- The paper introduces NSGR, a tree-based generative reranking method that employs a hierarchical next-scale generator and multi-scale evaluator to optimize recommendation performance.
- The model leverages a multi-scale neighbor loss to ensure consistent generator-evaluator collaboration, achieving significant gains on Taobao and Meituan datasets.
- Deployment results show reduced latency and robust online improvements, setting a new benchmark for scalable, context-aware reranking in industrial recommendation systems.
Next-Scale Generative Reranking: A Tree-based Generative Rerank Method at Meituan
Background and Motivation
The transition in multi-stage industrial recommendation systems from conventional ranking architectures toward context-sensitive reranking is driven by the necessity to maximize global listwise utility. The complexity of this task arises from the factorial explosion of valid permutations as the candidate pool grows, making efficient and consistent optimization challenging. Prior research into generative reranking—both autoregressive and non-autoregressive—has focused on search heuristics, sequence modeling, and two-stage generator-evaluator frameworks, each exhibiting inherent limitations: suboptimal context modeling, inefficiency, and inconsistencies in generator-evaluator collaboration leading to degraded solution quality.
Next-Scale Generation Reranking (NSGR): Framework and Key Mechanisms
NSGR introduces a tree-structured next-scale generator (NSG) coupled with a multi-scale evaluator (MSE), explicitly designed to reconcile the imbalance between local and global context modeling. The NSG hierarchically partitions and refines the candidate space in a coarse-to-fine manner, ensuring that incremental list construction leverages both global user preference and fine-grained local interactions. The MSE provides contextually aware list evaluation signals at multiple decomposition levels, directly addressing the goal inconsistency problem endemic to prior works.
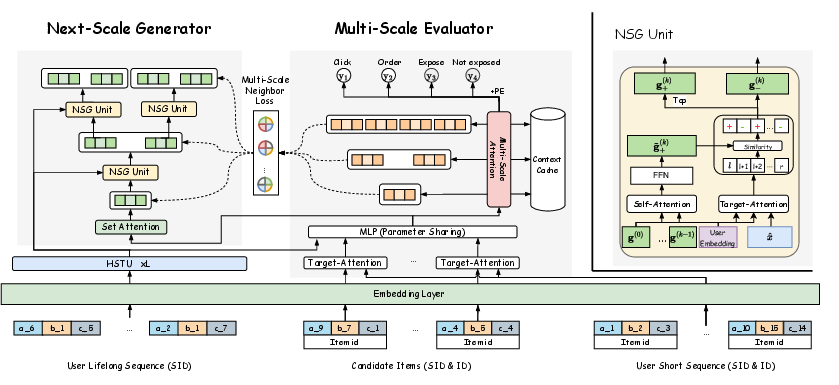
Figure 1: The overall architecture of NSGR.
The generative process proceeds recursively: at each tree level, subsets are formed and refined based on item priorities and contextually modulated pairwise relationships (competitive suppression, complementary enhancement, neutrality), realized via learned MLP-based interaction heads. Each partial list is recursively subdivided, and at every scale, score alignment with the MSE ensures progressive list refinement toward global optimality.
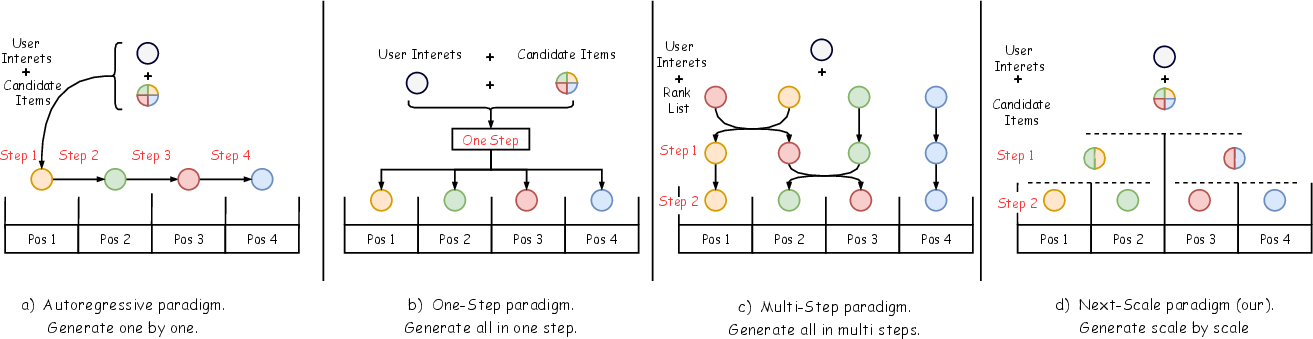
Figure 2: Demo of NSGR generation: for a length-4 list, positions are sequentially fixed from an initially entropy-maximized state of candidates.
