- The paper shows that generative VLMs using advanced CoT prompting achieve 82% accuracy, outperforming embedding methods by nearly 20 points.
- It demonstrates that tailored prompt engineering significantly boosts performance in both embedding-based and generative models.
- Findings reveal that while generative models offer higher accuracy, they require more computational resources and exhibit nondeterminism compared to lightweight embedding approaches.
Comparative Evaluation of Embedding-Based and Generative VLMs for LLM-Driven Document Classification
Introduction
This paper presents a thorough empirical comparison between embedding-based and generative VLM paradigms for classifying technical geoscience documents, addressing a domain featuring substantial multimodality, suboptimal OCR, and document heterogeneity. The study encapsulates benchmarking on a proprietary, multi-class geoscience corpus using both established and state-of-the-art models, and systematically analyzes prompt design, fine-tuning effects, accuracy, stability, and resource implications. The analysis is substantiated with robust metrics, and it provides concise recommendations for deploying LLM-driven classification solutions in operational information management settings.
Experimental Methodology
Dataset and Benchmark Task
The dataset consists of technical documents classified into eight geoscience-centric categories (e.g., Geology, Petrophysics, Petroleum Engineering). To normalize model input, only the first page from multi-page documents is used, capturing the signal-rich initial context and canonical layouts. Source formats are diverse, including OCR-impaired scanned images and native PDFs, enforcing a realistic assessment of multimodal machine perception performance in industrial repositories.
Models and Workflows
Two primary model paradigms are evaluated:
- Embedding-based Methods: These generate vector representations for both documents and class labels, leveraging domain-specific class definition prompts for enhanced embedding quality. Classification is realized through similarity voting based on cosine distance.
- Generative VLMs: Vision-LLMs directly output class labels in response to document-image plus prompt input. Prompt engineering ranges from simple persona-based cues to sophisticated CoT formats tailored for geoscience semantics and workflow.
Additionally, the effect of SFT (Supervised Fine-Tuning) is studied on Qwen2.5-VL-7B, probing the trade-off between distributional data scarcity and overfitting risks.
Standard performance metrics include overall accuracy, macro F1-score, and clustering separability/compactness measures (e.g., intra/inter-cluster distance, silhouette score).
Main Results
Classification Accuracy and Prompt Sensitivity
The head-to-head evaluation decisively indicates that generative VLMs, particularly Qwen2.5-VL series, achieve higher zero-shot classification accuracy and F1 than their embedding-based counterparts on this realistic document classification task. Specifically, Qwen2.5-VL-72B with an advanced CoT "plus" prompt yields 82% accuracy and macro F1, outperforming the best embedding baseline (QQMM) by nearly 20 points.
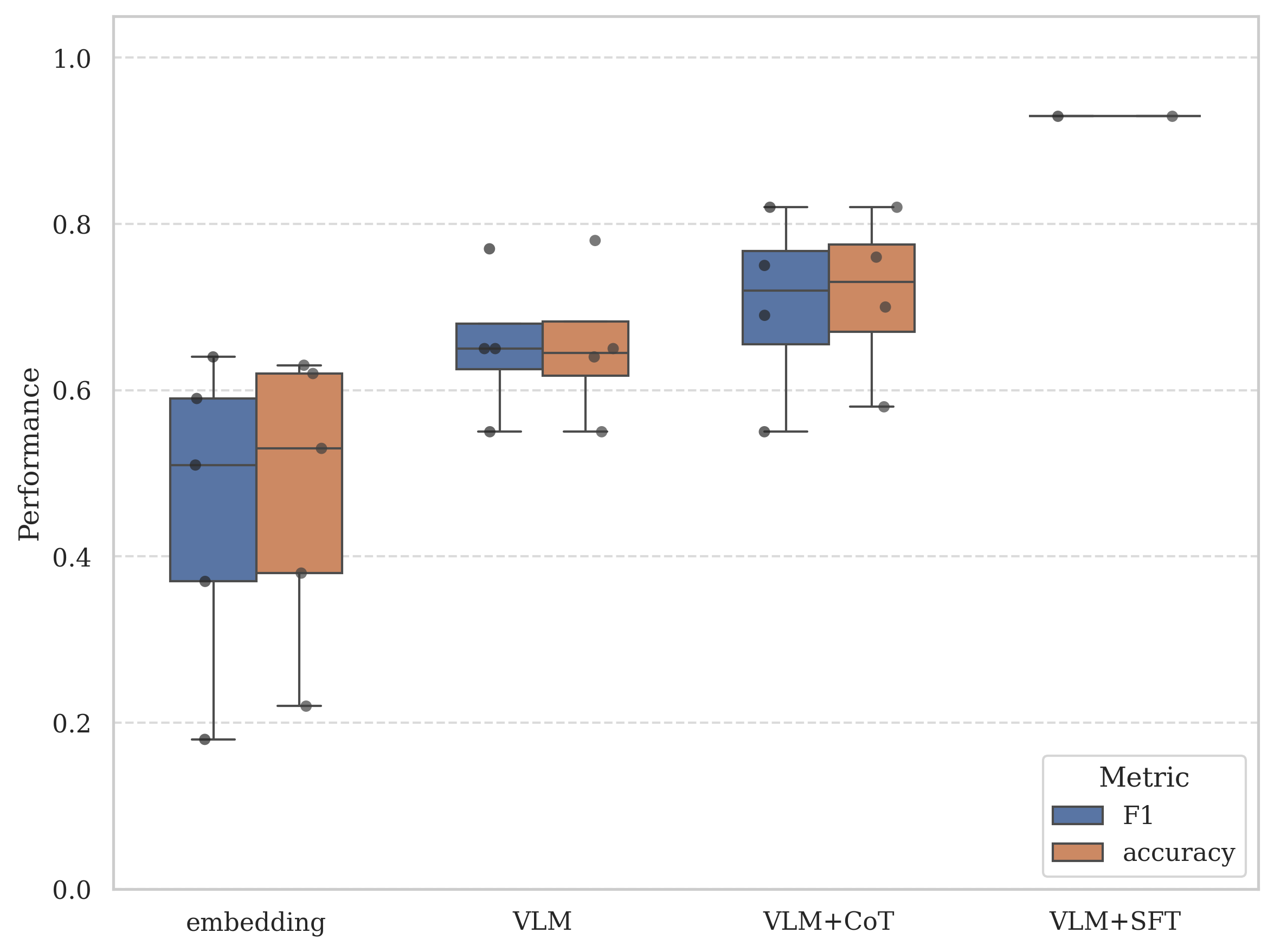
Figure 1: Classification performance for both embedding and VLMs under various configurations. VLMs generally outperform embedding models, especially after fine-tuned with sufficient training samples. Dots are individual models' results.
