- The paper demonstrates a hybrid fine-tuning approach using domain-specific and instruction-following datasets to empower an 8B LLaMA model in HPC log parsing.
- It employs Low-Rank Adaptation to achieve rapid convergence, high parsing coverage, and substantial energy and resource efficiency compared to larger models.
- The results validate that compact, instruction-tuned LLMs can effectively transform noisy log streams into structured templates for downstream analytics.
Instruction-Tuned LLMs for Unstructured Log Parsing and Mining on Leadership-Class HPC Systems
Introduction
The paper "Instruction-Tuned LLMs for Parsing and Mining Unstructured Logs on Leadership HPC Systems" (2604.05168) provides a technically rigorous account of deploying instruction-following, parameter-efficient LLMs for the operational parsing and analysis of heterogeneous, unstructured logs in leadership-class high-performance computing (HPC) environments. The authors motivate the necessity for domain-adapted, privacy-preserving, and locally deployable log parsing frameworks given the volume, velocity, and semantic diversity of system log streams in exascale supercomputing infrastructures. This work addresses the structural limitations of traditional rule-based or clustering-based parsers, the adaptability of open-source LLMs via instruction tuning, and the practical cost constraints of instantiating such models at scale.
Log Parsing Challenges in Leadership-Class HPC
HPC facilities such as the Frontier supercomputer at Oak Ridge National Laboratory generate hundreds of millions of log entries weekly, sourced from multi-layered hardware, firmware, operating system, and application runtimes. The nonuniformity—ranging from loosely structured time-series hardware telemetry to free-form application logs—presents obstacles for classical or database-centric log analysis due to frequent format drift, lack of universally labeled data, and the operational infeasibility of manual rule curation.
The paper formalizes log parsing as a twofold challenge: (1) extraction of invariant log templates from noisy, diverse input, and (2) mapping templated logs to structured canonical forms that can support downstream event correlation, anomaly detection, and root-cause inference.
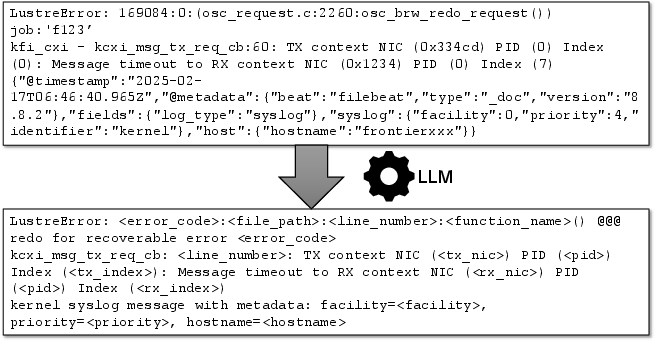
Figure 2: A schematic of the log parsing objective—transforming raw system log lines into extracted log templates via LLM-driven sequence transformation.
Instruction-Tuned LLM and Parameter-Efficient Fine-Tuning Pipeline
The authors introduce a hybrid fine-tuning methodology for adapting an 8B-parameter LLaMA model, selected for its open-source instruction-following capabilities, to the HPC log parsing domain. The framework jointly utilizes two types of training sets: (1) a domain-specific log template dataset (SET 1) derived from LLaMA 70B outputs and manual curation, and (2) general instruction-following samples from the Alpaca dataset (SET 2). Empirically, fine-tuning on their union (SET 3) enables the model to both infer abstract templates from raw logs and robustly execute natural language instructions.

Figure 3: Examples of SET 1 and SET 2 used for fine-tuning; SET 1 contains LLaMA 70B-derived templates, SET 2 samples Alpaca instruction tasks.
Learning is made both efficient and robust through Low-Rank Adaptation (LoRA), tuning only trainable low-rank subspaces of the LLM, thus enabling rapid convergence and minimal resource consumption—even when targeting inference on supercomputing nodes.
