- The paper presents a database-inspired hybrid context engineering framework that structurally compresses machine data for effective LLM processing.
- It introduces dual row and column views along with SQL-based recovery methods to maintain complete data fidelity despite token truncation.
- Empirical results demonstrate token usage reductions of 50–90% and latency improvements up to 83%, significantly enhancing both numerical and relational reasoning.
HYVE: Hybrid Context Engineering for LLM Reasoning over Machine Data
Motivation and Core Challenges
Modern observability and troubleshooting pipelines in networking and systems operations are dominated by machine data—logs, metrics, telemetry records, and configuration snapshots. These inputs are structurally complex, often represented as interleaved natural language and large, deeply nested structured payloads (JSON, Python/AST literals). State-of-the-art LLMs, even with extended context windows, fail to robustly reason over such inputs due to three systemic bottlenecks: (1) token explosion from verbose, repetitive structure, (2) context rot from diluted task signals, and (3) poor quantitative and relational reasoning over long value sequences.
Conventional solutions—ad hoc serialization, fixed prompt truncation, or lossy summarization—either discard salient evidence or cannot guarantee the recoverability of omitted context. Consequently, existing approaches trade off fidelity or performance when reasoning over large machine-data payloads.
HYVE Architecture and Execution Model
To address these limitations, the paper proposes HYVE (HYbrid ViEw), a disciplined context engineering framework inspired by database systems. HYVE wraps an LLM invocation with preprocessing and postprocessing modules governed by a request-scoped in-memory datastore augmented with explicit schema.
The system executes as follows:
- The preprocessor parses the raw input (opaque strings potentially containing malformed or embedded JSON or AST literals), robustly detects repetitive patterns and schema-consistent regions, and materializes these into a hybrid columnar and row-oriented view. Only the statistically or contextually relevant subsets are exposed to the LLM; all omitted segments are retained losslessly in an isolated relational datastore.
- The postprocessor inspects the model's output, recognizes when the visible context is insufficient (typically due to truncation), and coordinates either deterministic template backfilling (Mode 2) or bounded SQL-augmented synthesis (Mode 3). The recovery interface is constructed automatically per request, exposing live table schemas and tool-call contracts to the LLM.
The architecture is depicted in Figure 1.
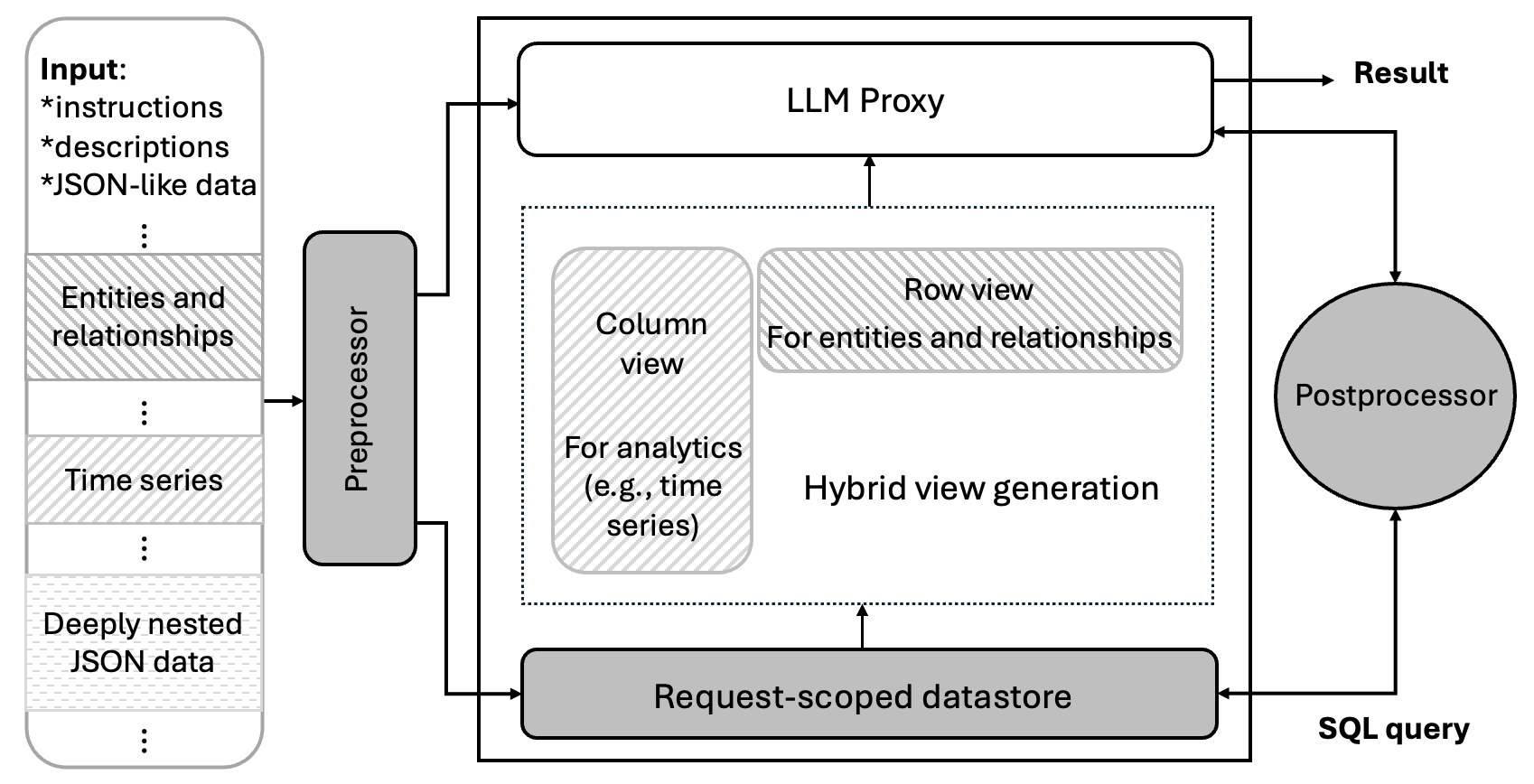
Figure 1: The HYVE system architecture—context parsing, hybrid-view construction, datastore retention, and LLM result postprocessing.
