- The paper introduces StructKV, which preserves the structural skeleton of token sequences using global in-degree centrality.
- The paper employs dynamic pivot detection to compress the KV cache effectively, balancing prefill speed, decoding latency, and accuracy.
- The paper demonstrates near-lossless long-context inference on benchmarks like LongBench and RULER while significantly reducing computation.
Structure-Aware KV Cache Compression for Long-Context LLM Inference: The StructKV Framework
Introduction: Motivation and Context
Scaling context windows for LLMs to encompass millions of tokens introduces severe memory and compute bottlenecks, predominantly driven by the linear growth of the Key-Value (KV) cache. Standard approaches for long-context inference optimize either the prefill (computationally bound due to quadratic attention complexity) or decoding (memory bound owing to the KV cache) phase, often sacrificing one for improvements in the other. Most recent compression methods operate on local attention saliency at a single layer, systematically discarding tokens that may function as information hubs across the network, thus undermining long-range dependency retention and retrieval robustness.
The StructKV framework defines a fundamentally different paradigm by preserving the "structural skeleton" of the context. It leverages global in-degree centrality, dynamic pivot detection, and decoupled structural propagation to robustly compress the KV cache while maintaining near-lossless performance under extreme memory constraints. StructKV's design addresses the trilemma of prefill speed, decoding latency, and long-context accuracy without their conventional trade-offs.
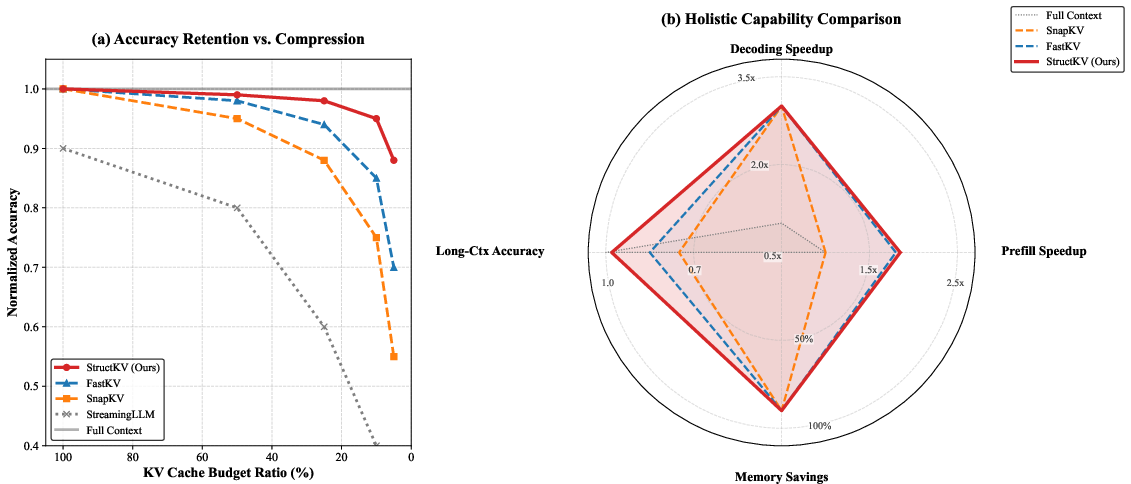
Figure 1: Comparison of StructKV with state-of-the-art methods. StructKV exhibits superior robustness under strict KV cache budgets and resolves the trilemma of speed, latency, and accuracy.
Methodological Innovations
Global In-Degree Centrality
StructKV replaces myopic, layer-local saliency snapshots with an aggregated cross-layer in-degree centrality metric. The centrality score for each token is recursively computed across early network layers, with an exponential decay factor λ enabling semantic prioritization of deeper layers. This aggregation robustly identifies tokens that serve as persistent information hubs, ensuring structural anchors are retained irrespective of transient local saliency fluctuations. The formalization enables the structural skeleton to persist through aggressive pruning, preserving essential long-range dependencies for logical and retrieval tasks.
Dynamic Pivot Detection
Selecting a fixed pruning layer is brittle given architectural scaling. StructKV employs online pivot detection via information-theoretic metrics (entropy, sparsity, variance) to dynamically locate the phase transition where attention stabilizes. A composite gradient-based transition score Tl identifies the structural phase boundary, allowing compression to occur precisely when the context's semantic organization is fully formed. This dynamic alignment generalizes across model depths and facilitates reliable adaptation in evolving LLM architectures.
