- The paper presents explainable ML models that outperform traditional sepsis scores by accurately predicting outcomes from a large Romanian EHR dataset.
- It shows that combining laboratory tests with diagnostic features, especially via Histogram-based Gradient Boosting, significantly boosts predictive accuracy with AUC up to 0.983.
- SHAP analysis identifies key predictors such as eosinopenia and cardiovascular markers, offering actionable insights into sepsis prognosis.
Explainable Machine Learning for Sepsis Outcome Prediction Using a Novel Romanian Electronic Health Record Dataset
Introduction and Motivation
This work presents a rigorous examination of explainable machine learning models for sepsis outcome prediction using a large-scale, single-center Romanian Electronic Health Record (EHR) dataset encompassing 12,286 hospitalizations. The cohort, derived from an 18-year period at the University Emergency Hospital of Bucharest, addresses the pronounced gap in sepsis data coverage for Central and Eastern Europe, where mortality rates remain elevated relative to Western Europe. The dataset incorporates extensive demographic, diagnostic, and laboratory data, including results from 600 distinct laboratory test types. The study pursues differential outcome prediction on sepsis patients through three binary classification tasks: Deceased vs. Discharged, Deceased vs. Recovered, and Recovered vs. Ameliorated.
The traditional paradigms for sepsis prognosis—SOFA, qSOFA, APACHE, and SAPS—are acknowledged for their limited representation of complex nonlinear interactions among physiological and comorbidity variables, restricting their applicability in high-dimensional or heterogeneous datasets. By contrast, the present work utilizes classical ML algorithms with an emphasis on explainability to formulate interpretable and accurate prediction models tailored for the Romanian clinical context.
Data Curation, Preprocessing, and Feature Construction
The study utilizes a highly curated EHR dataset, including both coded (ICD-10) and free-text diagnoses, strict demographic filters, and exclusion criteria targeting pediatric and single-day cases. The final analytic dataset links patient admission, diagnostics (compressed into 14 broad comorbidity categories), test results, and in-hospital outcome. Notably, combinatorial event sparsity is managed by ranking and selecting subsets of the most frequently performed laboratory investigations, balancing between patient coverage and feature richness (e.g., top-10 yields ∼93% coverage, top-50 yields ∼9%).
Aggregate statistics show that the dataset offers balanced demographics and outcome variables, with the majority of hospitalizations of elderly patients (mean age around 77), and a broad spectrum of hospitalization durations.
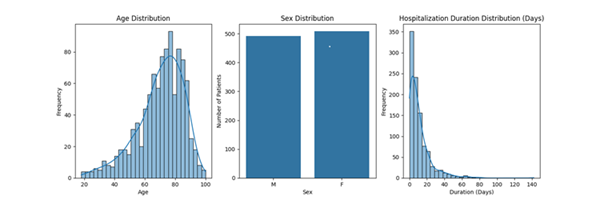
Figure 1: Age, sex, and hospitalization duration distribution in the sepsis cohort.
Laboratory time series are represented via simple mean aggregation per hospitalization episode, given the sparse sampling across patients. Diagnostic features are encoded categorically according to major organ system involvement.
Machine Learning Framework and Experimental Protocol
The methodological framework encompasses five learning algorithms: Logistic Regression, Support Vector Classifier (SVC), Random Forest, Gradient Boosting (GB), and Histogram-based Gradient Boosting (HistGB). Each model is trained under base (lab tests + demographics) and extended (base + comorbidity encoding) representations.
Three clinical prediction tasks are operationalized as binary classification:
- Deceased vs. Discharged: Prediction of in-hospital death versus survival (primary clinical importance).
- Deceased vs. Recovered: Maximal outcome separation (death vs. full recovery).
- Recovered vs. Ameliorated: Discrimination among survivors regarding extent of recovery.
Stratified resampling mitigates class imbalance where present. Experiments traverse laboratory subsets of top-10 to top-50 tests by frequency. Performance is measured by accuracy and AUC.
HistGB consistently produced optimal AUC and accuracy across all diagnostic-rich scenarios, with performance peaking in the Deceased vs. Recovered task (AUC=0.983, accuracy =0.93 for the top-40 subset with diagnostic features).
