- The paper introduces a paradigm shift from heuristic extraction to transformer-based autoregressive models for crafting emotionally resonant video trailers.
- It presents a taxonomy spanning heuristic, affective, graph-based, and LLM-orchestrated pipelines, emphasizing narrative coherence and optimized shot sequencing.
- Empirical results demonstrate that the Trailer Generation Transformer outperforms previous methods on metrics like F1 overlap and Levenshtein distance, impacting industrial content creation.
Introduction
The landscape of automatic video trailer generation has transformed fundamentally, progressing from heuristic extraction and shallow signal processing to the application of deep generative modeling, multimodal orchestration, and foundation models. "Generative AI for Video Trailer Synthesis: From Extractive Heuristics to Autoregressive Creativity" (2604.04953) offers a comprehensive technical account of this shift, proposing a refined taxonomy for the field and scrutinizing both technical advances and their industrial, economic, and ethical ramifications. The work distinguishes itself from general video summarization, highlighting trailer synthesis as a uniquely adversarial and narrative-driven process requiring optimization for persuasive engagement rather than maximal information coverage.
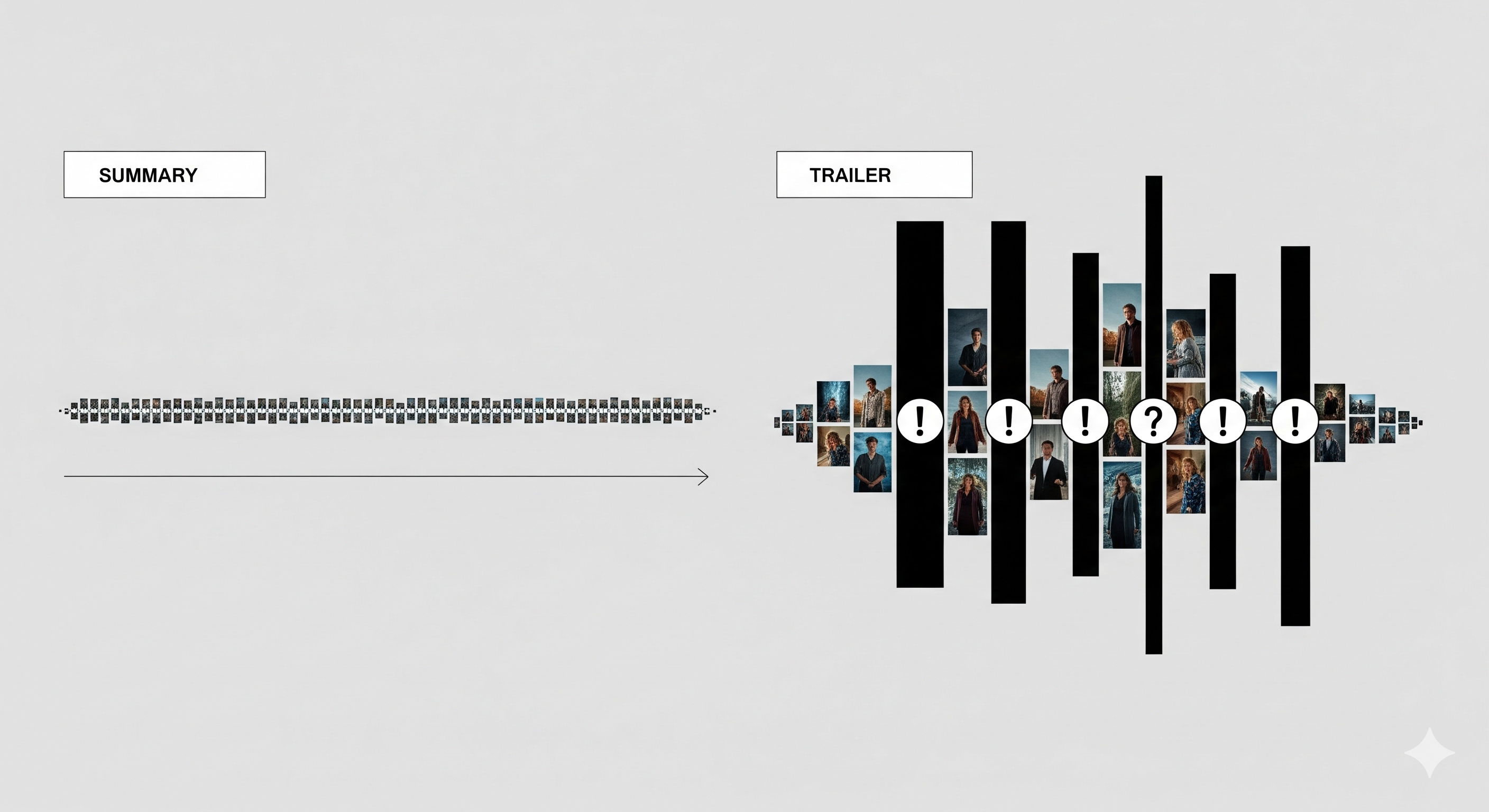
Figure 1: Video summarization condenses content for coverage, whereas trailer generation selects and sequences emotional beats for persuasive engagement.