Figure 2: The three-phase workflow of StructKV, illustrating global centrality accumulation, pivot detection, and structural propagation with decoupling.
Structural Propagation and Decoupling
StructKV decouples the structural propagation (computation) budget from the KV cache (memory) budget. At the dynamically detected pivot layer, only tokens comprising the structural skeleton (high centrality plus local window) are retained and propagated, significantly reducing computation for subsequent layers. The KV cache used for decoding is separately selected via local saliency, allowing ultra-low memory footprints while preserving rich structural context during prefill. This design enables high-fidelity reasoning and retrieval even under strict memory constraints.
Empirical Evaluation and Results
Robustness Across Compression Regimes
StructKV demonstrates superior robustness on LongBench and RULER benchmarks. Under a 10% KV cache budget, StructKV achieves near-lossless accuracy, outperforming FastKV (+1.02) and GemFilter (+8.21) with a LongBench average of 48.61, closely tracking full-context performance (49.33) while reducing prefill computation by 40%. Summarization and code tasks particularly benefit from global centrality: MultiNews and GovReport scores surpass FastKV, affirming StructKV's ability to preserve distributed structural anchors required for complex summarization and code reasoning.
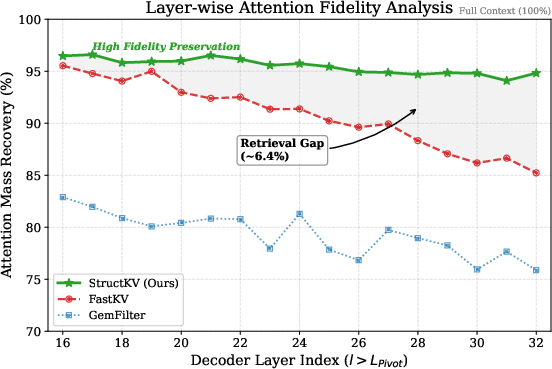
Figure 3: Layer-wise hidden state fidelity demonstrating stable recovery mass with StructKV, substantially outperforming local snapshot methods at depth.
Adaptability to Model Depth
Dynamic pivot detection ensures StructKV generalizes across architectures. Pivot layers shift from 12 (Qwen-2.5-7B) to 28 (Qwen-2.5-32B), illustrating the inapplicability of static pruning methods on deep models. The transition score automatically aligns structural pruning with stabilization of attention patterns, preventing premature structural information loss.
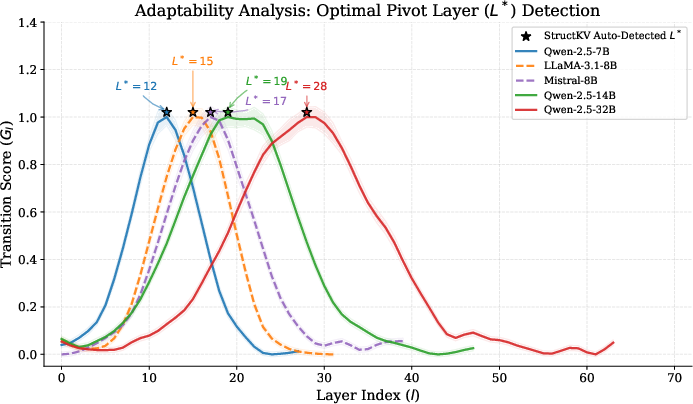
Figure 4: Adaptability of pivot selection across Qwen-2.5 Series, Llama-3.1-8B-Instruct, and Ministral-8B-Instruct.