End-to-End LLM-Driven Log Parsing Workflow
The described log parsing pipeline consists of three modular stages:
- Signature Generation: Clustering related log lines for batch template extraction.
- Template Generation: Prompting the fine-tuned LLM with log samples and explicit parsing instructions, evoking chain-of-thought (CoT) reasoning for variable annotation.
- Sequence Generation: Canonicalizing further incoming logs against the extracted templates for downstream analytics.
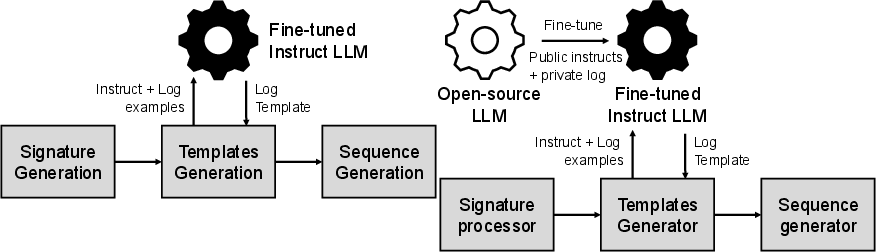
Figure 1: The end-to-end inference workflow integrates signature generation, template extraction using the LLM, and production-level log sequence generation.
Prompt engineering plays a crucial role, with tailored prompts incorporating parsing instructions and CoT cues to improve parsing fidelity for complex or previously-unseen log structures.
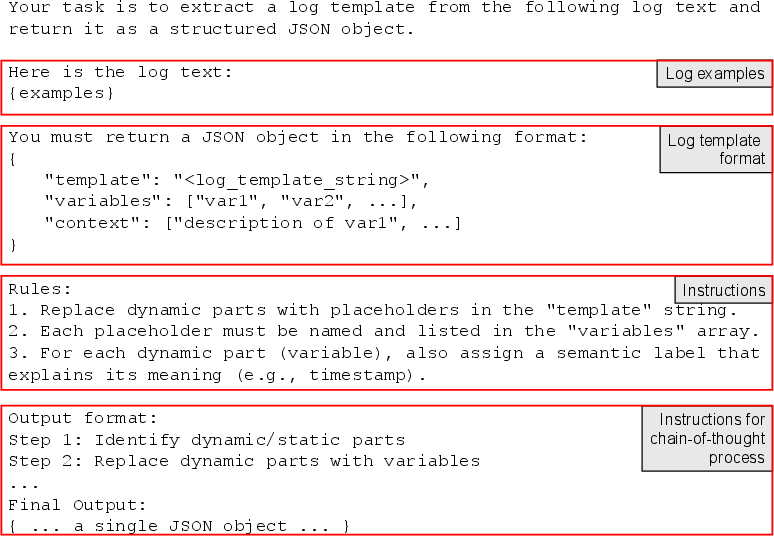
Figure 4: Representative prompt structure—jointly encoding log parsing instructions and chain-of-thought directives for the fine-tuned LLM.
Experimental Results: Coverage, Generalization, and Resource Efficiency
Experiments are conducted on both benchmark LogHub datasets (HDFS, HPC, Hadoop, Linux, OpenSSH) and ~638 million production log entries from the Frontier supercomputer. Parsing coverage—the percent of successfully structured logs—serves as the core metric.
Notable findings:
- The fine-tuned LLaMA 8B on SET 3 achieves coverage rates on-par with Claude 3.5 (175B) and LLaMA 70B, despite being an order of magnitude smaller.
- Fine-tuning with only domain templates or only instruction-following data yields suboptimal results; the union is required for strong generalization.
- Longer fine-tuning schedules can induce overfitting; 3–5 epochs with LoRA rank 8 and alpha 8 provide optimal trade-offs.
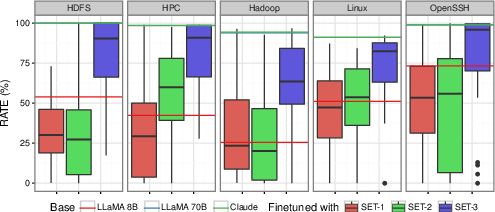
Figure 5: Post-fine-tuning results indicate that the SET 3-trained LLaMA 8B achieves comparable coverage to much larger baselines.
