- The paper introduces EEG-MFTNet, which combines multi-scale temporal convolutions and a Transformer encoder to address cross-session non-stationarity in motor imagery EEG decoding.
- The proposed model jointly captures frequency-specific and long-range temporal features through parallel branches while maintaining a lightweight architecture of only 16k parameters.
- EEG-MFTNet achieves a notable 58.9% average accuracy on the SHU dataset and employs gradient-based attribution to confirm neurophysiological relevance in its decision-making.
Introduction
This paper presents EEG-MFTNet, an end-to-end deep neural architecture for motor imagery (MI) EEG decoding, designed to address the persistent challenge of cross-session non-stationarity in BCI applications. EEG-MFTNet extends the foundational EEGNet model by integrating both multi-scale temporal convolutional processing and a parallel Transformer-based encoder, facilitating joint extraction of frequency-specific and long-range temporal features. The proposed methodology is rigorously evaluated on the SHU dataset with a subject-dependent cross-session protocol, yielding demonstrably improved classification accuracy over multiple EEGNet baselines, while maintaining computational efficiency suitable for real-time BCI deployment. Detailed interpretability analyses, including gradient-based attribution and channel deletion experiments, further elucidate the neurophysiological relevance of the model’s learned representations.
Figure 1: EEG-MFTNet’s architecture with annotated dimensions, illustrating the parallel multi-scale temporal convolution and Transformer branches, subsequent feature fusion, spatial processing, and dense classification head.
Recent years have seen substantial advances in MI EEG decoding through end-to-end deep learning, notably with architectures such as EEGNet and its derivatives, which leverage compact convolutions and reduced parameter counts for practical deployment. Despite these gains, the majority of methods remain sensitive to inter- and intra-subject variability due to their limited temporal modeling capacity, often capturing only short-range dependencies or requiring hand-engineered input representations. Noteworthy advances—such as incorporation of TCNs (EEG-TCNet, EEG-ITNet), inception modules (MI-EEGNet), and graph-based spatial modeling (EEG-GENet)—have incrementally improved accuracy, but at the cost of increased model complexity or loss of adaptability. Transformer-based designs, such as those in DS-GTF or AA-EEGNet for related tasks, suggest that attention mechanisms offer a compelling path forward for capturing long-range dependencies in nonstationary EEG, but have not been directly embedded in lightweight end-to-end pipelines for cross-session MI decoding.
Model Architecture
EEG-MFTNet processes single-trial, multi-channel EEG as X∈RC×T×1 (32 electrodes × 1000 time samples in SHU). The architecture consists of two parallel branches:
- Multi-Scale Temporal Convolutions: Six branches, each with a unique temporal kernel (k∈{5,9,13,29,61,125}), extract frequency- and scale-specific features, with outputs subsequently concatenated and adaptively scaled via learnable weights.
- Transformer Encoder Stream: Input is reshaped to RT×C, allowing each time step to be treated as a sequence token. A single Transformer encoder block (2 heads, dimension 32, GELU activation, dropout, residuals) learns cross-time dependencies. The output is mapped back to the original representation for fusion.
The outputs of both parallel streams are concatenated and normalized, followed by spatial modeling using a depthwise convolution across electrodes. Additional separable convolutions with average pooling and dropout further refine the fused representation before a dense, max-norm-constrained layer and softmax provide final class probabilities.
Experimental Protocol and Results
The SHU dataset supports rigorous cross-session evaluation, with model training on Session 1 (subject-wise, 20% validation split) and sessions 2–5 for testing. All baselines were retrained under consistent protocols for fair comparison. The proposed EEG-MFTNet attains an average accuracy of 58.9% (±10.5%), a +5.2% absolute margin over the original EEGNet (53.7%), and similarly outperforms AA-EEGNet (54.8%) and EEG-GENet (54.7%). Despite the inclusion of a Transformer module, EEG-MFTNet is parameter-efficient (16k trainable parameters, 49.6 ms/trial inference), representing a favorable trade-off between accuracy and compute cost, and substantially less resource-intensive than AA-EEGNet (517k parameters).
