The Master Key Hypothesis: Unlocking Cross-Model Capability Transfer via Linear Subspace Alignment
Abstract: We investigate whether post-trained capabilities can be transferred across models without retraining, with a focus on transfer across different model scales. We propose the Master Key Hypothesis, which states that model capabilities correspond to directions in a low-dimensional latent subspace that induce specific behaviors and are transferable across models through linear alignment. Based on this hypothesis, we introduce UNLOCK, a training-free and label-free framework that extracts a capability direction by contrasting activations between capability-present and capability-absent Source variants, aligns it with a Target model through a low-rank linear transformation, and applies it at inference time to elicit the behavior. Experiments on reasoning behaviors, including Chain-of-Thought (CoT) and mathematical reasoning, demonstrate substantial improvements across model scales without training. For example, transferring CoT reasoning from Qwen1.5-14B to Qwen1.5-7B yields an accuracy gain of 12.1% on MATH, and transferring a mathematical reasoning direction from Qwen3-4B-Base to Qwen3-14B-Base improves AGIEval Math accuracy from 61.1% to 71.3%, surpassing the 67.8% achieved by the 14B post-trained model. Our analysis shows that the success of transfer depends on the capabilities learned during pre-training, and that our intervention amplifies latent capabilities by sharpening the output distribution toward successful reasoning trajectories.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper asks a simple but powerful question: can we “copy” a skill that one AI LLM has and make another model use that skill—without retraining either model? The authors’ answer is yes. They propose the Master Key Hypothesis and a practical method called Unlock. The idea is that each skill (like thinking step by step or doing math) corresponds to a direction inside the model’s internal “thought space.” If you can find that direction in one model and map it into another model’s space, you can push the second model’s thoughts in the right direction at the moment it’s answering—no extra training needed.
Goals and Questions
The paper’s main goals are to:
- Figure out if abilities learned after pre-training (like better reasoning from instruction-tuning or reinforcement learning) can be reused in different models without training.
- Test whether skills are like “directions” in a shared, low-dimensional control space inside models.
- Build a simple, training-free tool (Unlock) to extract a skill direction from one model and apply it to another model so the second model shows the skill at answer time.
In short: Can we find a portable “key” that unlocks a behavior in many models?
Approach (Everyday Explanation)
Think of a LLM as a huge mixing board full of knobs and sliders that shape how it “thinks.” Most of the time, only a few important knobs really matter for a particular skill—this is the “low-dimensional subspace.” A skill like chain-of-thought (step-by-step explanations) is like setting the knobs in a certain direction.
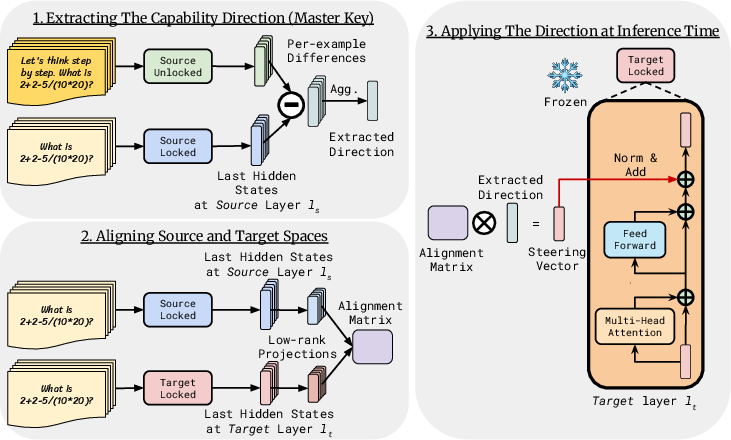
The Unlock method works in three steps:
- Find the skill direction in a source model
- Compare the model when it does not show the skill (“Locked”) with when it does show the skill (“Unlocked”).
- For example, take the same model and use two prompts: a normal prompt (no step-by-step), and a chain-of-thought prompt (“Let’s think step by step”).
