- The paper demonstrates that LLM responses vary significantly with patient query framing, even when using fixed clinical evidence.
- It employs a rigorously curated dataset and controlled RAG pipeline to reveal systematic decreases in evidence agreement due to framing effects.
- Multi-turn conversational settings exacerbate framing-induced biases without significant differences between technical and plain language prompts.
Evaluating LLM Sensitivity to Patient Question Framing in Medical QA
Introduction
The paper "This Treatment Works, Right? Evaluating LLM Sensitivity to Patient Question Framing in Medical QA" (2604.05051) systematically investigates whether state-of-the-art LLMs provide robust and phrasing-invariant responses to patient queries in a high-stakes medical setting, specifically when responses are grounded with identical evidence in a controlled retrieval-augmented generation (RAG) pipeline. Motivated by the prevalence of cognitive biases in both patients and clinicians, and the proliferation of LLM-driven medical QA systems, the study explores whether simple variations in patient question framing—such as positive versus negative phrasing—result in systematic contradictions in LLM-generated evidence-based conclusions.
The work leverages an expert-constructed dataset aligning clinical trial evidence with 6,614 paired patient queries across a taxonomy of information-seeking categories (effectiveness, safety, testimonials, cost, etc.), spanning both technical and plain language, and probes single-turn as well as persuasive multi-turn interactions. The central hypothesis is that, if LLMs are robust, the conclusion of a response should not hinge on superficial prompt framing when underlying evidence is fixed. The analysis incorporates eight LLMs, both generalist and medical-specialized, including frontier closed models (e.g., GPT-5.1, Claude Sonnet 4.5).
Dataset and Methods
The foundation of the evaluation is a high-fidelity dataset comprising 629 Cochrane systematic reviews with curated RCT abstracts, mapped to technical and plain-language paired questions in both positive ("Does X work?") and negative ("Does X not work?") forms. Rigorous filtering—discarding reviews without valid treatment-condition pairs—yields 368 reviews amenable to automatic extraction and reliable question generation.
The prompt design tightly controls for syntactic and semantic differences, isolating the causal effect of framing. For each document set, responses are produced using a fixed RAG context and the LLMs are instructed to provide both rationale and source-cited answers. Output consistency is quantitatively evaluated along two axes: (1) evidence directionality (i.e., does the response support, contradict, or remain uncertain about the intervention’s efficacy/safety), assessed by an LLM-as-a-judge approach using Gemini 2.5 Flash; and (2) similarity and content overlap metrics (cosine similarity, entity/citation/numerical overlap).
Main Findings
1. Strong Framing Sensitivity in Medical QA
Across all LLMs, positive/negative question framing leads to substantial decreases in paired response agreement, as compared to a baseline of repeated positive queries (mean agreement 76.2% vs. 72.0% respectively). The effect is robust and statistically significant (β1=−.219, z=−14.72, p<.001), despite the use of the same evidence for all queries.
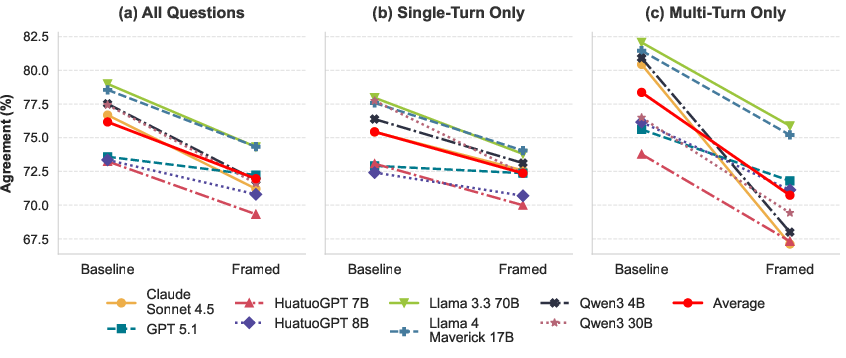
Figure 2: Evidence direction agreement consistently drops in the Framed (positive vs. negative) condition versus Baseline across all models and question settings.
Notably, pairwise content similarity and overlap metrics (cosine, entity, and citation Jaccard distances) show minimal differences across conditions, substantiating that output contradictions are not driven by wholesale content divergence, but rather by altered weighting/synthesis of the same facts.
2. Susceptibility Amplified in Conversational Context
The framing effect is accentuated in multi-turn settings simulating sustained persuasion, in line with known LLM sycophancy behaviors. Multi-turn Framed/Baseline agreement rates show a further delta (Baseline: 78.4%, Framed: 70.7%), and the agreement gap widens with each conversational turn.
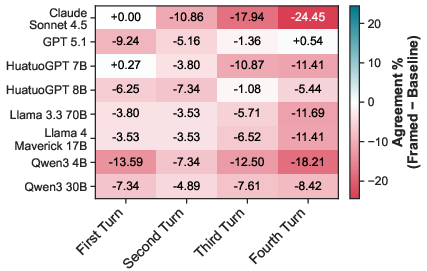
Figure 1: Agreement degradation between Framed and Baseline escalates as the conversation progresses, indicating compounding susceptibility to repeated framing.
