- The paper presents a multi-agent framework that enhances literature discovery and analysis through modular, deterministic pipelines.
- It integrates discovery and analysis pipelines using both offline and online sources, ensuring reproducibility and transparent state tracking.
- The framework achieves strong retrieval metrics and supports detailed knowledge graph generation, advancing human-AI collaborative research workflows.
Paper Circle: An Open-source Multi-agent Research Discovery and Analysis Framework
Motivation and Positioning
The exponential increase in scientific literature poses significant challenges in discovery, synthesis, and critical evaluation. Paper Circle (2604.06170) proposes a multi-agent, open-source framework to efficiently support the entire literature engagement lifecycle—from discovery to analysis and synthesis—via an integrated, modular platform. In explicit contrast to prior fully autonomous “AI scientist” systems, Paper Circle adopts a collaborative, researcher-augmenting design paradigm, emphasizing transparency, reproducibility, and traceability for human-in-the-loop scientific workflows.
System Architecture
The architecture comprises two main pipelines: an agentic Discovery Pipeline and an Analysis Pipeline, unified through a modular orchestration backplane.
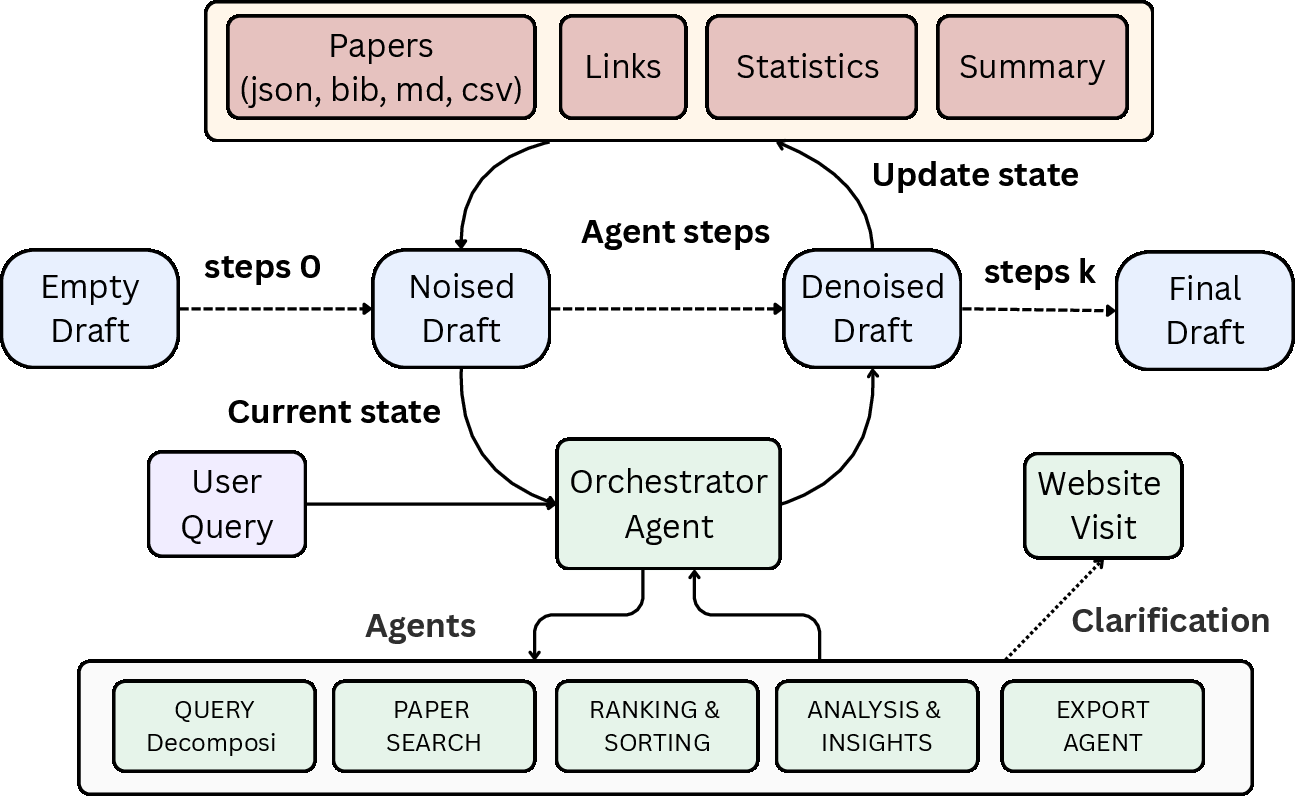
Figure 1: The iterative dynamics of the multi-agent discovery system, managing evolving paper sets and progressively refining results with orchestrated agentic steps, externalizing web retrieval as needed.