- Look at the internal activations (the model’s “brain signals”) and compute their difference. Averaging across a small set of unlabeled examples gives a consistent direction—this is the “MasterKey.”
- Align the source and target models’ spaces
- Different models can have different sizes and “shapes” of internal spaces.
- The authors use a simple “adapter” that aligns the most important parts of both models’ spaces using basic linear math (like fitting a plug adapter so one plug fits another outlet).
- This is done by focusing on a few main components (the top “knobs”), then learning a small linear mapping from the source’s main components to the target’s main components.
- Apply the transferred direction at answer time
- While the target model is generating an answer, gently nudge its internal activations along the transferred direction at each layer.
- Think of it as steering: not replacing the model, just giving it a push toward the right kind of thinking.
- A strength parameter controls how strong the push is.
Key points:
- No new training, no labels—just forward passes and a handful of example prompts.
- Works across different model sizes and even different model families in early tests.
Main Findings and Why They Matter
Here are the main results, explained simply:
- It boosts step-by-step reasoning without changing weights
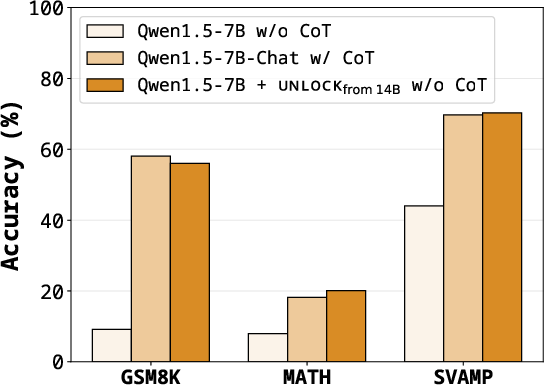
- Transferring a chain-of-thought (CoT) “key” from a larger Qwen1.5-14B model to a smaller Qwen1.5-7B model raised performance on math word problems a lot.
- Example: On GSM8K, the 7B model jumped from about 9% to 56% correct without even using a CoT prompt, close to the 58% the instruction-tuned 7B model gets with CoT prompting.
- This shows the nudge can reliably trigger step-by-step thinking.
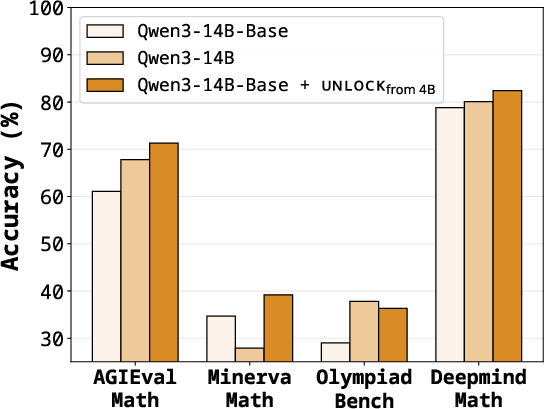
- It can improve math reasoning and sometimes beat post-trained models
- Transferring a math reasoning direction from Qwen3-4B to Qwen3-14B improved AGIEval-Math from 61.1% to 71.3%, even surpassing a 14B model that was instruction-tuned (67.8%).
- That’s surprising: a training-free nudge matched or beat what expensive post-training did in some cases.
- It works best when the skill already exists “under the surface”
- If the target model’s pre-training already gave it some beginnings of the skill (even if it doesn’t show it naturally), the nudge unlocks it.
- If the skill truly isn’t there, the nudge can’t invent it from scratch.
- Asymmetry: small-to-large transfers often help more than large-to-small
- Bigger models tend to contain more of the needed circuits, so nudges from a small model can still activate the right patterns in a larger model.
- But a small model might not have the capacity to mirror all the complexity of a large model’s skill.
- What the nudge actually does: “sharpening”
- The authors’ analysis suggests the method makes the model stick to more promising reasoning paths, rather than wandering.
- This echoes findings about some post-training methods, which don’t add brand-new knowledge so much as push the model to choose better outputs it already “knows” are likely.
