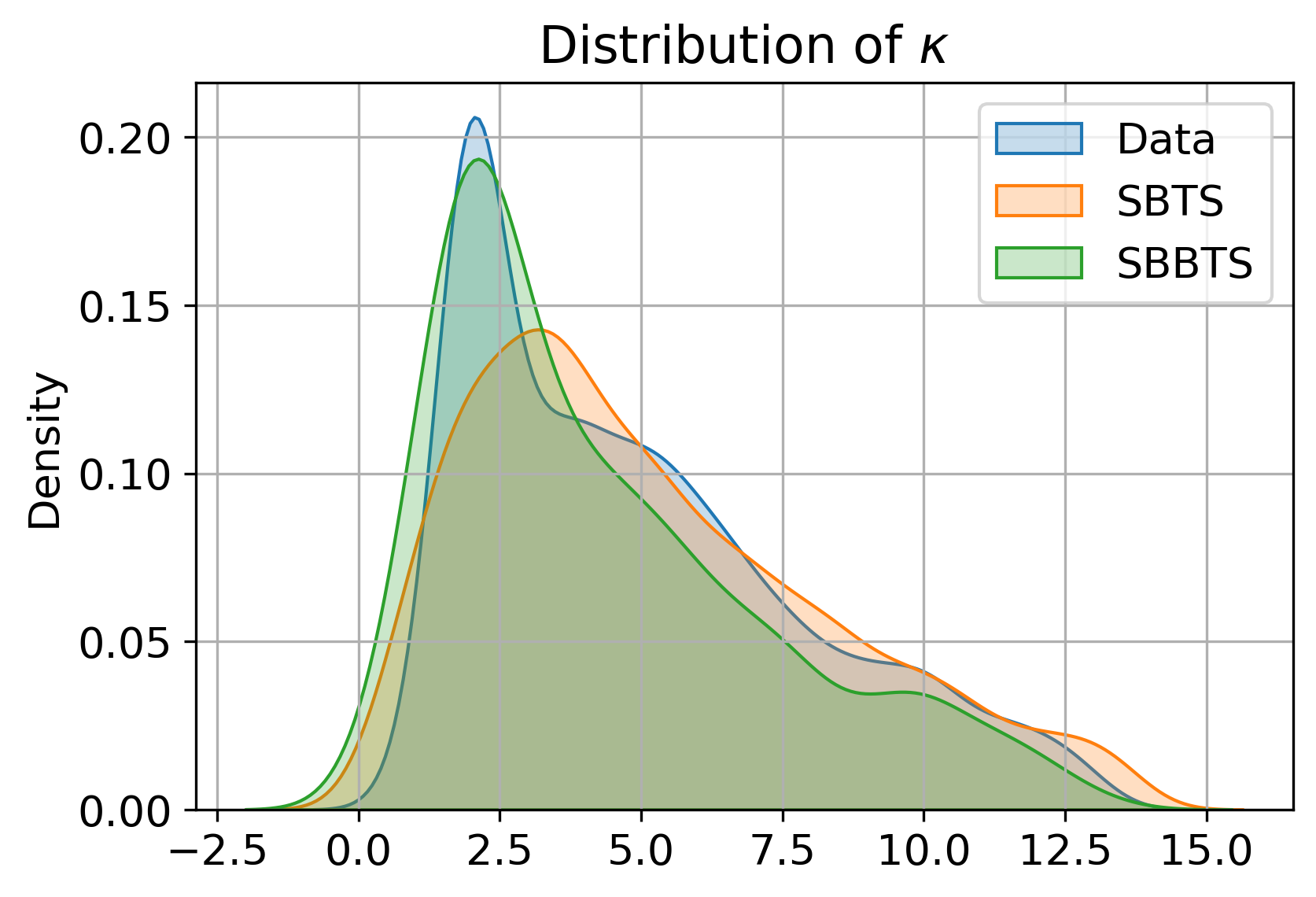
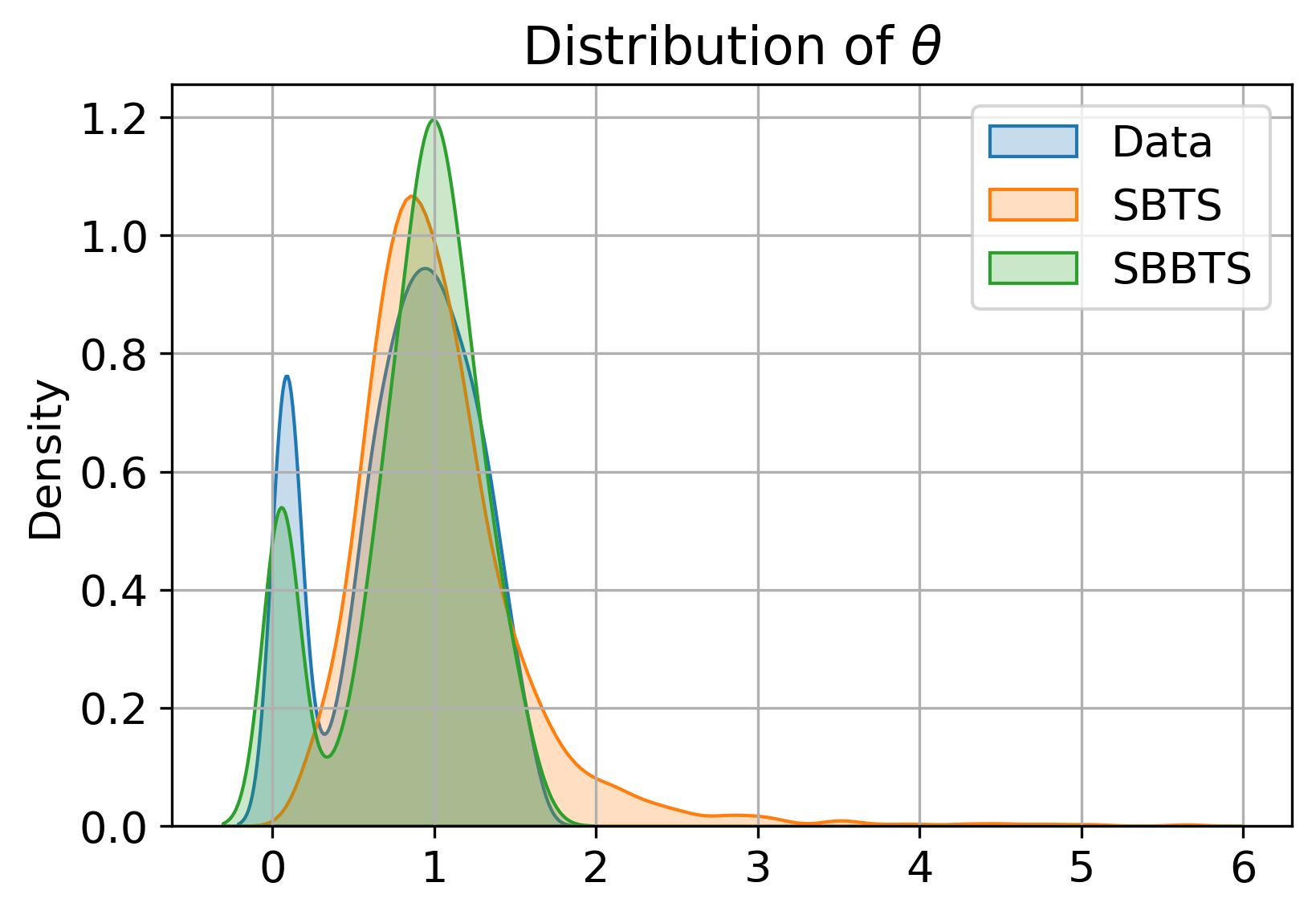
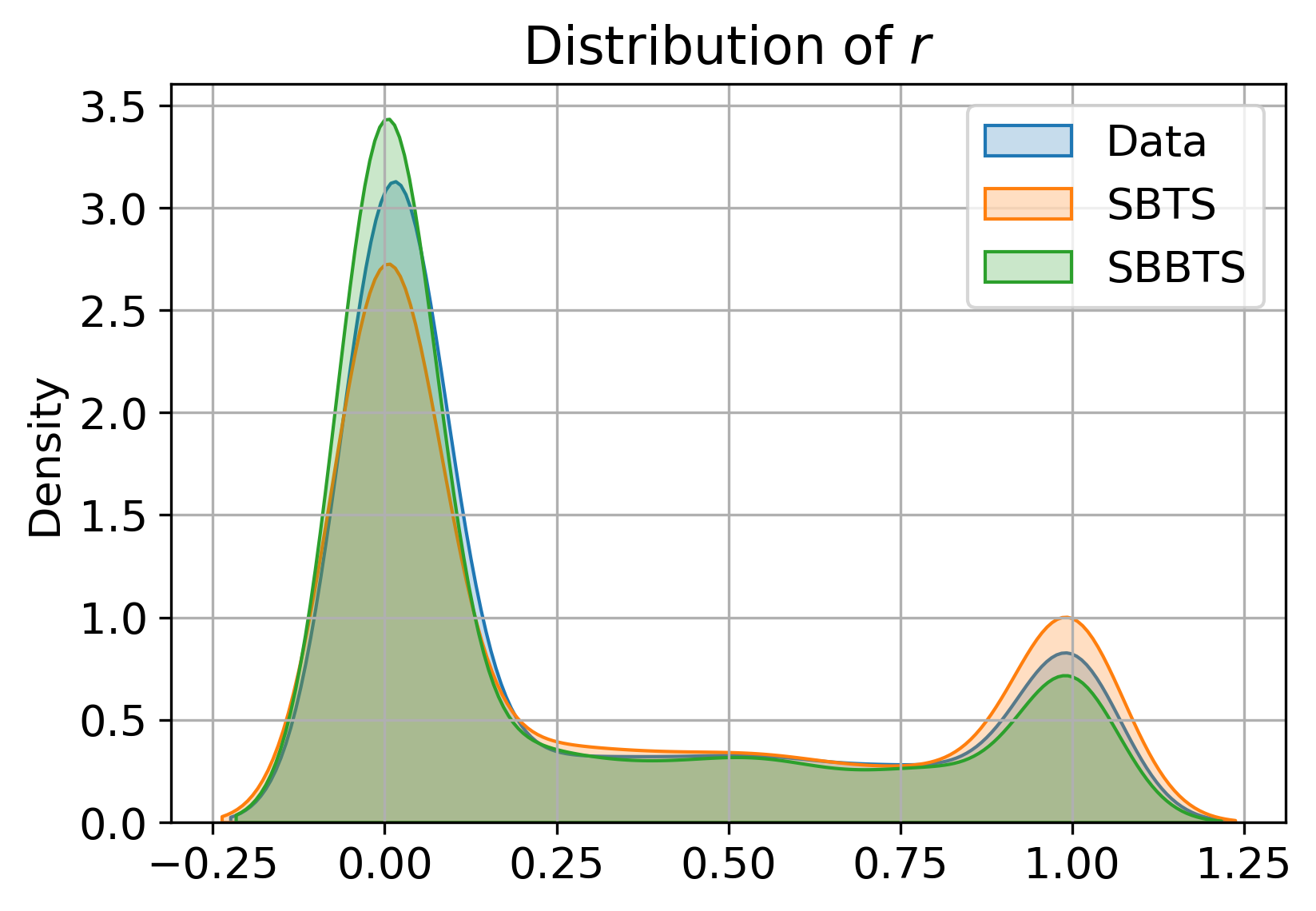
Figure 2: Distributions of Heston model parameters estimated by MLE, comparing real, SBTS, and SBBTS-generated samples.
Data Augmentation in Financial Forecasting
Applied to daily returns from the S&P 500, SBBTS is used to augment training data for forecasting models (TabICL), and its impact is evaluated both in predictive accuracy and financial utility metrics. Augmentation with SBBTS synthetic data yields consistently superior classification performance (accuracy, log loss, ROC AUC) and financial metrics (average daily return, Sharpe ratio) compared to both real-data-only and random noise augmentation. The improvement persists as the synthetic dataset size is increased, plateauing before overfitting occurs.
