- The paper presents a dual-decoder Transformer that self-discovers vehicle driving intentions, eliminating the need for manual intention labels.
- It uses temporal and spatial attention modules to capture inter-agent dynamics, significantly reducing RMSE and MAE in trajectory prediction.
- The residual summation mechanism in trajectory decoding ensures mode diversity and smooth ordering, enhancing model interpretability and accuracy.
Introduction
The paper introduces a Transformer-based architecture for trajectory prediction in multi-agent autonomous driving scenarios, focusing on multi-modal and intention-aware forecasting. Unlike conventional models reliant on manual intention labels or explicit graph structures for inter-agent interactions, the proposed framework achieves intention discovery and spatial reasoning intrinsically, leveraging dual decoder tracks. This approach allows the model to predict multiple plausible future trajectories (modes) per agent, each associated with a likelihood reflecting behavioral uncertainty.
Model Architecture and Methodology
The model consists of temporal and spatial attention modules designed to capture rich spatiotemporal dependencies among vehicles without explicit graph definitions. Historical vehicle trajectories are first embedded with temporal positional encodings. The encoded features are then processed by two parallel Transformer decoders:
- Trajectory Decoder: Predicts K distinct candidate trajectories per agent, each corresponding to a potential underlying driving intention.
- Probability Decoder: Computes the likelihood for each candidate trajectory, considering both agent dynamics and neighborhood context.
This dual-track setup follows a "propose-then-select" mechanism: the trajectory decoder proposes potential futures, and the probability decoder identifies the most probable realization.
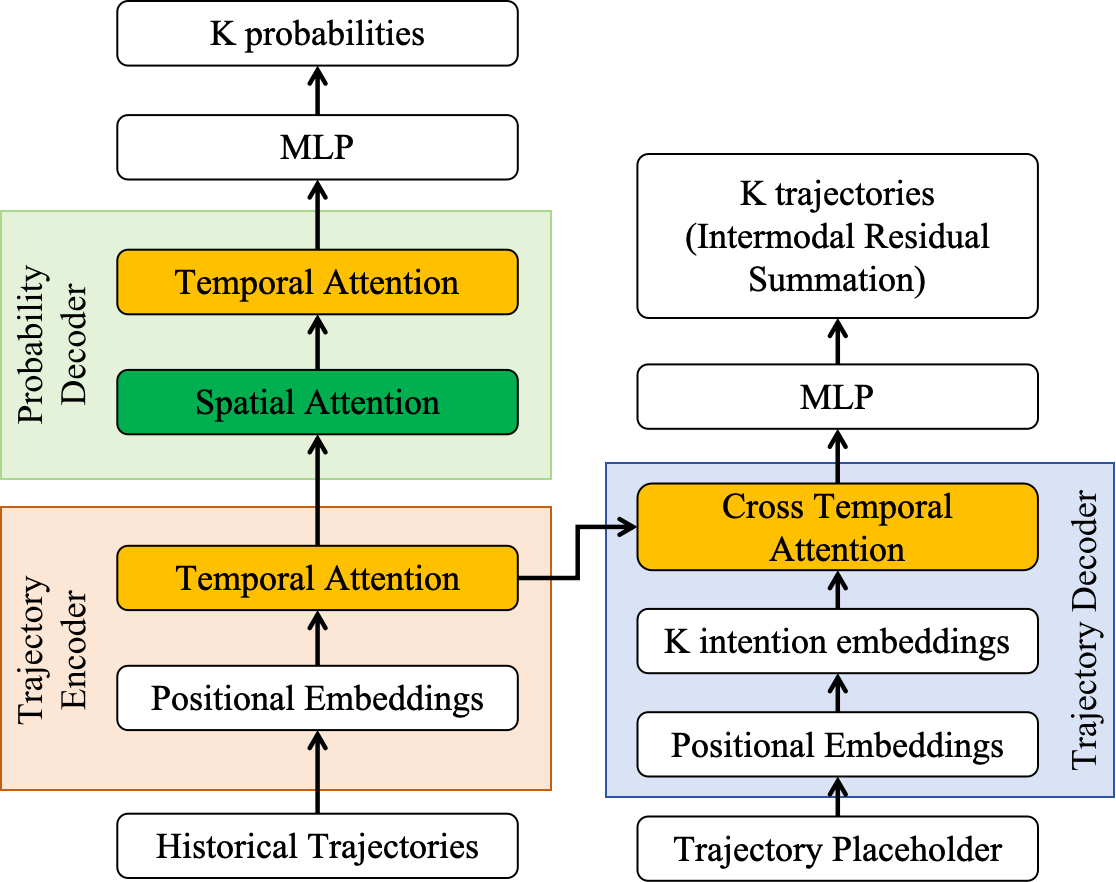
Figure 1: An overview of the proposed model framework, illustrating separate pathways for trajectory and intention probability predictions.