Why this matters:
- Training new models or post-training existing ones is expensive.
- If you can reuse a skill from one model across many models without retraining, you save time, money, and compute.
- It makes capabilities more modular and portable.
Implications and Impact
- Reusable “skill modules”: If skills really are directions in a shared, small control space, we can extract a “MasterKey” for a capability (like step-by-step reasoning, safety style, or math strategies) and plug it into other models at answer time.
- Faster, cheaper development: Instead of retraining each new model to have the same behaviors, labs could transfer capabilities quickly with Unlock-like tools.
- Limits still apply:
- This approach doesn’t invent totally new abilities that a model never learned during pre-training. It mostly reveals and amplifies what’s already latent.
- Results can depend on how similar or different the models are, and how strong the skill is in the target model.
- A path toward modular AI: Over time, we could imagine libraries of MasterKeys for different behaviors that can be composed and aligned across many models.
In short, the paper presents an encouraging step toward plug-and-play AI skills. By treating capabilities as directions in a model’s internal space and aligning those directions across models, we can unlock useful behaviors without costly retraining.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains unresolved, uncertain, or unexplored in the paper, phrased to guide actionable follow-up research:
- Theoretical grounding and identifiability
- Lack of a formal proof or necessary/sufficient conditions for the Master Key Hypothesis (existence, uniqueness, and identifiability of capability directions across models).
- No characterization of when linear maps suffice versus when nonlinear mappings are required for cross-model alignment.
- Unclear whether capability directions are unique or whether multiple, non-collinear directions can induce the same behavior (directional degeneracy).
- Subspace alignment design
- Alignment uses SVD and least-squares in a shared low-rank subspace; performance of alternative mappings (e.g., orthogonal Procrustes, CCA, partial least squares, constrained/orthogonal W, or small nonlinear adapters) is not evaluated.
- Sensitivity of results to the choice of subspace rank k and the number of queries n is not systematically quantified (sample complexity and bias–variance trade-offs).
- The mapping is estimated with a shared prompt to reduce variance; the robustness to differing prompts or distributions between Source and Target during alignment is not tested.
- No analysis of whether alignment quality varies across layers and whether a layer-specific or block-specific alignment schedule improves transfer.
- Layer selection and intervention strategy
- Layers are matched by relative depth; there is no ablation comparing alternative layer-matching strategies (e.g., attention/MLP-only hooks, absolute layer correspondence, or learned layer mappings).
- The intervention is applied to the final-token residual stream at all layers; efficacy of token-wise, position-dependent, or module-specific interventions is not explored.
- No study of dynamic or input-conditional steering (e.g., gating, adaptive α) versus the current global, fixed-direction approach.
- Generality across architectures and families
- Cross-family results are preliminary; comprehensive tests across diverse architectures (e.g., Llama, Mistral, MPT, MoE, multimodal LMMs) are missing.
- The method’s robustness to different tokenizers and vocabulary segmentations is not evaluated (especially for cross-family transfer).
- Applicability to non-autoregressive encoders, encoder–decoder models, and multimodal models is untested.
- Scope of capabilities
- Focus is on CoT and math; transferability to other non-atomic domains (coding, planning, tool use, retrieval-augmented reasoning, multilingual reasoning, safety/harms mitigation) is not investigated.
- Compositionality of capabilities (combining multiple MasterKeys, interference/synergy, and order of application) is unexplored.
- Persistence and stability of unlocked capabilities across long contexts or multi-turn interactions are not measured.
- Causality and interpretability
- Evidence that directions “cause” capabilities remains correlational; no causal tests (e.g., interventions + counterfactuals, circuit-level ablations) validate mechanistic explanations.
- It remains unclear which circuits or attention heads mediate the induced behavior, and whether the same circuits are engaged across Source and Target.
- Asymmetry and scaling laws
- The observed small-to-large vs. large-to-small asymmetry lacks a predictive scaling law or diagnostic to forecast when transfer will succeed or fail by model size.
