- The paper introduces a novel PPFT framework that prevents raw text transmission by aligning client embeddings using a ModernBERT encoder and k-pooling.
- It demonstrates up to 95.6% accuracy on legal tasks by injecting calibrated Laplace noise to thwart inversion attacks while preserving domain-critical semantics.
- The method scales across model sizes and domains, offering a reusable, protocol-agnostic solution for privacy in MLaaS without compromising model utility.
Privacy-Preserving Prompt Transmission for LLMs: Text-Free Inference via PPFT
Motivation and Background
Cloud-based LLM services are increasingly deployed for sensitive domains such as medical and legal question answering, where securely handling user prompts is paramount. Conventional MLaaS interfaces typically require transmission of raw prompt text, exposing users to severe privacy risks including interception, infrastructure breaches, and accidental data persistence in system logs. Existing privacy defenses—prompt sanitization, cryptographic inference, and embedding perturbation—have seen limited adoption due to their computational burden or vulnerability to inversion attacks, where transmitted embeddings are reconstructed into semantically faithful text [morris2023text] [lin2024inversion]. Consequently, a practical solution mandating that raw prompt text never leaves the client device, while preserving both privacy and model utility, is urgently needed.
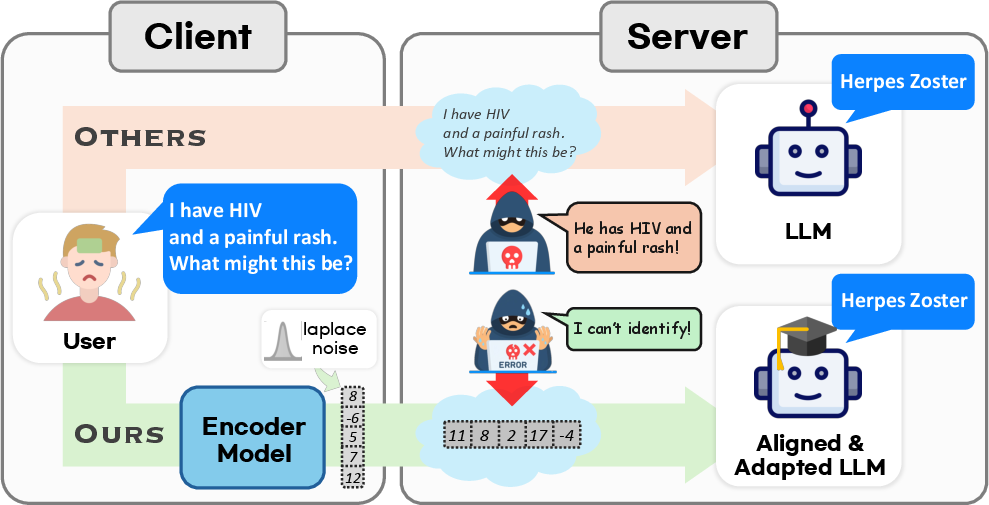
Figure 1: While conventional services expose plain text prompts to the server, PPFT transmits only obfuscated embeddings to prevent prompt inference and mitigate privacy risks.
The PPFT Framework: Architecture and Protocol
The paper introduces Privacy-Preserving Fine-Tuning (PPFT), an end-to-end system for text-free prompt transmission and inference. PPFT implements two critical stages:
- Stage 1: Encoder-Decoder Alignment Client-side prompts are mapped by a lightweight ModernBERT encoder to token embeddings, which are compressed with k-Pooling (block-wise mean). A trainable server-side projection aligns the pooled embeddings to the LLM decoder’s input space. No discrete tokens are transmitted; the interface operates solely on continuous representations.
- Stage 2: Domain Adaptation with Noise Injection To thwart inversion risks, isotropic Laplace noise (calibrated under dχ-privacy) is injected into the pooled embeddings, which are then projected and used for domain-specific fine-tuning of the decoder. The encoder is frozen; all adaptation is performed server-side.
Throughout both stages, the server never receives nor sees prompt text or its direct derivatives.