Hybrid Representation: Row and Column Views
The core architectural novelty is the dual transformation of raw input into both column and row-oriented representations:
- Column View: Groups schema-consistent scalar fields across repetitive structures, providing LLMs with contiguous value sequences for numerical analysis or aggregation.
- Row View: Maintains entity- and record-level correlations, preserving the joint field structure necessary for entity-centric retrieval and relational queries.
The layout of the resulting hybrid view is outlined in Figure 2.
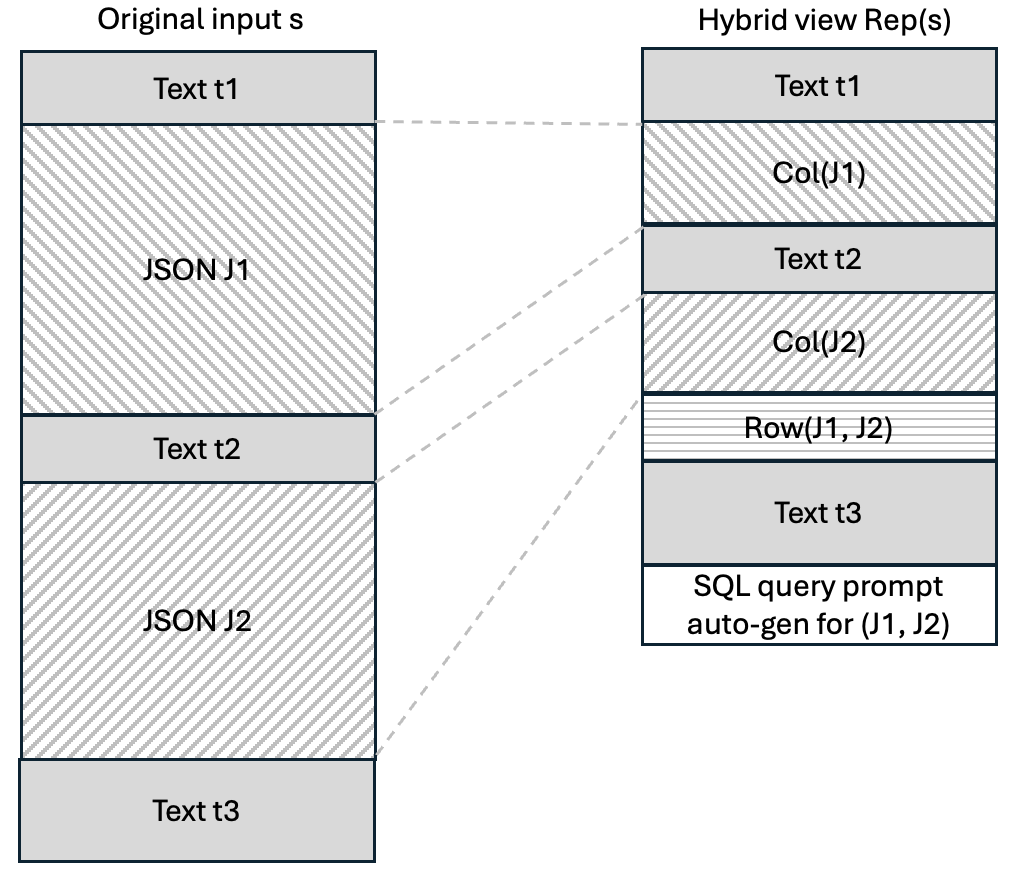
Figure 2: Schematic of the hybrid representation Rep(s)—column and row extraction, coupled with schema-aware truncation and SQL query prompt injection.
Omitted portions, when necessary for downstream synthesis, are referenced via schema-exposing metadata and recovered through automatic SQL generation over the datastore.
Automatic Truncation, Ranking, and Recovery
Table truncation is not a naive prefix cutoff. For both columnar and row views, HYVE selects visible entries via a reference-aware BM25-style ranking function using the request context as a query string. This ensures the highest-probability task-relevant entries are surfaced, minimizing interface-level LLM recovery.
When omissions do occur (e.g., sequences exceeding prompt budgets), HYVE dynamically injects tool-call prompts that reveal the available relational schema, sample SQL queries/few-shot completions, and guides the LLM to output either SQL queries for direct synthesis (Mode 3) or intermediate JSON templates for template-based data restoration (Mode 2). The postprocessor deterministically executes the SQL or fills in the output template using the hidden machine data.
