- The paper introduces the CGVC paradigm that leverages controllable generative models to reconstruct non-keyframes from compact keyframe and control prior sets.
- The paper employs a color-distance-guided keyframe selection and luminance-based control extraction to balance rate-distortion with perceptual quality.
- The paper demonstrates superior performance over traditional and neural codecs by achieving improved temporal coherence and color fidelity at competitive bitrates.
Controllable Generative Video Compression: Paradigm, Methodology, and Empirical Evaluation
Introduction and Motivation
Traditional video compression frameworks, grounded in residual coding and rate-distortion optimization (RDO), have reached an advanced state exemplified by standards such as H.264/AVC, H.265/HEVC, and H.266/VVC. While these codecs maintain high signal fidelity, their reliance on pixel-wise metrics often leads to artifacts—blur, blocking, ringing—at low bitrates, diverging from perceptual realism. Recent advances in neural video compression (NVC) have bifurcated into fidelity-oriented and perceptual-oriented methods. Perceptual methods based on GANs or diffusion models hallucinate visually appealing details but often sacrifice temporal or structural consistency, introducing drift and hallucinations. The core challenge remains: how to reconcile the tradeoff between perceptual quality and faithful signal reconstruction under stringent bitrate constraints.
The paper "Controllable Generative Video Compression" (2604.06655) introduces the Controllable Generative Video Compression (CGVC) paradigm, which leverages recent advances in controllable video generation (notably multimodal generative frameworks such as VACE) to synthesize high-fidelity, temporally coherent video guided by a compact set of transmitted conditions. The crux of CGVC is to encode a minimal set of structural and appearance priors—keyframes and frame-level control signals—while generating non-keyframes via a generative model, with explicit mechanisms for color fidelity and rate-appearance balance.
Paradigm and System Architecture
CGVC transforms the traditional paradigm by reframing non-keyframe reconstruction as a conditional generation problem within a multimodal generative modeling framework. The pipeline comprises the following stages:
- Keyframe Selection and Encoding: Keyframes are chosen to segment the video into clips. Each segment is bounded by a first and last keyframe. Instead of uniform sampling, CGVC introduces a color-distance-guided keyframe selection algorithm that maximizes the diversity of object-level color appearances, balancing the coverage of visual content and bitrate efficiency.
- Extraction of Control Priors: For each non-keyframe within a segment, a dense structural prior is computed. Three candidates are considered: skeleton maps, edge maps, and luminance components. Empirical results favor the luminance component, which encapsulates stable and semantically rich cues closely aligned with object boundaries while being efficient to encode.
- Transmission and Compression: Both keyframes and per-frame control priors are compressed using a traditional video codec. The system is codec-agnostic—improvements in traditional video encoding translate directly to improved CGVC performance.
- Decoding and Controllable Generation: At the decoder, the VACE generative model fuses decoded keyframes and control priors through cross-attention, synthesizing non-keyframes with temporal and spatial consistency.
- Color Correction: To compensate for color drift inherent to generative models, CGVC applies a frame-wise linear color correction using the mean and variance statistics of the original frame, which are losslessly transmitted.