Discovery Pipeline
The discovery workflow encapsulates six agent types: intent classifier, search, sorting, analysis, export, and web search agents. This pipeline is deterministic, emitting JSON-serializable logs, state diffs, and reproducible multi-format outputs at each agentic step. Paper retrieval is orchestrated using both offline (local JSON-indexed corpora with BM25/sentence-transformer indexing) and online sources (arXiv, Semantic Scholar, OpenAlex, DBLP), with normalization, deduplication, and multi-criteria ranking (via BM25, recency, novelty, and semantic relevance). Result diversity is enforced using Maximal Marginal Relevance (MMR), and the scoring strategy is adjustable at inference time.
Paper Analysis Pipeline
The Analysis Pipeline centers on conversion of individual papers into structured, provenance-rich knowledge graphs. The extraction pipeline, orchestrated by a central agent, encompasses four sequential agentic routines: concept extraction, method/algorithm identification, experiment and dataset recovery, and visual element-linkage.
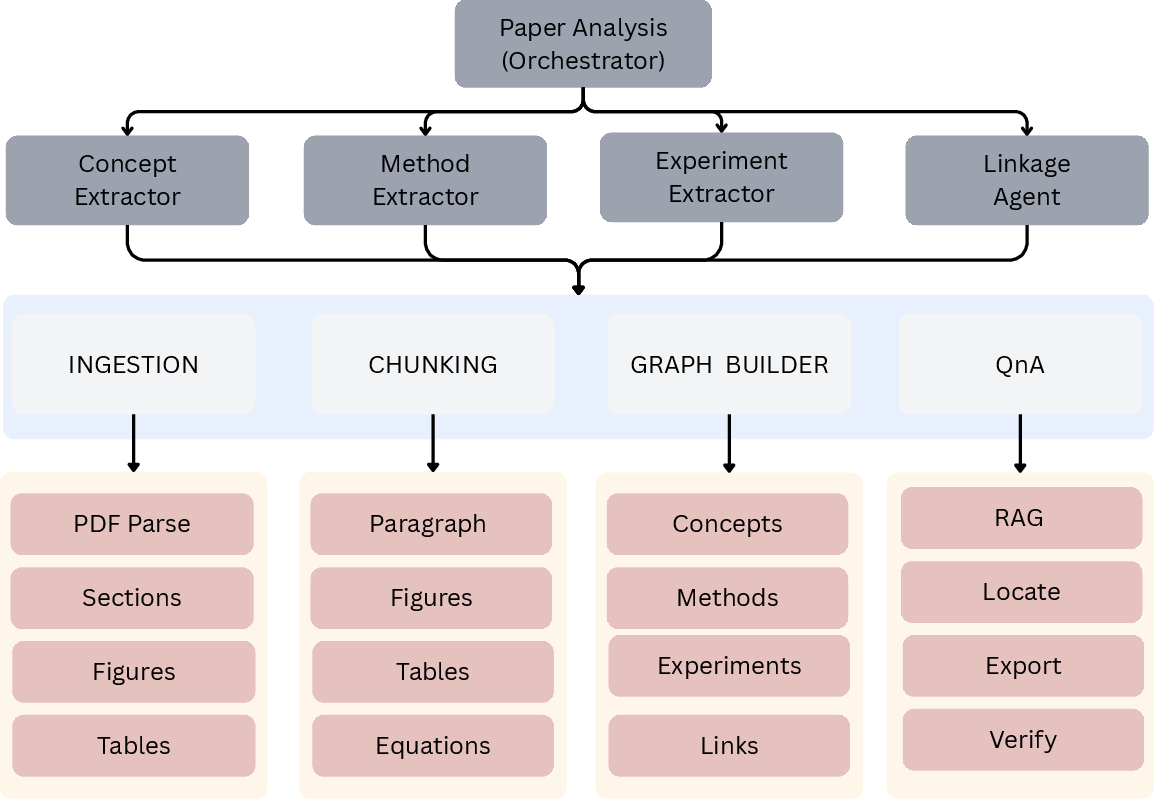
Figure 2: The multi-phase agent-driven analysis protocol, parsing PDFs into structured elements, semantic chunks, and ultimately into knowledge graphs enabling graph-aware verification and QA.
