- The paper demonstrates that TabPFN maintains robust predictive performance despite noise, irrelevant feature injection, and moderate label corruption.
- The study employs controlled synthetic binary classification tasks to quantify attention metrics using KL-divergence, embedding geometry, and SHAP attributions.
- Empirical results show that attention specialization and distinct feature-token embeddings consistently prioritize informative signals over noise.
Noise Robustness in Tabular Foundation Models: An In-Depth Evaluation of TabPFN's Internal Mechanisms
Introduction
This paper provides a systematic and fine-grained analysis of robustness properties in TabPFN, a tabular foundation model leveraging in-context learning (ICL), with a focus on its attention mechanisms under a range of noise and data corruption scenarios (2604.04868). The study targets challenges not only in predictive performance but also in the reliability and interpretability of TabPFN's internal feature selection and attribution in environments where irrelevant features, correlated predictors, sample size variation, and label noise are prevalent. This evaluation directly addresses an underexplored aspect in the empirical study of tabular foundation models (TFMs): the relationship between internal model diagnostics (specifically, attention signals and derived feature importance) and external robustness to real-world data imperfections.
Controlled Experimental Design and Evaluation Metrics
The methodology relies on controlled synthetic binary classification tasks where data properties can be precisely modulated. Four axes of perturbations are explored:
- Dataset width: Addition of large numbers of irrelevant (random) or redundant (nonlinearly correlated) features.
- Sample size: Increasing the number of available training rows.
- Label quality: Varying the proportion of randomly flipped labels.
The evaluation paradigm is dual: classical predictive performance (ROC-AUC on held-out data) is tracked in tandem with internal diagnostics—attention concentration (KL-divergence-based metrics), attention-based feature ranking, feature-token embedding geometry, and SHAP-based attributions.
Internal Mechanisms: Attention Specialization and Representation Dynamics
TabPFN exhibits characteristic attention dynamics as input passes through successive transformer layers. In early layers, attention is diffuse and label-focused; progression through the model yields increasing concentration on the informative features, demarcating signal from noise effectively (Figure 1). The model’s feature-token embeddings become progressively disentangled, with informative features forming distinct clusters separated from random features by the final layers (Figure 2).
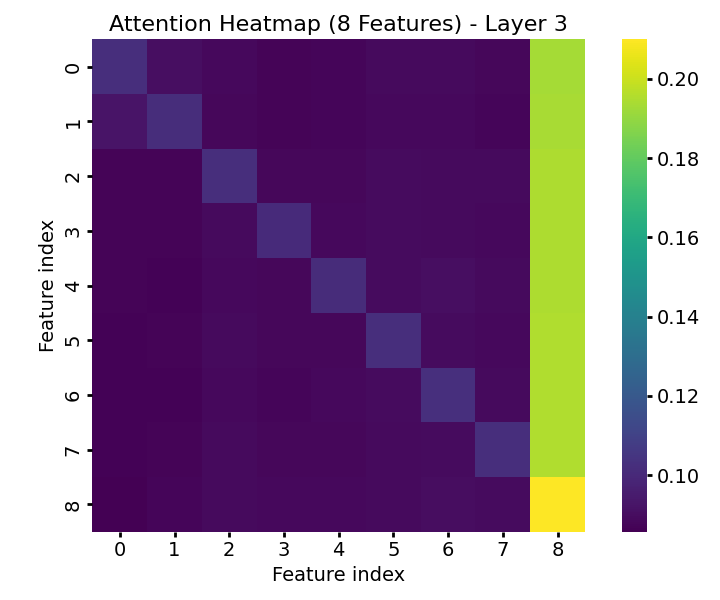
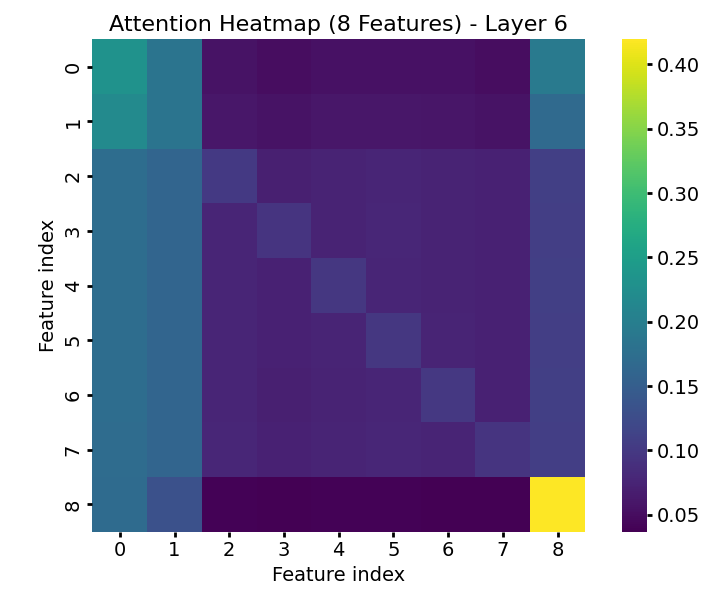
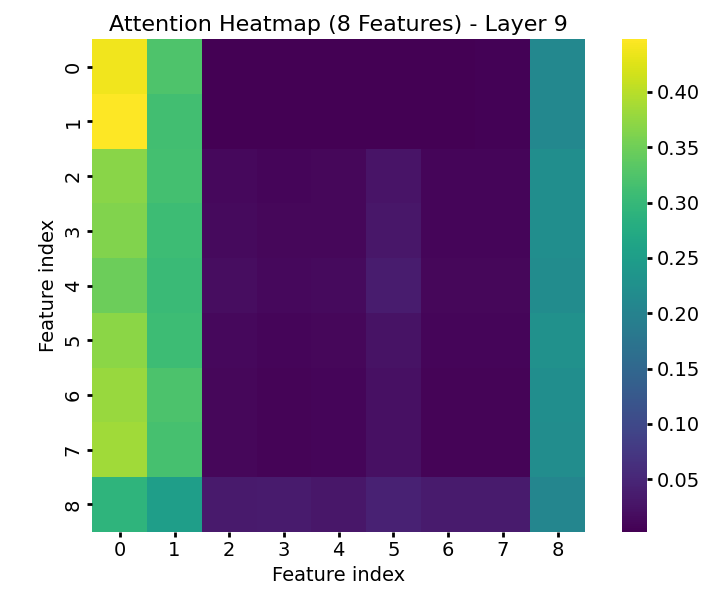
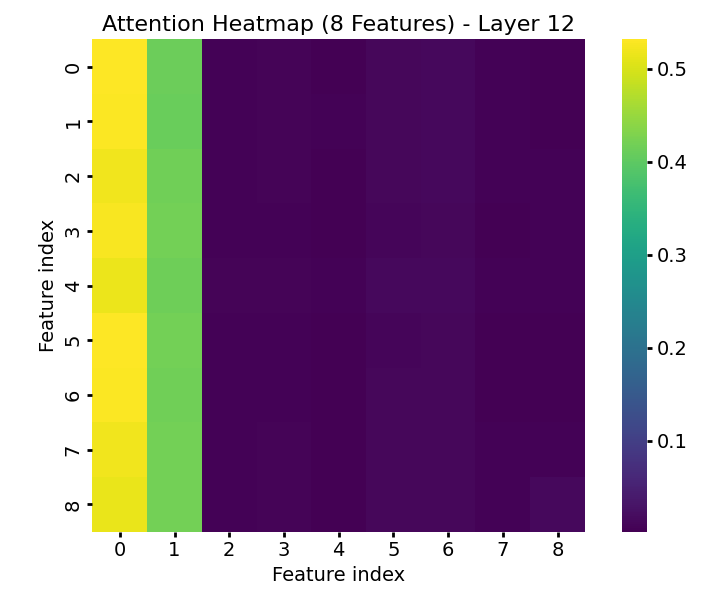
Figure 1: Feature-wise attention weights in TabPFN across transformer layers, illustrating progressive focus on informative features.
