- The paper's main contribution is decomposing complex software engineering workflows into five distinct atomic skills for LLM coding agents.
- It introduces a joint reinforcement learning framework that significantly improves both individual skill performance and out-of-distribution task generalization.
- Experimental results demonstrate enhanced Avg@3 metrics and overall scalability compared to traditional composite-task RL strategies.
Scaling Coding Agents via Atomic Skills: A Technical Summary
Motivation and Paradigm Shift
Current LLM-based coding agents predominantly rely on end-to-end optimization with composite composite tasks (e.g., bug-fixing, code generation), commonly resulting in policies with weak generalization outside their training domains. The absence of explicit supervision on intermediate skill steps in composite-task RL leads to agents overfitting high-level reward signals and failing to acquire compositional, transferable competencies.
This paper proposes a paradigm shift: decomposing complex software engineering workflows into a spectrum of granular, reusable atomic skills and scaling coding agents by training them via joint RL across these atomic capabilities. The central hypothesis is that joint atomic-skill mastery catalyzes capability generalization and compositional transfer to new, unseen composite coding tasks.
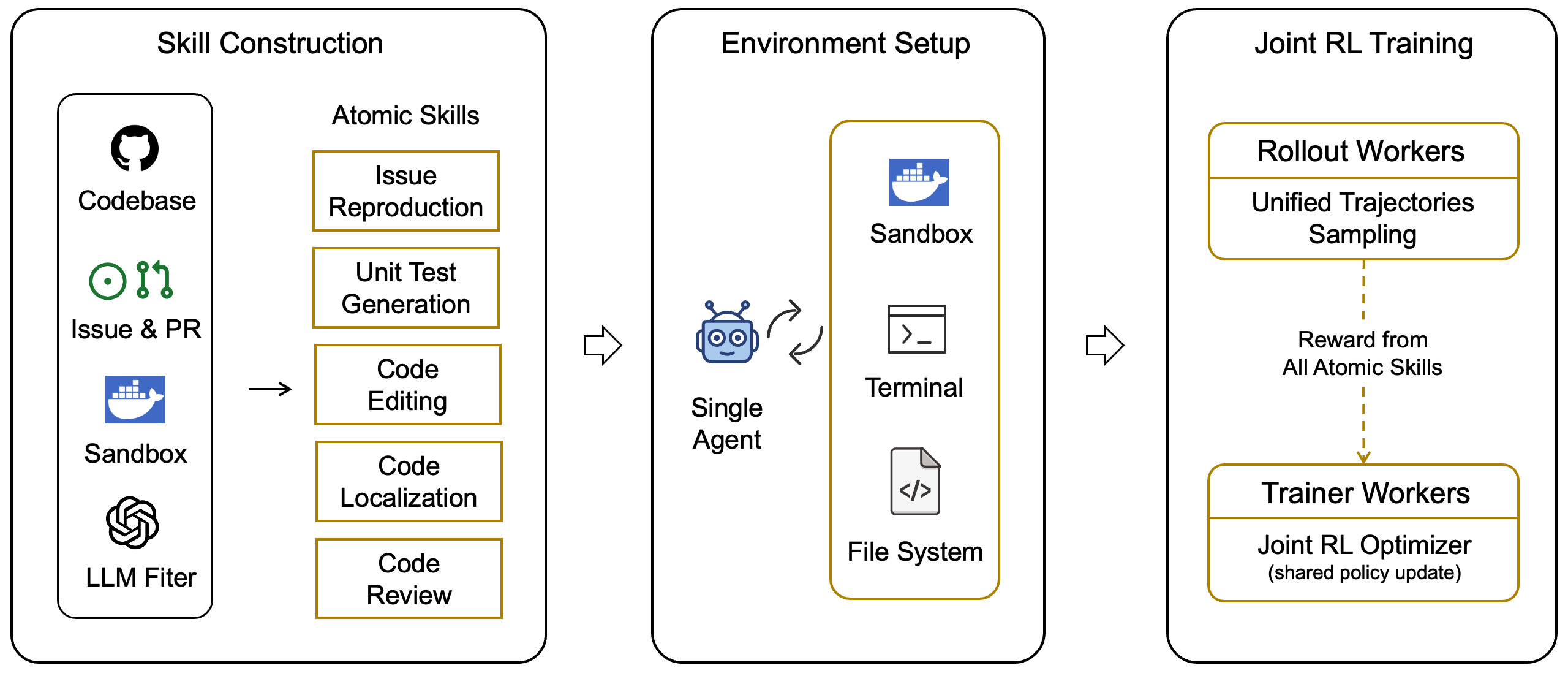
Figure 1: The architecture of the overall training framework, showcasing data flows and joint optimization infrastructure.