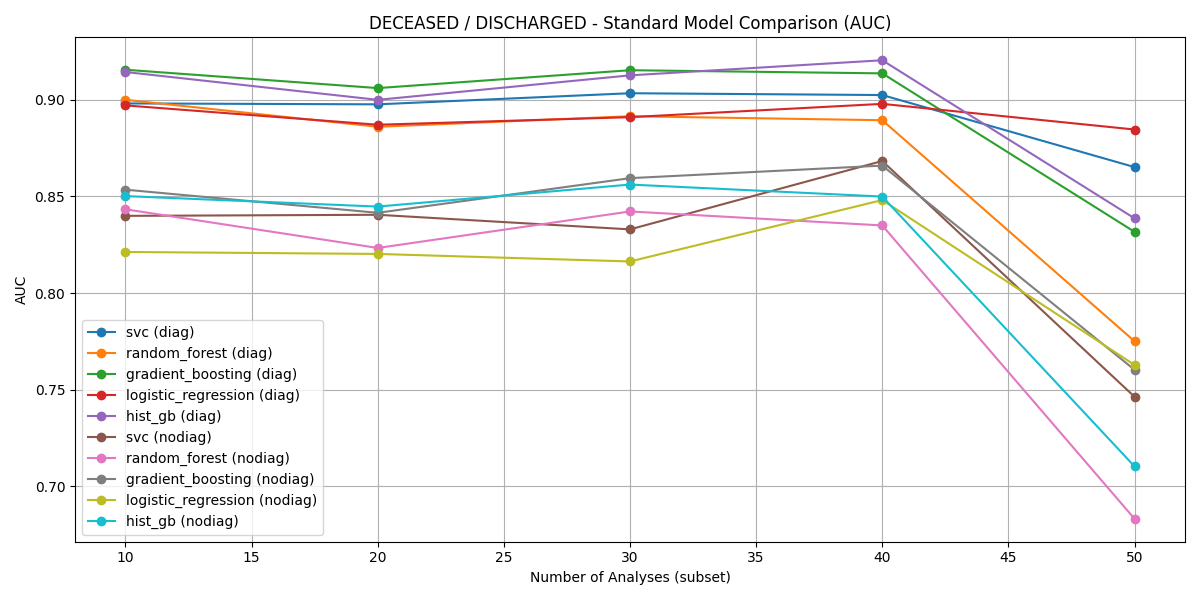
Figure 2: AUC comparison for Deceased vs. Discharged across all classifiers and feature sets.
For Deceased vs. Discharged, HistGB achieved an AUC of 0.920 and accuracy of 0.843 on the top-40 subset, outperforming non-diagnostic models.
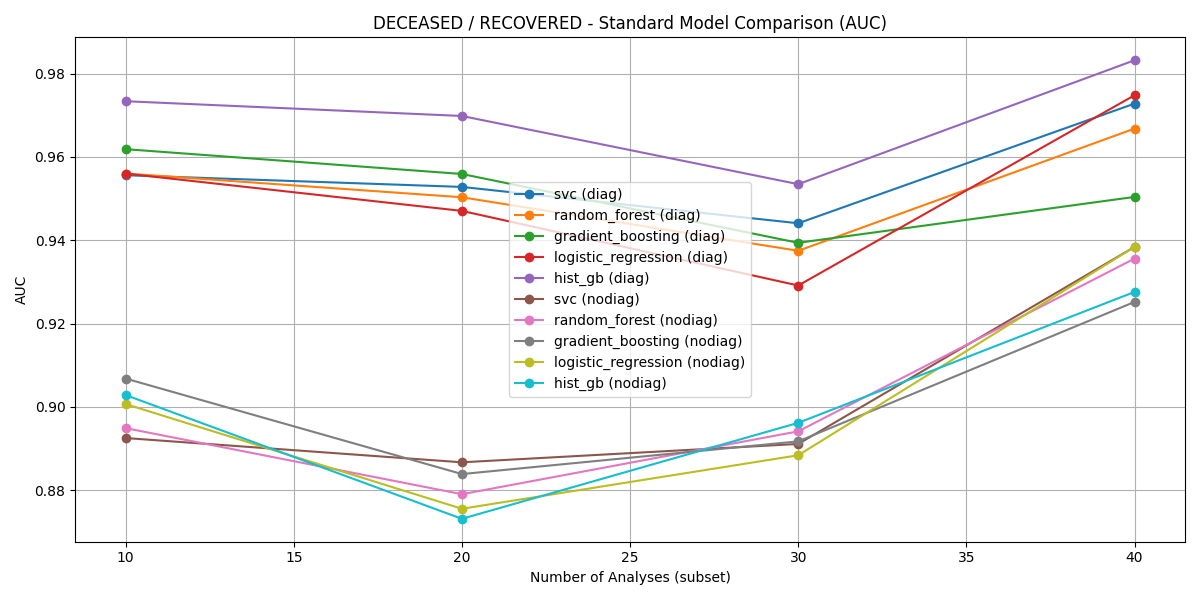
Figure 3: AUC comparison for Deceased vs. Recovered across diagnostic subsets.