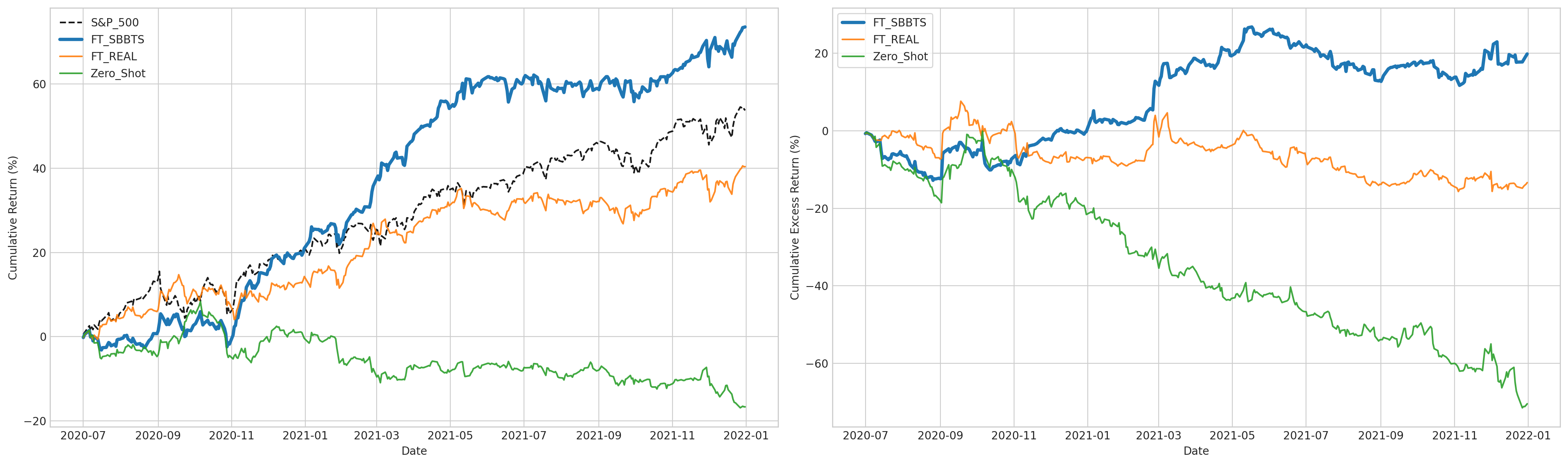
Figure 3: Cumulative returns (left) and cumulative excess returns (right) for trading strategies trained with SBBTS augmentations, benchmarked against S&P 500 index.
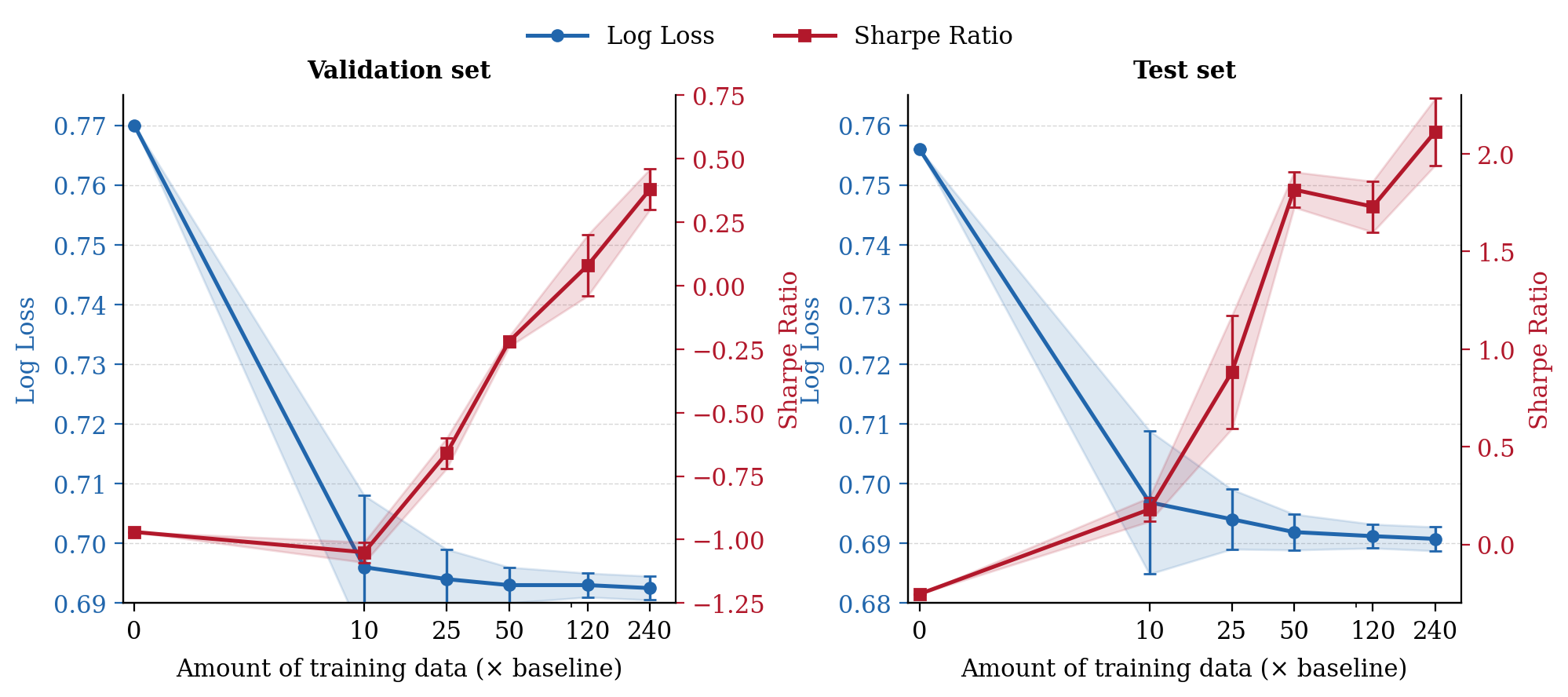
Figure 4: Validation and test performance as a function of