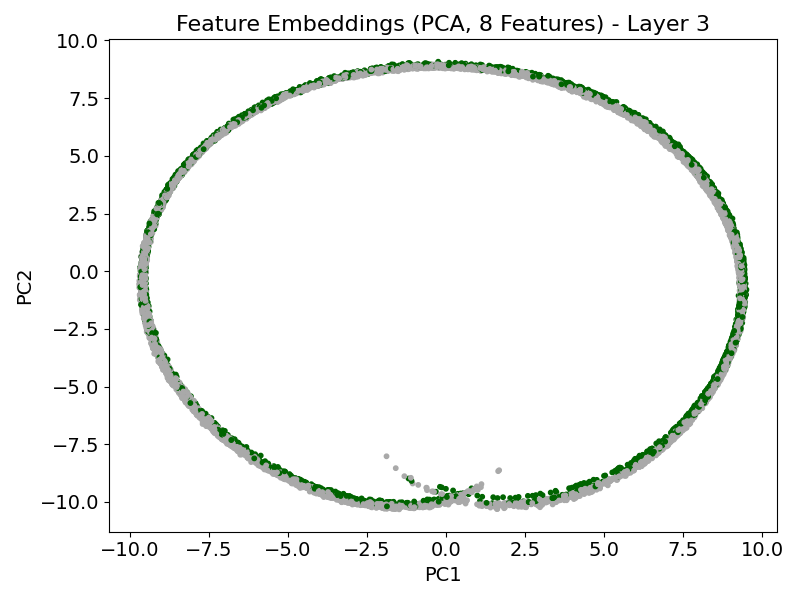
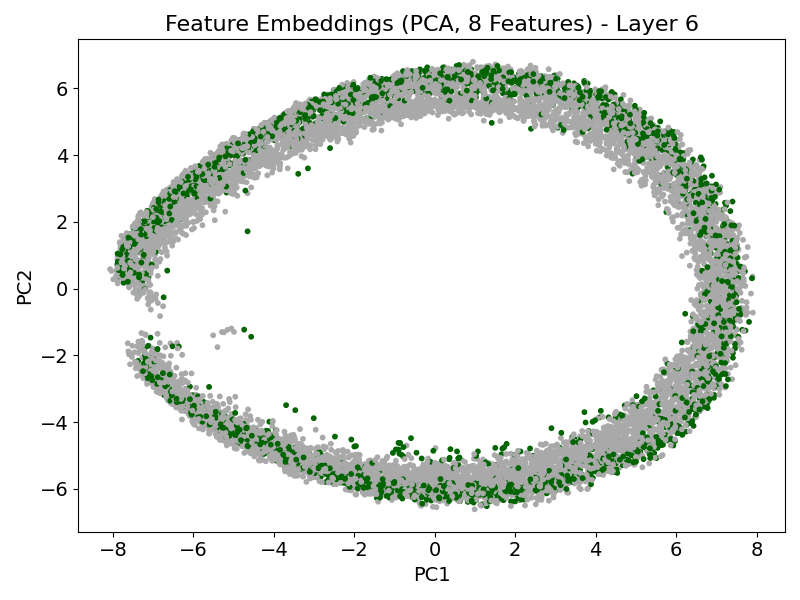
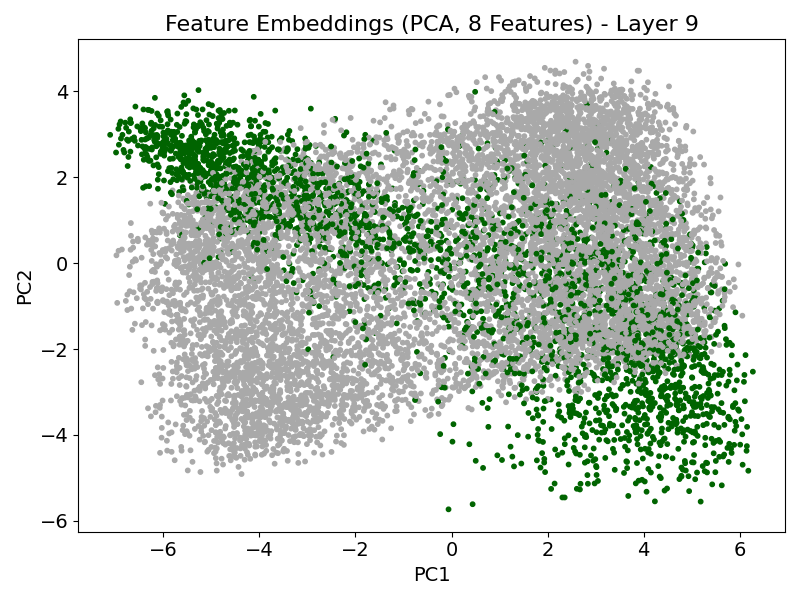
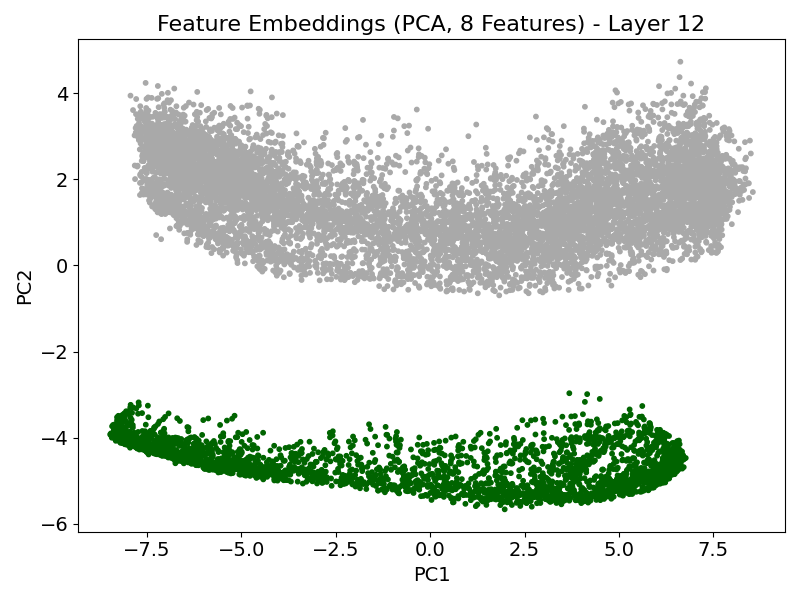
Figure 2: PCA projection of feature-token embeddings showing emergent geometrical separation between informative and non-informative features across layers.