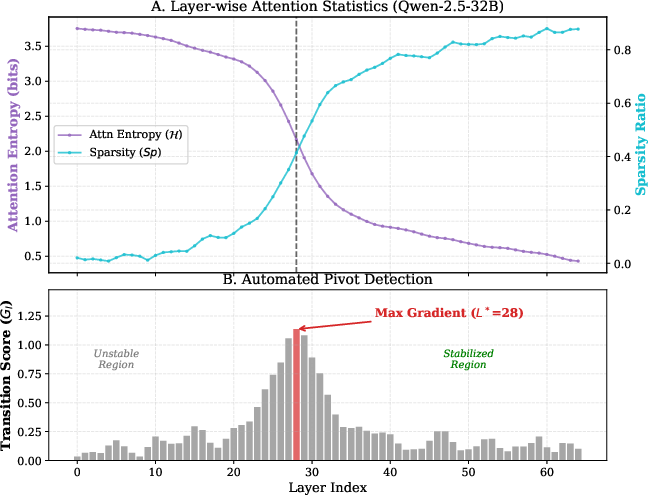
Figure 5: Visualization of dynamic pivot detection on Qwen-2.5-32B-Instruct, showing entropy and sparsity evolution with layer index.
Extreme Context Handling
StructKV sustains high-fidelity retrieval at 128K+ tokens (RULER), outperforming FastKV and other baselines. When local saliency snapshot methods fail under extreme length pressure (FastKV drops to 68.2, StructKV retains 73.6 at 128K), StructKV's historical centrality accumulation acts as a safety net, preserving dormant but topologically critical tokens. Needle-in-a-Haystack tests yield perfect retrieval scores (1.000) for StructKV, matching full-context and FastKV but outperforming GemFilter and SnapKV.
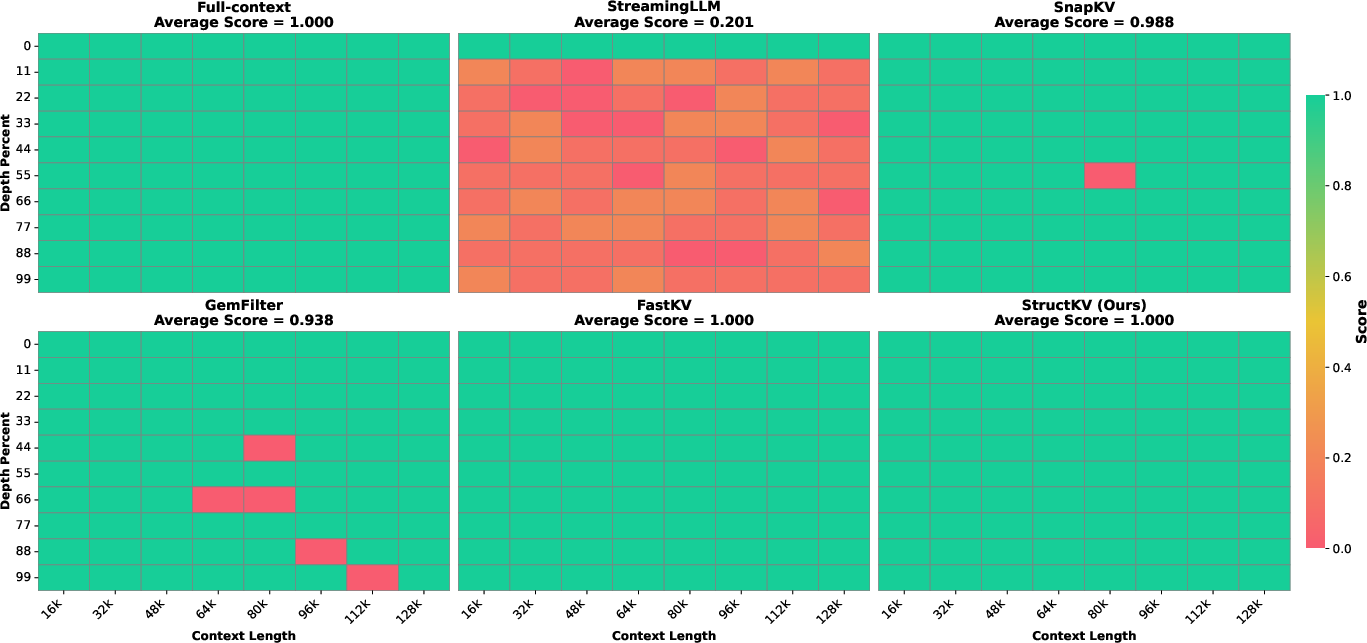
Figure 6: Needle-in-a-Haystack results on LLaMA-3.1-8B-Instruct with 10% KV retention rate, confirming stable retrieval across contexts and depths.