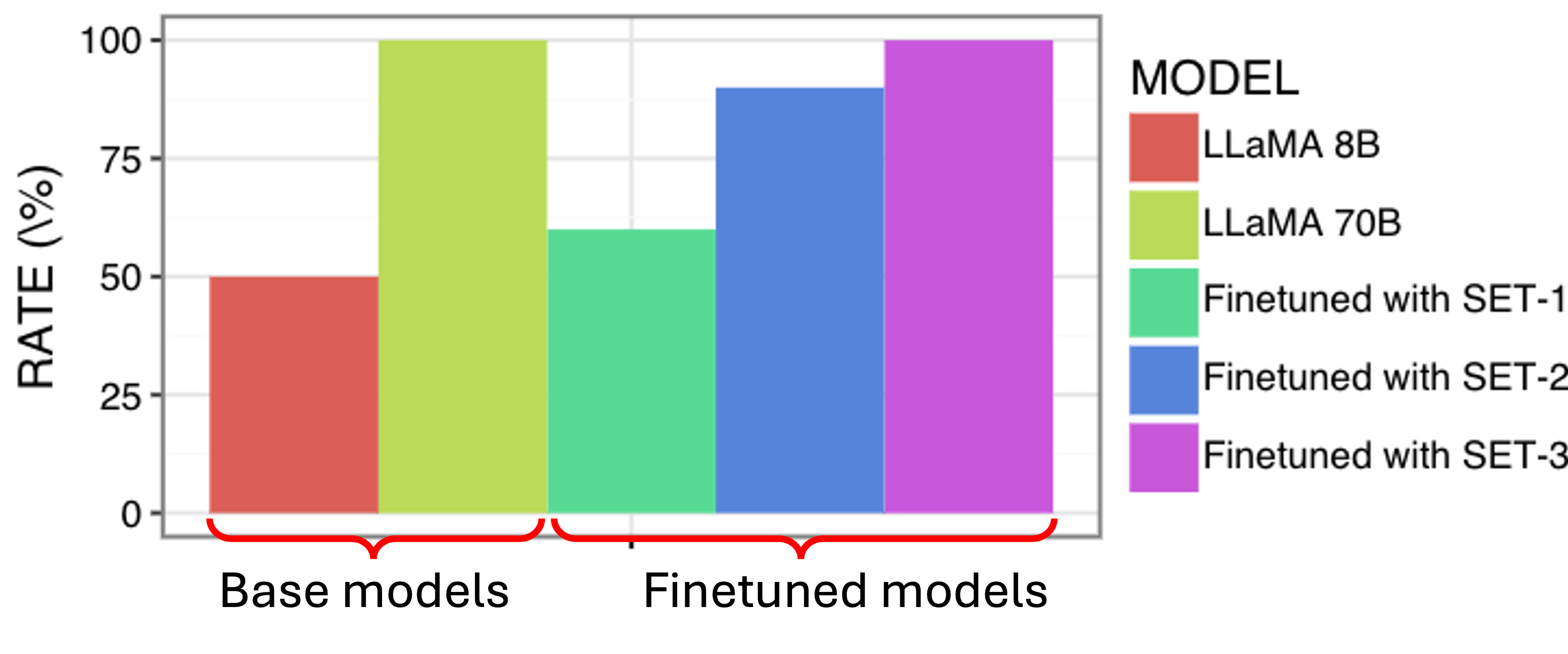
Figure 6: On actual Frontier logs, the SET 3-finetuned 8B model matches the 70B model in accuracy, validating domain transfer.
Resource profiling on the Frontier hardware reveals that LLaMA 8B infers over 7x faster, consumes less than 1/12 the peak memory, and is over 20x more energy efficient than LLaMA 70B, directly supporting its deployment for large-scale, privacy-sensitive environments.
