- The paper introduces a novel pipeline that uses TRELLIS-based 3D generation combined with part-level segmentation and automatic kinematic inference.
- It employs a dual-stream method with SAGA and PointNet++ to achieve precise segmentation and reliable prediction of joint and hinge axes.
- Quantitative results, including improved CLIP similarity and LPIPS scores, validate the approach for creating high-fidelity, animatable vehicle digital twins.
Part-Level 3D Gaussian Vehicle Generation with Joint and Hinge Axis Estimation
Introduction
This paper introduces a pipeline for generating animatable 3D Gaussian Splatting (3DGS) vehicle models from sparse imagery, targeting applications in simulation for autonomous driving and vehicle dynamics reasoning. Standard 3D asset generative models produce visually appealing but static reconstructions, insufficient for simulation frameworks needing per-part articulation and kinematic modeling. This work addresses this gap with a novel system that integrates 3DGS generation, part-level segmentation, and automatic kinematic parameter inference, enabling high-fidelity, part-aware digital twins suitable for realistic simulation and analysis.
System Overview
The proposed pipeline orchestrates multiple state-of-the-art components to enable part-level segmentation and articulation of 3DGS vehicle assets. The process begins with generating a detailed and plausible 3D Gaussian vehicle from few multi-view images using TRELLIS—a generative latent model optimized for asset completion and consistency. This asset is subjected to two parallel streams: a kinematic reasoning module and an enhanced SAGA-based pipeline (Figure 1).
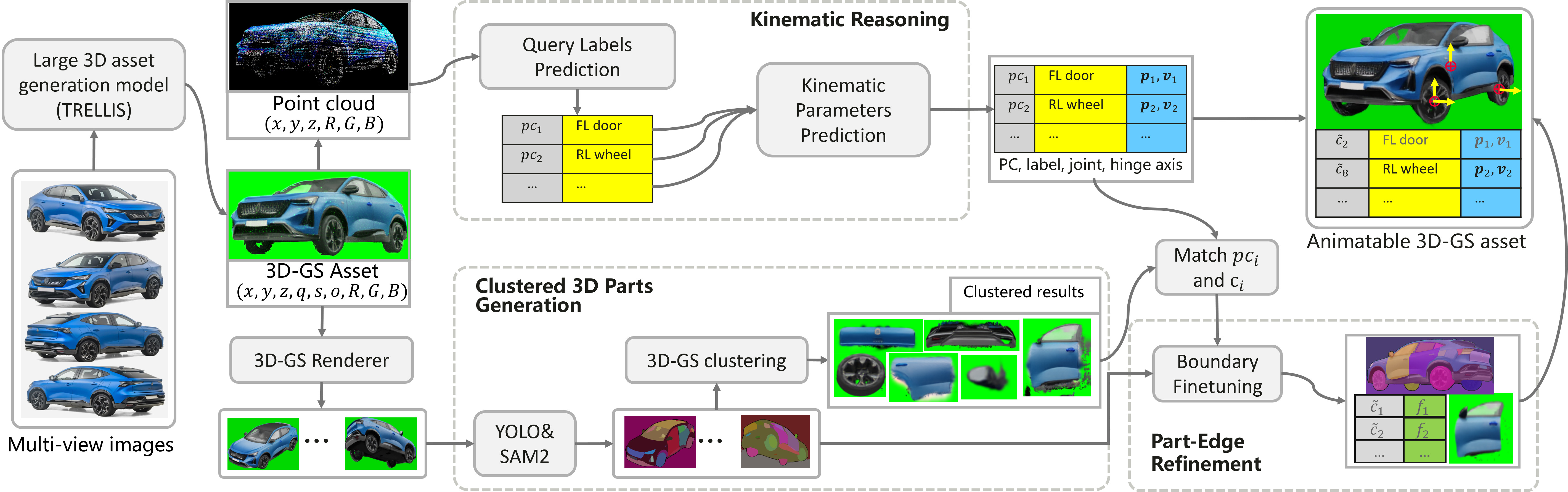
Figure 1: Pipeline overview, from image input to animatable 3DGS vehicle via TRELLIS, PointNet++-based kinematic reasoning, and SAGA segmentation with boundary refinements and mask insertion.