The following figure outlines the full system architecture:
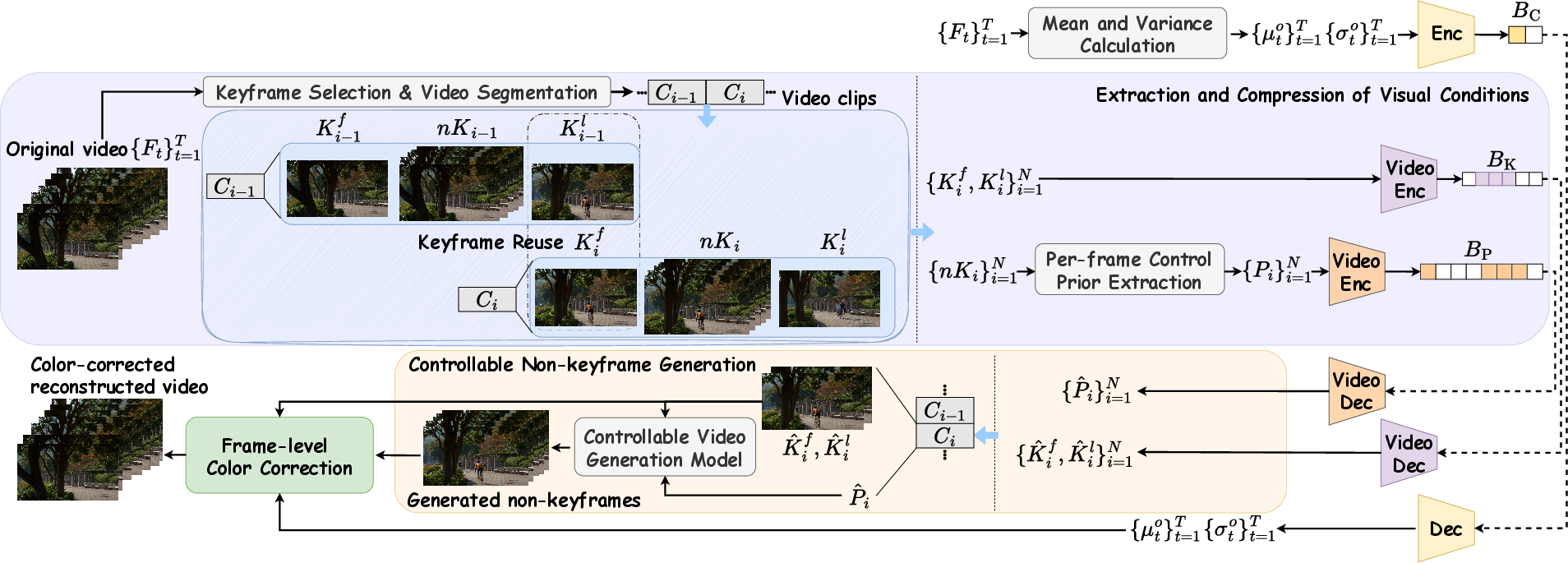
Figure 1: Framework of the proposed CGVC paradigm.
Keyframe Selection and Its Impact
Uniform keyframe selection can fail to capture significant appearance variations—especially color changes—across objects, leading to suboptimal color fidelity in reconstructed videos. CGVC's color-distance-guided algorithm utilizes object segmentation and color histogram analysis to adaptively select keyframes that reflect substantial changes in color distributions at the object level. This process is formalized via bidirectional keyframe search and kernel density estimation, ensuring that color novelty, rather than frame spacing alone, drives keyframe placement.
The efficacy of color-distance-guided selection compared to uniform selection is illustrated in the following example:

Figure 2: Color-distance-guided selected keyframes and the corresponding reconstructed non-keyframe.
Ablation Studies on Control Priors and Color Correction
A detailed ablation shows that employing the luminance component as the control prior yields a superior balance between signal fidelity (as measured by PSNR and MS-SSIM) and perceptual quality (MDTVSFA, DISTS), outperforming both edge maps and skeleton maps in guiding generative reconstruction. Removing the color correction step results in a pronounced degradation across all metrics, demonstrating its necessity in practical scenarios where color drift is perceptually salient.
Quantitative and Qualitative Evaluation
Quantitative Metrics and Numerical Claims
Extensive benchmarks against traditional and neural video codecs on standard datasets (HEVC, MCL-JCV, UVG) are conducted. CGVC outperforms prior perceptual-oriented codecs (e.g., PLVC) in both no-reference (MDTVSFA) and reference-based (DISTS) perceptual metrics at comparable or lower bitrates. In fidelity metrics, such as MS-SSIM and PSNR at low bitrates, CGVC demonstrates competitive or superior performance against state-of-the-art neural codecs (e.g., DCVC-FM). Notably, CGVC achieves significantly improved perceptual quality without substantial penalties in rate or signal distortion, a nontrivial accomplishment in view of the rate-distortion-perception tradeoff [blau2019rethinking].