Implementation: Robust Parsing and Lightweight Datastore
The preprocessing pipeline leverages robust multi-stage parsing (handling malformed JSON, embedded Python literals, and stringified nested structures) and precise schema alignment/consistency checks to generate accurate hybrid views and relational tables. Large repetitive segments are promoted to dedicated tables with parent-child foreign keys, enabling high-recall SQL-based evidence recovery.
An in-memory DuckDB instance is allocated per request, supporting expressive SQL queries, custom time-series summarization, and anomaly detection operators directly on the retained data. The entire context engineering pipeline is LLM-provider-agnostic and can be used with OpenAI, Anthropic, or fine-tuned domain-specific models.
Empirical Results
Across diverse networking and analytics benchmarks—spanning slot filling, anomaly detection, large-scale QA, chart generation, and complex multi-hop reasoning—HYVE demonstrates consistent and substantial improvements in both efficiency and quality.
Token Reduction and Latency: On datasets with significant machine data payloads, HYVE reduces token usage by 50–90% versus vanilla GPT-4.1/5 pipelines. Latency falls in proportion, with up to 83% reduction for structured generation tasks. Representative distributions for slot-filling and time series chart generation are shown in Figures 2 and 3, respectively.
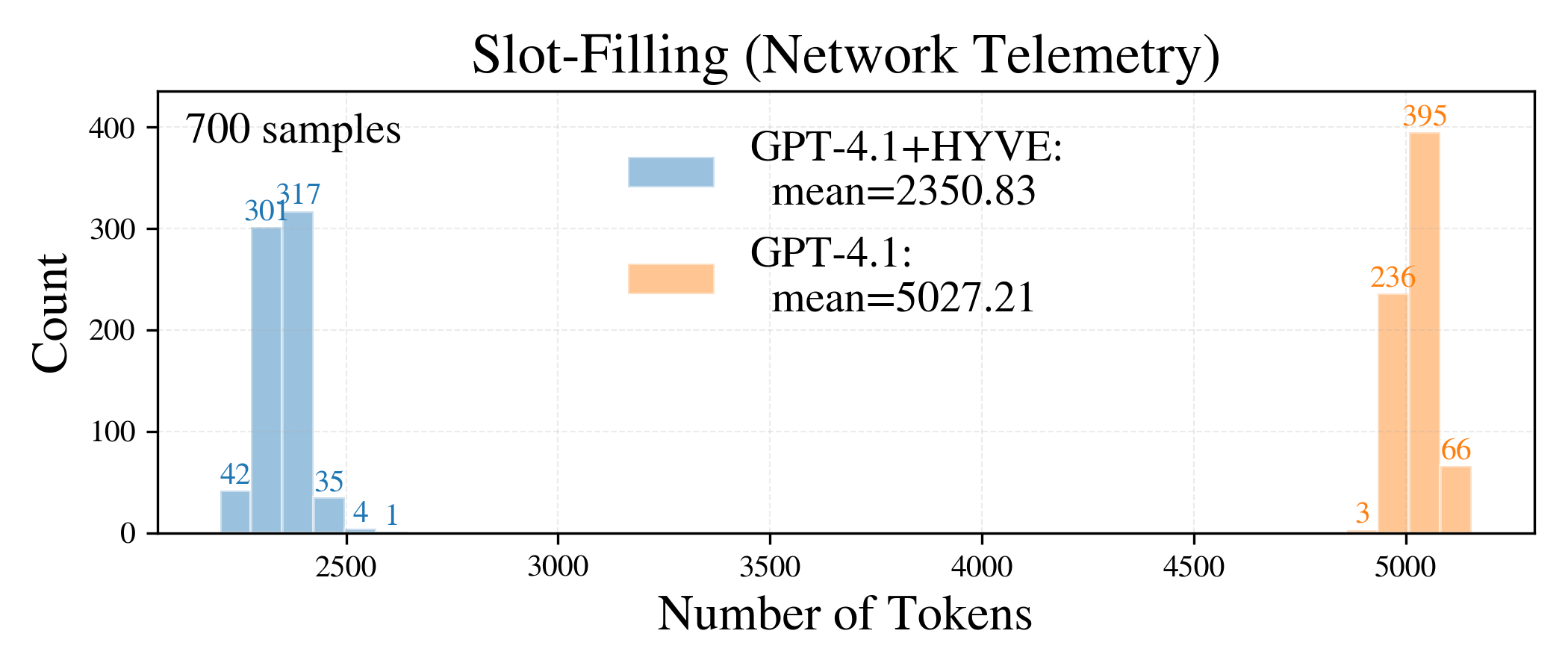
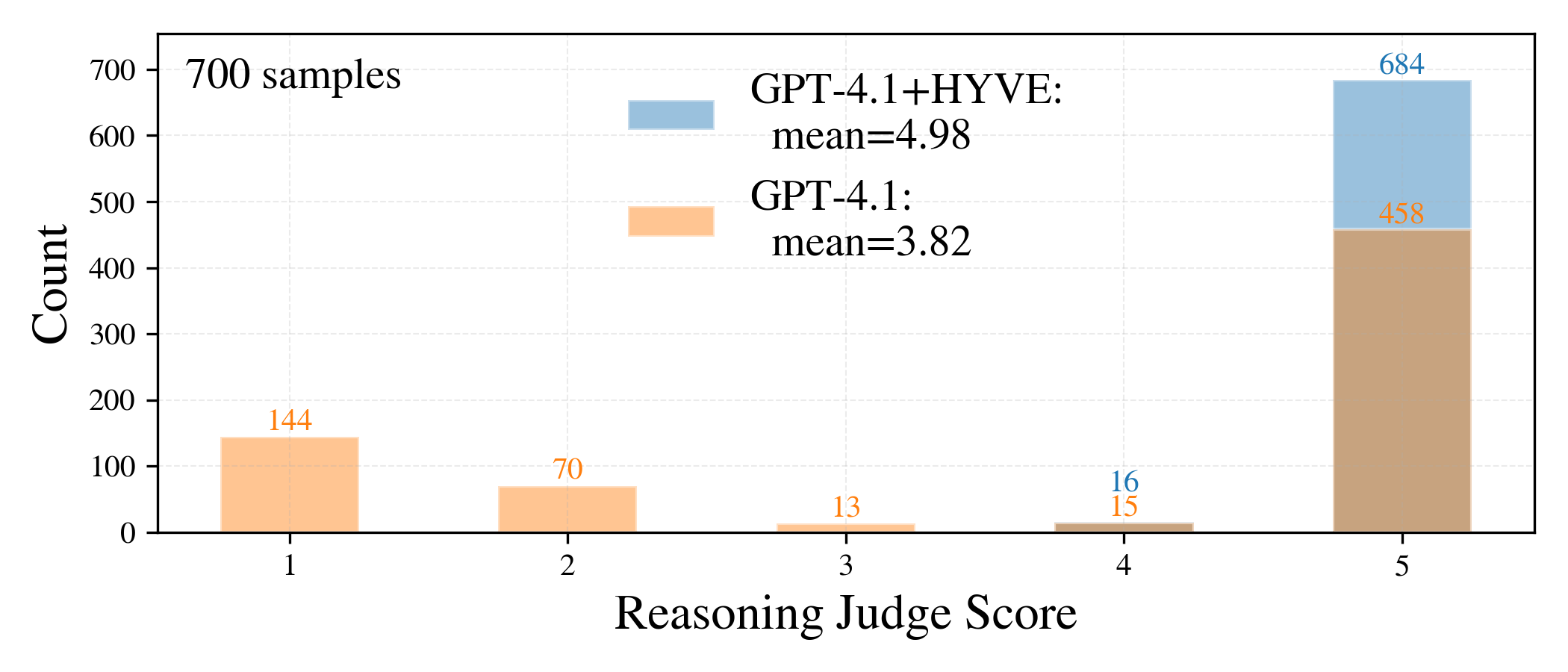
Figure 3: Token use and success rate on slot-filling tasks—HYVE cuts token consumption by 53% and eliminates failure cases.
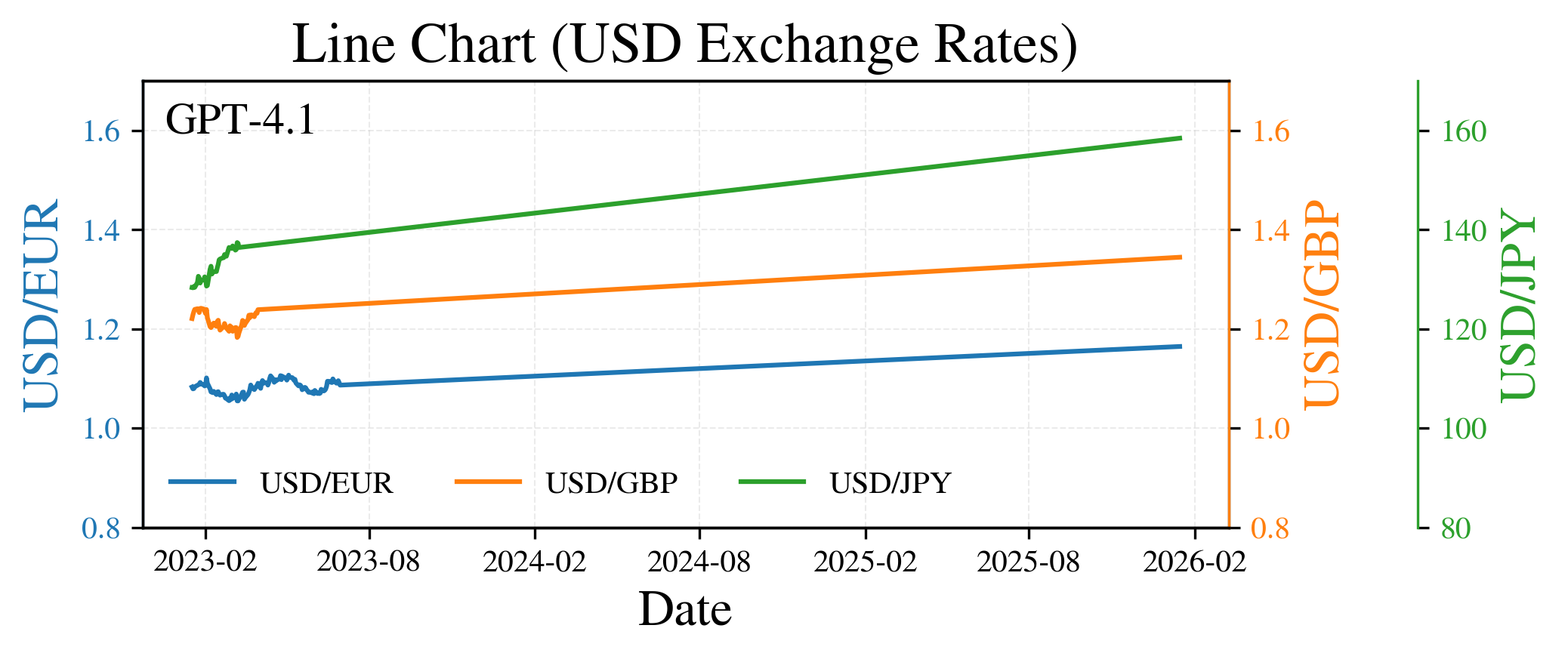
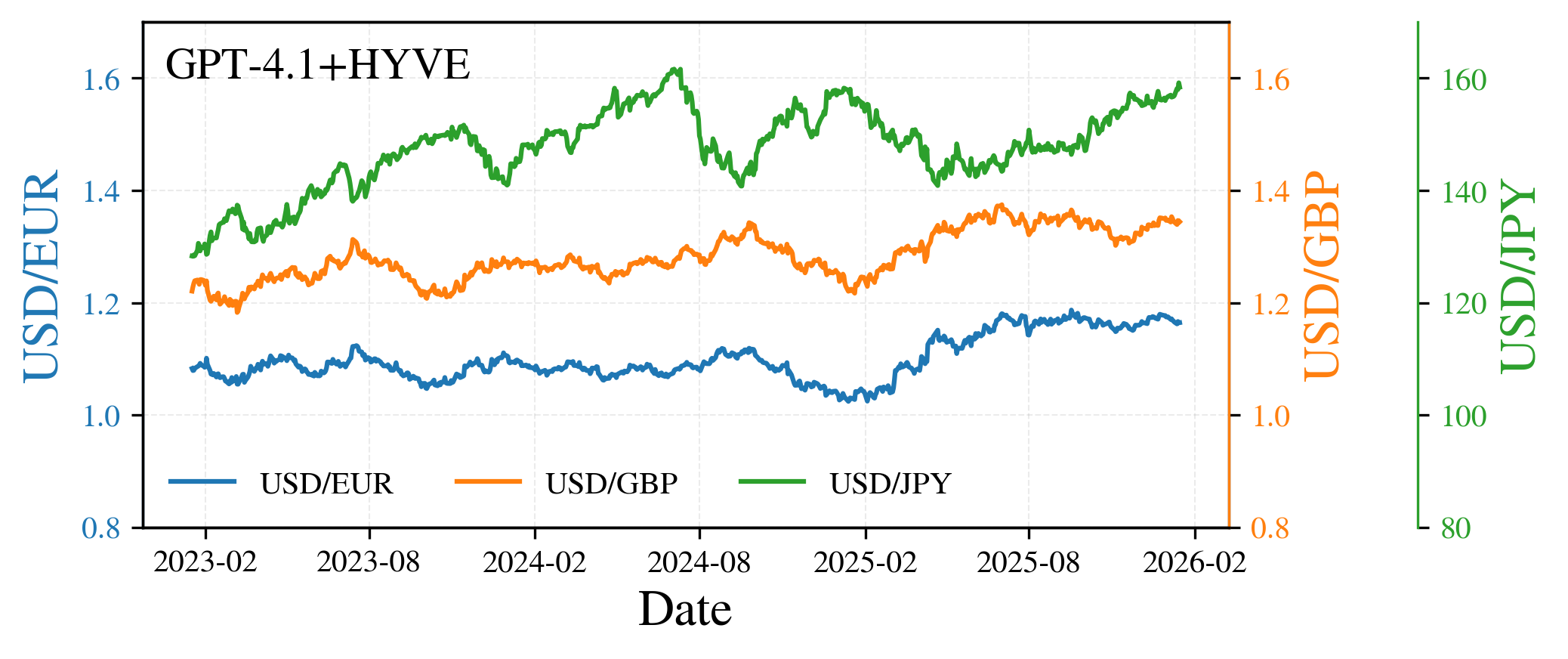
Figure 4: Recovery of complete multiyear time series—HYVE reconstructs all 778 points while baseline GPT-4.1 truncates to 40–120.
Quality: On chart tasks, HYVE lifts data fidelity (similarity scores) by up to 132%; on range-query structured QA (TOON-QA), it raises exact-match accuracy from 0.47 to 0.93 with GPT-4.1. For anomaly detection and multi-hop reasoning, reasoning quality (as measured by LLM-as-judge or field-by-field metrics) improves by up to 23% in the most challenging settings.
Data Fidelity: HYVE guarantees that omitted context is never lost, only hidden from the visible prompt—recoverable on demand via SQL or template generation. This contrasts sharply with lossy summarization-based prompt compression.
Component Ablations: Disabling postprocessing ruins chart accuracy (0.99 → 0.06 similarity) and halves TOON-QA accuracy (0.93 → 0.38), underscoring the criticality of bounded SQL-augmented reasoning. Truncation and ranking bring additional token/latency savings with minimal effect on quality for appropriately chosen thresholds.
Distributional analysis over per-sample metrics is illustrated in Figures 5 and 6 for chart generation and anomaly detection, respectively.