Outputs comprise typed, traceable nodes (e.g., concepts, methods, datasets, figures/tables/equations) and semantically grounded edge relationships. Fine control, provenance, and manual verification are supported through transparent logs and export affordances.
Multi-agent Review and Synthesis
Paper Circle further extends the agentic protocol to the review and critique of literature, deploying task-specialized agents for deep analysis, author claim extraction, baseline verification, and reproducibility checks. The orchestration layer supports parallel operation and process-level state synchronization, facilitating reviewer-style synthesis on each paper.
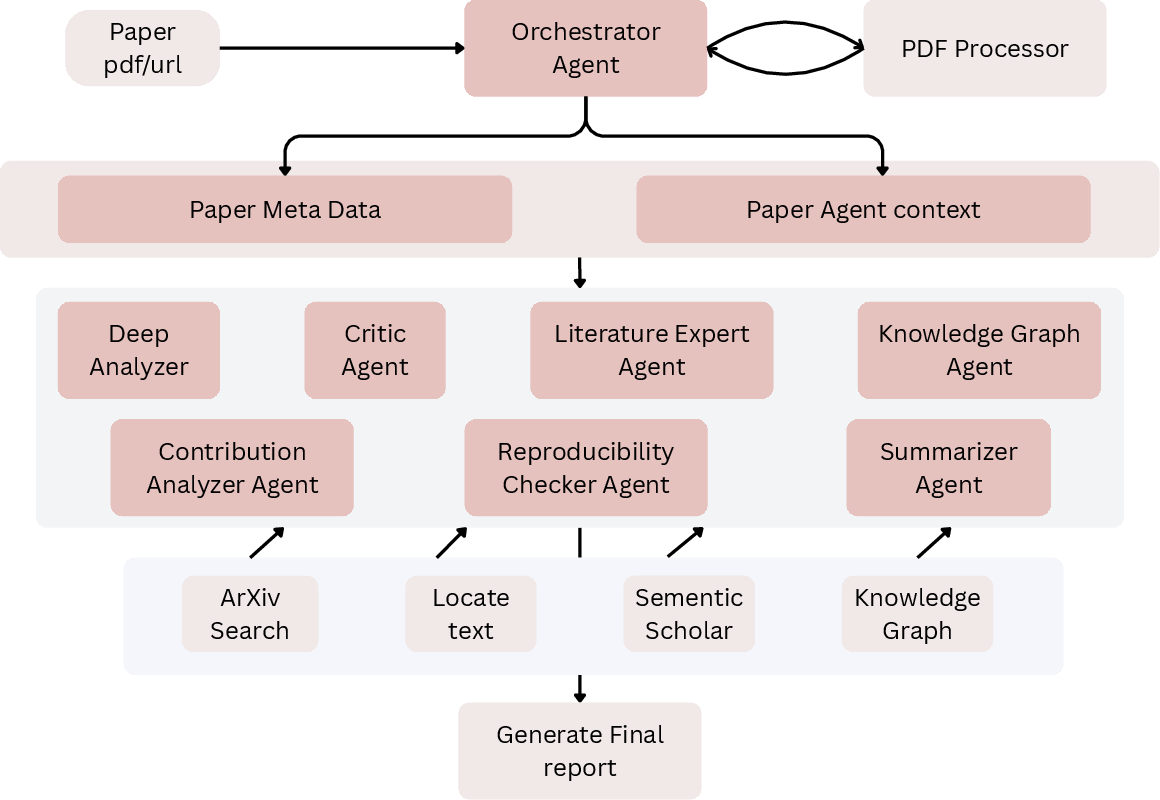
Figure 3: The coordinated multi-agent pipeline for reviewer-style analysis, enabling technical dissection, context mapping, baseline verification, and modifiable outputs.
The review agents generate artifacts such as multi-dimensional critiques, author query lists, and reproducibility scoring, analogous to peer review processes in contemporary academic venues.
Output Interfaces and Knowledge Graphs
Agentic outputs are materialized in synchronized, multi-format artifacts for downstream integration: JSON for graph data, Markdown summaries for notes and curation, BibTeX for citation management, and HTML dashboards for real-time analytics. Knowledge graphs enable graph-aware retrieval, structured QA, and automated coverage auditing.