Rate-distortion-perception tradeoffs across datasets are summarized below:
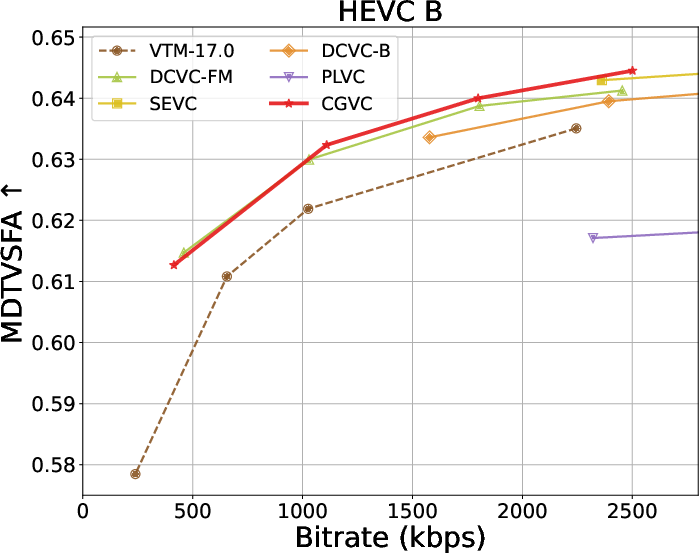
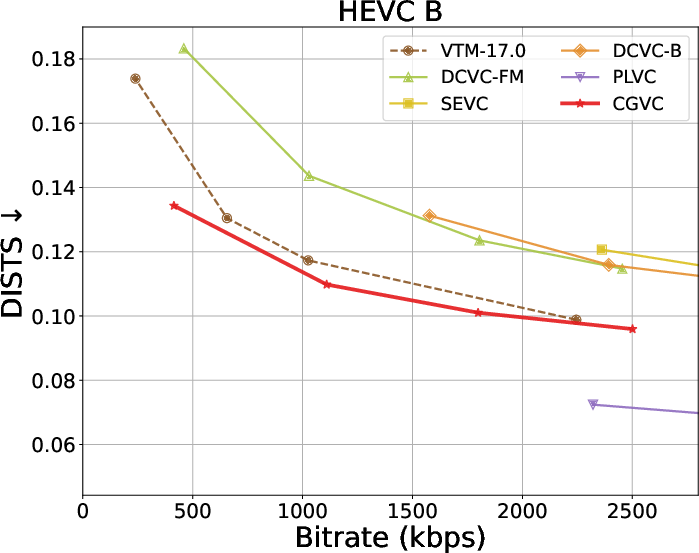