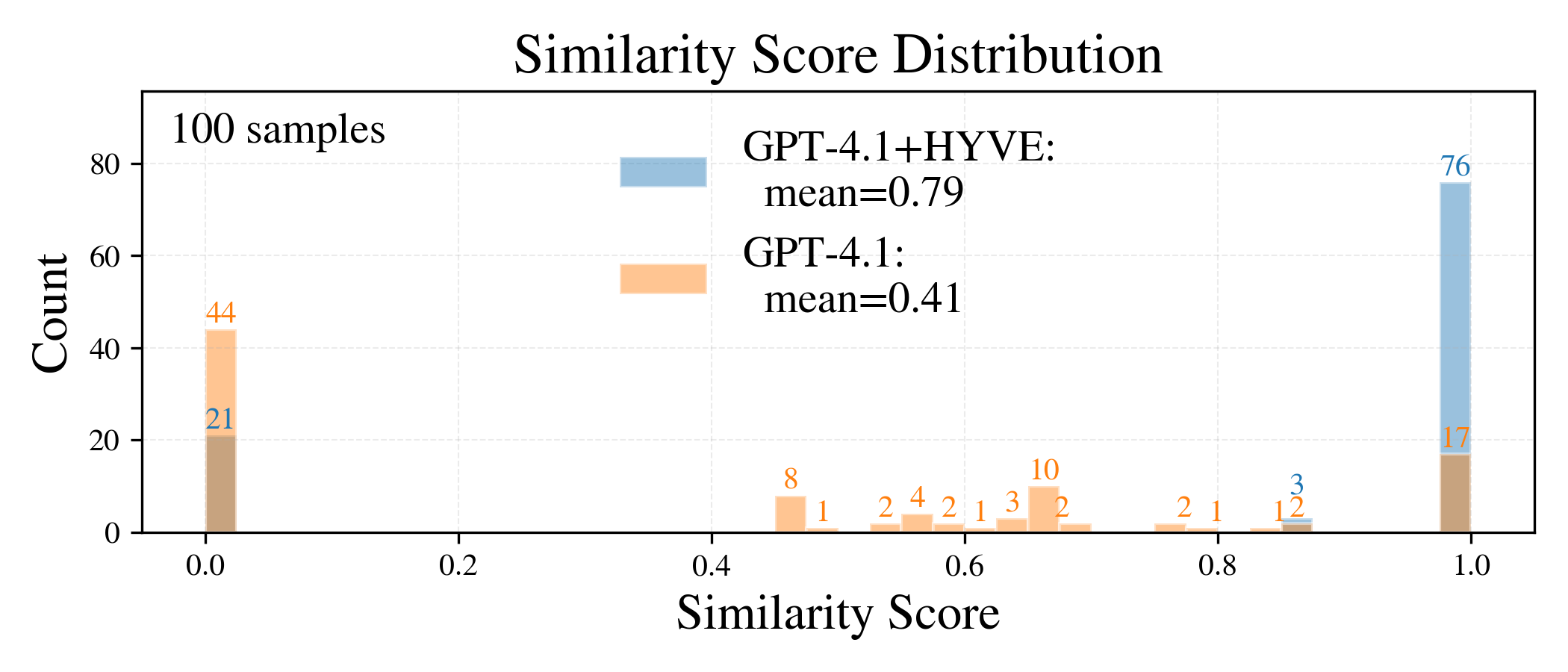
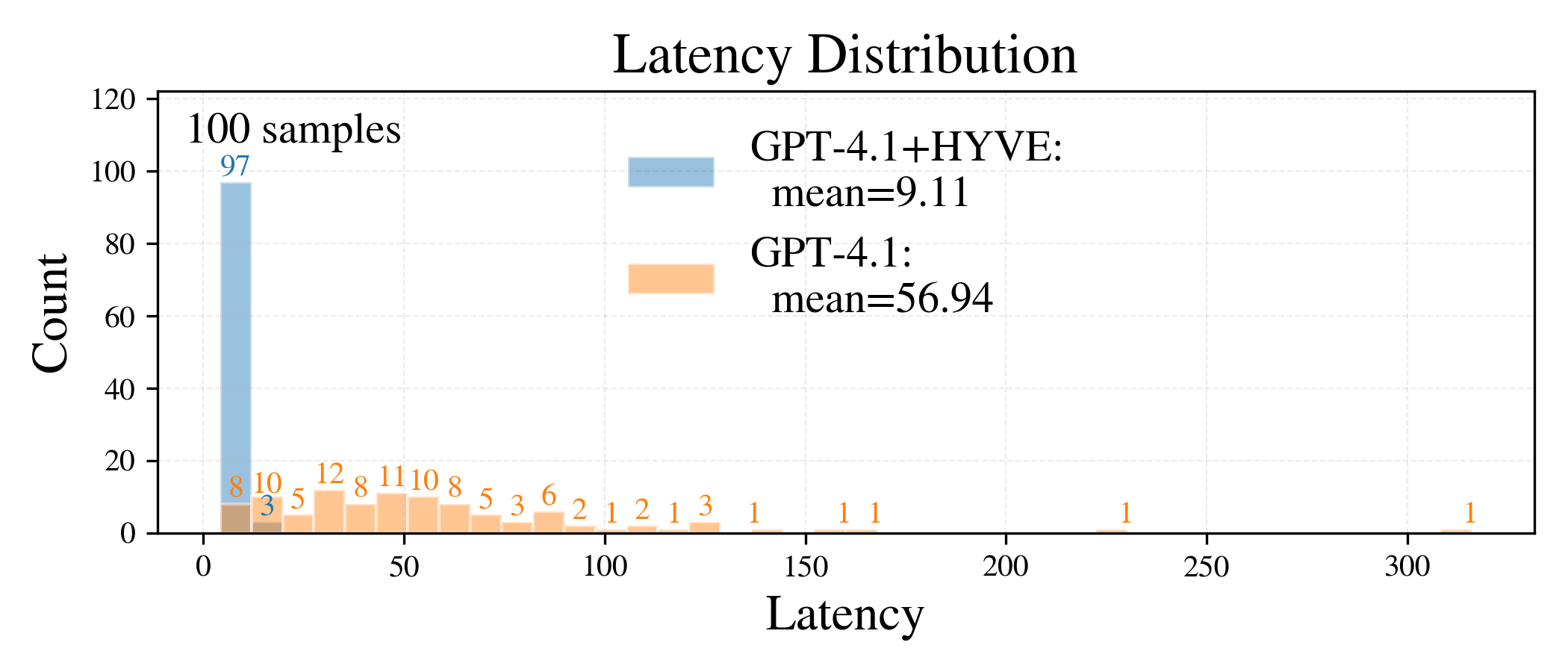
Figure 5: Per-sample similarity and latency—76% perfect similarity with median latency 8.9s post-HYVE transformation.