The kinematic reasoning module relies on PointNet++ architectures for part segmentation and hinge/joint position regression, trained on a custom point cloud dataset with manual part and kinematic annotations. In parallel, SAGA clusters the 3DGS Gaussians using auto and task-specific masks, facilitated by mask insertion and state-of-the-art image segmentation with YOLO and SAM2. Outputs from both streams are fused to preserve six principal vehicle components, with geometries refined at part boundaries for animatability.
Component Methodology
Large 3D Asset Generation: TRELLIS
TRELLIS conditions on as few as four multi-view images and synthesizes consistent 3D Gaussian assets, as demonstrated in prior work (2604.05070). Unlike traditional 3DGS reconstructions which require dense captures and suffer from incomplete/uncontrollable geometry, TRELLIS leverages latent structured priors to infer missing regions and preserve distinctive articulable forms (especially critical for elements like wheels and doors). The pipeline generates multiple rendered views used downstream for segmentation and training.
Semantic and Kinematic Segmentation
SAGA with Task-Specific Mask Insertion
The SAGA pipeline learns contrastive 3DGS features by propagating masks derived from SAM2 and YOLO (trained on fine-grained car part datasets). Since SAM tends to over-fragment parts of interest (e.g., splitting mirrors and windows from doors), explicit mask insertion ensures full-part coverage and reliable clustering of semantically significant components. Propagation to multi-view renders enhances mask consistency across the 3D asset, increasing segmentation precision.
PointNet++-based Kinematic Reasoning
PointNet++ is trained for both point-wise segmentation and continuous-value regression (joint and hinge axis prediction), leveraging a high-quality annotated point cloud dataset constructed from 100 CAD models. At inference, the 3DGS asset is converted to a point cloud (using Gaussian center means and RGBs) and fed to PointNet++ for both segmentation and kinematic prediction (Figure 2, Figure 3).
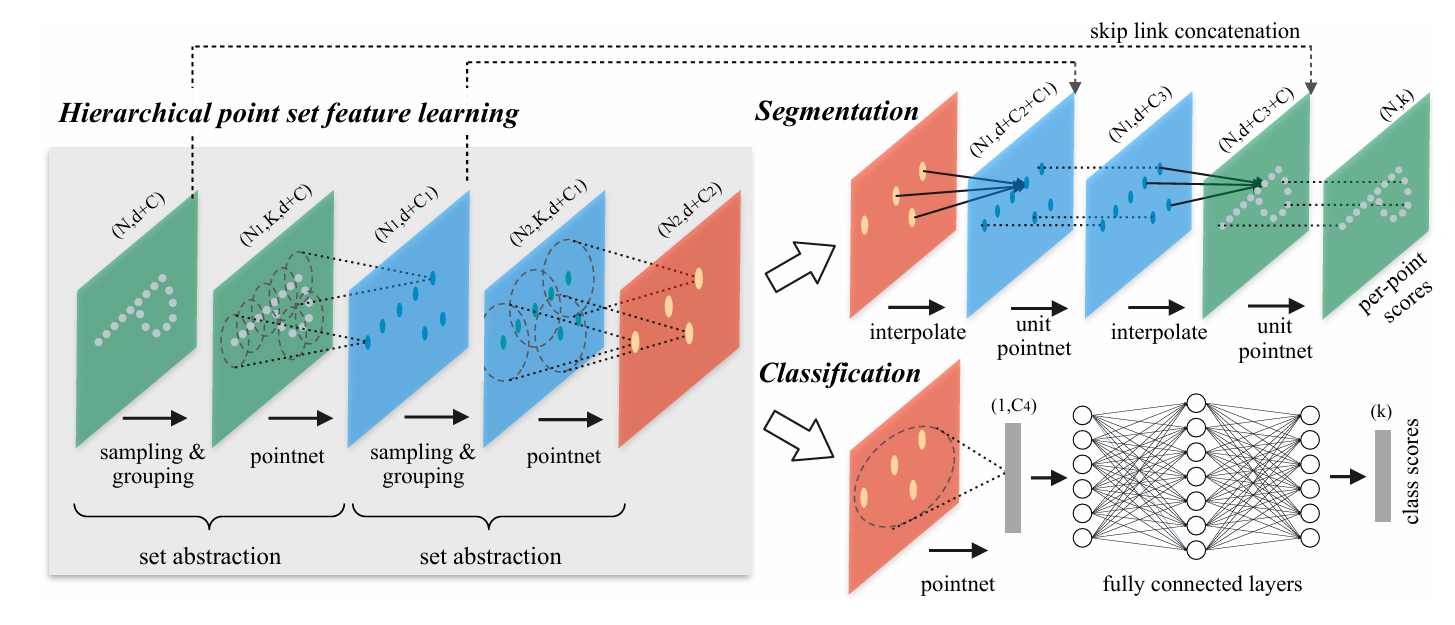
Figure 2: PointNet++ hierarchical feature learning architecture—multi-scale local feature aggregation for part segmentation and kinematic regression.