The authors formalize five atomic skills, each with a precise task interface, unambiguous reward definition, and high composability:
- Code Localization: Identify relevant files based on NL issue description and codebase, with rewards tied to exact-set matching of predicted and ground-truth file sets.
- Code Editing: Apply minimal code modifications at specified locations as dictated by an edit instruction; reward is defined by complete unit/regression test pass.
- Unit-Test Generation: Synthesize unit tests for target functions; reward is nontrivial, requiring tests to both pass for correct code and to expose faults in semantically mutated variants.
- Code Review: Output a NL summary plus binary correctness judgment for proposed PRs; reward is match to ground-truth correctness verified via automated execution.
- Issue Reproduction: Produce scripts that replicate a reported failure; script is rewarded if it triggers the failure pre-patch and eliminates it post-patch.
All skills adhere to a unified interface and leverage a controlled, minimal toolset (mainly file manipulation and bash execution) to ensure task expressiveness without extraneous complexity.
Joint Reinforcement Learning Framework
A single unified agent policy is optimized with RL over all five atomic skills. Each training step samples from a mixture of atomic skill distributions, collects trajectories and rewards across all skill types, and shares parameters among tasks. The reward structure is inherently sparse and heterogeneous, thus Group-based Relative Policy Optimization (GRPO) is employed for advantage normalization and stabilization.
Decoupled rollout-generation and policy-optimization workers coordinate asynchronously for high-throughput data collection, supporting compute-intense, sandboxed evaluation of tool-using LLM agents at scale.
Experimental Evaluation and Results
The base model is GLM-4.5-Air-Base (106B, 12B active), initialized via SFT exclusively on atomic-skill-specific data (decontaminated from all test targets). Three configurations are evaluated:
- Public GLM-4.5-Air (reference)
- GLM-4.5-Air-Base + SFT (atomic-skill pretrained)
- GLM-4.5-Air-Base + SFT + joint RL (full approach)
Metrics: Avg@3 scores for five atomic and five OOD composite tasks, including SWE-bench Verified, Multilingual, Terminal-Bench, Refactoring, and Security.
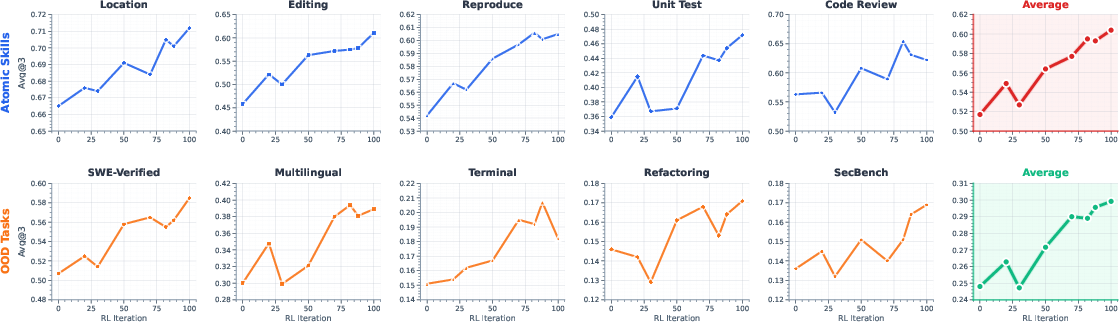
Figure 2: Training curves showing improvements across all five atomic skills and composite OOD tasks during joint RL.
Key findings:
- Joint RL yields strict monotonic improvements across all atomic skills (e.g., Code Editing: 0.458 → 0.611; Unit Test: 0.359 → 0.472).
- Generalization to OOD benchmarks is robust: e.g., Verified bug-fixing 0.507 → 0.585, Multilingual 0.300 → 0.389, outperforming strong baselines on multiple composite tasks.
- Aggregate general capability (Avg@3 over all tasks) increases from 0.383 (SFT) to 0.452 (joint RL), surpassing the public model (0.416).