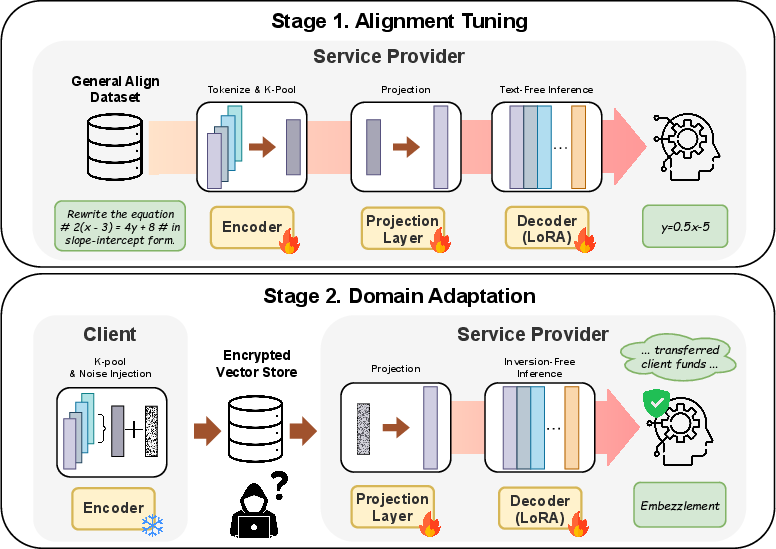
Figure 2: Overview of PPFT. Stage 1 aligns pooled client-side embeddings with the decoder to enable text-free inference. Stage 2 implements domain adaptation with noise-injected embeddings for robustness.
Evaluation: Robustness and Utility
PPFT is evaluated against major baselines—dχ-privacy (token perturbation), Paraphrase (generative rewriting), PrivacyRestore (masked inputs with auxiliary vectors)—on medical (Pri-DDX, Pri-NLICE) and legal (Pri-SLJA) datasets, as well as general-domain QA benchmarks (SQuAD, CSQA). PPFT consistently outperforms competitors, achieving up to 95.6% task accuracy with noise injection in the legal domain and limiting utility degradation to <0.2 relative to noise-free upper bounds, even for large decoder models (8B) (see Table 1 in the paper). Importantly, domain-critical semantics are preserved under aggressive privacy constraints.