Recovered vs. Ameliorated, though less clinically critical, still showed robust discrimination (AUC up to 0.865 via Histogram-based Gradient Boosting on the top-20 diagnostic subset).
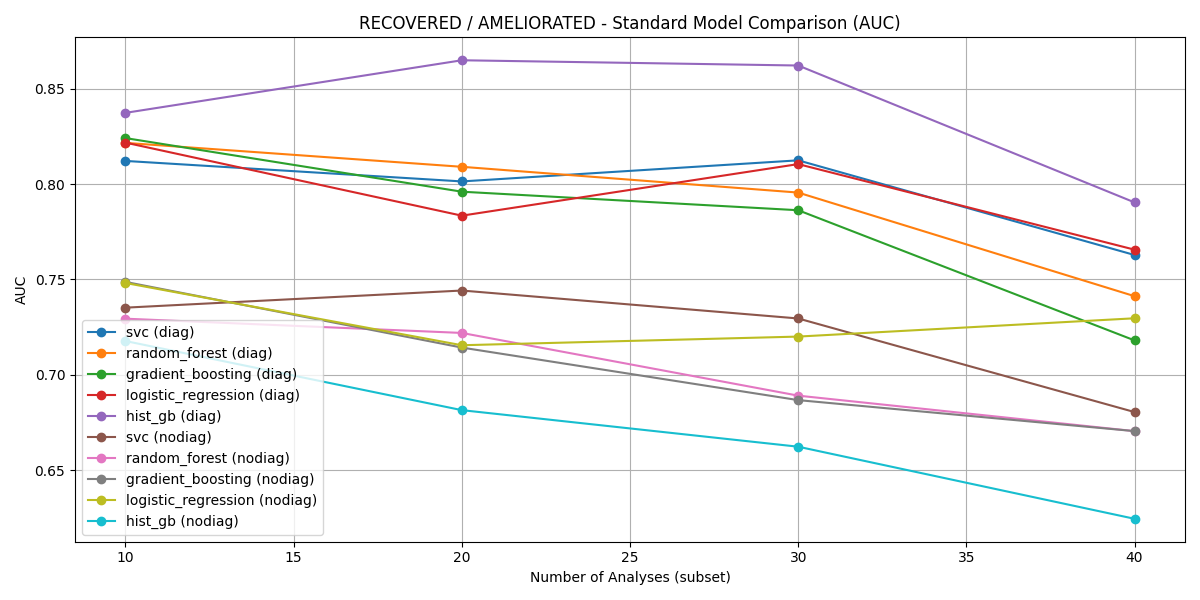
Figure 4: AUC comparison for Recovered vs. Ameliorated across diagnostic subsets; HistGB outperforms alternative models consistently.
Crucially, models with diagnostic feature augmentation provided clear superiority, with a sharp decay in performance when considering only laboratory and demographic attributes.
Accuracy analyses across all subsets reinforce the AUC results, and demonstrate the optimal trade-off of predictive performance at the top-20 to top-40 feature range, prior to excessive sample attrition with higher-dimensional lab panels.