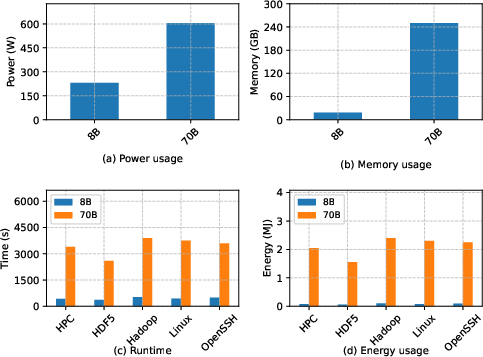
Figure 9: LLaMA 8B achieves dramatic savings in power, memory, execution time, and total energy compared to LLaMA 70B for parsing workloads.
Structural and Operational Insights from Large-Scale Log Mining
By parsing hundreds of millions of production logs, the framework enables advanced analyses:
- Temporal frequency analysis (Figure 10) quantifies the bursty and highly skewed distribution of warning/error events, revealing that catastrophic failures are extremely rare and dominated by hardware recoverable errors (15 million ECC/retry events).
- Node-utilization and failure-cascading analysis (Figure 11, Figure 12) details the propagation pathway from hardware stress to system-level fabric deadlocks, with only 55 critical failures initiating outages affecting thousands of jobs.
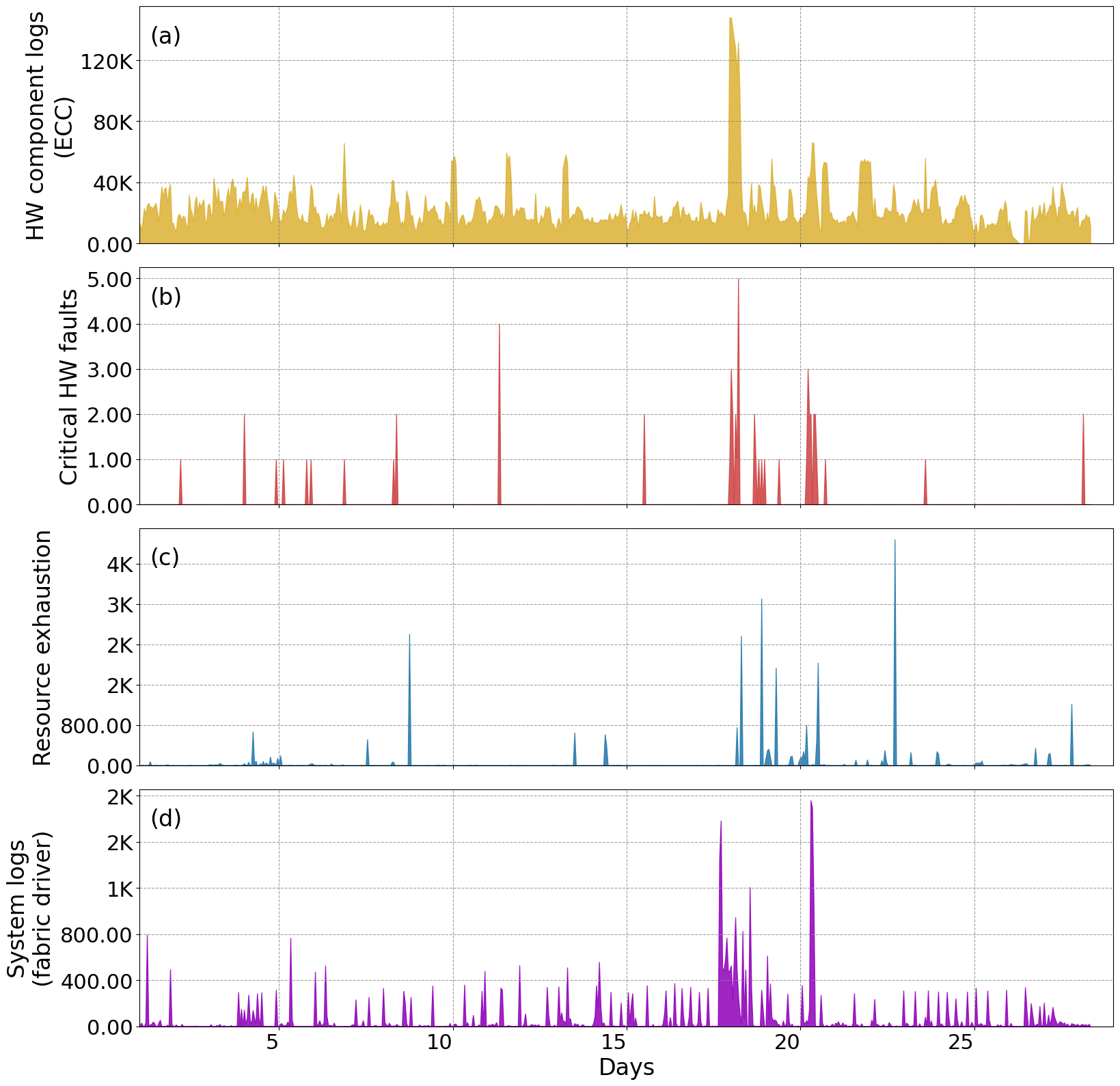
Figure 7: Multi-metric time course reveals cascade progression from ECC hardware stress to memory exhaustion and system error.