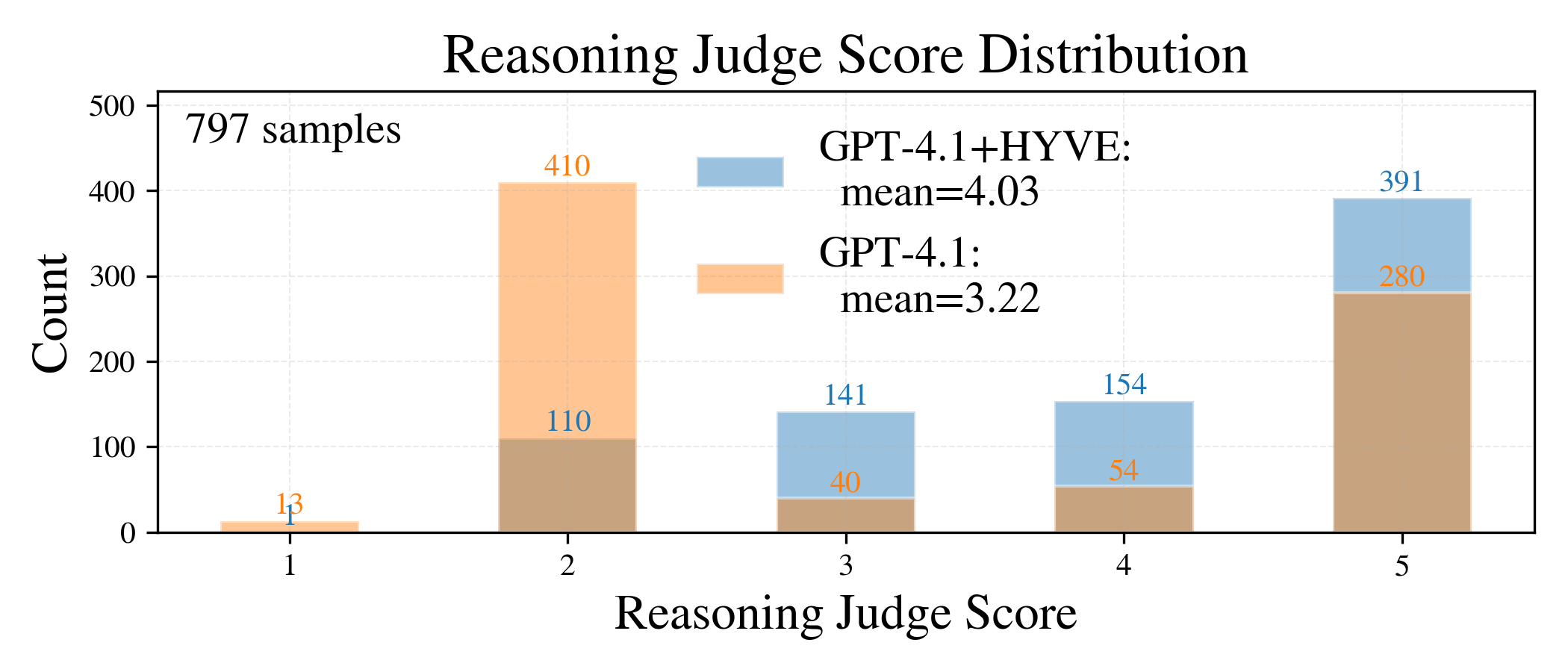
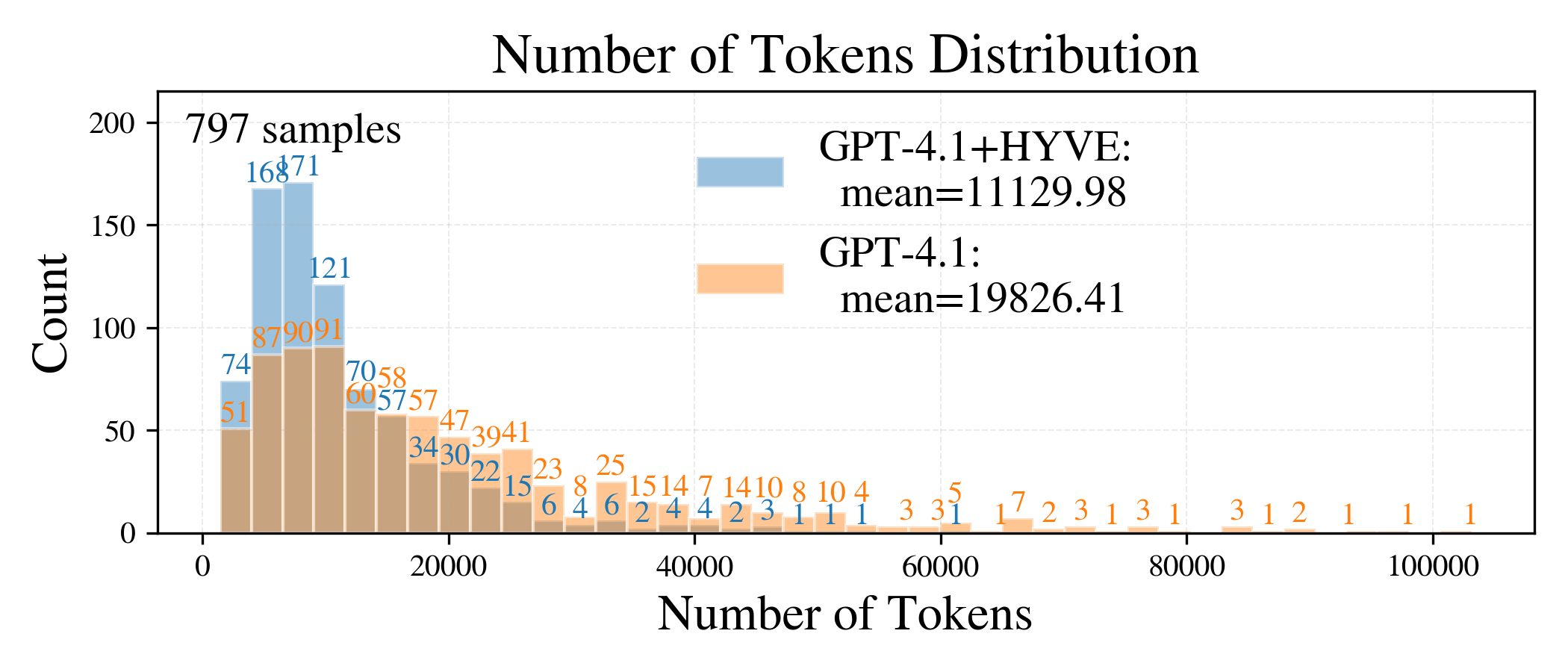
Figure 6: Anomaly detection quality/efficiency—higher reasoning scores and lower token usage using HYVE's anomaly summarization operator.
HYVE occupies a unique space relative to prior art. Unlike table-specialized models (TAPAS, TaBERT, DATER), it requires no pre-existing tabular structure. Unlike prompt compression (LLMLingua, LongLLMLingua, Selective Context), compression is structurally recoverable (i.e., all dropped data are reconstructable via SQL/datastore). Unlike memory-based agent frameworks (OpenClaw, Claude Code), HYVE is strictly short-term/request-scoped but ensures within-request completeness. The architecture is directly inspired by hybrid OLAP/OLTP systems (C-store, TiDB, F1 Lightning): analytical views for machine data are synthesized on the fly, and workload alignment is performed per request.
Limitations and Future Directions
HYVE intentionally provides only short-term session memory; inter-request or session-level memory must be layered with external retrieval or memory architectures (e.g., LongMem, MemGPT, Mem0). The approach assumes structured payloads are extractable—extensions to semi-structured logs or mixed-content tasks are plausible but not implemented. For maximum performance, LLMs should be post-trained or fine-tuned to exploit HYVE-style representations, as observed in domain-adaptive settings (e.g., Cisco DNM + HYVE).
Implications and Outlook
The decoupling of data structure from visible prompt, coupled with deterministic, schema-driven context engineering, represents a robust pathway to deployable LLM analytics in machine-data-heavy domains. HYVE enables practical, bounded-computation LLMification of monitoring, diagnostics, and automated reasoning—domains previously inaccessible to general-purpose transformers due to token and context window constraints.
In deployed contexts, HYVE is an operational bridge from raw system telemetry to scalable, low-latency, high-precision LLM-powered analytics with guaranteed fidelity and bounded resource use. Its principles are well-aligned with ongoing trends in hybrid reasoning (mixing statistical models and structured backends) and are likely to propagate into future system designs for LLM-based agents and analytics over structured, high-volume input domains.
Conclusion
HYVE demonstrates that database-inspired context engineering, combined with request-scoped delayed querying and hybrid view construction, effectively overcomes the traditional bottlenecks of LLM reasoning over large, repetitive, and structured machine data. By structurally compressing and retaining complete recoverability, HYVE achieves dramatic improvements in both efficiency and accuracy, and lays a disciplined foundation for practical, scalable LLM analytics in observability and automation.