Alignment between attention allocation and SHAP-based importance confirms that features prioritized by internal mechanisms drive model predictions, with negligible attribution to irrelevant variables (Figure 3).
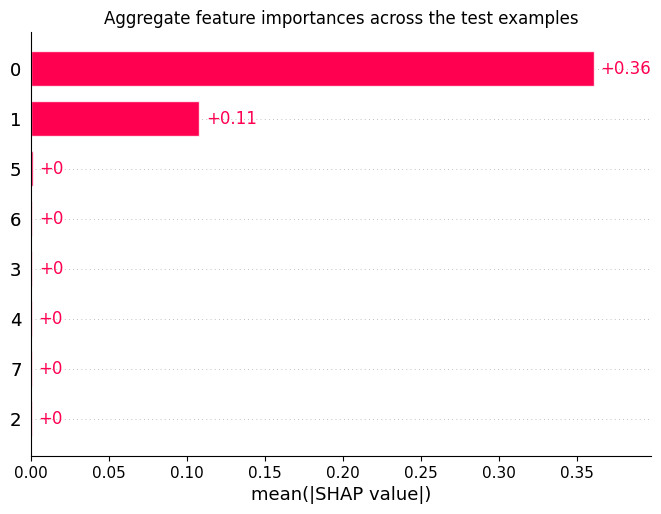
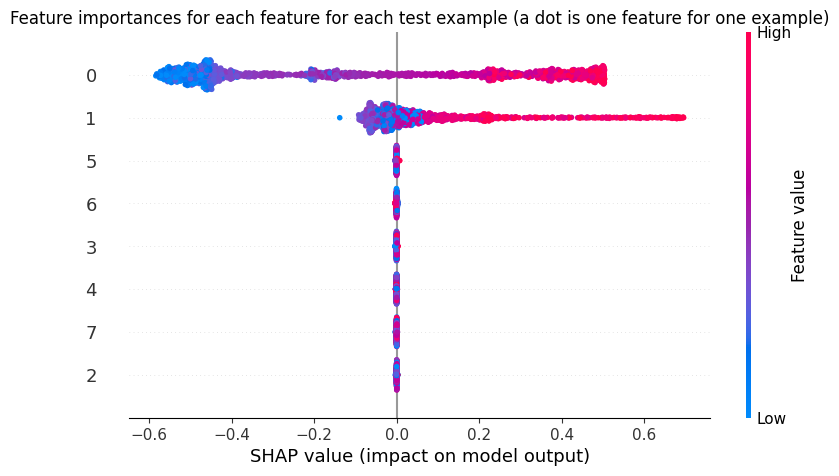
Figure 3: SHAP plots for a baseline case—the two informative features dominate global and per-sample importance, consistent with attention heatmaps.
Robustness to Dimensionality Expansion
Irrelevant Feature Injection
Increasing feature dimensionality up to 512 via the injection of random (uninformative) features does not degrade predictive performance—ROC-AUC remains virtually constant. Internal diagnostics reveal the model continues to focus sharp, non-uniform attention on informative features, with only a moderate relative decrease due to denominator effects. KL-based attention metrics indicate strong deviation from uniform allocation. Critically, attention-based ranking consistently places informative features atop the ranking, even as feature clutter increases (Figure 4). Visualizations further corroborate that only the initial informative features absorb significant attention mass (Figure 5).
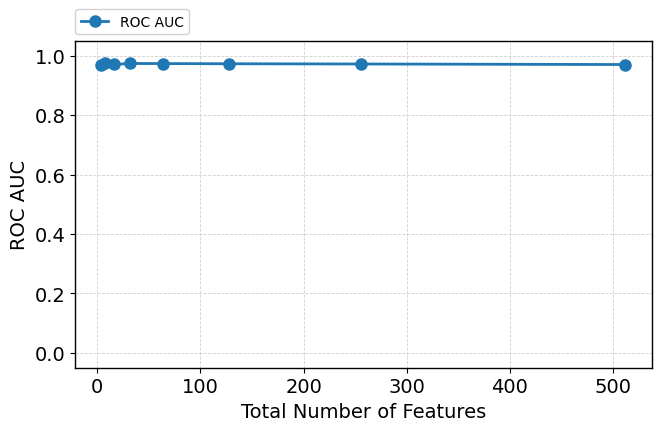
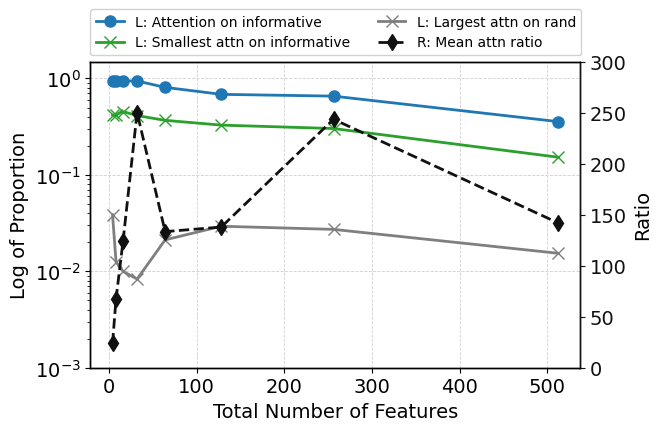
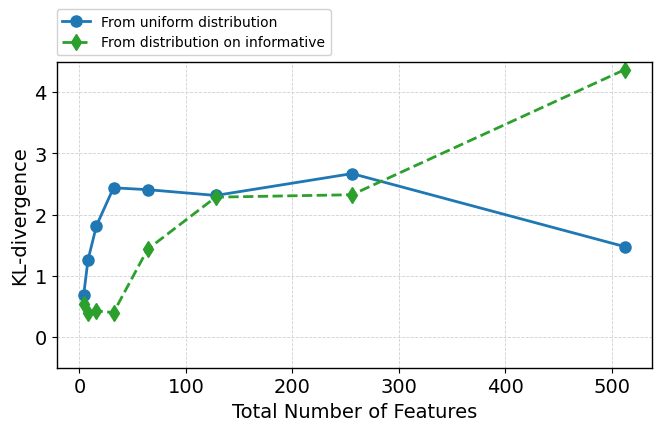
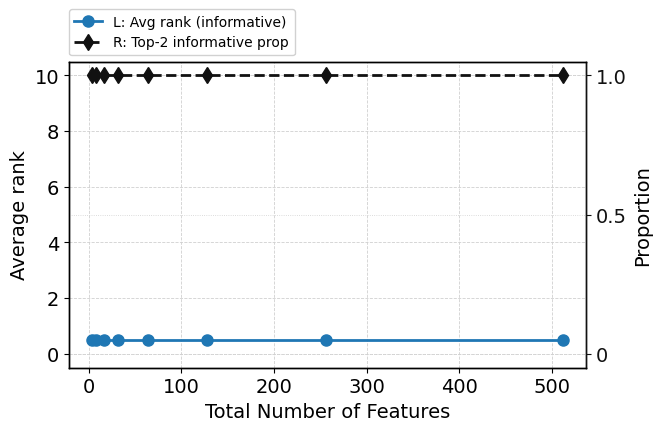
Figure 4: TabPFN performance and attention metrics as number of random features grows—ROC-AUC stable, attention focus and ranking metrics robust.