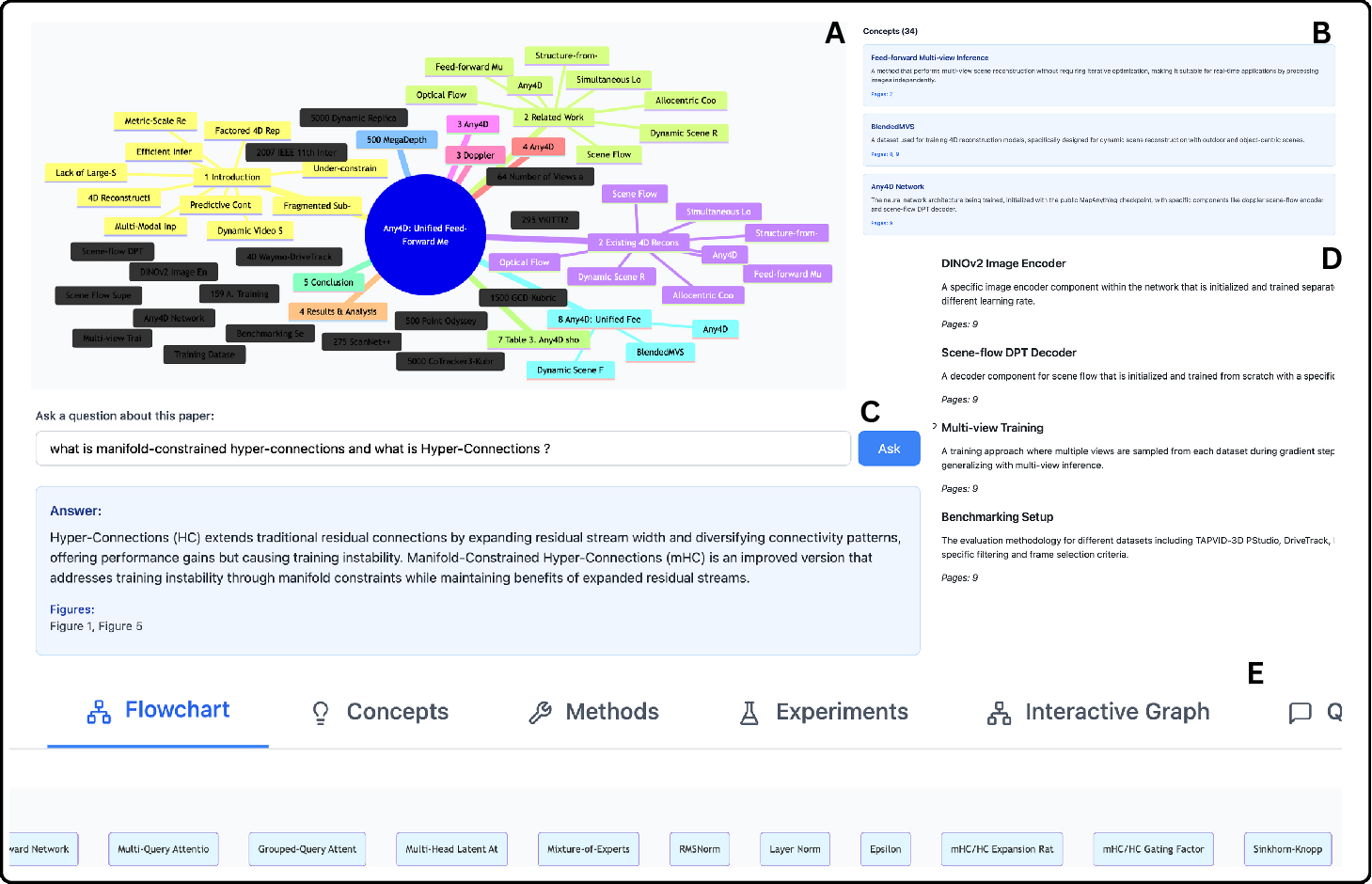
Figure 4: Primary analysis agent outputs—interactive concept graphs, detailed explanations, graph-aware QA, export in Markdown, and process flowcharts—supporting comprehensive downstream use.
Experimental Evaluation
Quantitative Retrieval
On a 50-query semantic benchmark, Paper Circle’s agent-based retrieval with the qwen3-coder-30b variant achieves state-of-the-art performance (Hit Rate: 0.80, MRR: 0.627, R@1: 0.58, R@5: 0.66) while maintaining low latency (≈22s per query) and outperforming or closely matching traditional BM25 baselines. In extended ablation, hit rates reach 0.98 and MRR 0.88 for the best full-pipeline, filtered setting over 500 queries. Lexical baselines (BM25, hybrid with reranking) remain competitive but cannot match the system’s coverage and graphification features.