Inversion Resistance
PPFT demonstrates strong robustness against generative inversion attacks. Across a range of privacy budgets, ROUGE-L reconstruction scores remain low (typically <0.25 for ϵ=75), indicating that attackers reconstruct template scaffolding but fail to recover sensitive attributes or content.
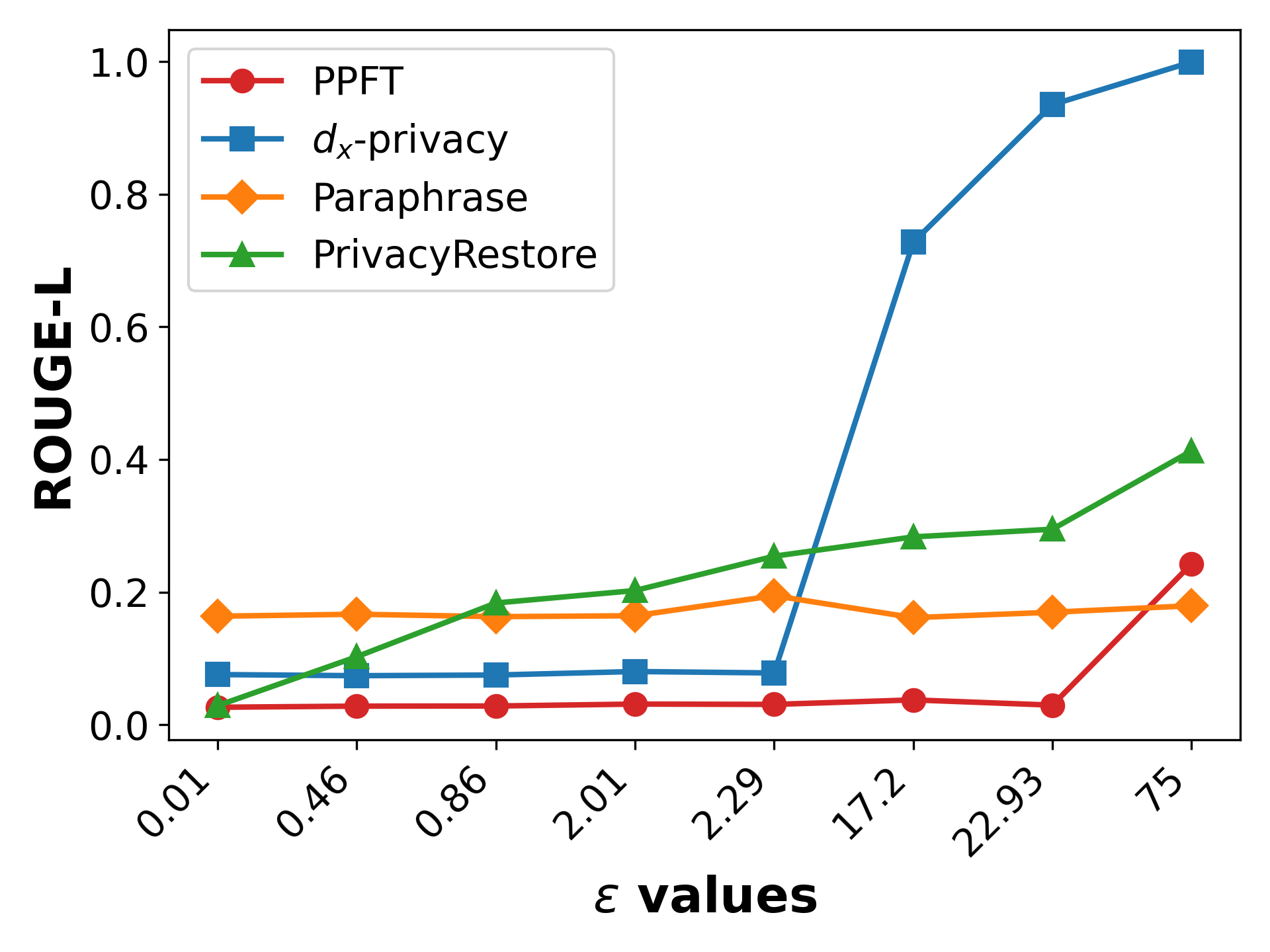
Figure 3: Results of embedding inversion attacks and attribute inference attacks across all baselines under varying privacy budgets ϵ on Pri-DDX.
Further fine-grained analysis shows PPFT attribute recall rates for age and antecedents near zero, and sex recall at random baseline, outperforming PrivacyRestore and paraphrasing methods.