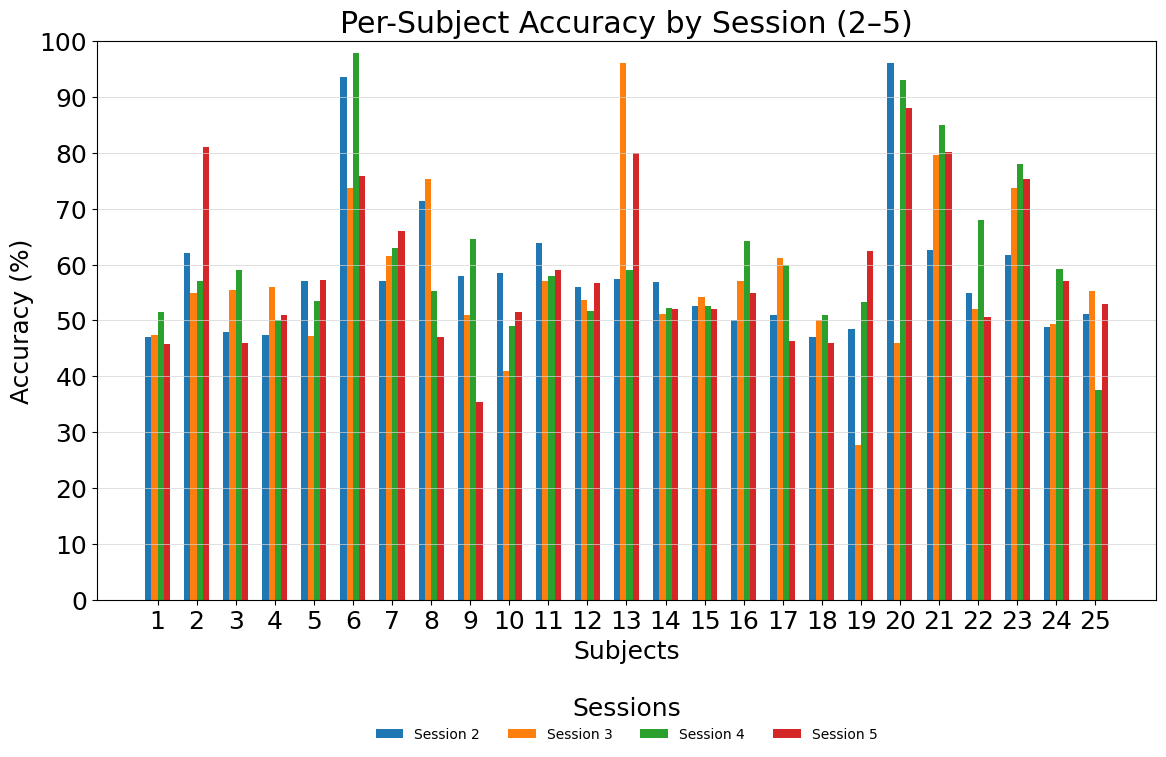
Figure 2: Subject-wise classification accuracy across four testing sessions, highlighting the considerable inter-subject variability and session-dependent effects.
Analysis of session-wise results reveals moderate variance, with especially high classification stability exhibited by certain subjects (notably, IDs 6 and 20 consistently achieving >90% accuracy), while others demonstrate marked cross-session fluctuations. This underscores outstanding challenges in MI-based BCI due to subject-specific and temporal nonstationarity that are not fully addressed even with improved modeling.
Ablation Study
Removal of the multi-scale temporal convolution block or Transformer encoder stream from EEG-MFTNet results in significant performance degradation: exclusive use of the multi-scale branch yields 55.2% accuracy, the Transformer branch 57.2%, while the full model achieves 58.9%. Both branches independently exceed vanilla EEGNet’s accuracy, verifying their complementary roles.
Interpretability Analyses
Attribution mapping with Gradient × Input identifies channel- and class-specific spatial signatures consistent with canonical MI neurophysiology: right-hand motor imagery is characterized by suppressed activity in midline and frontoparietal electrodes (e.g., Fz, F4, Cz), and enhanced activation posteriorly (e.g., PO3, Oz), with left-hand trials yielding opposing patterns.
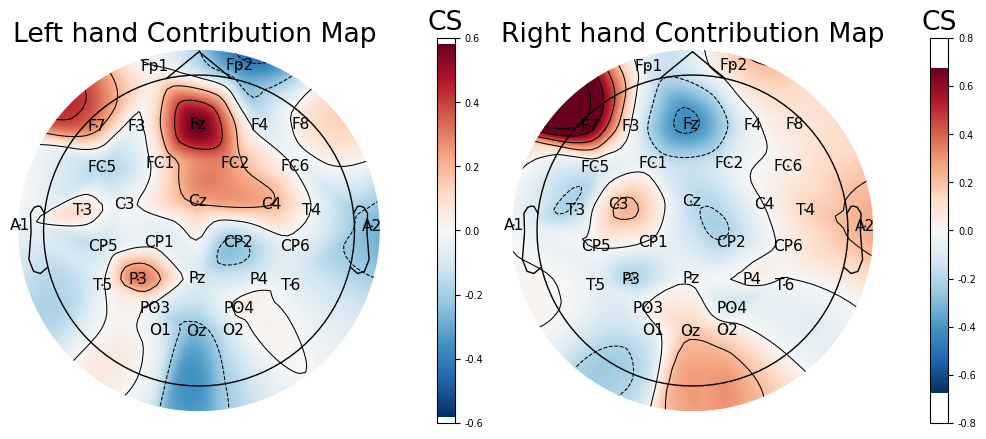
Figure 3: Topographic Gradient × Input contribution maps for Subject 6, Session 4, demonstrating clear class-specific spatial patterns aligned with MI representations.