Qualitative Discovery
In fielded research sessions (81 unique queries across 9 domains), the multi-source agentic approach results in a mean source coverage far exceeding single-source platforms (arXiv miss: 70.9%, Paper Circle miss: 9%), and allows domain-agnostic, diverse literature sets. User feedback indicates low cognitive load (NASA-TLX overall: 1.2/7), high learnability (8/10), and minimal barriers to productive use.
Agent-based Review Analysis
Performance on ICLR 2024 human review score prediction tasks highlights clear model dependence: large chat-oriented LLMs (gpt-oss:120B) attain best MAE (1.68, Contribution: 0.62), while code-oriented agents (Qwen3-coder-30b) yield higher regression error and poor relative ranking (correlations |r| < 0.25). This underscores current limitations in aligning LLM-based scoring with human subjective evaluation protocols.
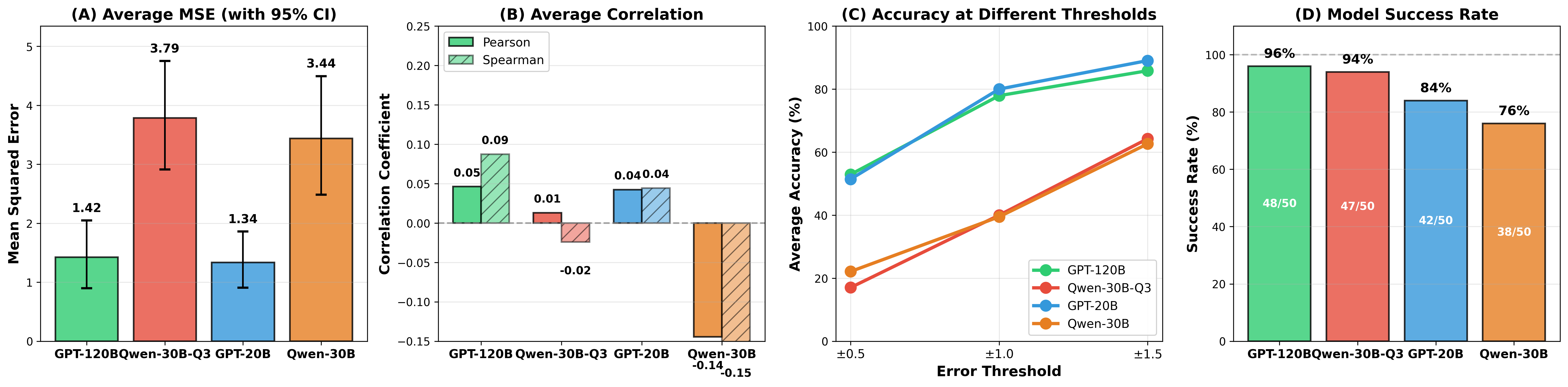
Figure 5: Score agreement between automated multi-agent review and human ratings, stratified by model size and specialization.
System Engineering and Database Management
Paper Circle is delivered as a full-stack Python backend and React/TypeScript frontend. Database and user/session state are managed on Supabase; offline and online retrieval pipelines are exposed via REST/JSON APIs for extensibility and reproducibility. Multi-format export and audit trails further support large-scale, longitudinal research workflows.