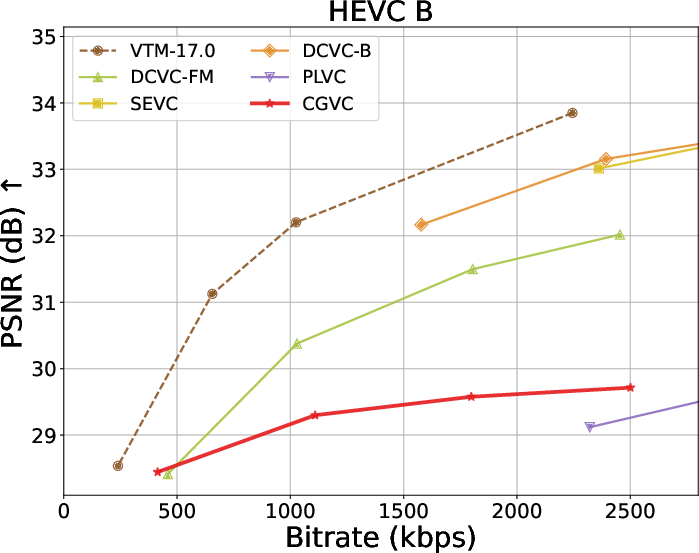
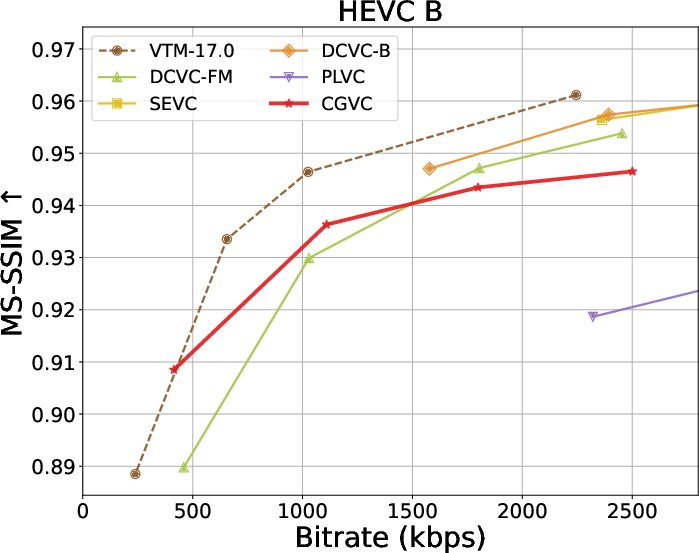
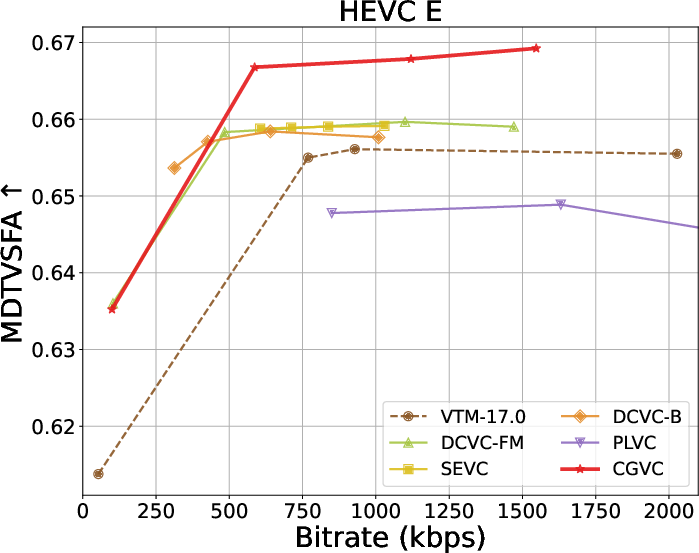
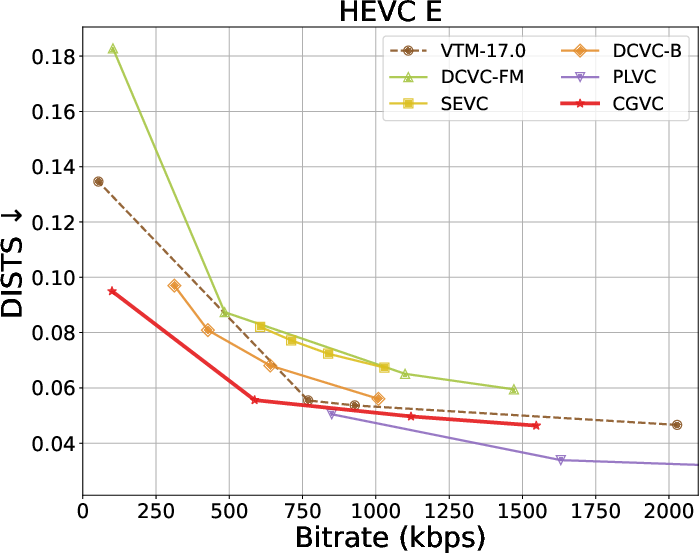