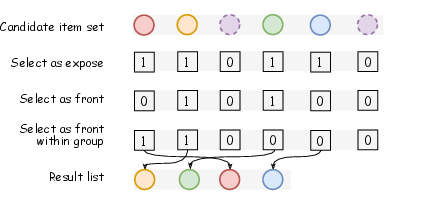
Figure 3: Next-scale generation process: how candidate subsets are recursively split and selected by NSG.
Multi-Scale Neighbor Loss and Generator-Evaluator Consistency
To address the gradient sparsity and the generator-evaluator goal inconsistency, NSGR defines a multi-scale neighbor loss (MSNL) that incorporates tree-structured neighbors at each generator partition node. The generator’s candidate partial lists are compared against perturbations (neighbors) both within and outside the generated subset, and the MSE evaluates all such alternatives. The MSNL then leverages the relative rewards across these neighbors to form dense guidance signals for generator parameter updates, facilitating gradient flow at each tree scale—not solely at the terminal full-list node.
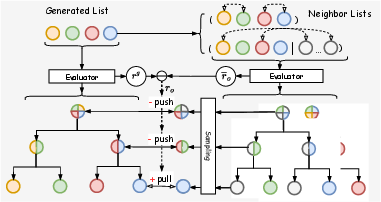
Figure 4: Multi-scale neighbor loss: guidance is provided at all tree scales via local list perturbations, maximizing informative signal for generator updates.
This explicit multi-scale objective and cross-scale vector sharing between the generator and evaluator (made possible by their structurally analogous hierarchical attention) both alleviates the local-global inconsistency and provides much denser supervision than sequence-level rewards utilized in earlier works such as NLGR.
Empirical Evaluation
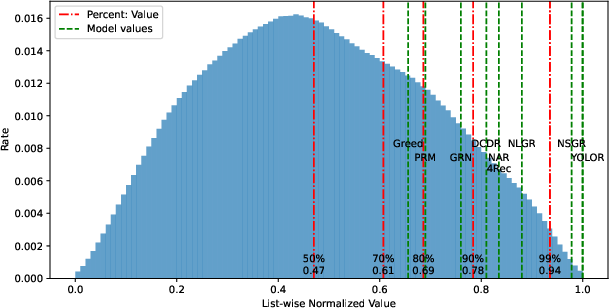
Extensive experiments on both the public Taobao Ad dataset and proprietary Meituan food delivery logs highlight the efficacy of NSGR:
Positional and Behavioral Analysis
A detailed analysis of the top-10 item position mappings confirms that NSGR’s rerankings, while exploiting the full candidate space, retain position inertia and the intuitive decaying utility of position with degree of displacement (distance-decay). This indicates the model’s robustness in preserving necessary list structure while generating global optima.