- No quantitative measure of representational overlap or “capability salience” is proposed to predict transfer effectiveness in a target model.
- Atomic vs. non-atomic capability definitions
- The paper provides informal, model/data-dependent definitions; operationalizing, measuring, and standardizing atomicity across tasks and models remains open.
- For non-atomic capabilities, the extent to which transfer succeeds due to latent representation compatibility versus overfitting to steering artifacts is unclear.
- Evaluation and baselines
- Missing comparisons to weight-space and output-space transfer baselines (task arithmetic, logit steering, LoRA adapters, and activation editing baselines) under identical settings.
- Lack of ablations on aggregator choice (mean vs. PCA vs. alternatives), per-layer contributions, and intervention strength α across datasets.
- No evaluation of robustness under distribution shift, out-of-domain tasks, or adversarial/worst-case prompts.
- Side effects and trade-offs
- Potential degradation on non-targeted tasks (e.g., general QA, summarization, factuality, calibration) is not examined (catastrophic interference).
- No measurement of safety/ethical risks (e.g., transferring undesirable or unsafe behaviors) or safeguards for capability misuse.
- Effects on calibration, uncertainty, and hallucination rates are not reported despite claims of “distribution sharpening.”
- Practicality and deployment
- Inference-time compute/latency and memory overhead of per-layer interventions are not quantified; scalability to very deep or large models remains unknown.
- The approach requires internal activation access; feasibility in API-only or restricted-access settings is not addressed.
- Stability across random seeds, different prompt templates, decoding strategies (temperature, nucleus sampling), and maximum generation lengths is not reported.
- Data and prompts
- Sensitivity to the choice of unlabeled prompts and query sets used to build MasterKeys and alignments is not quantified; guidance for dataset selection remains vague.
- Task-agnostic vs. task-conditioned trade-offs are observed but not formalized; criteria for choosing between them in practice are not provided.
- Failure modes and limits
- Conditions under which Unlock fails to improve or actively harms performance are not systematically catalogued.
- The maximum “distance” between Source and Target (architecture, data, scale) for which linear subspace alignment remains viable is not bounded.
- Long-horizon and structure
- Impact on very long reasoning chains, program synthesis with execution, or tasks requiring external tool use and memory is unassessed.
- Whether steering changes early-token distributions in ways that reliably propagate to correct long-horizon trajectories is only partially investigated.
These gaps suggest concrete directions for future work: formalizing and stress-testing the hypothesis and alignment method; broadening capability, model, and task coverage; introducing causal/interpretability analyses; evaluating safety and side effects; and establishing practical guidelines (sample complexity, rank selection, and deployment constraints).
Practical Applications
Immediate Applications
The paper’s “Unlock” framework enables training-free, label-free transfer of reasoning behaviors between LLMs via linear subspace alignment. The following applications can be deployed now, given access to model activations and the ability to apply inference-time interventions.
- Training-free reasoning boosts for smaller/cheaper models (software, education, customer support)
- What: Add Chain-of-Thought (CoT) and math reasoning behavior to base models at serving time, improving task success without retraining.
- Tools/workflows: “Reasoning Boost” inference plugin that extracts MasterKeys from a post-trained or prompted source model and injects them into target models; per-task alpha scheduling; capability toggles in product UIs.
- Assumptions/dependencies: Access to hidden states and ability to modify residual streams at inference; small unlabeled dev set from the task domain; target model must have latent (atomic) capability for best results; slight latency overhead from per-layer interventions.
- Cost-efficient capability reuse across product lines (AI platforms, MLOps)
- What: Post-train once (e.g., RLHF/RLVR on a flagship model), then extract and distribute “capability packs” (MasterKeys + alignment maps) to many base models across SKUs.
- Tools/workflows: Internal capability library; automated pipeline for MasterKey extraction, low-rank alignment, validation, and deployment; capability versioning in model registries.
- Assumptions/dependencies: Consistent access to “locked” and “unlocked” model variants or prompt-induced variants; hyperparameter tuning (k, n, α) on held-out dev sets; governance to prevent inadvertent capability drift.