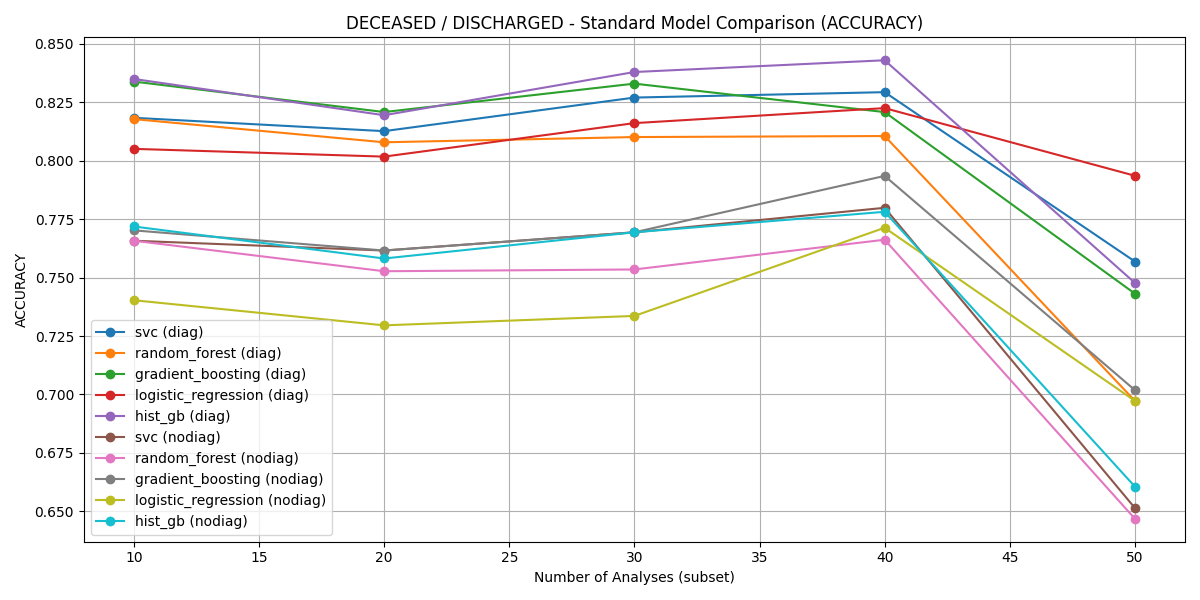
Figure 5: Accuracy of different models for Deceased vs. Discharged across diagnostic feature subsets.
Model Interpretability and Feature Importance via SHAP
SHAP analysis illuminated the predominant predictors of adverse outcomes. Top features, robust across all tasks, include cardiovascular and respiratory comorbidities, urea levels, AST, platelet count, and notably, eosinophil percentage.
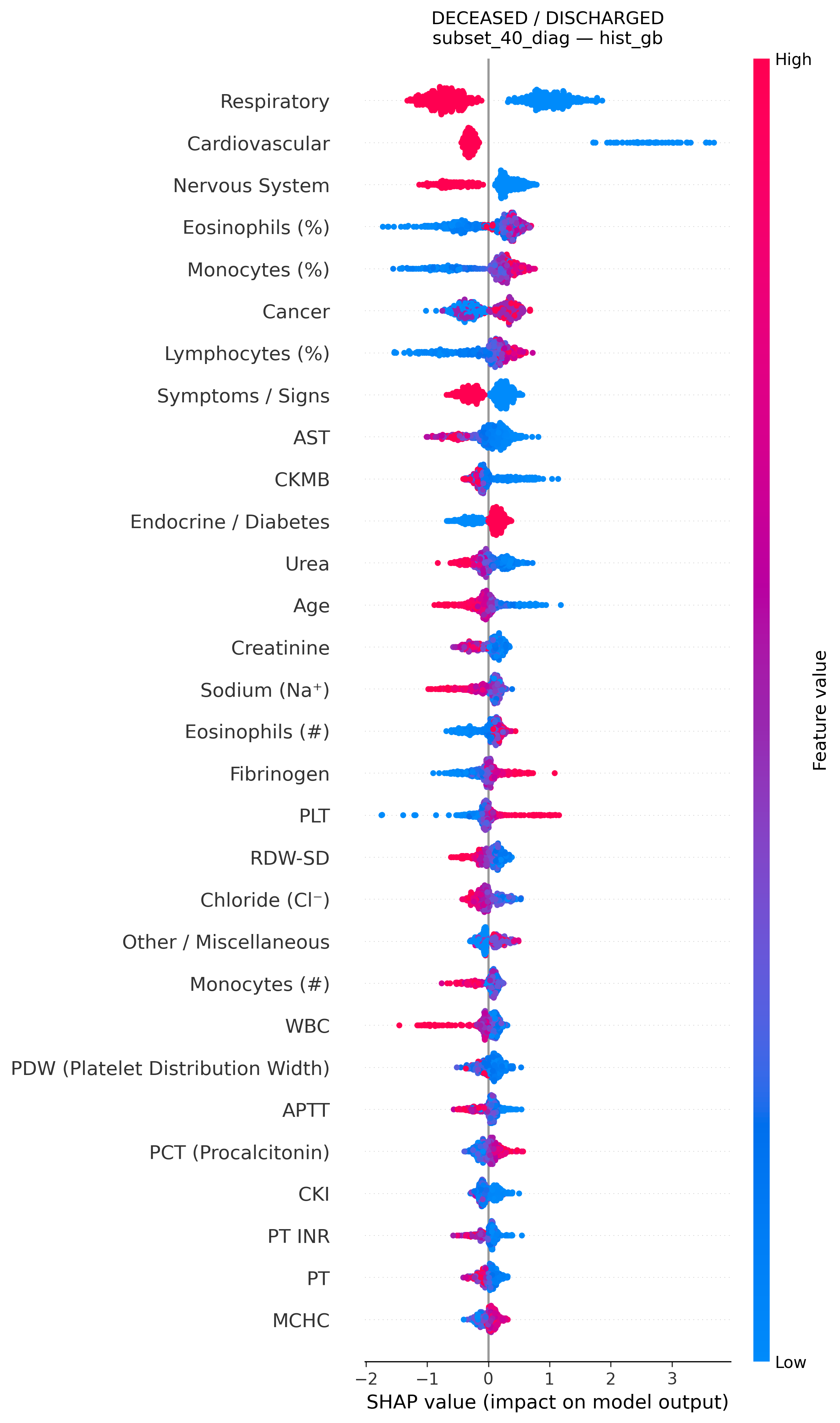
Figure 6: SHAP summary plot highlighting features affecting mortality risk in the HistGB model (Deceased vs. Discharged, top-40 diagnostic subset).