amount of SBBTS-generated synthetic training data.
Statistical Quality of Synthetic Data
Comprehensive quantitative and qualitative assessments compare real vs. synthetic time series. Marginal distributions, autocorrelation structures, and cross-sectional dependence (correlation matrices) are reproduced accurately by SBBTS-generated samples, indicating not only temporal but also multivariate fidelity.
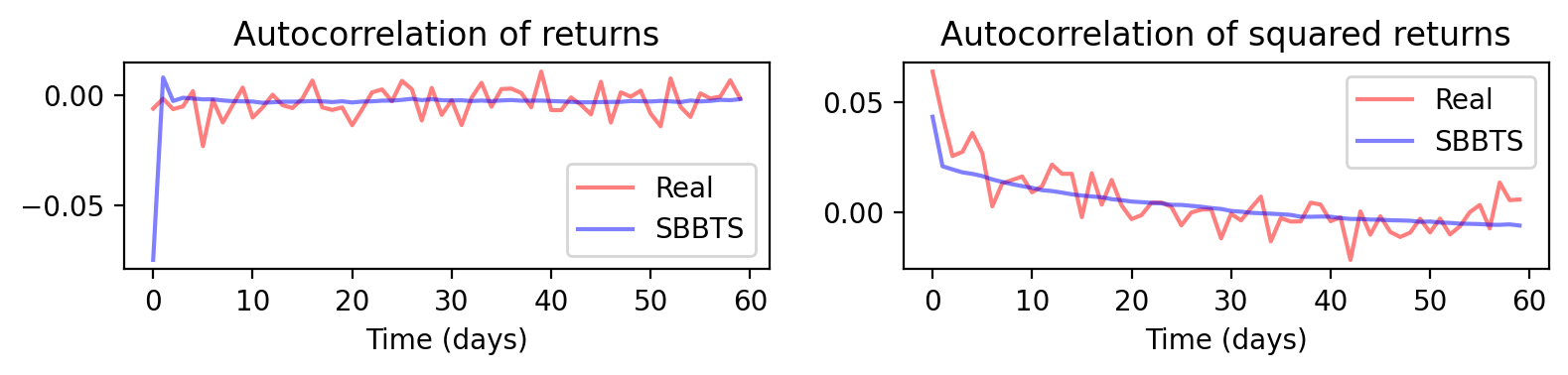
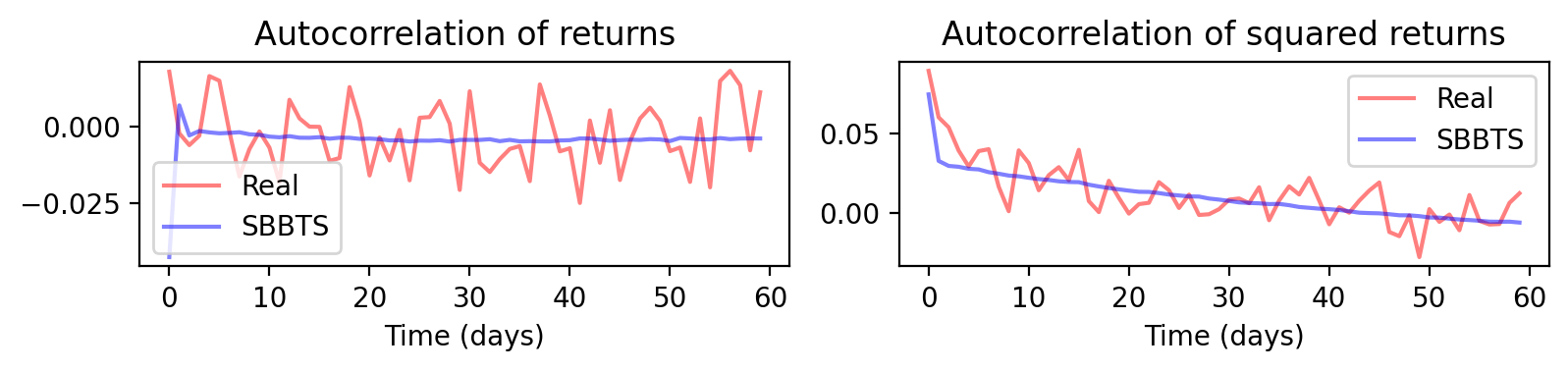
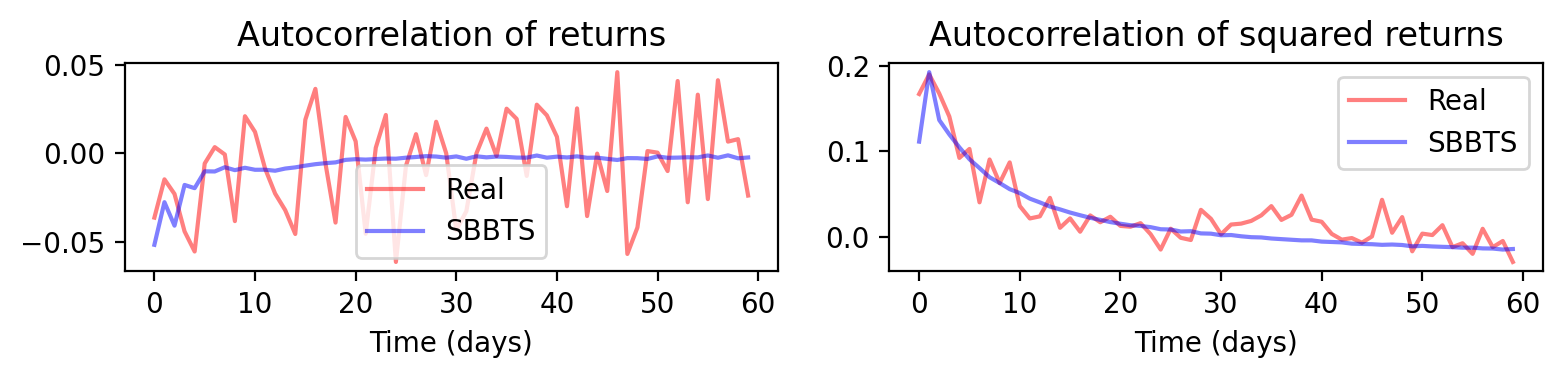
Figure 5: Cluster 1—temporal autocorrelation structure comparison real vs. synthetic.