- On-device or edge “reasoning mode” without retraining (mobile, robotics, embedded)
- What: Inject reasoning directions into compact on-device models to improve planning or step-by-step explanations while keeping data on the device.
- Tools/workflows: Lightweight runtime for vector injection; precomputed alignment maps shipped as part of the model bundle.
- Assumptions/dependencies: Edge runtime must support activation access; compute/memory budget for per-layer vector addition; gains are larger when the target model’s latent space already encodes the capability.
- Domain- or task-specific adaptation using unlabeled prompts (healthcare, finance, legal)
- What: Tailor reasoning behavior for domain formats (e.g., math-style answer boxes, calculation consistency) using unlabeled in-domain prompts to compute alignment and steer vectors.
- Tools/workflows: Task-conditioned extraction on small in-domain dev sets; deployment as “Math mode,” “Compliance mode,” or “Clinical note reasoning mode.”
- Assumptions/dependencies: Sufficiently representative unlabeled prompts; rigorous domain evaluation (especially in high-stakes settings); careful monitoring for distribution shift.
- Data-efficient distillation and dataset generation (academia, AI R&D)
- What: Use Unlock to reliably elicit high-quality CoT trajectories from base models, then collect these traces for supervised distillation into even smaller models.
- Tools/workflows: “Steer-then-distill” pipelines; automated filtering of high-confidence trajectories produced under MasterKey steering.
- Assumptions/dependencies: License compliance for source and target models; quality filters to avoid amplifying spurious behaviors.
- Rapid A/B testing of post-training targets (software, product teams)
- What: Prototype the effect of prospective post-training objectives by extracting directions from prompted or lightly tuned sources, before committing compute to full RLHF/RLVR.
- Tools/workflows: Sandbox for extracting and trialing MasterKeys on target candidates; regression tests for non-regression on safety and general performance.
- Assumptions/dependencies: Proxy directions approximate post-training effects best when capabilities are already latent in the target.
- Safety or stylistic behavior transfer (policy, trust & safety)
- What: Transfer refusal behavior, tone, or guardrails from a safety-aligned model into base models at inference-time.
- Tools/workflows: “Safety Key” packs for refusal-on-demand; rule-based gating that controls when to activate/deactivate safety keys.
- Assumptions/dependencies: Safety directions must be validated to avoid over- or under-refusal; capability composition (reasoning + safety) requires careful interaction testing.
- Carbon and cost savings via smaller targets (energy, procurement, sustainability)
- What: Replace some large-model inference with smaller “unlocked” models for workloads needing reasoning but not full model capacity.
- Tools/workflows: Routing policies (confidence-based fallback to larger models only when needed); tracking of energy and cost savings.
- Assumptions/dependencies: Observed directional asymmetry—small-to-large transfers often yield bigger relative gains; for heavy non-atomic capabilities, expect more modest improvements without further training.
Long-Term Applications
With additional research and engineering (e.g., broader capability coverage, standardized interfaces, hardware support), the following applications become more feasible.
- Standardized capability libraries and marketplaces (software ecosystem, open science)
- What: Interoperable repositories of MasterKeys and alignment maps (e.g., “CoT v2 for Math,” “Tool-use v1,” “Safety Key v3”) reusable across families.
- Tools/products: Capability pack registries with metadata, provenance, and evaluation reports; SDKs for integration with serving stacks.
- Assumptions/dependencies: Community standards for interfaces and evaluation; IP/licensing frameworks for capability artifacts; cross-architecture layer mapping.
- Compositional capability stacking and routing (general AI, enterprise)
- What: Combine multiple capabilities (reasoning, tool-use, safety, style) at inference via weighted or context-aware routing of MasterKeys.
- Tools/products: Capability routers; conflict-resolution and arbitration policies; per-task α controllers.
- Assumptions/dependencies: Nonlinear interactions between directions; need for verifiable composition safety and stability.