Prompt engineering is unequivocally effective. Class definition prompting boosts QQMM's F1 from 0.55 to 0.64; CoT-style prompting uplifts Qwen2.5-VL-7B's F1 by 10 points. These gains underscore the insufficiency of vanilla zero-shot interaction and highlight the importance of incorporating domain knowledge through prompt design.
Fine-Tuning and Data Imbalance
SFT on the VLM substantially improves classification for head classes (F1/accuracy of 0.93 for classes with >150 samples); however, it introduces pronounced degradation on tail classes (<100 samples), underscoring the risk of overfitting and the persistent challenge of imbalanced industrial datasets. Thus, domain adaptation is promising but nontrivial; rigorous data curation remains a bottleneck.
Generative VLMs realize superior end-to-end performance but at the cost of significant inference resource overhead and occasional nondeterminism, complicating deployment at operational scale where reproducibility and throughput are critical. In contrast, embedding-based models deliver deterministic, lightweight inference suitable for batch scenarios and resource-constrained environments, albeit with lower ultimate accuracy.
Theoretical and Practical Implications
The empirical results highlight that contemporary generative VLMs possess a substantial advantage for complex, multimodal industrial document triage tasks, primarily through deeper image-text layout integration and contextualized prompt-conditioned reasoning.
Practically, engineering robust prompts or templates is as vital as model selection, offering substantial gains with minimal computational burden. Nevertheless, the clear sensitivity of SFT to class imbalance raises unresolved issues regarding robust generalization and the need for future research on data augmentation, re-weighting, and curriculum training techniques.
From a system design standpoint, a hybrid architecture leveraging lightweight embedding models for large-scale, resource-sensitive pre-filtering—followed by VLM reranking or "hard" instance validation—could offer pragmatic balance between accuracy and cost.
Future Directions
- Data Imbalance Mitigation: Algorithms for low-shot/long-tail fine-tuning need to be developed to stabilize SFT performance across class distributions.
- Prompt Automation: Methods for automated, dataset-specific prompt synthesis could further lower user burden and enhance reproducibility.
- Resource-Efficient VLMs: Research in distillation or model compression for VLMs may make their deployment more attractive for production-scale applications.
Conclusion
This paper presents robust evidence that generative VLMs, especially those enhanced with CoT prompting, decisively outperform embedding-based approaches for multimodal document classification in real-world, OCR-noisy, visual/textual hybrid archives. However, these benefits are counterbalanced by resource and determinism limitations. Prompt engineering materially improves both paradigms. SFT enables state-of-the-art results under balanced data, but head-tail disparity persists. Results point to best practices for deployment and future research toward scalable, robust document understanding systems in industrial AI (2604.04997).

