- The paper introduces URMF, a robust model that integrates aleatoric uncertainty modeling into multimodal fusion to dynamically downweight unreliable modality contributions.
- It employs a composite training objective combining information bottleneck regularization, modality prior alignment, cross-modal alignment, and uncertainty-driven contrastive learning.
- Experimental results show URMF achieves state-of-the-art performance with 95.02% Accuracy and 94.91% F1-score, demonstrating enhanced robustness in detecting sarcasm.
Uncertainty-aware Robust Multimodal Fusion for Multimodal Sarcasm Detection
Introduction
Multimodal Sarcasm Detection (MSD) addresses the challenge of identifying sarcastic intent in social media content, which often leverages semantic incongruity between textual and visual modalities. Existing methods have advanced cross-modal interaction and incongruity reasoning, but typically fail to account for variable modality reliability—a notable limitation given the noisy and asynchronous nature of real-world social data. The paper "URMF: Uncertainty-aware Robust Multimodal Fusion for Multimodal Sarcasm Detection" (2604.06728) introduces the URMF architecture, which integrates explicit unimodal aleatoric uncertainty modeling into the fusion process. This enables the network to dynamically adapt to unreliable modalities and enhances overall robustness and discriminative power for sarcasm detection.
URMF Architecture and Methodology
URMF is a unified, end-to-end framework composed of four key modules: cross-modal interaction, unimodal uncertainty modeling, uncertainty-guided dynamic fusion, and a composite training objective. The design premise is that by quantifying and leveraging per-modality uncertainty at the representation level, the model can actively suppress spurious information and highlight incongruity signals central to sarcasm recognition.
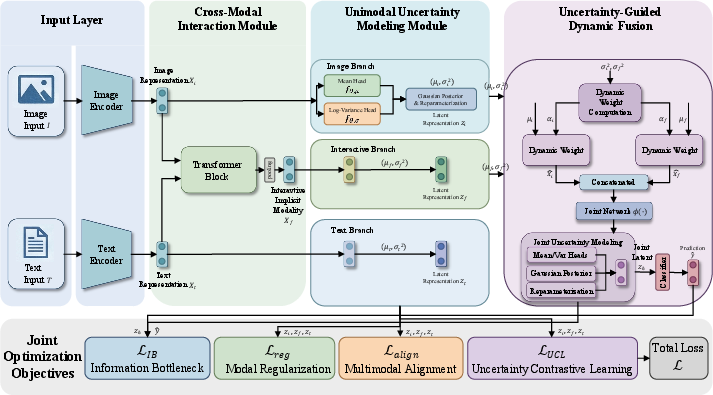
Figure 1: URMF pipeline: from image-text input through cross-modal interaction and uncertainty modeling to prediction; the model is supervised with bottleneck, regularization, alignment, and uncertainty losses.
Cross-modal Interaction
URMF departs from conventional Transformer-based multimodal fusion strategies. Rather than employing "self-attention first, then cross-attention," cross-attention is deployed at the outset to inject image-derived visual evidence into the textual token stream. Subsequent self-attention refines intra-modal dependencies in the resultant semantic space. This order provides stronger modeling of conflicts induced by image-text incongruity, essential for robust sarcasm detection.
Aleatoric Uncertainty Modeling
Each modality’s latent representation is parameterized as a multivariate Gaussian random variable, where both the mean and variance are learned via distinct MLP heads. The mean encodes semantic content, while variance quantifies irreducible, modality-specific noise—i.e., aleatoric uncertainty. This formulation enables the downstream fusion module to discern and adaptively downweight unreliable modality contributions based on learned uncertainty estimates.
Uncertainty-guided Dynamic Fusion
Fusion proceeds by aggregating the interaction-aware latent modality and the image modality. A scalar uncertainty measure (average variance) is computed for each; fusion weights are assigned inversely proportional to uncertainty—lower uncertainty yields a higher fusion weight. This approach ensures that the final joint representation for classification is both semantically rich and robust to multimodal noise artifacts.
Joint Optimization Objective
URMF's learning objective integrates four loss components:
- Information bottleneck regularization: Controls the informativeness of representations while suppressing redundant encoding.
- Modality prior regularization: Aligns unimodal latent distributions towards a standard prior, stabilizing uncertainty estimation and regularizing representation spaces.
- Cross-modal alignment: Enforces KL divergence alignment between modality-specific distributions, reducing representation drift and enhancing cross-modal semantic congruity.
- Uncertainty-driven contrastive learning: Stochasticity inherent in uncertainty modeling is used to construct positive and negative samples for contrastive loss, further enhancing representation robustness.
Experimental Results and Ablation Analysis
Comprehensive evaluation on the public MSD benchmark demonstrates that URMF surpasses state-of-the-art unimodal, multimodal, and MLLM-based approaches across all core metrics. Specifically, URMF outperforms previous best results by up to 1.0 percentage point in accuracy and F1-score, reaching 95.02% Accuracy and 94.91% F1-score. Notably, it exhibits superior balancing of Recall and Precision, indicative of both improved conflict cue preservation and effective suppression of misleading modalities.
Ablation experiments confirm the individual and synergistic contributions of the model's uncertainty modeling, fusion strategy, and loss regularization components. Replacing URMF’s interaction module with a standard Transformer or disabling uncertainty-guided fusion consistently leads to sizable performance drops.
Figure 2: t-SNE plots of joint latent space for major ablation variants versus full URMF; URMF achieves maximal inter-class separation and compact class clustering.
Visualization of the joint latent space under t-SNE further establishes that the full URMF architecture yields the most compact, well-separated class distributions, whereas ablated variants exhibit increased cluster overlap, particularly near decision boundaries.
Implications and Future Directions
URMF’s explicit uncertainty quantification strategy demonstrates that modeling modality reliability at the representation level is a substantial factor in complex cross-modal tasks such as sarcasm detection. This has practical ramifications for deployment in dynamic, noisy streams where modality relevance fluctuates or where samples may be partially missing. Theoretically, it advances the perspective that uncertainty should be leveraged not only for post-hoc calibration or outlier rejection, but as an active regularization and learning signal during multimodal fusion.
Prospective research includes scaling the framework to broader multimodal domains and larger datasets, integrating more granular or hierarchical uncertainty decomposition, and transferring the paradigm to multimodal foundation models with even higher-capacity backbone encoders. Furthermore, exploring URMF’s applicability to open-world or few-shot scenarios—where modality noise and incompleteness are even more pronounced—may yield further advances in real-world cross-modal reasoning.
Conclusion
URMF sets a new standard for multimodal sarcasm detection by integrating aleatoric uncertainty modeling directly into the representation and fusion stages of a cross-modal network. Explicit modeling and exploitation of modality-specific reliability enables dynamic evidence weighting, yielding improvements in robustness and discriminability not attainable by prior deterministic or equally-weighted fusion methods. These results underscore the pivotal role of uncertainty-aware architectures in advancing the state of the art in multimodal reasoning systems.