Ablation: Joint vs. Single-Skill RL
Ablations compare joint RL, editing-only RL, and verified-only RL. Only joint RL provides broad, cross-capability gains: single-skill RL matches in-domain improvements on the optimized task but confers limited benefit or even degradation on non-optimized atomic and composite skills.
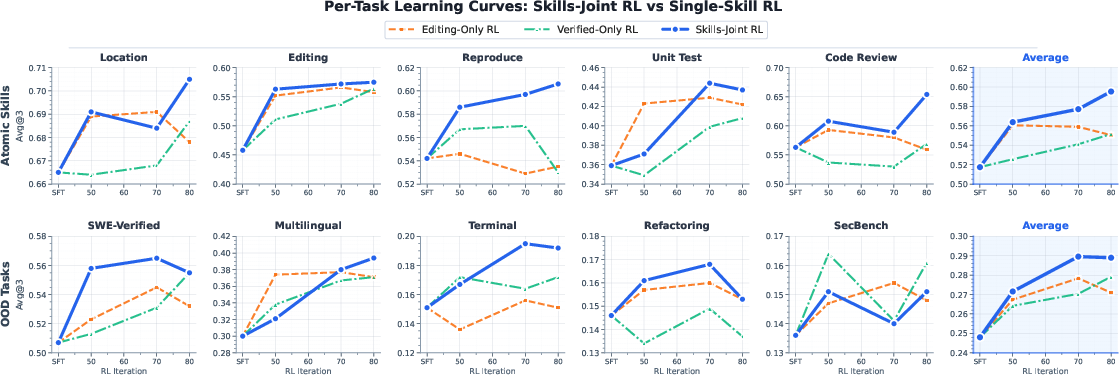
Figure 3: Ablation results, illustrating generalization and capability retention superiority of joint RL over single-task RL.
Training Dynamics
Pass@1 and average environment steps are tracked per skill. Most atomic skills show correlated improvements in both metrics, while code review displays non-monotonic behavior in step usage—potentially indicative of exploration-exploitation tradeoff dynamics.
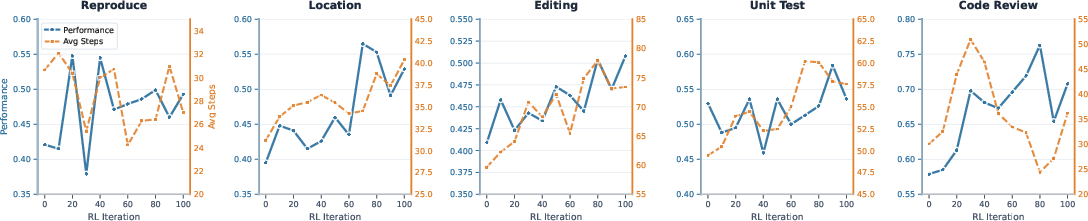
Figure 4: Evolution of atomic skill performance and average action steps over RL training.
Implications, Limitations, and Future Directions
This work substantiates that decomposing software engineering workflows into minimal, composable atomic skills and optimizing them via joint RL produces agents with broader, more robust capabilities than composite-task optimization alone. The approach resolves the sample inefficiency and reward engineering barriers endemic to naively scaling composite RL benchmarks.
Practically, atomic-skill-based RL offers a scalable methodology for constructing extensible, generalist coding agents: skill sets can expand to support new software engineering domains without retraining on all possible downstream tasks. Theoretically, the findings confirm the compositionality and positive-transfer hypotheses for LLM-based agentic RL in coding environments.
Future research directions include:
- Expansion of the atomic skill set to encompass richer software workflows.
- Hierarchical skill composition and dynamic curriculum learning.
- Curriculum-based or reinforcement-guided skill library construction.
- Exploring capability ceilings and transfer saturation as a function of skill diversity and policy scale.
Conclusion
Training agentic LLM coding agents with joint RL over explicitly defined atomic skills yields significant improvements in both direct capabilities and transfer to unseen tasks. This atomic-skill-centric scaling paradigm demonstrates robust specialization-generalization tradeoff management, outperforming prior composite-task RL strategies for software engineering agents. The results motivate the development of more granular, compositional skill libraries and frameworks for next-generation code agents.
Reference: "Scaling Coding Agents via Atomic Skills" (2604.05013)