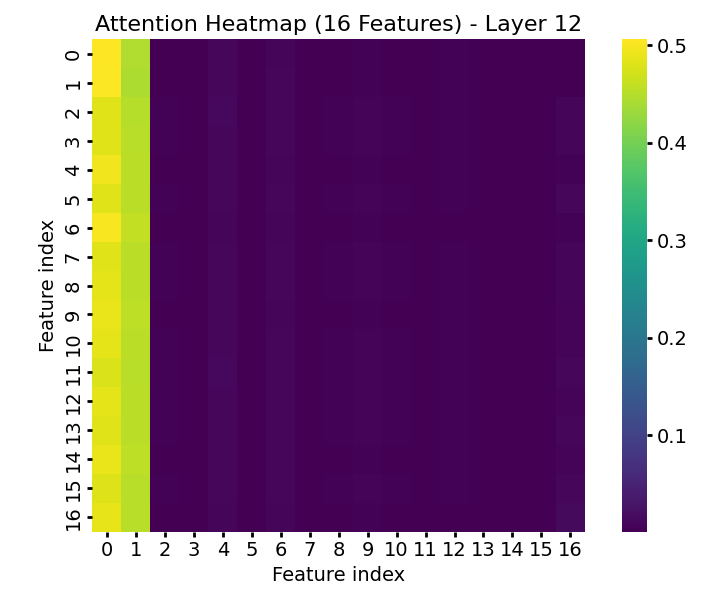
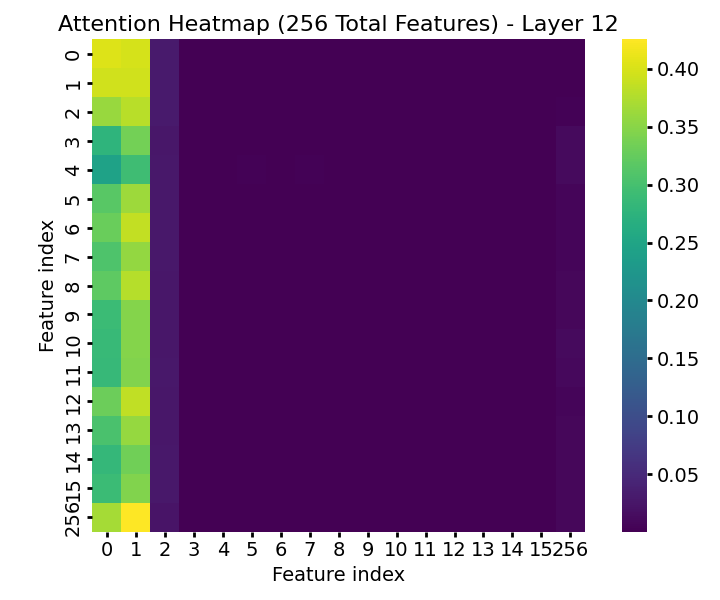
Figure 5: Attention in the final layer when the table is wide—concentration on informative features persists even with 256 features.
Augmentation with nonlinearly correlated features—statistically entangled but not purely redundant—poses a subtler challenge. While ROC-AUC remains high, attention becomes distributed among both informative and correlated features. KL-divergence relative to various hypothetical distributions quantifies this soft competition; correlated features increasingly share attention, and occasionally displace informative ones from top rankings (Figure 6).
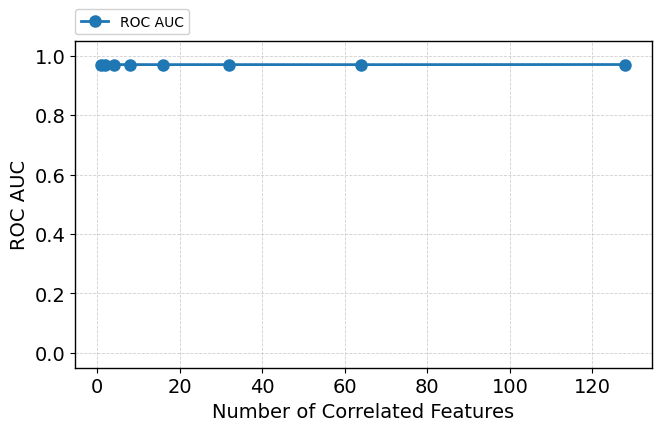
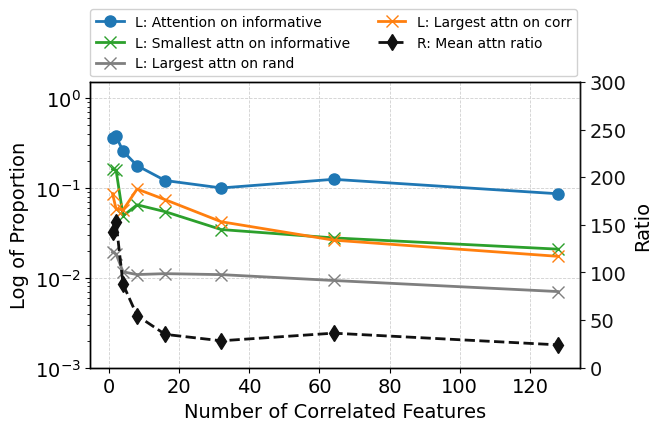
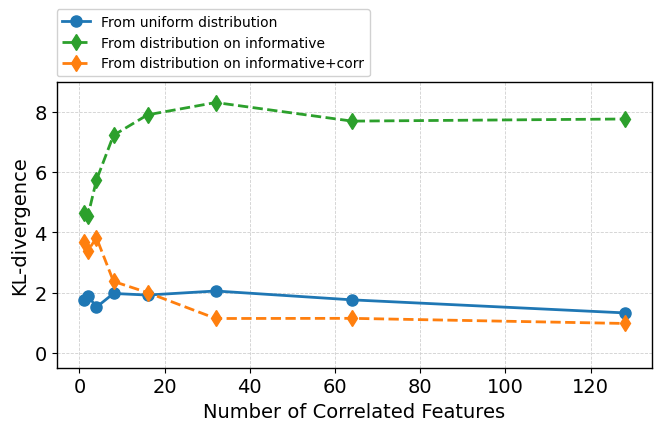
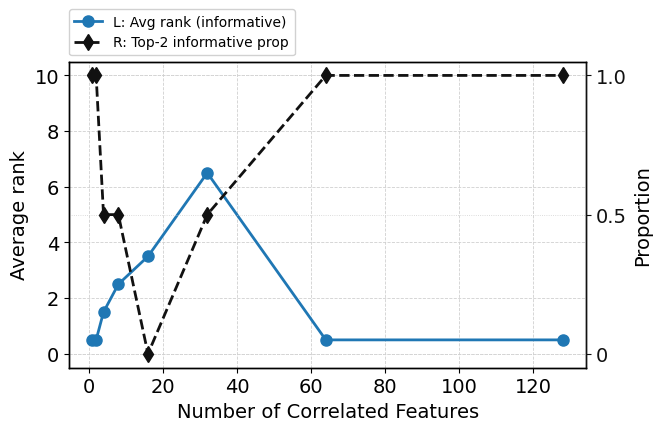
Figure 6: As number of correlated features grows, informative and correlated features compete for attention but overall predictive performance (ROC-AUC) remains unaffected.