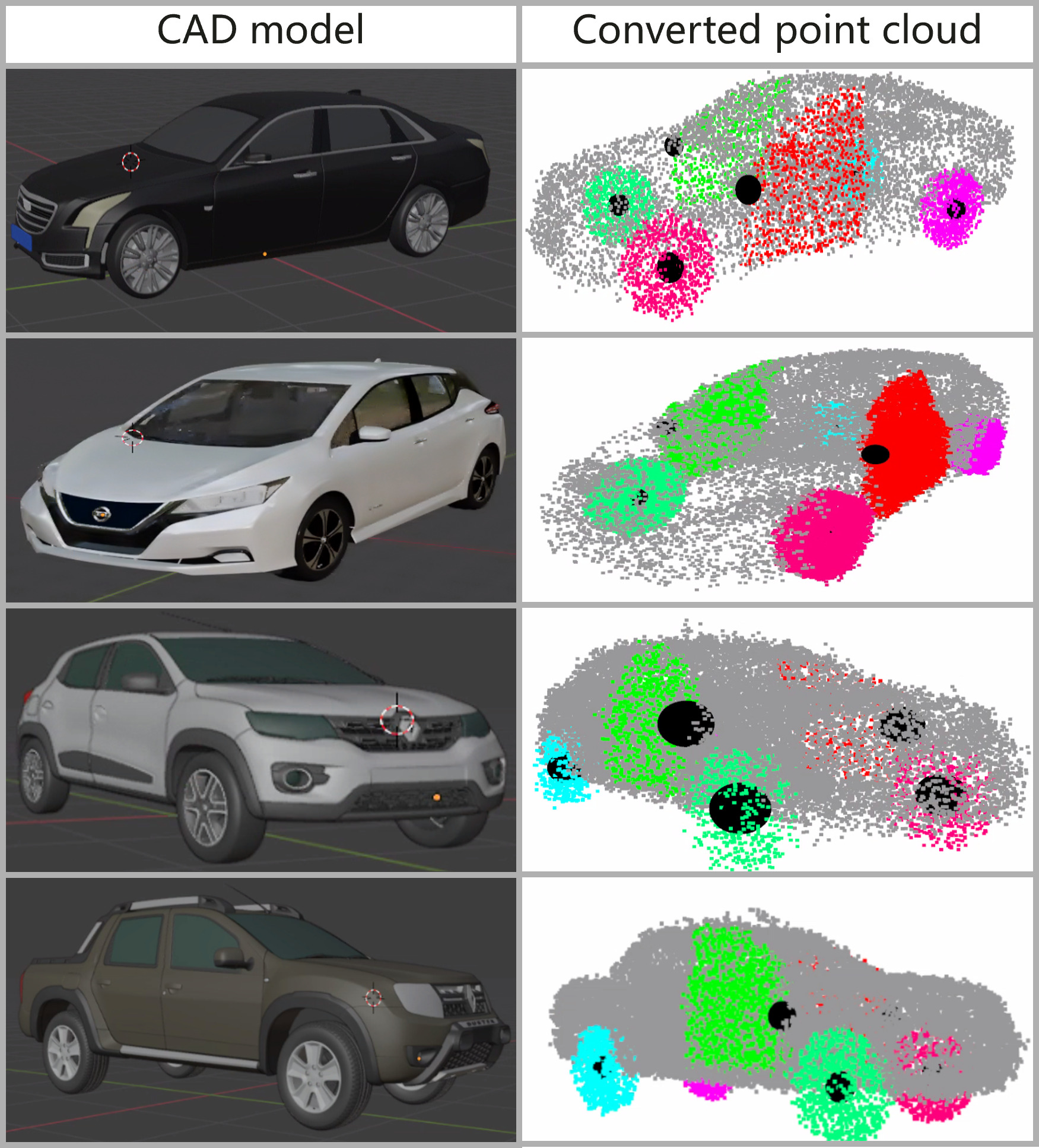
Figure 3: Training examples for PointNet++ segmentation and kinematic label prediction, colored by part, with kinematic loci highlighted.