The paper rigorously differentiates trailer synthesis from video summarization through formal problem statements—emphasizing that trailers seek to maximize engagement and emotional resonance within temporal and ordering constraints, in direct contrast to the coverage-minimization objectives of summaries. This divergence necessitates distinct modeling approaches and loss functions: while summarization penalizes redundancy and prioritizes chronology, trailer synthesis may deliberately repeat motifs or reorder scenes to craft tension and narrative arc.
The taxonomy delineated includes:
- Heuristic: Rule-based extraction leveraging motion, audio signals.
- Affective/Saliency: Use of gaze and emotional response proxies, often implemented as point processes.
- Graph-Based: Understanding narrative structure via GCNs and domain-specific beat alignment.
- LLM-Agent: Multistage, planning-centric systems orchestrated by LLMs and CLIP-like models.
- Autoregressive: Transformer-based models directly optimizing for trailer shot sequence generation.
- Foundation/Diffusion: State-of-the-art text-to-video generative modeling (e.g., Sora, Veo 2).
Pre-Generative Methodologies: Affective Models and GCNs
Initial generations of trailer generation systems emphasized quantifying "attractiveness" at the shot or sub-shot level. Affective modeling, as exemplified by fixation variance and self-correcting point processes [37], used physiological surrogates to detect moments likely to elicit viewer focus and attention decay. The mathematically principled approach of self-correcting point processes models viewer boredom and stimulus as interacting temporal intensities, capturing the necessary rhythm of high-impact trailer editing.
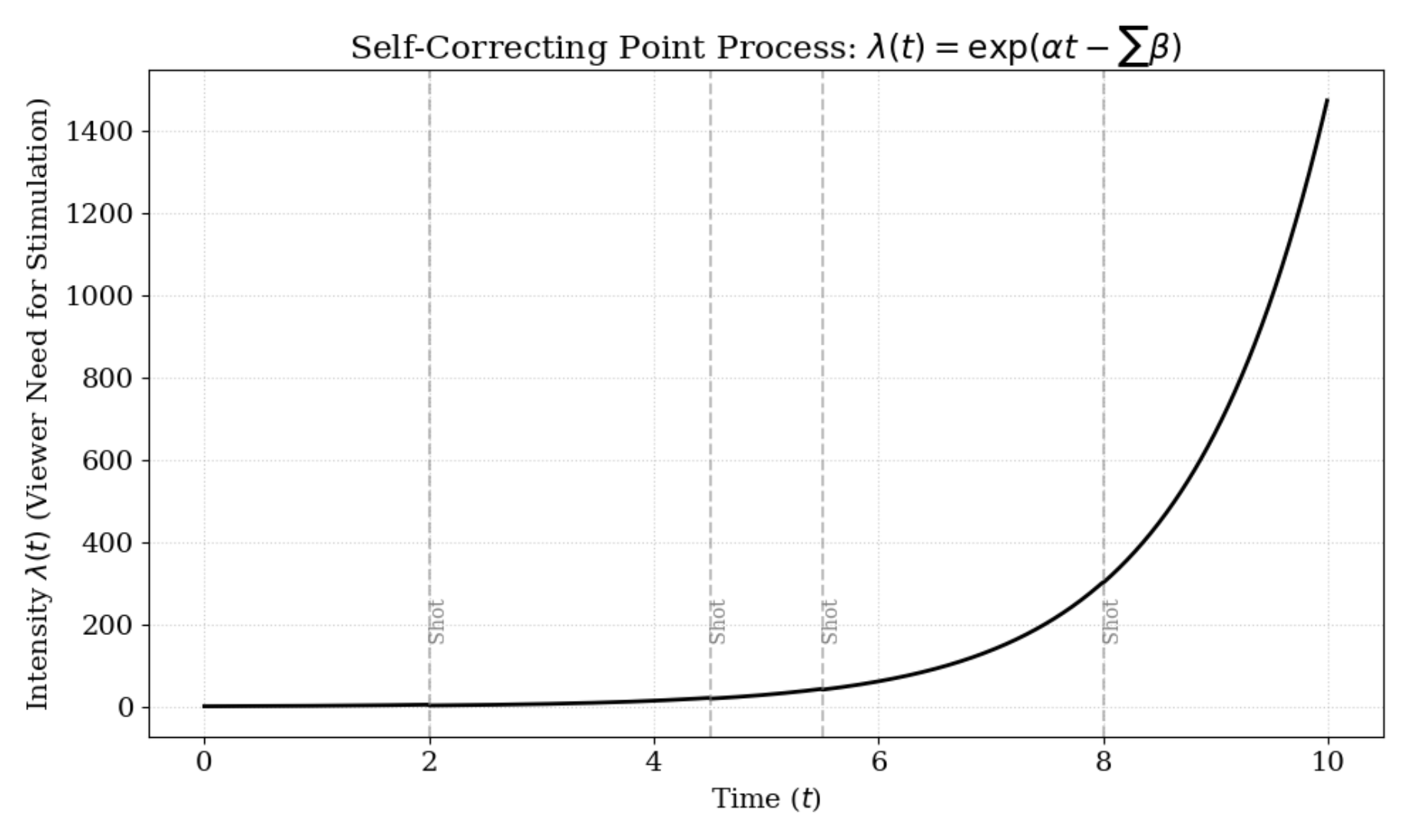
Figure 2: The self-correcting point process models rising attention intensity, which decays with the occurrence of engaging trailer-worthy events.