SHAP attribution reflects this internal redistribution: the most strongly correlated features share high importance, and in some cases an informative feature is no longer among the top two by SHAP or attention metrics (Figure 7).
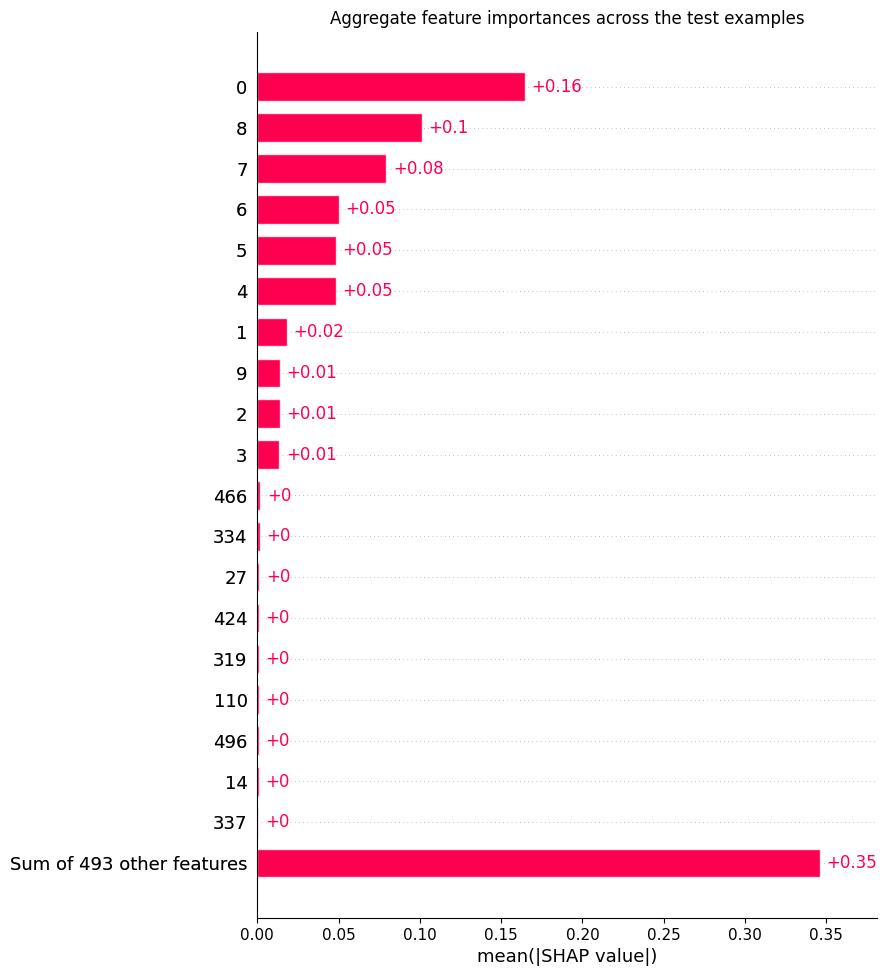
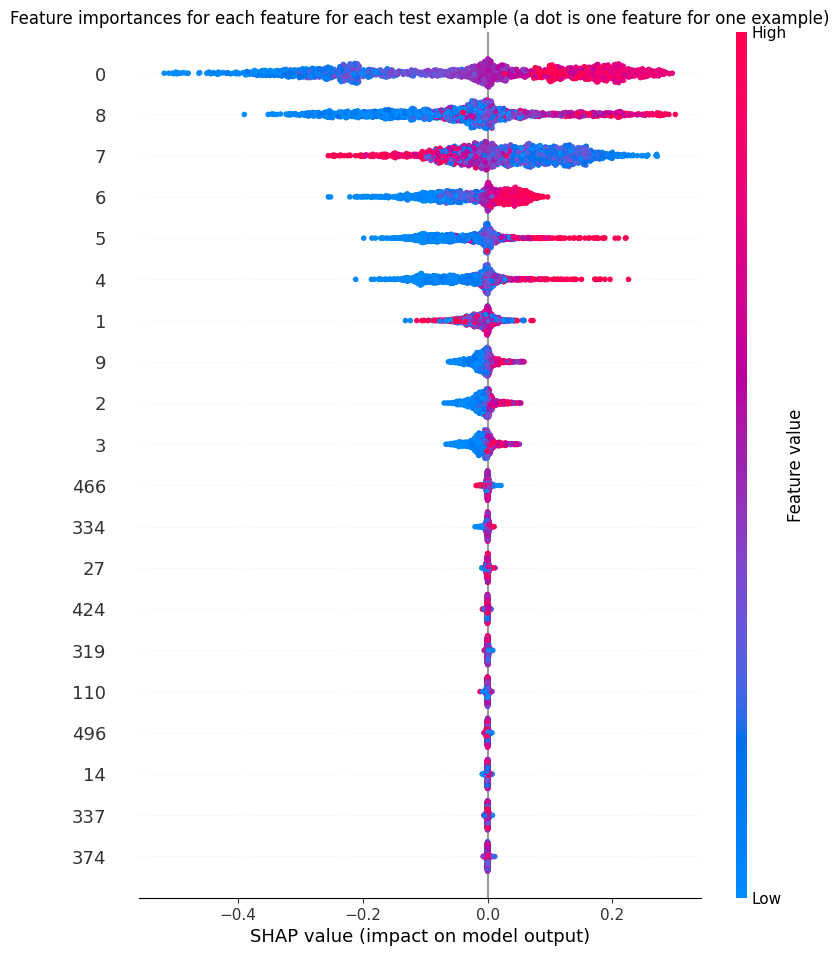
Figure 7: SHAP plots with 8 correlated features—the primary informative feature dominates, others drop in importance as correlated features compete for attribution.