- Workload-to-failure analysis (Figure 13, Figure 14) demonstrates that domain-specific jobs on the supercomputer experience distinct log error modalities, supporting the practical value of domain-informed scheduling/predictive maintenance.
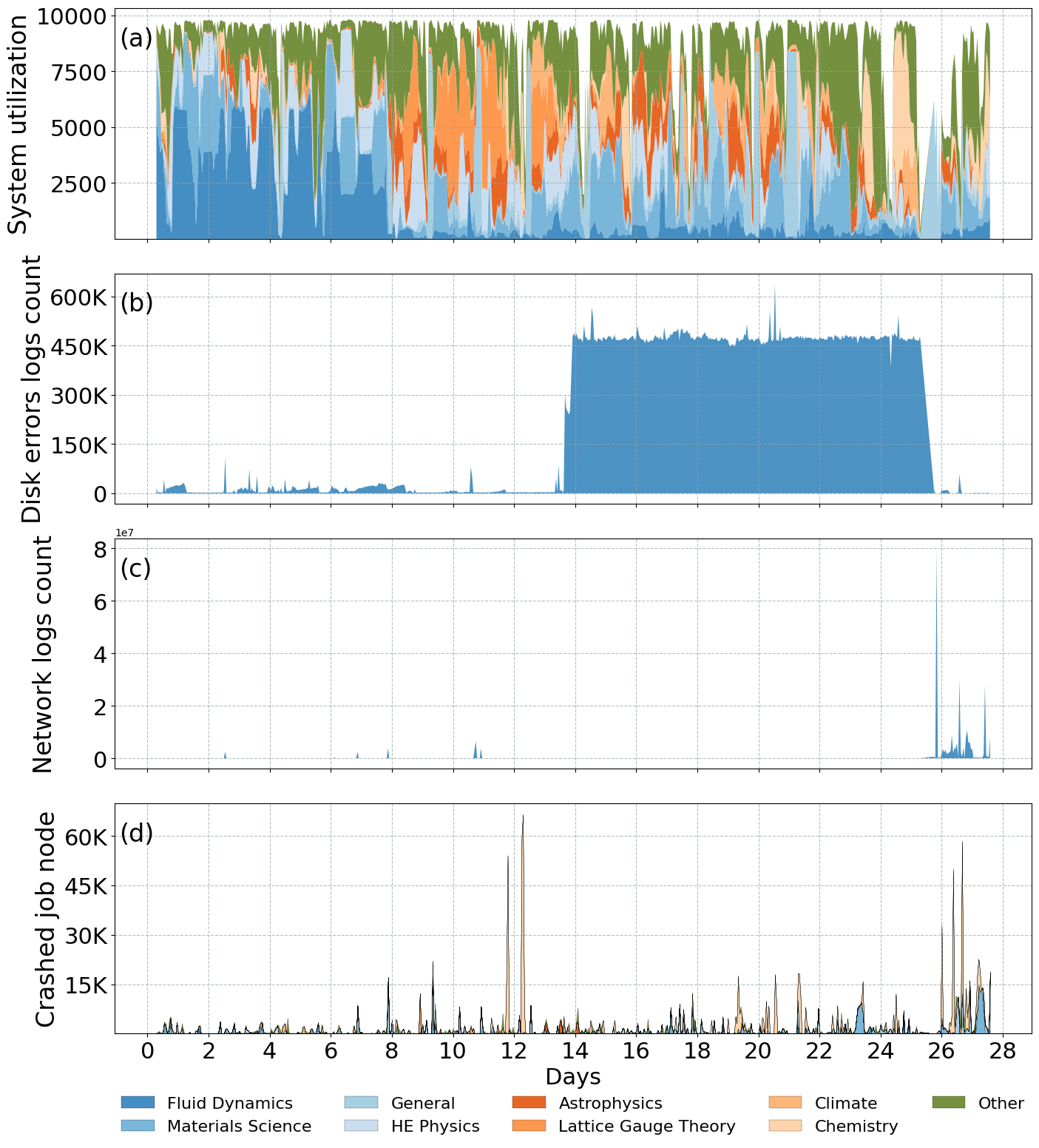
Figure 8: Scientific workload categories on Frontier show differentiated vulnerability to specific system errors and network events.
- Network topology fault mapping via kernel density estimation (Figure 15) highlights recurring, highly structured patterns in interconnect errors, implying that physical infrastructure characteristics (e.g., top-of-rack switching) dominate outage topology.
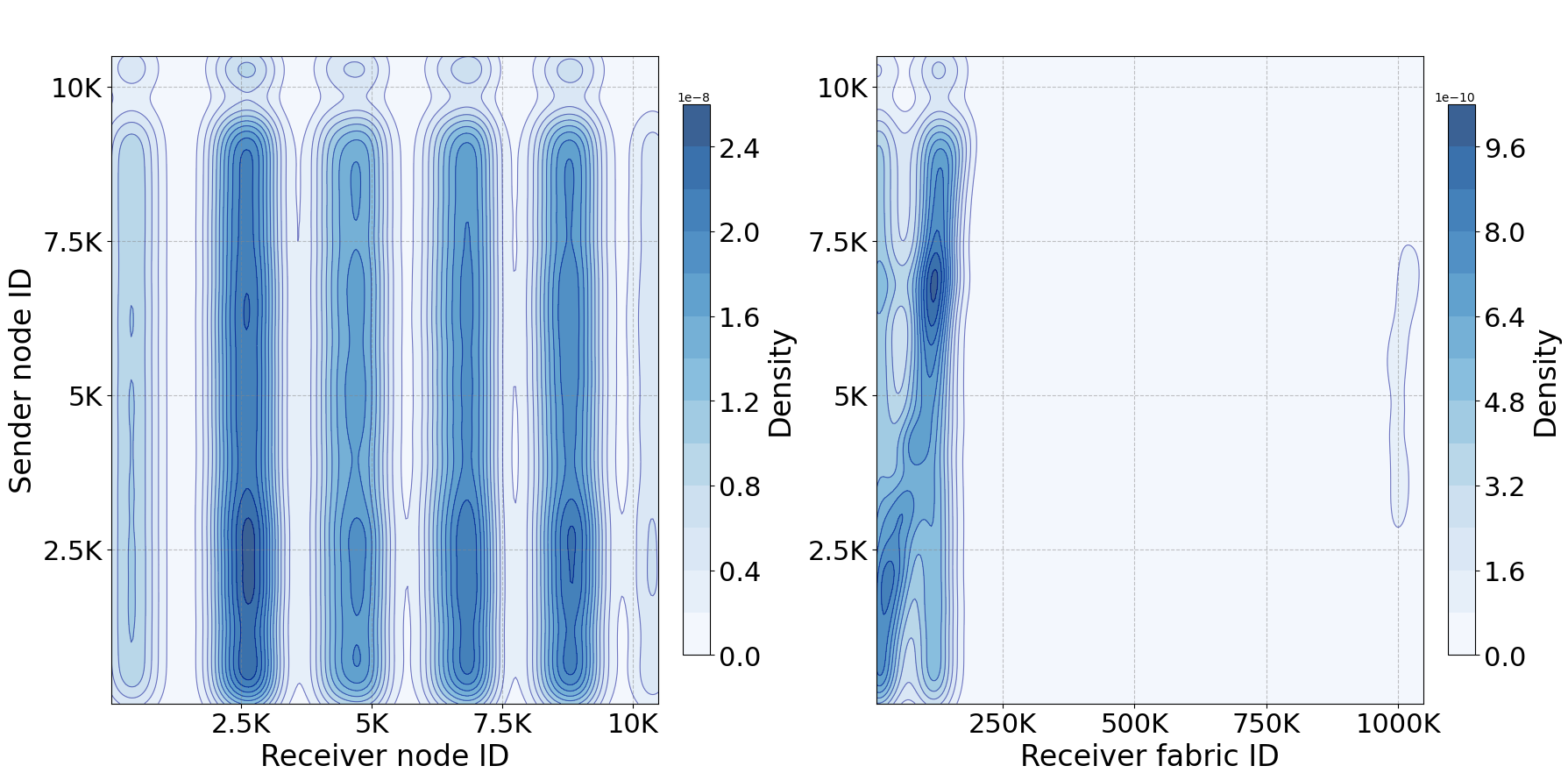
Figure 10: Spatial density analysis of interconnect errors reveals structured, periodic vulnerability zones in the network topology.
Robustness, Noise Tolerance, and Generalization