Ablation Studies: Pooling and Noise
Increasing pooling size k improves privacy at the cost of utility; optimal trade-offs are observed at moderate k values. Laplace noise injection materially outperforms Gaussian and no-noise alternatives for reconstruction resistance.
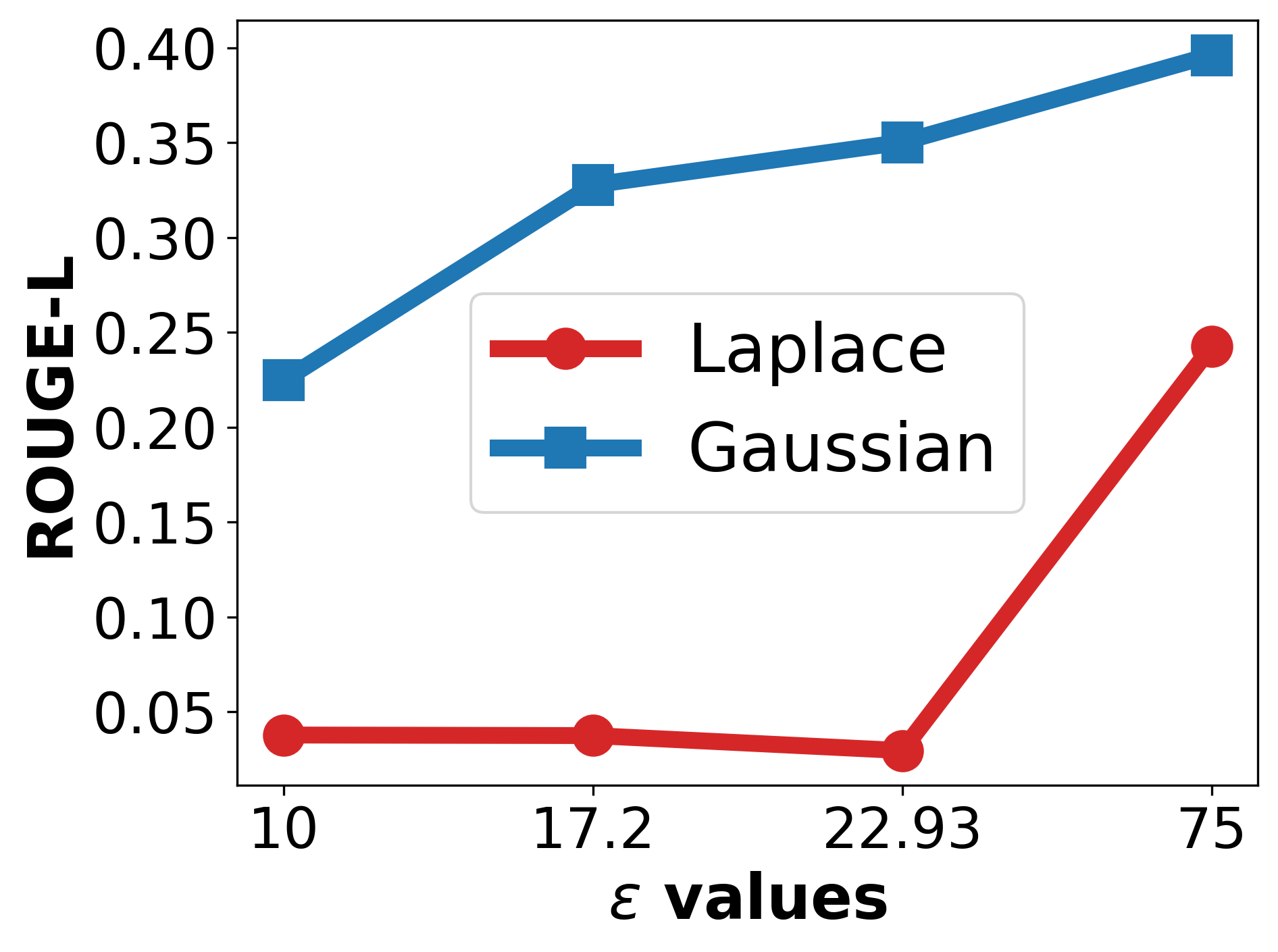
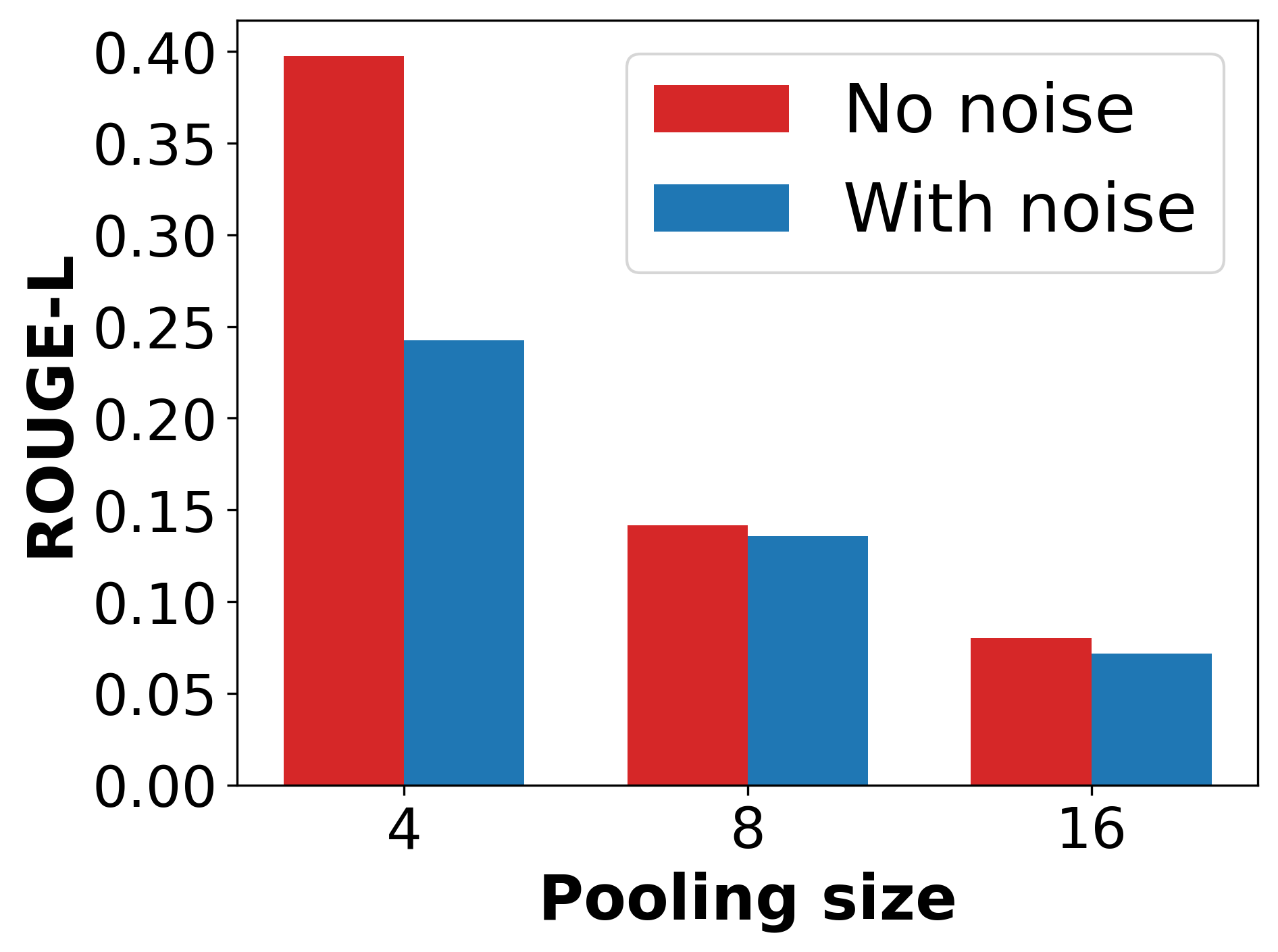
Figure 4: Left: Reconstruction performance under different noise types. Right: Reconstruction performance with and without noise injection.
Adversarial Analysis and Implications
Noise-aware adversaries trained on PPFT’s noisy embedding distribution achieve only modest improvements in surface-level reconstruction, with qualitative outputs dominated by template matching rather than accurate recovery of private information. Even strong attackers (stage-1 aligned decoders) do not faithfully reconstruct input semantics.