Graph-based approaches augment local saliency by imposing constraints informed by screenwriting and cinematic theory (e.g., the "Save the Cat" beat sheet), operationalized via GCNs that model topological shot relationships [3]. Stratified sampling across narrative beats ensures coherent, non-redundant structural arcs, counteracting the tendency of affective models to overrepresent short-term excitement at the expense of overarching narrative logic.
LLM-Orchestrated Multistage Generative Pipelines
The contemporary generative phase is characterized by LLM-orchestrated frameworks. These pipelines utilize modular reasoning and prompt-based control: segmenting source narratives, retrieving semantically corresponding visuals (via models such as CLIP), synthesizing original voice-over scripts, and generating genre-aligned music tracks with text-to-audio models. LLMs act not as passive selectors but as active scriptwriters and narrative planners, enforcing anti-spoiler constraints and allowing for content-aware orchestration beyond signal-level analysis [8]. This modularity enables hybrid human-AI co-editing scenarios, particularly essential in domains demanding compliance and precise narrative control, e.g., educational and factual content generation.
Transitioning toward fully differentiable architectures, models such as the Trailer Generation Transformer (TGT) [9] recast trailer synthesis as a sequential, autoregressive modeling problem. The TGT framework integrates trailerness scores as attribute-aware embeddings, contextually encodes the full movie with self-attention, and utilizes a decoder to generate ordered shot sequences. This enables the model to learn and reproduce the editing "grammar" underlying professional trailer cuts—handling complex, non-chronological juxtapositions and ensuring narrative continuity.
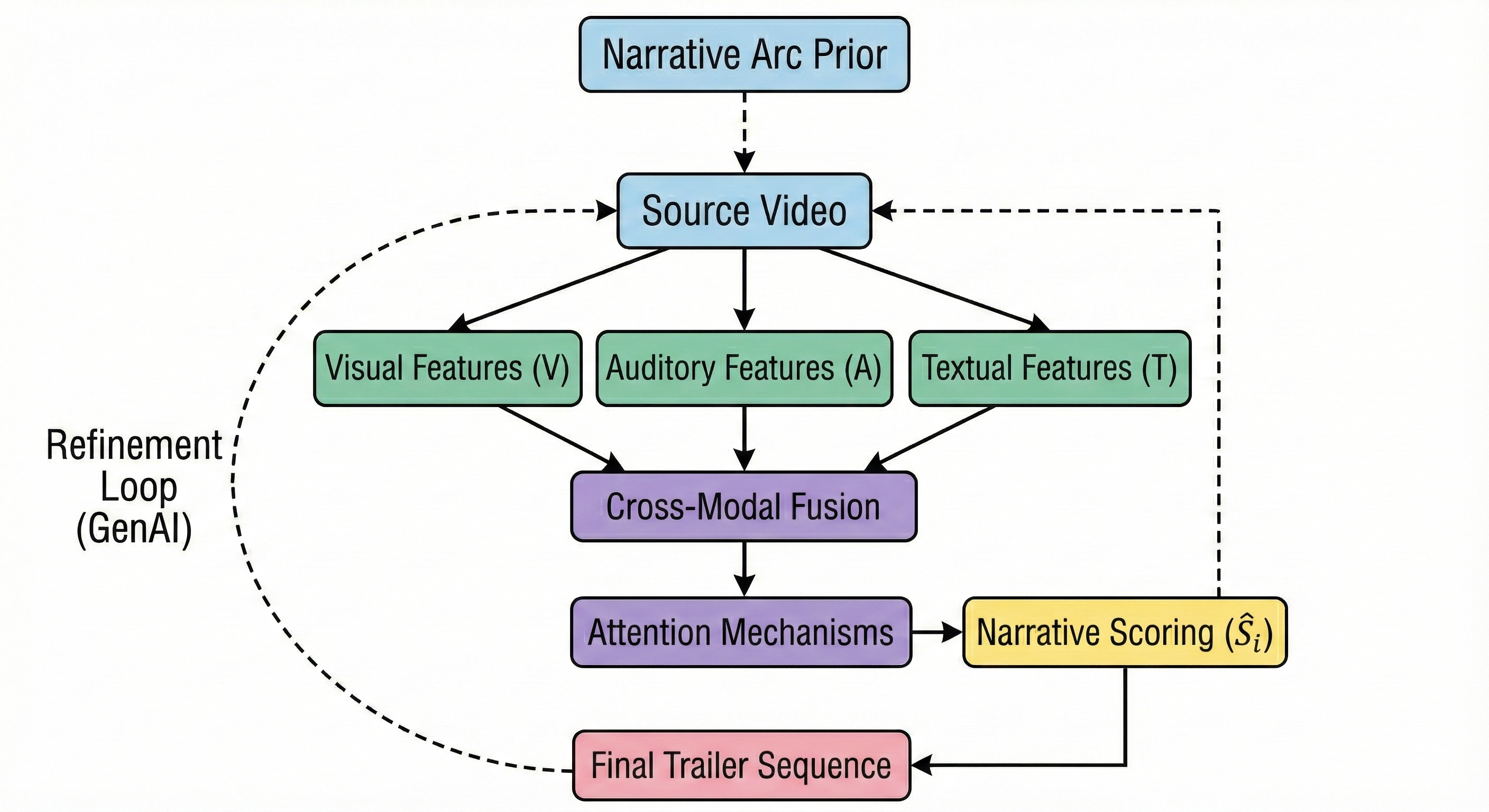
Figure 3: Block diagram for the Trailer Generation Transformer, comprising trailerness encoding, contextual self-attention, and an autoregressive trailer decoder.
Empirical evaluation demonstrates strong performance: TGT outperforms prior methods on F1 overlap and Levenshtein distance against human-edited sequences on standard datasets, quantifying its superiority in both content selection and shot ordering.
Foundation Models for Generative Trailer Creation
The advent of text-to-video foundation models—OpenAI’s Sora, Google’s Veo 2, Meta’s MovieGen—fundamentally redefines the generative landscape. These diffusion-based models generate temporally and physically plausible video from textual prompts, supporting creative fill-in for missing narrative shots, style transfer, and domain-consistent upscaling. However, the central research challenge is to constrain their creativity: precise adherence to input narrative, minimization of hallucinated or misleading content, and domain-specific factuality.