A notable design innovation is the inter-modal residual summation used in the trajectory decoder. Instead of independent heads, residuals between modes are recursively summed, producing a smoothly ordered set of trajectories where adjacent modes exhibit high similarity. This regularization mitigates modal collapse and encourages diversity across intentions.
The spatial attention module incorporates an adaptive relational bias, modeling asymmetric inter-agent influences through a learned function of pairwise motion feature differentials. This allows the attention mechanism to dynamically allocate context based on relative kinematic profiles, enhancing capacity for contextually-aware behavioral modeling.
The final trajectory output for each agent is selected by maximizing over the predicted intention likelihoods, focusing on the most probable future.
Experimental Results
Experiments are conducted using the "Ubiquitous traffic eyes" dataset, emphasizing challenging scenarios at highway merging and splitting zones. Trajectory data are segmented into 10-second episodes for training and evaluation, using 5 seconds for observation and 5 seconds for prediction.
Key experiments assess the effect of multi-modal prediction and inter-agent interaction modeling via ablation. The models compared include:
- Single-modal (1 trajectory) vs. multi-modal (8 trajectories)
- With and without spatial (inter-vehicle) attention
Results indicate that increasing the number of predicted modes notably reduces error, and integrating spatial attention yields further improvement:
| Model |
RMSE (meter) |
MAE (meter) |
| OV_1 |
22.25 |
17.20 |
| OV_8 |
6.22 |
3.55 |
| MV_8 |
5.91 |
2.45 |
The best configuration (8 modes, multi-agent spatial attention) achieves an RMSE of 5.91 meters and MAE of 2.45 meters over a 5-second horizon. This is competitive with, or surpasses, state-of-the-art Transformer-based and graph-based approaches reported in the literature [9832594, 2677-946].
Model Interpretation
The interpretability of attention-based models is addressed via visualization of learned spatial attention weights, revealing how the model dynamically focuses on certain neighboring vehicles as context evolves. The attention weight plots clearly illustrate which other agents most influence the prediction for a focal vehicle, with the magnitude and directionality correlating to plausible interaction logic.
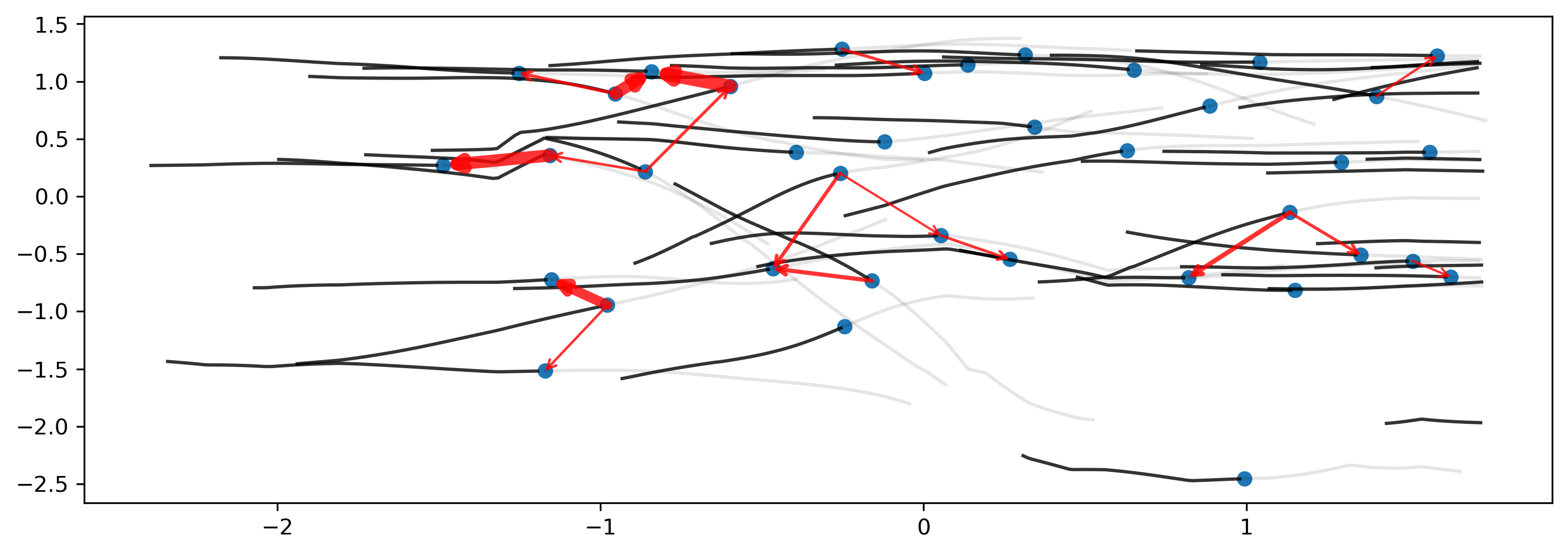
Figure 2: Averaged spatial attention weights between each pair of vehicles, highlighting dynamic influence patterns in complex traffic.
Notably, the model does not require explicit intention annotation (e.g., 'left turn', 'merge'), yet discovers intention modes directly from data through end-to-end learning. Counterfactual and temporal analysis is employed to assess decision boundary robustness, further contributing to interpretability.