Robustness to Increasing Sample Size
Scaling the number of training examples from 1,500 to 12,000 does not affect ROC-AUC or undermine attention focus. Structured attention concentration persists, informative features remain dominant in rankings, and embedding separation becomes more pronounced in deeper layers (Figure 8; see also Figure 9 for qualitative attention/embedding states at high sample count).
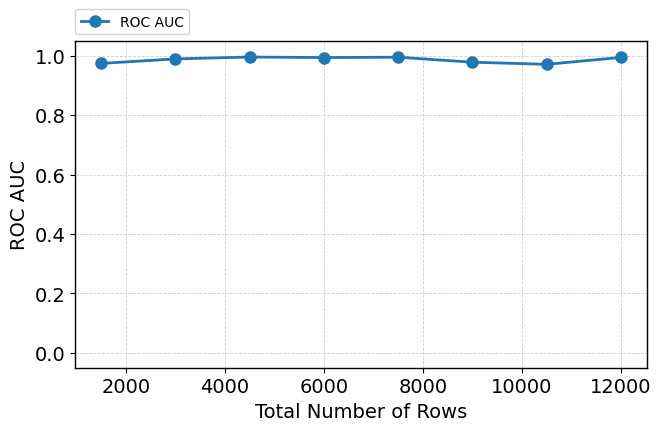
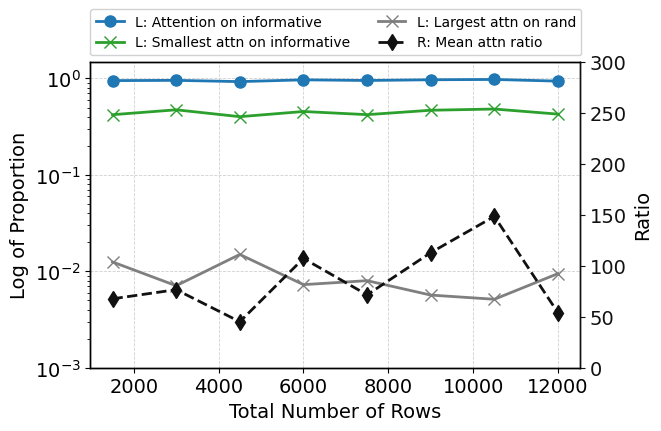
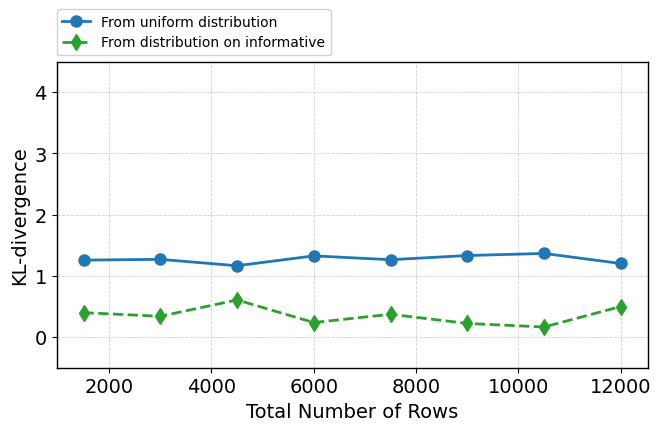
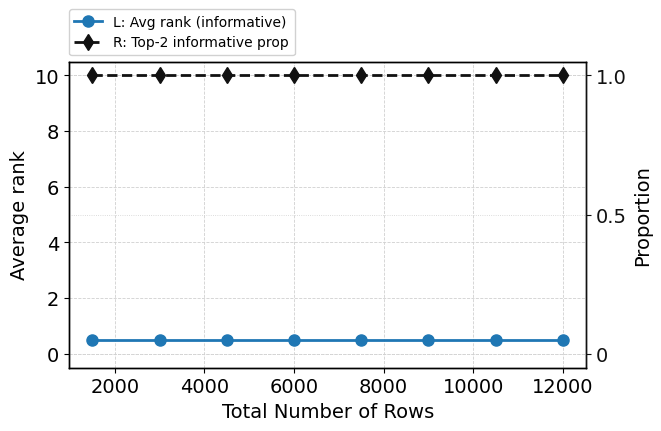
Figure 8: Robustness metrics remain stable with increasing sample size, indicating scalability of attention mechanisms and predictive calibration.