To validate robustness, the LLM was stress-tested with symbolic, lexical, and syntactic perturbations mimicking real-world log noise (variable renaming, token drop/reordering, punctuation/whitespace change). While the exact-match metric varies (strong for parameter changes, weak for prefix insertions), similarity metrics remain high, showing that the LLM generally preserves template semantics under significant format drift.
Implications and Outlook
This work establishes that instruction-tuned, compact LLMs—when fine-tuned on modest corpus sizes using LoRA and hybrid datasets—attain accuracy and coverage equivalent to proprietary or very large models without their privacy, runtime, or energy costs. The pipeline supports locally deployable, real-time analytics for exascale systems.
The findings collectively motivate several research and operational directions:
- Automated log-mining pipelines that adaptively ingest new log formats via online or continual instruction-tuning.
- Integration with synthetic dataset generation (via weakly supervised bootstrapping with larger LLMs) to bootstrap generalization to entirely new infrastructure modalities.
- Augmentation with domain-invariant feature extraction for seamless portability across HPC facilities with differing hardware/software stacks.
- Coupling with end-to-end automated monitoring, anomaly causality tracing, and domain-aware job scheduling for improved operational resilience.
Conclusion
The combination of instruction-following and domain-specific fine-tuning enables mid-scale, open-source LLMs to perform at the level of much larger, resource-prohibitive models for unstructured HPC log parsing. The demonstrated scalability and robustness, as well as the ability to extract critical operational insights from massive log streams, set a practical paradigm for HPC monitoring and fault diagnostics pipelines powered by instruction-tuned LLMs. This work underscores the emerging role of compact, fine-tuned foundation models as the preferred substrate for trustworthy, efficient systems operation analytics in supercomputing and other data-intensive domains.