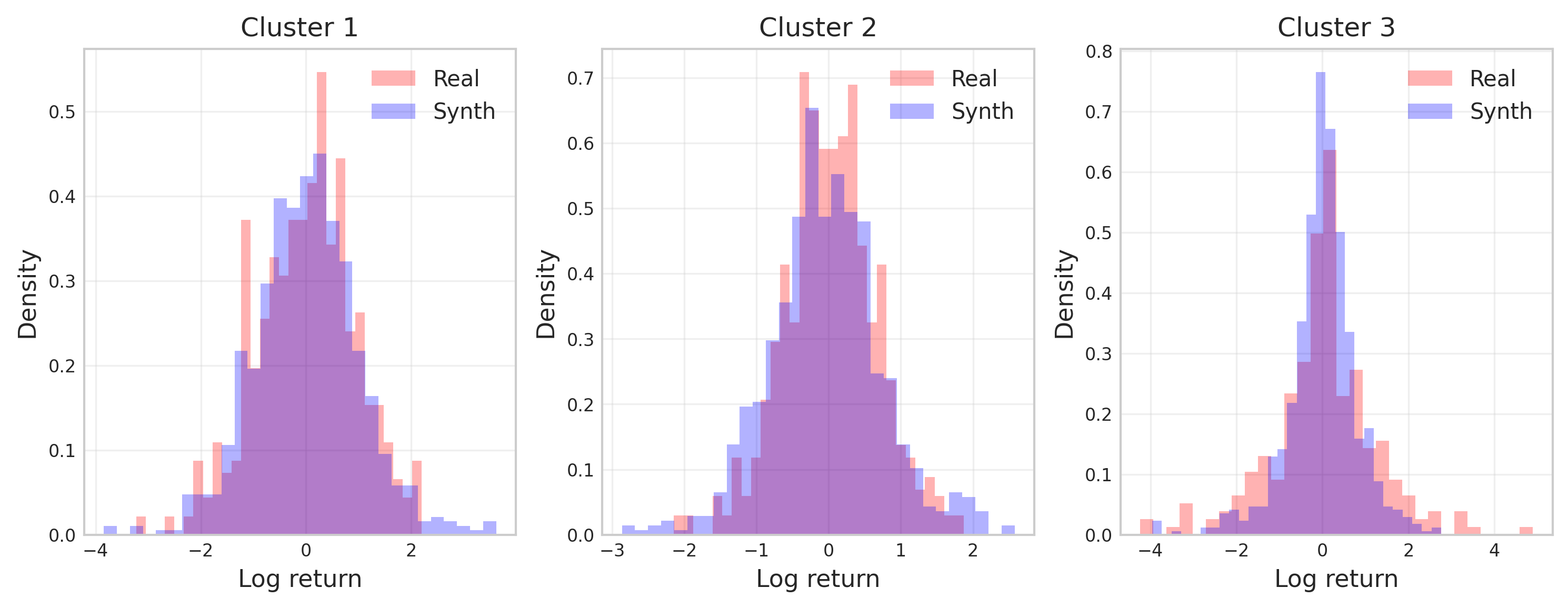
Figure 6: Distribution of cluster factors in real and synthetic data.