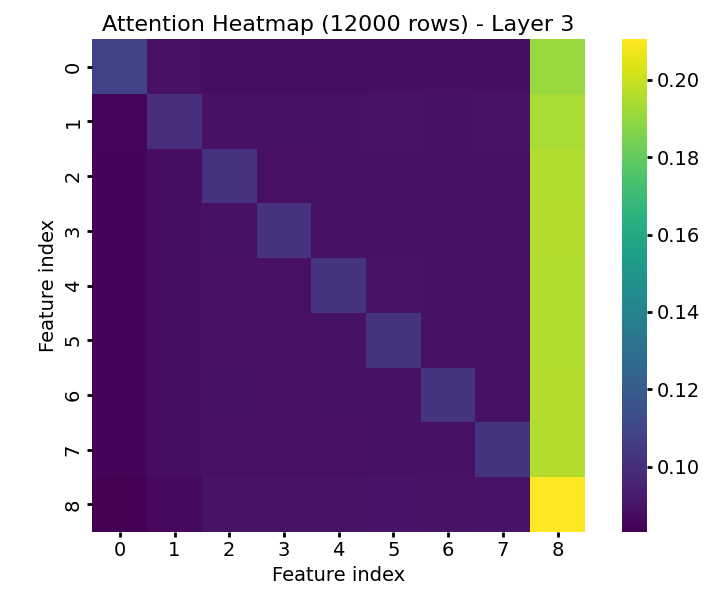
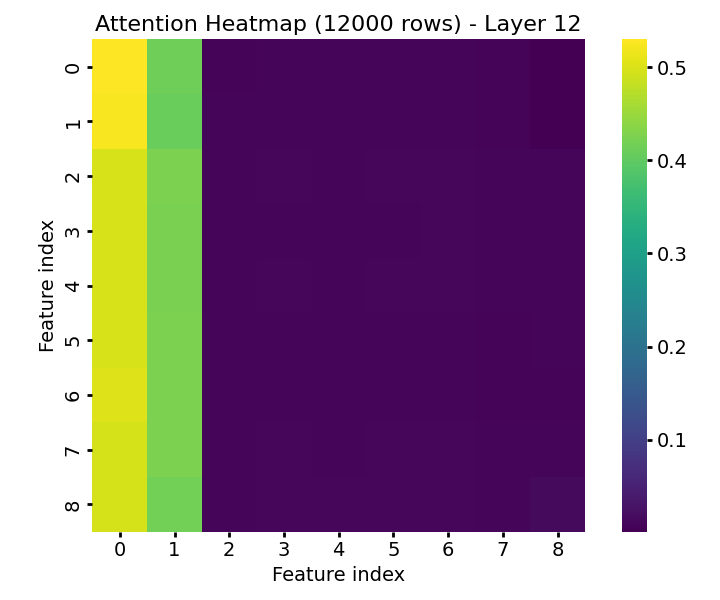
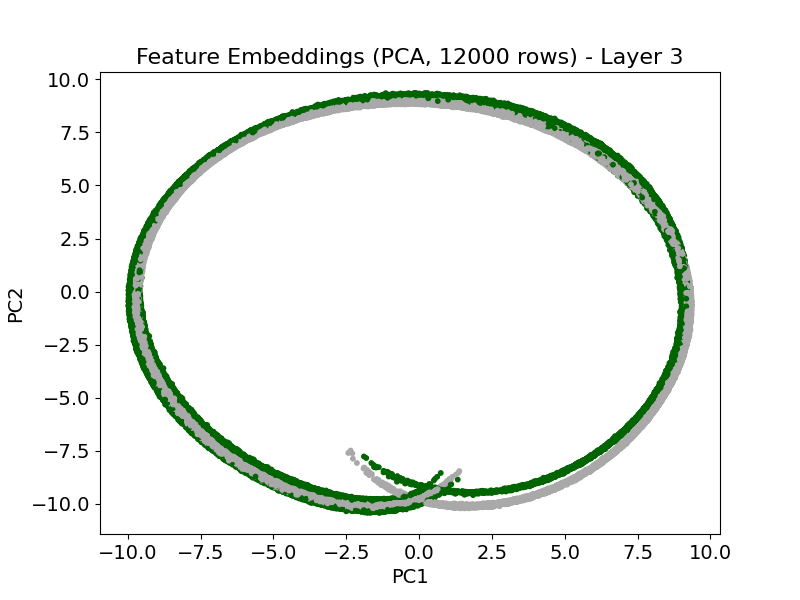
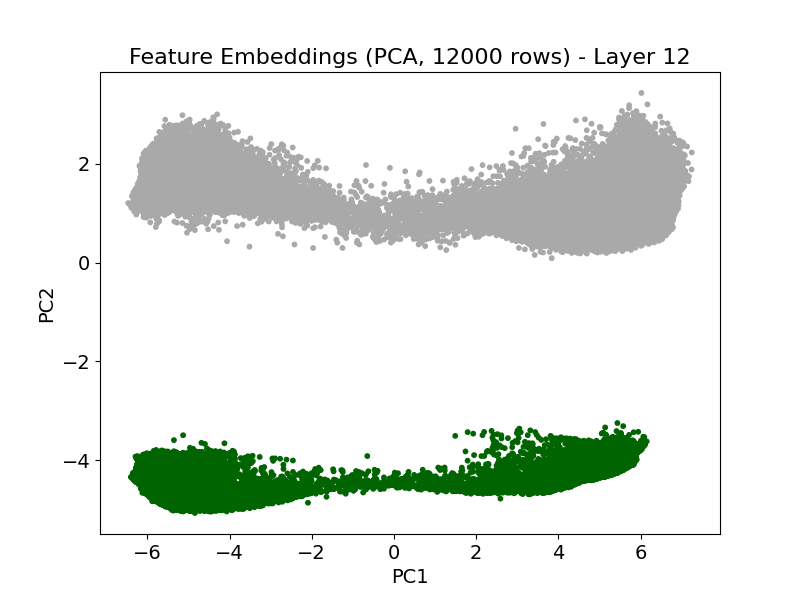
Figure 9: Attention and feature embedding visualization at high sample count—informative features maintain distinct embeddings and attract majority of attention in the final layer.
Robustness to Label Noise
Introducing up to 35% label noise leaves both ROC-AUC and attention-based prioritization of informative features substantially intact (Figure 10), demonstrating the model's tendency to discount unreliable supervision as a consequence of its pretraining and in-context inference mechanisms. Attention to the label token itself decreases when it becomes unreliable, and attention allocation among informative features can shift in response to noise (Figure 11).