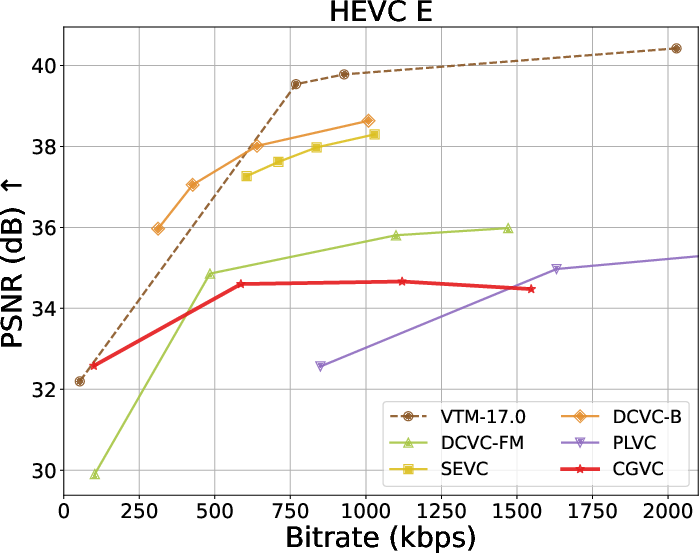
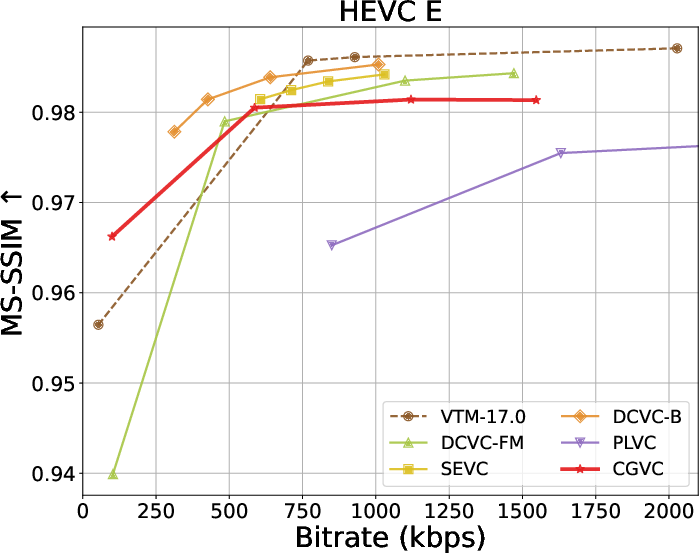
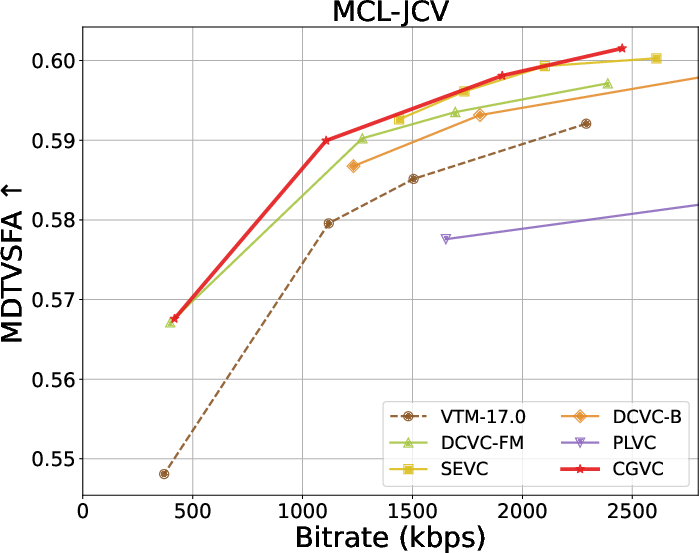
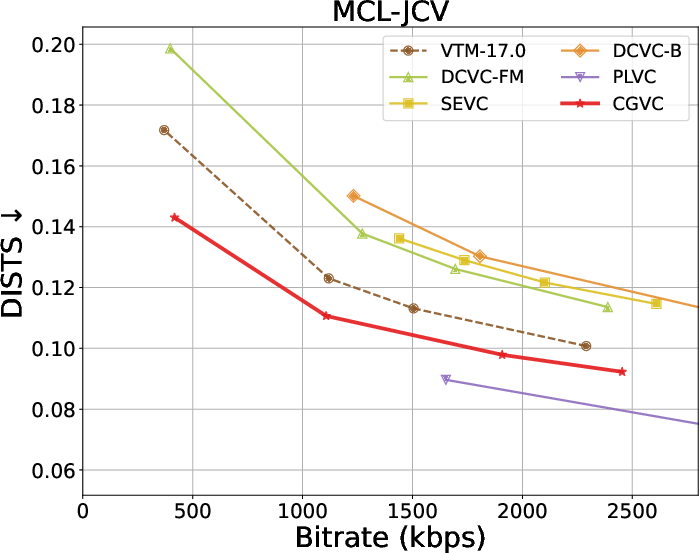