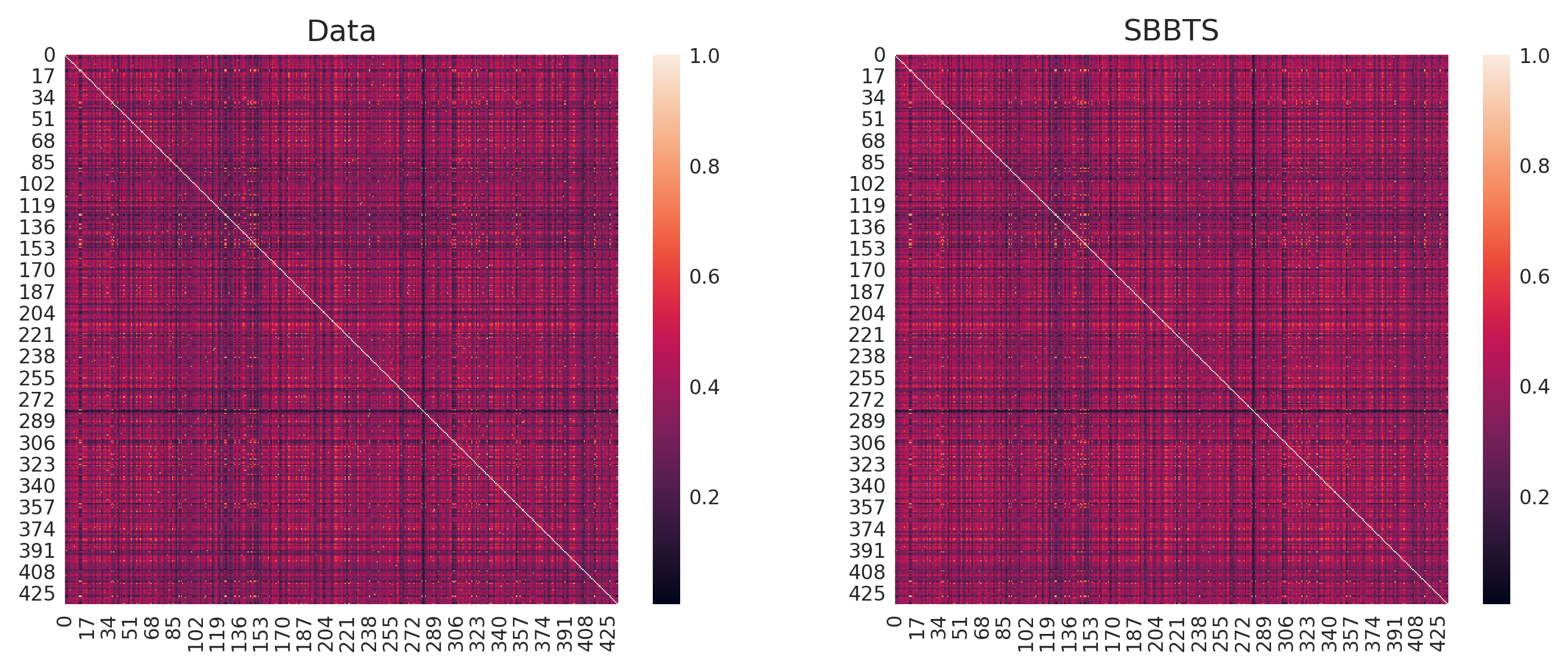
Figure 7: Correlation matrices of returns for real and synthetic datasets.
SBBTS also preserves tail-risk statistics (VaR, ES) and risk–return characteristics, outperforming SBTS benchmarks.
Implications and Future Directions
SBBTS's success in recovering stochastic volatility and providing more predictive signal demonstrates its theoretical soundness and practical utility for synthetic financial time series generation. Its core innovation—joint learning of drift and volatility, structured via conditional optimal transport decomposition—is not limited to financial applications but has potential for broader time series modeling, especially where accurate representation of higher-order dependencies and volatility is critical.
For practical downstream use, SBBTS enables robust data augmentation, systematically improving performance of tabular and sequential predictive models and boosting out-of-sample economic metrics. It offers a rigorous alternative to ad hoc noise-based augmentation, with statistically validated improvements.
Theoretically, SBBTS prompts new research into principled αt3 calibration schemes, extension to jump-diffusion and irregular sampling, and formal convergence analysis for the iterative large-αt4 neural training algorithm. Its generalization to non-Gaussian reference volatility further strengthens its adaptability to empirical market data.
Conclusion
SBBTS unifies the two main classes of diffusion-based generative models, achieving joint calibration of drift and volatility for complex multi-marginal time series generation. It addresses critical limitations of prior methods by enabling accurate modeling of stochastic volatility and correlation, validated by strong numerical results on both model and real financial data. The framework's implications extend to synthetic data generation, forecasting, and risk management, and future research will focus on theoretical guarantees and enhancements for broader applicability.