Economic and Industrial Implications
Automated trailer generation impacts content velocity and accessibility on major UGC platforms. The technology democratizes promotional video editing, enabling micro-creators to rapidly generate compelling shorts and teasers, previously achievable only by skilled editors. However, scaling inference to billions of videos incurs significant compute cost, necessitating optimization strategies such as model distillation, quantization, and edge-compute deployment. In addition, data-driven trope mining enables highly personalized, genre-specific trailer variants, maximizing click-through and recommendation rates.
Evaluation Metrics and Protocols
Evaluating the output of generative systems is intrinsically multi-objective. The paper proposes a composite scheme evaluating:
- Fidelity: Overlap and similarity metrics, updated via Fréchet Video Motion Distance for generative-only (non-retrieval) outputs.
- Narrative Coherence: Alignment to screenwriting beats and story arcs, assessed via beat alignment and LLM-based coherence scoring.
- Multimodal Synchronization: Alignment between visual edits, soundtrack, and synthesized voice-over (quantified with metrics such as AV-Sync and BERTScore).
- Safety and Hallucination Control: Factuality scores and bias checks to minimize deceptive or sensational output, essential in non-fiction and regulated domains.
Implications and Future Directions
The shift toward generative AI enables full-stack creative control, from visual editing to voice and music composition. Theoretical advancements include expanded notions of "narrative grammar" learned via Transformers incorporating graph/beat structures, new composite evaluation metrics for creativity and appropriateness, and improved alignment controls for semantic consistency. Economic sustainability requires further innovation in model optimization.
Critical emerging research topics include:
- Narrative-aware attention mechanisms bridging graph beats and autoregressive modeling.
- LLM-driven evaluators for subjectivity and narrative flow.
- Consistency alignment protocols ensuring truthfulness and preventing misrepresentation.
- Provenance tracking for robust attribution and editorial transparency in AI-generated content.
Conclusion
The paper delineates the technical progression and current frontiers of AI-driven video trailer synthesis, evidencing a transition from mere extraction and summarization to fully generative, controllable, and personalized composition. Advances in LLM orchestration, Transformer-based sequence modeling, and foundation-scale diffusion architectures have established new standards for automation and creativity in narrative video editing, with corresponding economic and ethical considerations driving industrial adoption and future research agendas.