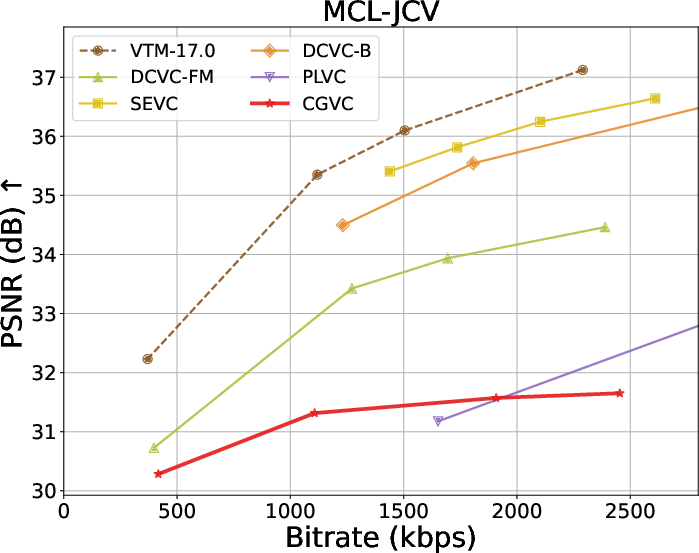
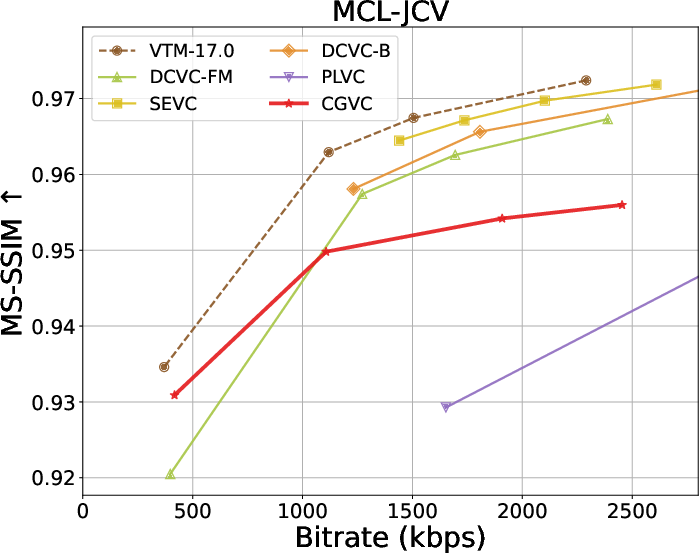
Figure 3: Rate and perception/fidelity curves on the HEVC and MCL-JCV datasets.