Comparative Analysis and Positioning
Distinct from prior works that embed explicit intention cues or require graph definitions [9832594, 2677-946], this approach leverages learnable attention biases and residual-based trajectory ordering to enable flexible, compositional representation of behavioral uncertainty. Methods such as intention-aware Transformer models have utilized manual intention labelling or graph augmentations for multi-agent prediction [9832594, 2677-946]. In contrast, the self-discovered intention mechanism offers generality and obviates reliance on such domain-dependent supervision.
Moreover, the architecture's light encoder-decoder structure enables efficient training and inference, positioning it as a practical candidate for real-time autonomous driving systems on resource-constrained platforms, assuming further engineering adaptation.
Implications and Future Directions
By demonstrating that intention-aware multi-modal trajectory forecasting can be achieved with pure Transformer architectures—absent explicit intention or manually-constructed graphs—the work opens several avenues:
- Generalization and Transferability: The decoupling of spatial and temporal reasoning, and the absence of manual labels, suggest that the framework can be readily adapted to diverse traffic environments, agent heterogeneity, and extended to non-vehicle road users (e.g., pedestrians, cyclists).
- Interpretable Decision-Making: Attention weight visualization, coupled with counterfactual analyses, enhances trustworthiness and deployability in safety-critical systems.
- Potential Enhancements: Incorporation of map topology, road constraints, or scene context (e.g., lane geometry, intersection topology) could further improve performance, as suggested by identified limitations.
Comparisons with diffusion-based and variational multi-agent prediction models [jiang2023motiondiffuser, salzmann2020trajectron++] or frameworks leveraging causal inference (Zong et al., 15 Feb 2026) remain open areas for benchmarking on broader and more heterogeneous datasets.
Conclusion
The self-discovered intention-aware Transformer presented in this paper advances the state of the art in multi-agent, multi-modal vehicle trajectory prediction by dispensing with the need for explicit intention labels and static interaction graphs. Numerical results demonstrate that explicit modeling of intention probabilities and ordered trajectory diversity yields significant improvements in predictive accuracy and model interpretability. Future extensions will need to address environmental context integration and further head-to-head experimental comparison against leading generative and causal models in complex, real-world domains.