Label predictions are used to identify and align SAGA clusters with precisely those corresponding to movable parts—a task where SAGA’s open-vocabulary CLIP-based clustering underperforms due to a lack of explicit spatial grounding.
Part-Edge Refinement
Boundary finetuning confronts two characteristic issues of 3DGS part segmentation: spatial bleeding of Gaussians at part intersections and the emergence of “floating” artifacts after part articulation. A geometry-only refinement term penalizes out-of-mask alpha in the rendered image and enforces tight conformance without compromising the photometric fidelity within masks. The documented loss functions are:
- Outer-boundary loss to suppress cross-part blending;
- L1 photometric loss for in-mask consistency, with λ=0.5 balancing geometry and appearance fidelity.
This step yields markedly sharper, cleaner segmentations critical for plausible articulated renderings (Figure 4).

Figure 4: Part geometries before and after boundary refinement, demonstrating suppression of edge artifacts and “floating” Gaussians.
Quantitative and Qualitative Results
The evaluation leverages second-generation CARLA vehicles with ground-truth part articulations, considering visual similarity metrics (CLIP similarity, LPIPS distance) over 56 renderings generated from various steering and opening states. An ablation study empirically demonstrates the effectiveness of each pipeline facet. Enabling movable part mask insertion increases full-part recall and reduces segmentation fragmentation. The boundary refinement module yields further substantial gains, as evidenced by quantitative metrics (CLIP: 0.848 → 0.873, LPIPS: 0.305 → 0.283) and improved perceptual alignment with ground truth (Figure 5):

Figure 5: Qualitative ablations. Top to bottom—(1) SAGA+Trellis baseline, (2) with mask insertion, (3) with boundary finetuning (full pipeline), (4) ground truth; note progressive reduction in incompleteness, edge noise, and artifacts.
Implications and Future Directions
The presented system fundamentally extends the capability of neural asset generation, merging high photorealism with precise, editable kinematic articulation of in-the-wild vehicles. This closes the sim-to-real gap for downstream simulation tasks (e.g., perception, control, scene understanding, OOD reasoning), which now can exploit part-aware digital twins. Theoretically, the methodology demonstrates the synergy of latent generative priors, transferable 2D segmentation, and geometric deep learning for structured 3D reasoning.
Notwithstanding, several limitations remain. Part geometry supervision is mask-based, resulting in degenerate thickness under some edit configurations. Interior structures are not well resolved, leading to artifacts when doors open. Future work must address these with volumetric or surface-based regularization, possibly integrating diffusion inpainting for interiors and exploring richer 3DGS or mesh-to-Gaussian domain adaptation schemes.
Conclusion
A comprehensive, efficient pipeline is proposed for generating faithful and highly controllable animatable 3D Gaussian representations of vehicles from sparse imagery. The integration of TRELLIS, SAGA with guided segmentation, PointNet++ for kinematic reasoning, and part-edge finetuning enables consistent and plausible motion editing, substantiated by both quantitative and perceptual studies. This work constitutes a key advancement toward scalable, part-aware neural asset generation for simulation, with substantial implications for autonomous vehicle system development and photorealistic data-driven simulation workflows.