- Cross-modal and cross-architecture transfer (multimodal AI, robotics)
- What: Extend linear subspace alignment to vision-language or speech-LLMs, enabling planning or perception-to-action reasoning transfer to smaller agents.
- Tools/products: Multimodal alignment modules; robotics planners leveraging language-derived MasterKeys.
- Assumptions/dependencies: Layer alignment across differing architectures/modalities; validation in embodied settings; safety constraints in real-world control.
- Hardware and serving-path optimization for steering (semiconductors, cloud)
- What: Accelerator support for per-layer vector injection (e.g., low-overhead residual-stream modifiers) and KV-cache–friendly implementations.
- Tools/products: Kernel-level fused ops for normalized vector addition; compiler passes to pre-bake transformations.
- Assumptions/dependencies: Vendor adoption; measurable latency/throughput wins to justify silicon or runtime changes.
- Governance and auditing for portable capabilities (policy, compliance)
- What: Regimes for auditing capability transfer artifacts (e.g., ensuring a “reasoning key” doesn’t inadvertently unlock harmful skills); disclosure requirements in model cards.
- Tools/products: Capability risk assessments; standardized “capability provenance” and “scope of use” declarations; monitoring dashboards for live deployments.
- Assumptions/dependencies: Policy consensus on capability portability and associated risks; procedures for revocation/updates.
- IP and licensing frameworks for capabilities (legal, ecosystem)
- What: Clarify ownership and licensing of post-trained behaviors when shared as MasterKeys separate from weights.
- Tools/products: License templates for capability packs; attribution and revenue-sharing mechanisms for third-party capability providers.
- Assumptions/dependencies: Legal precedents for capability artifacts; enforceable distribution/control mechanisms.
- Personalized capability profiles (consumer AI, enterprise)
- What: User- or team-specific MasterKeys (tone, workflows, reasoning depth) applied on demand without retraining the base model.
- Tools/products: “Personal capability packs” managed like profiles; policy controls for safe sharing inside organizations.
- Assumptions/dependencies: Privacy and security controls for user-derived directions; mitigation of bias amplification.
- Auto-discovery and diagnosis of capability subspaces (academia, tooling)
- What: Automated methods to discover, categorize, and score low-dimensional capability directions; use for debugging, interpretability, and curriculum design.
- Tools/products: Capability explorers and dashboards; tests for atomic vs non-atomic behaviors; subspace similarity maps across families.
- Assumptions/dependencies: Robust, model-agnostic metrics; reproducibility across seeds, datasets, and architectures.
- Safer open release of base models with separable capabilities (open-source, policy)
- What: Ship base weights plus community-reviewed capability packs separately, enabling safer, incremental activation of advanced behaviors.
- Tools/products: Staged-release pipelines; gating layers that enforce policy constraints on when and how to activate keys.
- Assumptions/dependencies: Community governance; effective technical and policy controls to prevent misuse of harmful capability keys.