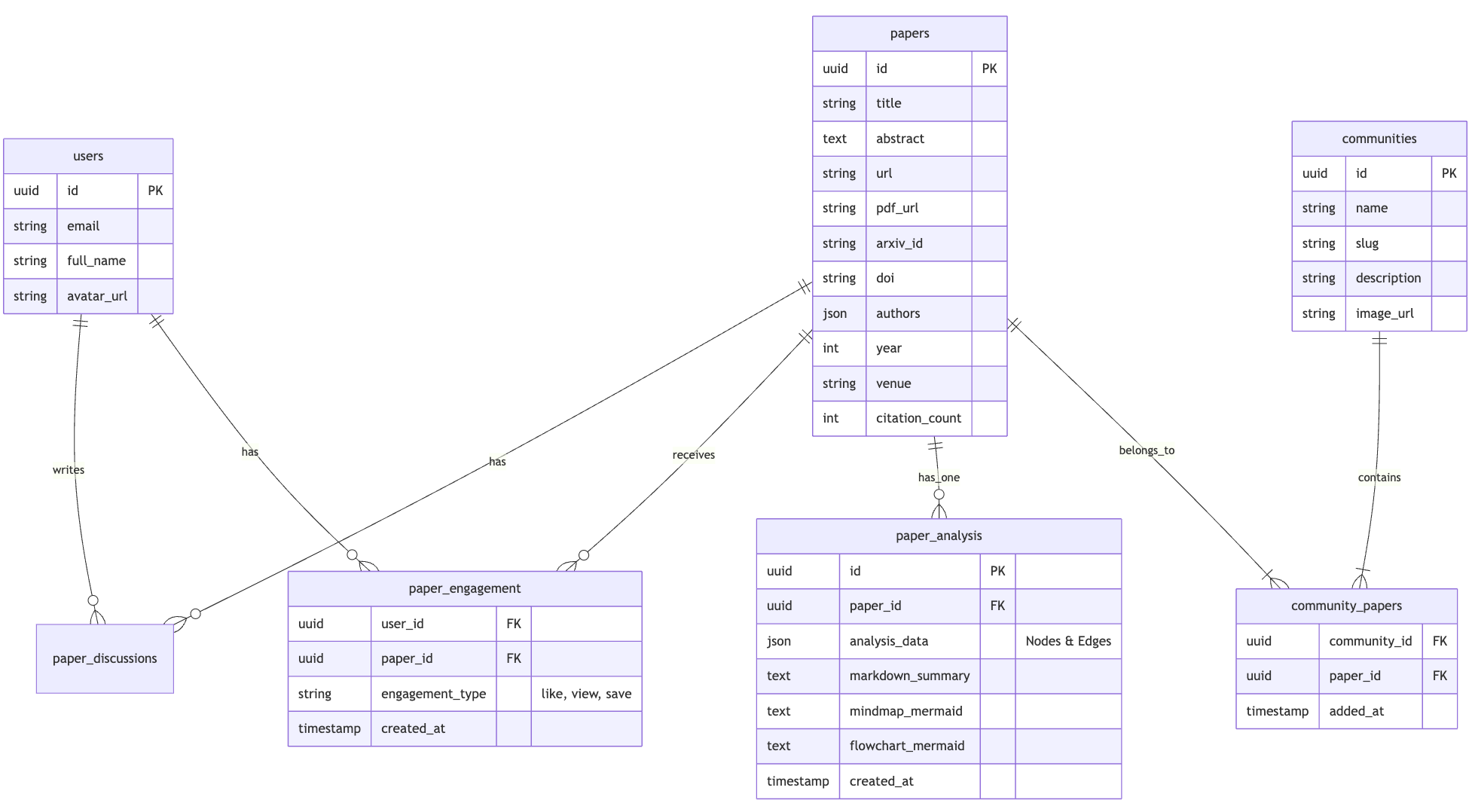
Figure 6: Backend architecture for synchronized analysis outputs, database management, and high-throughput inference.
Implications and Theoretical Impact
Paper Circle operationalizes the modular, agentic principles of LLM-based scientific discovery in a real-world, reproducible, and community-collaborative infrastructure. The explicit, evolving state tracking and provenance enforcement enable fine-grained human-AI feedback loops, transparent error analysis, and deterministic experiment reproducibility. The versatility for offline and massively multi-source online retrieval is crucial for domain-agnostic scalability—directly addressing deficits in coverage and explainability endemic to prior closed, monolithic recommender systems.
A notable theoretical advance is the graph-aware, provenance-preserving analysis pipeline. By integrating PDF chunking, typing, and cross-entity linkage, downstream Q&A and meta-analyses become traceable and modifiable—a prerequisite for advanced meta-scientific workflows, automated literature curation, and collaborative knowledge base construction.
Limitations and Future Work
Alignment between agent-generated reviews and human judgments remains weak, with low inter-rater reliability across scoring dimensions. Larger, more instruction-tuned LLMs somewhat mitigate this, but the problem persists due to the subjective and context-dependent nature of academic peer evaluation. The framework also depends on open APIs and PDF parseability; source completeness and extraction reliability can be bottlenecks. Future research directions include improved human-AI alignment for review, deeper integration of closed-source models, continual learning with community feedback, and agent-based logic for hypothesis-driven discovery and synthesis.
Conclusion
Paper Circle demonstrates the effectiveness of open, multi-agent architectures for research discovery, analysis, and review. The jointly orchestrated pipelines, traceable to source texts and augmented by reproducible, exportable artifacts, establish a new paradigm for AI-assisted scientific literature management. This modular, extensible foundation is poised for future integrations—potentially enabling broader meta-scientific inference, theory discovery, and collaborative knowledge evolution.