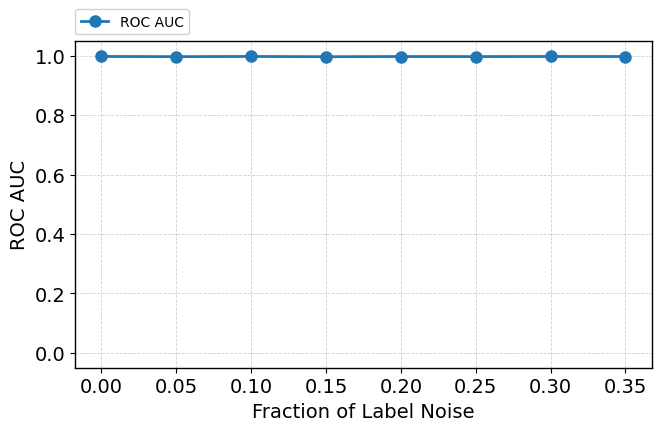
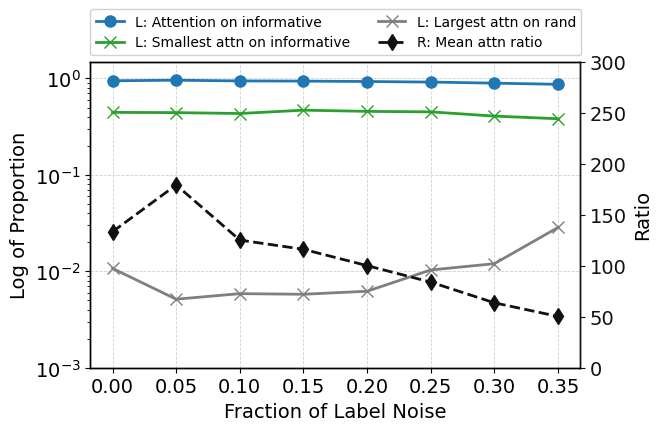
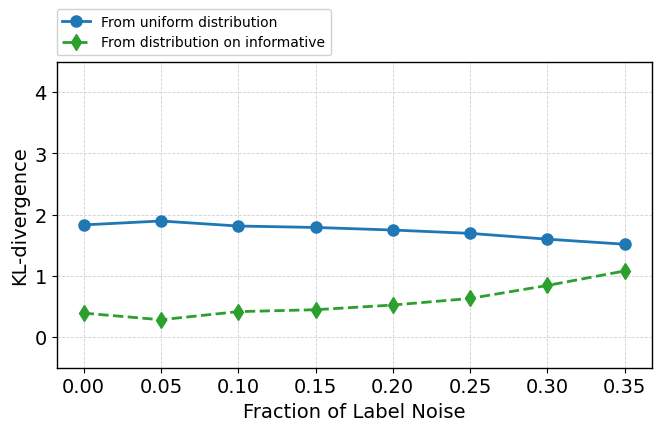
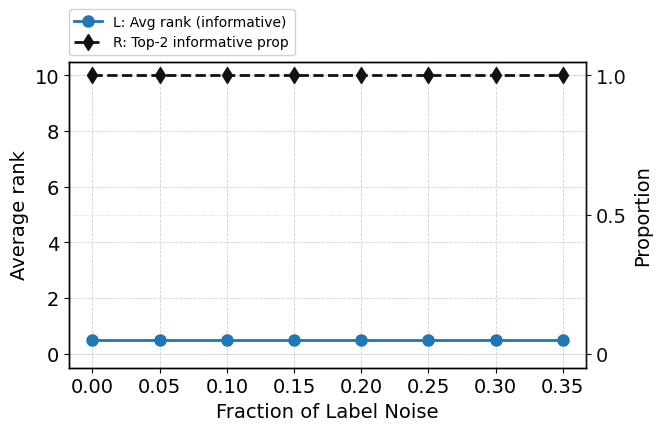
Figure 10: TabPFN performance and internal metrics as label noise increases—predictive and mechanistic robustness is retained.
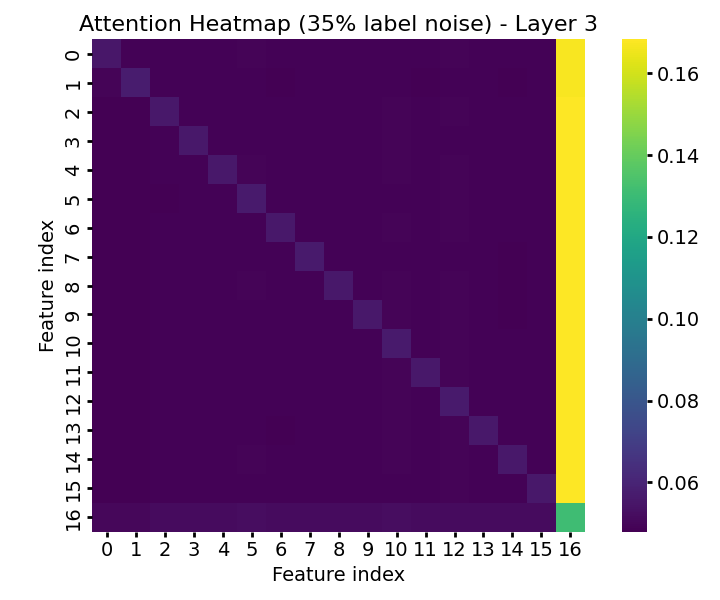
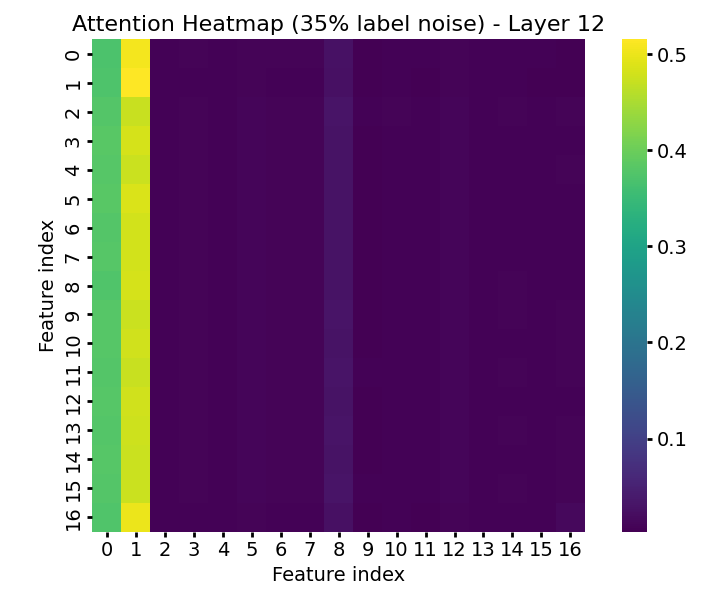
Figure 11: Layerwise attention heatmaps under heavy label noise—model reduces attention to the label and dynamically reallocates focus among informative features.
Implications, Theoretical Context, and Future Directions
The empirical results delineate a strong claim: TabPFN is robust to irrelevant feature clutter, correlated redundancy, variation in sample count, and moderate systematic label noise—both in terms of prediction and mechanistic prioritization of signal. This robustness is interpretable as a consequence of pretraining on a structural-causal-model-driven synthetic prior, which conditions the network to privilege features that are repeatedly and causally predictive, while penalizing attention to spurious correlations. The inductive bias instantiated by pretraining and by feature-tokenization (with permutation invariance) equips TabPFN with the ability to ignore features that are highly dataset-specific or random, given its optimization objective over a vast task distribution.
Competition among correlated features reveals, however, that explainability can be confounded when multiple features encode the underlying signal; the model remains robust, but attributions become distributed—complicating causal inference or regulatory justification. These phenomena, coupled with the practical realities of full matrix attention cost, delimit the present analysis to medium-scale tabular problems.
Further research should address real-world datasets, alternative synthetic priors, joint expansion in both table width and row number, and pretraining regime ablations to isolate the contribution of distinct mechanisms (causal prior, ICL, transformer architecture) to observed robustness.
Conclusion
This analysis establishes that TabPFN exhibits both predictive and mechanistic robustness when exposed to wide, noisy, and label-imperfect tabular data. Consistent and concentrated attention on informative features persists across a range of conditions, and qualitative diagnostics (embeddings, SHAP) are congruent with quantitative attention-based measures. The evidence positions TabPFN as a compelling TFM for industrial, impure tabular environments, while also highlighting the importance of internal diagnostics for true robustness assessment in foundation models for structured data.