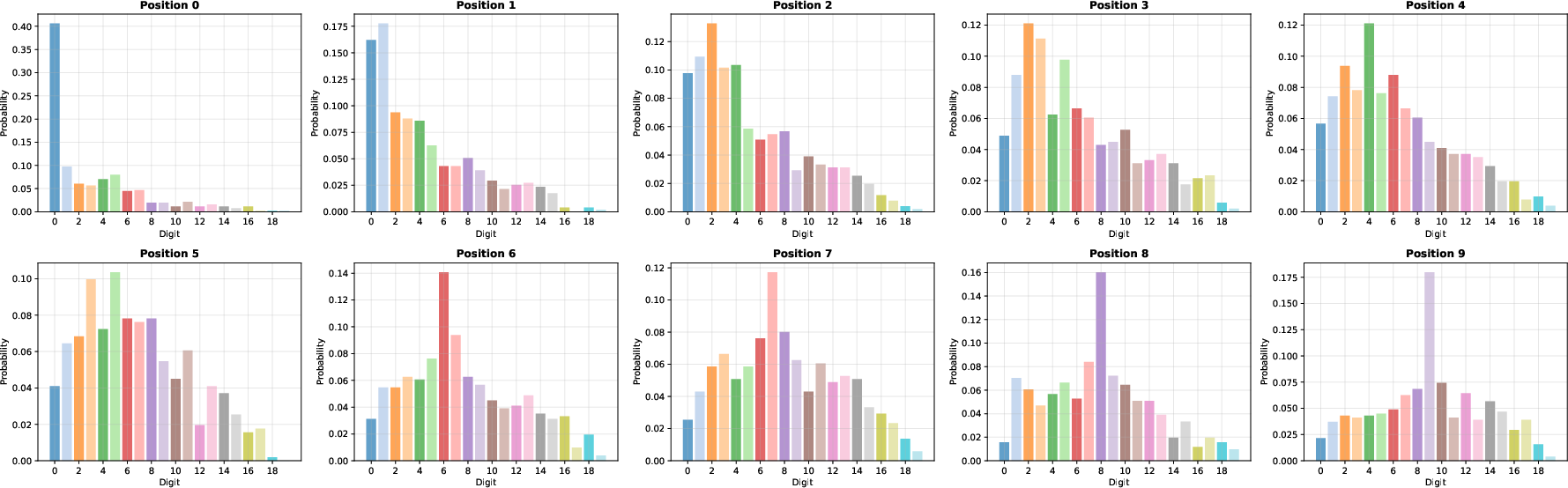
Figure 6: Positional distribution of Top-10 items after NSGR reranking, showing inertia and decaying probability with positional displacement.
System Integration and Deployment
Industrial deployment necessitates not only accuracy but also practical considerations such as computational cost and seamless pipeline integration. NSGR achieves reduced latency (−1.4 ms per request) by directly ingesting precomputed embeddings from the existing ranking model, minimizing real-time overhead. The architecture scales efficiently, allowing adoption in high-QPS online serving settings.
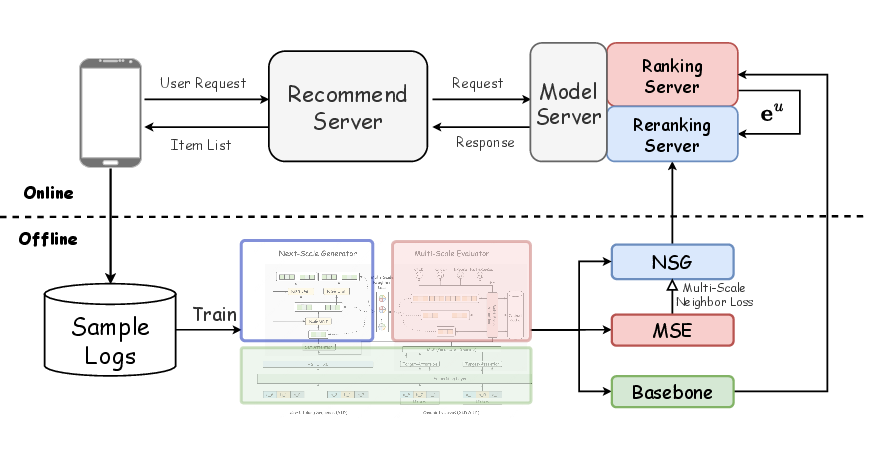
Figure 7: Architecture of the online deployment with NSGR in Meituan’s production environment.
Theoretical and Practical Implications
NSGR’s tree-based, multi-scale paradigm is theoretically appealing: it enables explicit disentanglement of local and global dependencies, enhances credit assignment at multiple compositional levels, and provides a natural structure for integrating counterfactual estimators and advanced reinforcement learning signals in future work. Practically, the model’s demonstrated improvements in both offline and online business metrics substantiate the case for tree-based generative reranking in large-scale recommendation systems.
Future Directions
Follow-on research could focus on expanding NSGR’s search heuristics with stochastic tree traversal for further diversity, adaptation to cross-domain retrieval, incorporation of user fairness constraints, or hybridization with large-scale LLM-based user simulators. Additionally, investigating parallelization and latency-accuracy tradeoffs for even larger permutation spaces (e.g., A100100) remains a pertinent direction.
Conclusion
Next-Scale Generation Reranking (NSGR) introduces an effective tree-based generative reranking framework that overcomes significant limitations of prior generative and evaluator-based models by balancing local and global optimization and ensuring high generator-evaluator consistency through the multi-scale neighbor loss. The approach has demonstrated strong empirical results on both public and industrial datasets and a robust impact in Meituan’s production setting. NSGR sets a new standard for scalable, context-aware reranking architectures in personalized recommendation.