Decoupling Analysis and Efficiency
Coupling computation and cache budgets leads to catastrophic accuracy collapse under aggressive compression. StructKV's decoupling enables robust accuracy recovery (+13.8 points when increasing structural rate to 20% under 10% KV), and at 30%+ structural propagation, sustains high-fidelity regardless of tight cache budgets.
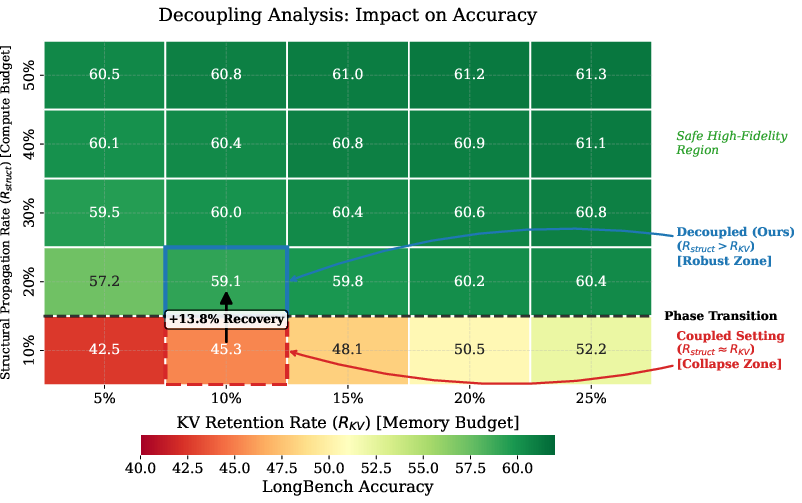
Figure 7: Decoupling analysis showing robust accuracy under independent computation and memory budgets.
End-to-end latency evaluations demonstrate StructKV provides 1.87× prefill speedup with negligible additional overhead (<2.5% latency from centrality and pivot detection components). The efficient vectorized implementation and block-based memory management ensure practical deployment at scale.
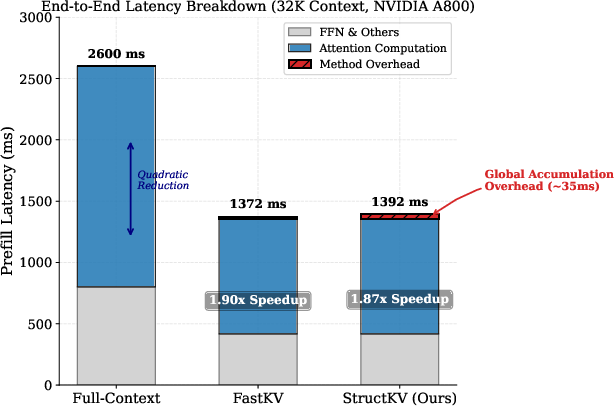
Figure 8: Prefill latency breakdown (LLaMA-3.1-8B, 32K context) showing substantial attention and FFN computational reductions post-pruning.
Practical and Theoretical Implications
StructKV's global structural awareness addresses the brittleness of local saliency for long-context inference, enabling memory-efficient deployment without quality trade-offs. The dynamic pivot detection mechanism supports rapid adaptation in large/deep LLMs, critical for scalability in real-world production systems. Decoupling propagation and cache constraints is essential for architecting inference systems robust to heterogeneous resource budgets and dynamic workloads.
On a theoretical front, the centrality-based paradigm aligns with graph-theoretic principles of information flow in Transformer networks and invites further exploration into structural importance metrics over attention topologies. The framework's limitations highlight opportunities for scaling to million-token contexts, extending to MoE and non-attention architectures, and optimizing aggregation for hardware with restricted memory bandwidth.
Conclusion
StructKV advances the state of scalable long-context inference by structurally preserving global information hubs, dynamically aligning compression with semantic stabilization, and decoupling computational and memory requirements. Experimental results rigorously validate its superiority over local snapshot, static pruning, and decoding-only baselines in accuracy, robust retrieval, and efficiency. StructKV is architecturally agnostic and poised for practical deployment in memory-constrained LLM applications, with potential extensions to future model architectures and scaling regimes.