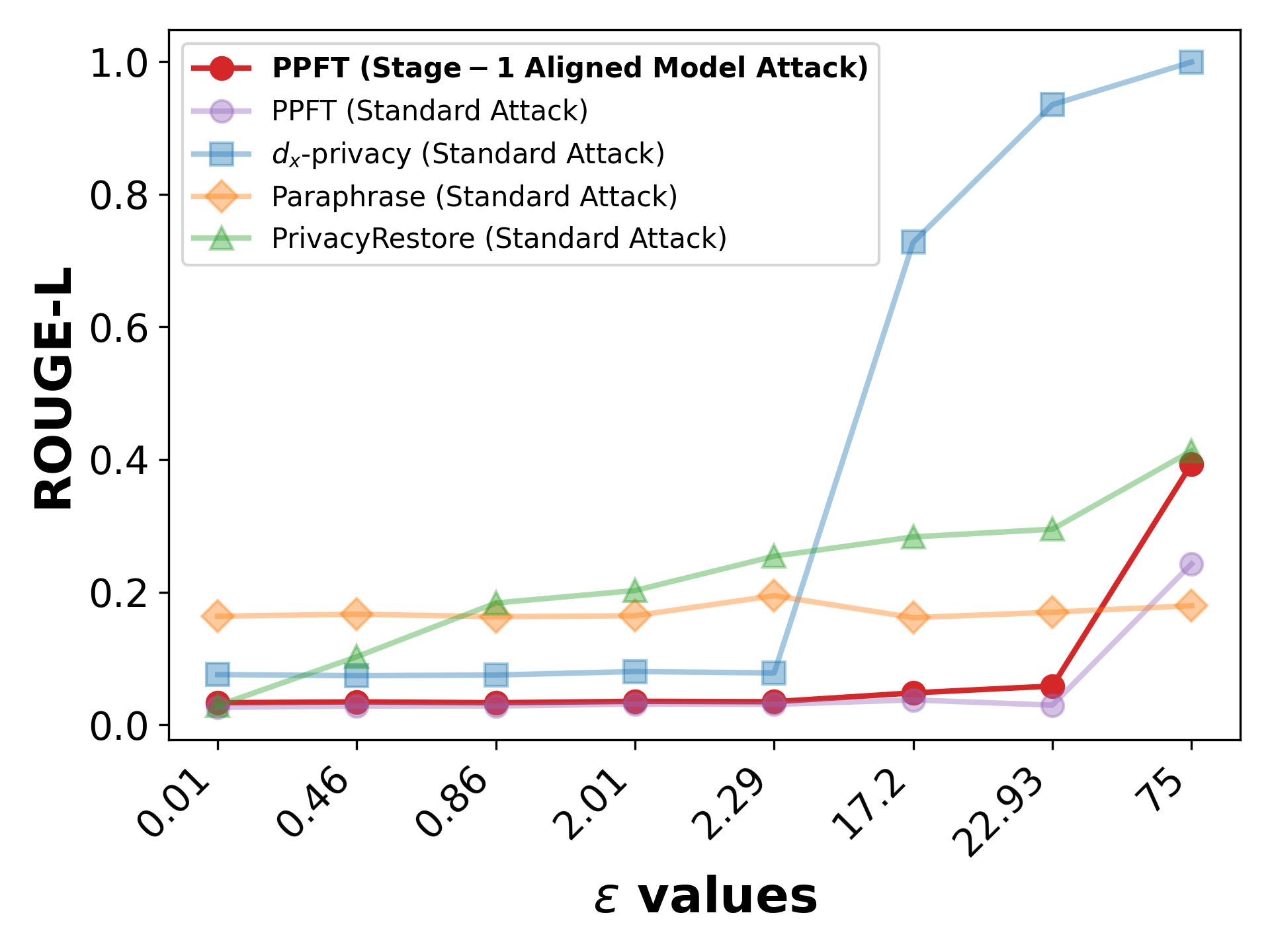
Figure 5: Inversion attacks on PPFT using a Stage-1 aligned model (stronger attacker) under varying privacy budgets ϵ.
Moreover, universal zero-shot embedding inversion methods fail on pooled, noise-injected representations, reiterating that pooling and noise fundamentally disrupt token-level alignment and generative inversion efficacy.
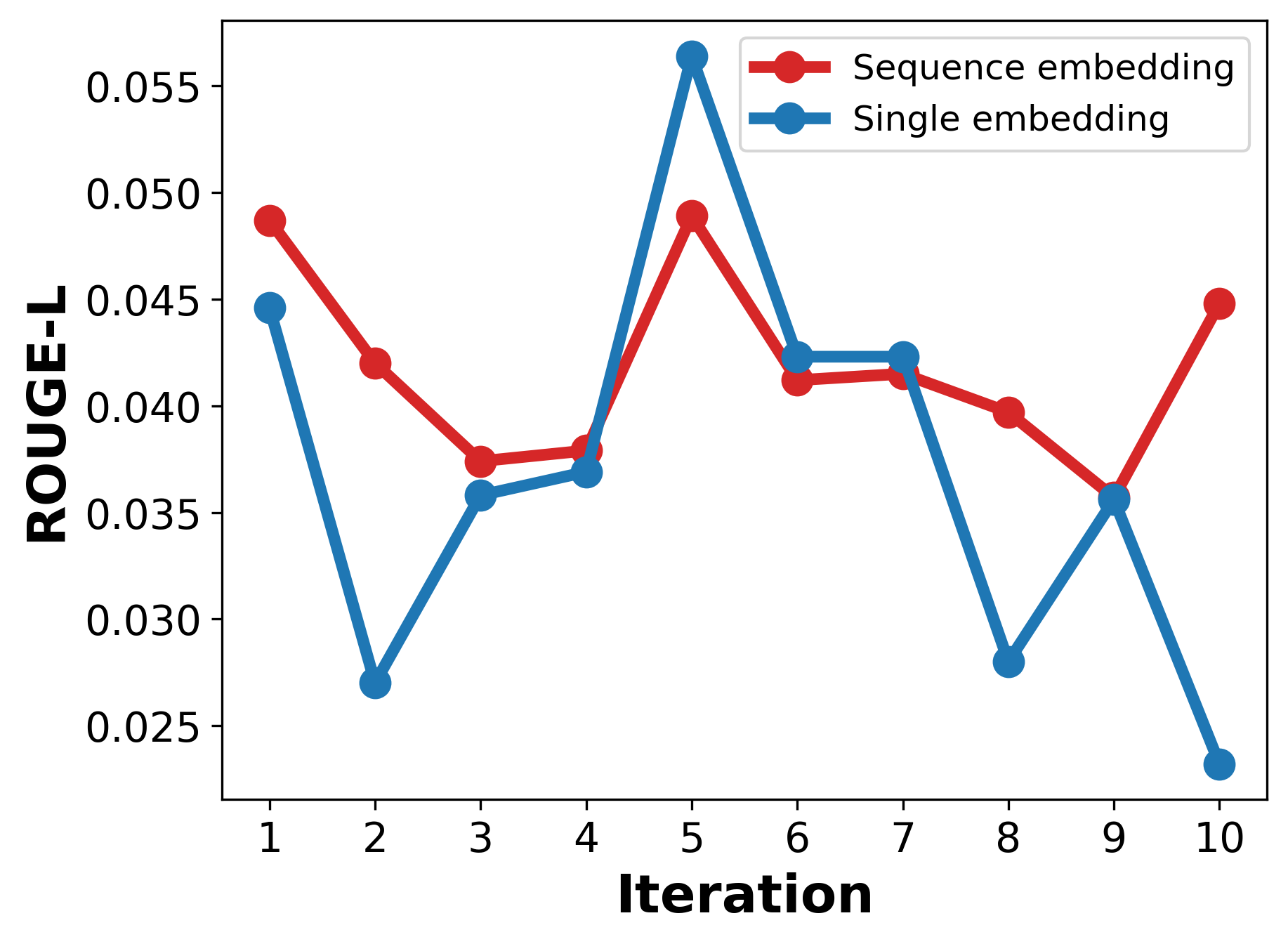
Figure 6: Reconstruction quality across iterations for the pooled-embedding (Experiment 1) and single-embedding (Experiment 2) settings.
Practical and Theoretical Implications
PPFT offers a protocol-agnostic, reusable privacy interface for MLaaS and edge-cloud deployments. Practical implications include:
- Deployment Feasibility: Lightweight client encoders and efficient pooled-compression are compatible with CPUs; no accelerators required.
- Service Provider Decoupling: No server-side access to raw text or proprietary decoder parameters is mandated, enabling adaptation with privacy and commercial secrecy.
- Scalability: PPFT scales across model sizes and domains, including general QA, without excessive cost or utility loss.
Theoretically, PPFT shows that embedding-level privacy not only withstands inversion attacks but also supports domain adaptation for high-stakes applications. Pooling and calibrated noise together break the assumption that “embeddings reveal (almost) as much as text” [morris2023text], challenging prior conclusions on representational privacy.
Future Directions
Future research may focus on:
- Extending the text-free, embedding interface to multimodal and multilingual inputs.
- Exploring adaptive pooling/noise schedules for dynamic privacy-utility optimization.
- Integrating output-side safeguards for end-to-end confidentiality, especially in applications where server-generated output may leak sensitive content.
Conclusion
PPFT presents a technically rigorous solution for privacy-preserving prompt handling in LLM inference and fine-tuning, eliminating text transmission and defending against inference attacks with minimal utility compromise. The framework’s alignment and adaptation mechanisms are empirically and theoretically validated, establishing a new paradigm for MLaaS privacy without exposing raw data or model internals (2604.06831).