Electrode deletion experiments, where channels are zeroed in order of attribution scores, demonstrate that elimination of highly ranked electrodes causes a steep decline in model confidence, while deletion of low-ranked channels produces minor effects. This supports the functional interpretability and neurophysiological validity of feature extraction in EEG-MFTNet.
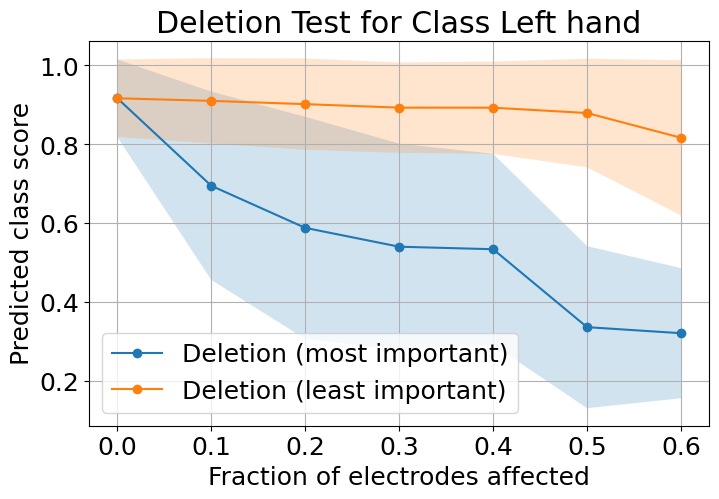
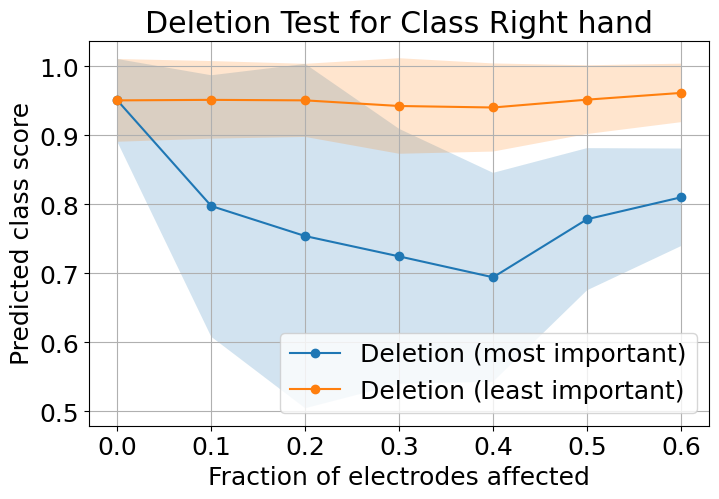
Figure 4: Average prediction confidence as a function of proportion of deleted electrodes, contrasting deletion of the most vs. least important channels as ranked by attribution methods across both MI classes.
Implications and Future Directions
The empirical results of EEG-MFTNet suggest that parallel multi-scale and Transformer branches are synergistic for robust feature learning in nonstationary MI-EEG, advancing the state of the art among lightweight models. The framework incurs only moderate complexity increases over EEGNet and its derivatives, supporting deployment in real-time or embedded BCI systems where low latency is critical.
Interpretability analyses verify that the learned representations emphasize neuroanatomically plausible electrode patterns, further motivating trust in these models for clinical or assistive applications. Nonetheless, subject and session-level variability persists, emphasizing the necessity of future research focusing on active adaptation, domain-invariant learning, and personalized calibration.
Open-sourcing of the EEG-MFTNet implementation addresses reproducibility gaps in the field and will catalyze further benchmarking and methodological refinement.
Conclusion
EEG-MFTNet achieves a substantial improvement in cross-session motor imagery EEG decoding by fusing multi-scale temporal convolutions and Transformer-based sequence modeling in an end-to-end architecture. Rigorous evaluation demonstrates improved accuracy and competitive latency/efficiency relative to both EEGNet and its strongest recent derivatives. Channel attribution and deletion analyses confirm neurophysiologically relevant decision-making. Future research may extend this blueprint with adaptation strategies and evaluation on more heterogeneous MI-EEG datasets.