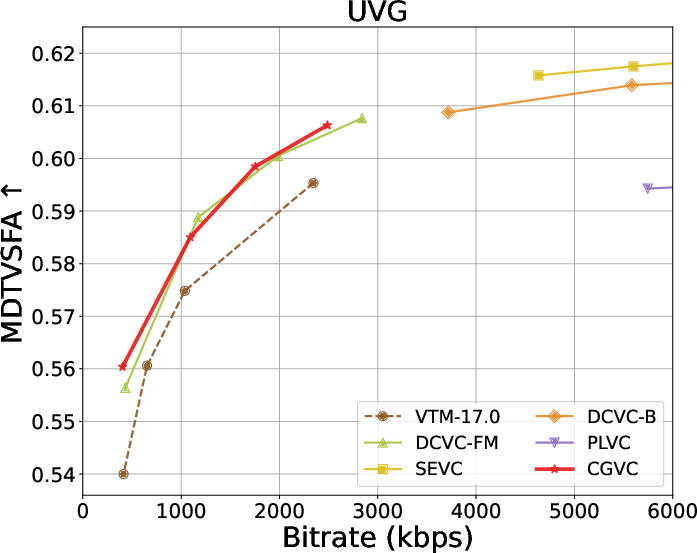
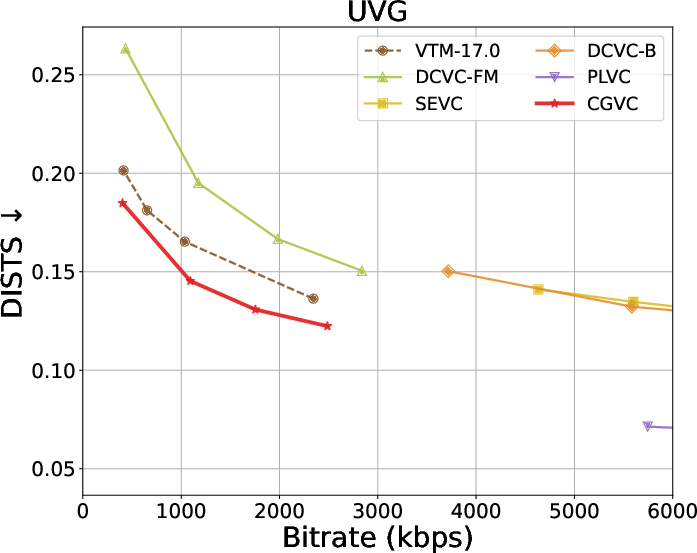
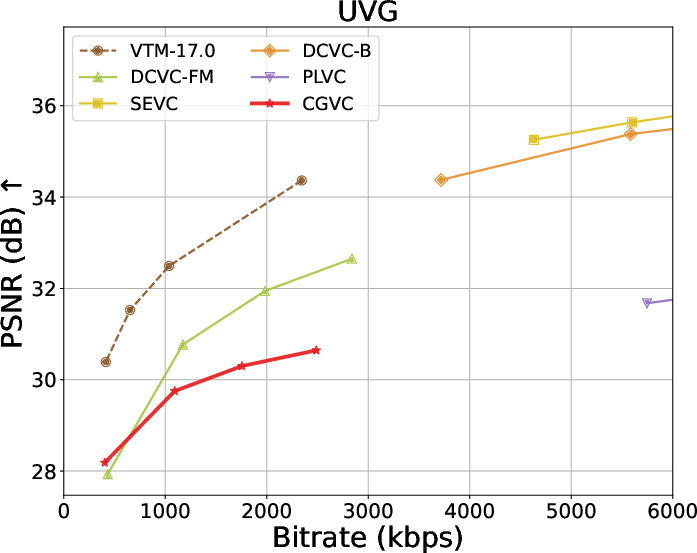
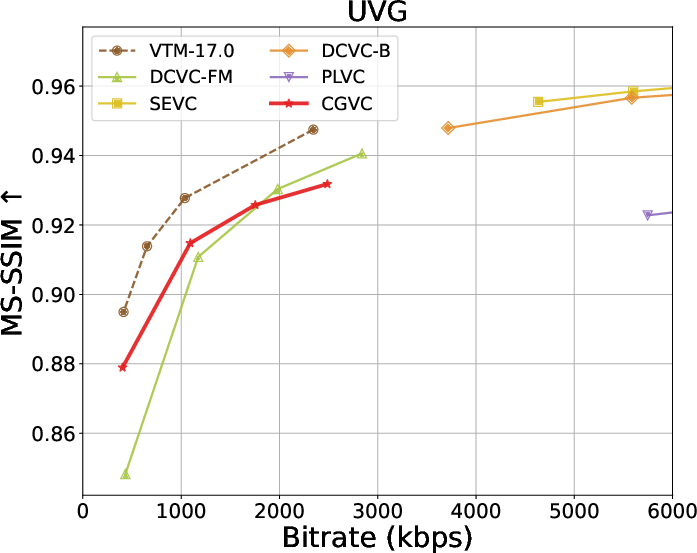
Figure 4: Rate and perception/fidelity curves on the UVG dataset.
A salient result is that, under tight bitrate budgets, CGVC reconstructions present higher subjective quality and temporal consistency compared to both traditional and prior neural codecs, as validated by visual analyses.
Visual Comparisons
Subjective analyses across diverse content highlight CGVC's ability to synthesize faithful structural and textural details. In contrast to PLVC, which prioritizes perceptual features sometimes at the expense of content integrity, and DCVC-FM, which occasionally produces over-smoothed frames, CGVC manages to deliver reconstructions that better balance sharpness, color fidelity, and temporal coherence. This superiority is evident in qualitative comparisons:

Figure 5: Visual comparisons with baselines on the videoSRC26 sequence in the MCL-JCV dataset.

Figure 6: Visual comparisons with baselines on the videoSRC19 sequence in the MCL-JCV dataset.

Figure 7: Visual comparisons with baselines on the Kimono sequence in the HEVC Class B dataset.

Figure 8: Visual comparisons with baselines on the FourPeople sequence in the HEVC Class E dataset.
Key Hyperparameter Studies and Codec Agnosticism
Hyperparameter tuning of keyframe interval and color-distance threshold demonstrates clear tradeoffs. Larger keyframe intervals reduce bitrate at the risk of insufficient context for generative models, while lower color-distance thresholds admit more keyframes, raising bitrate but improving color fidelity. Empirical search establishes an optimal configuration that is robust to content variability.
CGVC's codec-agnostic nature is validated by substituting different back-end codecs (e.g., VVenC vs. S266), confirming that advances in standard codecs translate into better overall system rates or reconstruction quality.
Implications and Prospects
Theoretically, the CGVC framework reframes generative compression as a controlled conditional video generation task, providing a modular foundation for integrating the latest advances in diffusion models, cross-modal conditioning, and compact representation learning. Practically, its codec-agnostic approach, together with adaptive control prior extraction, enables seamless upgrades and domain adaptation with minimal retraining.
Looking forward, optimizing the joint compression of visual conditions and generative models—rather than treating them as modular but independent entities—remains a promising direction. Efficient acceleration of the generative decoding stage, perhaps via distillation or hybrid inference, will be required for adoption in latency-sensitive applications.
Conclusion
CGVC presents a rigorously engineered paradigm reconciling perceptual realism and signal fidelity in video compression. By leveraging multimodal generative models conditioned on adaptively chosen keyframes and luminance priors, and by integrating an effective color correction mechanism, CGVC achieves superior perceptual and fidelity metrics at competitive bitrates compared to both neural and traditional baselines. Its extensibility and modular design chart a promising pathway for generative compression integrated with the evolving landscape of large vision models and foundational video generative architectures.