Glossary
- Activation shift: The change in neuron activations needed to move a model from one behavioral mode to another. "This vector represents the activation shift required to move the Locked model towards the Unlocked behavior"
- AGIEval Math: A benchmark subset assessing mathematical reasoning ability. "AGIEval Math accuracy from 61.1\% to 71.3\%"
- Atomic capability: A behavior already present in a base model that post-training does not substantially improve. "we say that ψ is an atomic capability"
- Capability direction: A vector in representation space that, when applied, elicits a specific behavior. "extracts a capability direction"
- Capability transfer: Moving a learned behavior from one model or setting to another. "Existing methods for capability transfer can be decomposed into two steps"
- Chain-of-Thought (CoT): A prompting or internal reasoning style that encourages step-by-step solutions. "including Chain-of-Thought (CoT) and mathematical reasoning"
- Cross-model Subspace Alignment: The process of mapping directions between different models’ representation subspaces. "Cross-model Subspace Alignment"
- Distribution-sharpening mechanism: A process that concentrates probability mass on a narrower set of likely-correct outputs without adding new knowledge. "act as a distribution-sharpening mechanism that pushes the base model towards narrow yet correct output trajectories"
- Final-token hidden state: The internal representation at a particular layer corresponding to the last token in the sequence. "denote the final-token hidden state at layer l"
- Frobenius norm: A matrix norm used to measure the difference between matrices, computed as the square root of the sum of squared entries. "minimizing the Frobenius norm loss"
- Inference-time intervention: A modification applied to model activations during generation to steer behavior. "apply the transferred direction as a normalized inference-time intervention"
- Instruction-tuned: A model variant fine-tuned on instruction-following data. "the 14B instruction-tuned model"
- Latent geometry: The structure and relationships within a model’s internal representation space. "may have a different hidden size and latent geometry"
- Latent subspace: A lower-dimensional region of representation space capturing important factors or capabilities. "directions in a low-dimensional latent subspace"
- Linear Subspace Alignment: Aligning capabilities across models by linearly mapping between their subspaces. "via Linear Subspace Alignment"
- Logit difference: The difference between two models’ pre-softmax output vectors, used to adjust outputs. "The logit difference between two Source variants is applied at each generation step"
- Low-rank linear transformation: A linear map constrained to a small effective dimension, used for efficient alignment. "estimate a low-rank linear transformation"
- Low-rank subspaces: Lower-dimensional spaces capturing dominant structure in high-dimensional representations. "align low-rank subspaces"
- Master Key Hypothesis: The claim that capabilities are directions in a shared low-dimensional subspace and are transferable via linear mappings. "The Master Key Hypothesis"
- MasterKey: The specific capability-inducing direction extracted from a source model’s activations. "extract a MasterKey --- a capability direction in a Source model's representation space"
- Mid-training: An intermediate training phase between pre-training and post-training used to introduce targeted behaviors. "creating an additional mid-training regime"
- Moore--Penrose pseudoinverse: A generalized matrix inverse used to compute least-squares solutions. "the Moore--Penrose pseudoinverse"
- Output distribution: The probability distribution over tokens produced by the model at each step. "sharpens the output distribution"
- Output-space transfer: Adjusting a target model’s logits directly using differences derived from a source. "Output-space transfer"
- Post-training: The alignment or fine-tuning stage after pre-training to instill desired behaviors. "post-training methods such as reinforcement learning with verifiable rewards (RLVR)"
- Pre-training: The initial large-scale training phase to learn general language patterns and knowledge. "Training modern LLMs involves two stages: pre-training, which instills general linguistic structure"
- Principal component: A direction of maximal variance used to summarize data, often computed by PCA. "the first principal component"
- Reinforcement learning with verifiable rewards (RLVR): A post-training approach that optimizes behaviors using rewards that can be checked for correctness. "post-training methods such as reinforcement learning with verifiable rewards (RLVR)"
- Representation-space transfer: Steering a model by intervening on internal activations rather than weights or outputs. "Representation-space transfer"
- Residual stream: The main sequence of layer-wise representations in a transformer that carry information between blocks. "to the residual stream at every layer"
- Right singular vectors: The orthonormal basis vectors from SVD associated with feature dimensions. "retain the top- right singular vectors"
- Singular Value Decomposition (SVD): A matrix factorization used to extract dominant subspaces and structure. "we perform Singular Value Decomposition (SVD) on both matrices"
- Steering direction: A vector applied to hidden states to guide the model toward a behavior. "construct steering directions from labeled contrastive examples"
- Steering vector literature: Prior work focusing on deriving and applying activation directions to control model behavior. "the steering vector literature"
- Test-time intervention: Applying a modification during inference rather than changing model parameters. "as a test-time intervention"
- Tokenization: The process of splitting text into tokens used by the model, which must often match across models for some methods. "requires identical tokenization between the source and target"
- Weight-space transfer: Adding parameter differences from a source fine-tuned model to a target model. "Weight-space transfer"
Collections
Sign up for free to add this paper to one or more collections.