Eosinopenia—uncommonly emphasized in classical sepsis scoring—emerges as a powerful indicator of both mortality and poor recovery, corroborating recent meta-analytic findings but diverging from standard clinical practice. Additional salient features encompass markers of inflammation (WBC, fibrinogen), hemodynamics (CKMB/CKI), coagulopathy (platelets), and hepatic dysfunction (AST, ALT).
Recovery-oriented discrimination prioritized hepatic/biliary indices alongside red-cell parameters, reflecting diversified trajectories among survivors.
Clinical and Theoretical Implications
The results demonstrate that explainable ML can provide actionable, improved risk stratification for sepsis, especially when diagnostic comorbidity signatures are available. The models generalize to outcome transitions beyond crude mortality, supporting resource allocation (e.g., triaging ameliorated patients from ICU), and facilitate transparent justification for clinical actions.
Importantly, the identification of eosinopenia as a central negative prognostic factor suggests that current sepsis severity scores (SOFA, qSOFA, etc.) are omitting significant, easily obtainable information. This finding aligns with recent biological insight regarding the acute phase response but remains underutilized in European standard-of-care. The demonstration of high predictive validity for models trained in a resource-limited Eastern European cohort also validates their applicability beyond major North American or Western European datasets—addressing concerns about cross-population generalizability.
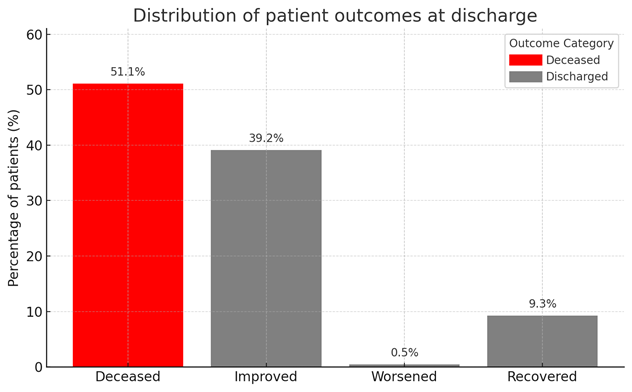
Figure 7: Distribution of discharge outcomes, illustrating class balance across key endpoint groups.
Limitations and Future Directions
The model development pipeline is limited by restriction to patients with complete laboratory and diagnosis panels for a given feature subset—potentially introducing selection effects. Subjectivity in discharge type annotation among survivors may introduce outcome ambiguity. No temporal modeling of lab dynamics is currently performed due to data sparsity.
Future work will focus on:
- Leveraging time-aware architectures (e.g., temporal neural networks) for progression modeling.
- Investigation of generalizability to external, non-Romanian cohorts.
- Prospective validation and integration into clinical decision support for real-time triage.
Conclusion
This study provides a comprehensive, technically rigorous demonstration of explainable ML methods delivering high-accuracy prediction of sepsis outcomes in a large Romanian EHR dataset. The models substantially outperform prior work on mortality discrimination, highlight underexploited prognostic markers, and offer a transparent foundation for clinical integration in resource-constrained settings. The theoretical contribution centers on validating tree-based ensemble models combined with SHAP as both effective and interpretable for complex, multi-morbidity critical illness phenotypes. The findings have strong implications for updating both clinical risk assessment tools and informatics strategies in sepsis care.