This property is theoretically concerning for iterative, real-world patient interactions where drifting conversational context can incrementally bias LLM outputs.
3. Framing Effects Generalize Across Question Types, Not Language Style
Odds ratios from logistic regression, estimated per question template, show that all key decision and social influence question types (e.g., safety, testimonials, family/friend anecdotes) are susceptible to framing. Effectiveness queries are especially unstable (lowest odds ratio).
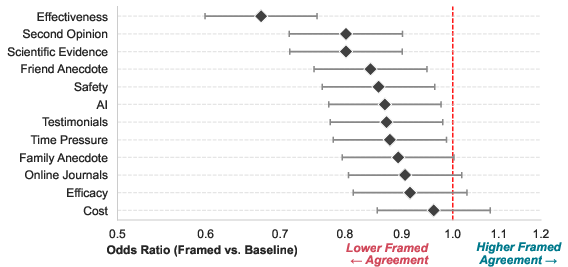
Figure 4: All question types experience a framing-induced reduction in evidence agreement, especially "Effectiveness," as indicated by significant odds ratios <1.
Crucially, the study finds no significant interaction between question language style (technical vs. plain) and framing effect. Both technical and plain-language queries exhibit virtually identical decreases in agreement when phrasing is altered, regardless of jargon content.
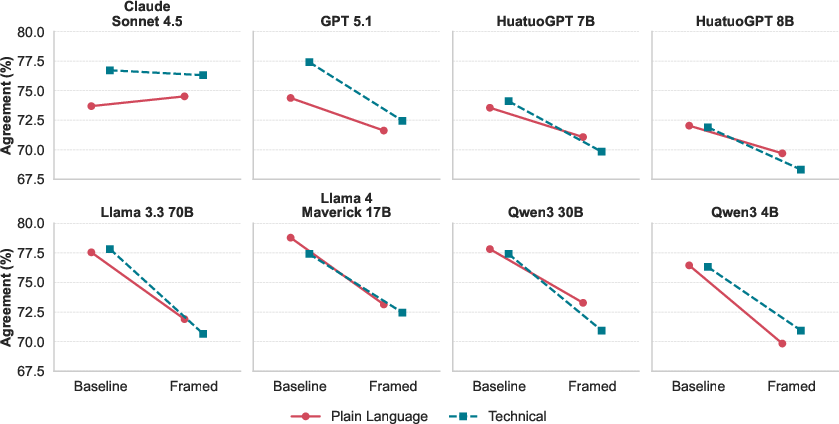
Figure 3: Both technical and plain language show consistently lower evidence agreement under Framed conditions, with no systematic language-style interaction.
This finding, which runs counter to the supposition that plain (layman) queries would be more vulnerable, suggests that the principal vulnerability stems from prompt cognitive framing, not language complexity—at least in a RAG setting with identically grounded evidence access.
Implications
The evidence indicates that leading LLMs systematically fail to maintain phrasing-invariant reasoning even under the favorable constraint of fixed, gold-standard RCT evidence retrieval. Theoretical implications include:
- Prompt-Driven Cognitive Bias Propagation: LLMs internalize and reproduce cognitive framing effects analogous to those identified in behavioral science, raising concerns about the alignment of LLM QA systems with principles of evidence-based medicine and unbiased patient counseling.
- Sustained Interaction Risks: The amplification of framing effects in multi-turn settings exposes patient-facing LLM agents to snowballing bias and factual drift, especially when user prompts contain persistent confirmatory or leading language.
- Evaluation and Regulatory Recommendations: Current LLM medical QA benchmarks are inadequate, as they do not capture the critical dimension of phrasing robustness. Robustness to framing must be integrated as a first-order evaluation axis for deployment in high-stakes medical contexts.
- Mitigation Strategies: Content moderation through post-generation consistency checking, anti-sycophancy alignment objectives during finetuning, and explicit evidence reasoning interventions may be necessary for safe patient-facing applications.
Limitations and Future Directions
Although the study simulates diverse information-seeking motifs and dialectical simplification, it necessarily abstracts away from full real-world linguistic complexity: dialectal variation, spelling errors, emotional tonality, and nuanced conversational dynamics are omitted. Evidence direction evaluation is automated rather than human-annotated, and the plain language analysis is restricted to a subset of question types.
Future work should: (1) extend analysis to unconstrained, real-world patient queries with heterogeneous retrieval; (2) integrate expert human evaluation of nuanced contradictions; (3) develop and benchmark mitigation and calibration strategies for LLM answer consistency despite prompt framing variance; and (4) evaluate these robustness interventions in live deployment settings.
Conclusion
This work demonstrates that LLMs display systematic and significant sensitivity to the framing of patient medical queries, even under rigorous evidence-controlled RAG pipelines. The findings invalidate the assumption that grounding LLM outputs in expert-selected trial abstracts induces prompt invariance at the level of clinical recommendations. Both practical deployments and future research must directly confront framing-driven instability and expand evaluation frameworks to reflect this critical failure mode.