- The paper presents a novel participatory platform that combines expert resource definition with structured community input for efficient morphological documentation.
- It employs a hybrid approach using rule-based heuristics, neural models, and few-shot LLM prompting to deliver high-quality annotation suggestions.
- Case studies across diverse language families demonstrate marked improvements in error reduction and annotation efficiency for low-resource languages.
Motivation and Background
The severe under-documentation of the world's linguistic diversity, especially among low-resource and endangered languages, necessitates efficient and scalable methodologies for morphological data collection. Existing processes are impeded by the expertise and time required for finite-state transducer (FST) grammar engineering, limited scalability, ineffective support for out-of-vocabulary forms, and insufficient systematic leveraging of cross-linguistic regularities. While resources like UniMorph have shaped the computational morphology landscape, their rigid, resource-intensive workflows and lack of community validation mechanisms limit extensibility and correction scalability.
Consequently, there exists a pronounced void for a comprehensive, scalable, and participatory platform—one that harmonizes linguistic expertise with structured speaker contribution and leverages recent advances in interactive machine learning for rapid, high-quality annotation.
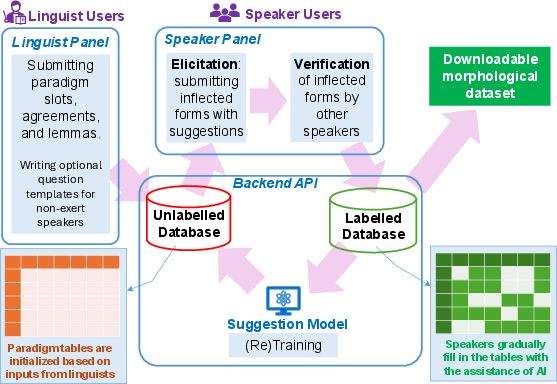
Figure 1: The CommonMorph platform workflow facilitates elaboration of morphological structures by a linguist and provides an interoperable ecosystem for contributors to validate and enrich labelled databases.
CommonMorph introduces a unified web-based framework integrating three collaborative tiers: expert-driven resource definition, contributor-driven elicitation, and community validation. The central innovation lies in modular, role-specific interfaces and a dynamic active learning pipeline for morphological suggestion, adaptable to the typological diversity inherent in endangered and low-resource languages.
Linguists initiate projects by encoding paradigms, inflection classes, and morphosyntactic feature sets, leveraging import mechanisms for cross-lingual resource adaptation. The interface encodes explicitly defined morphosyntactic structures, hierarchically organized inflectional layers, and morphophonological rewriting rules, and supports reusable elicitation prompt templates for speaker engagement. Notably, these materials are convertible to and from the UniMorph schema, ensuring downstream compatibility.
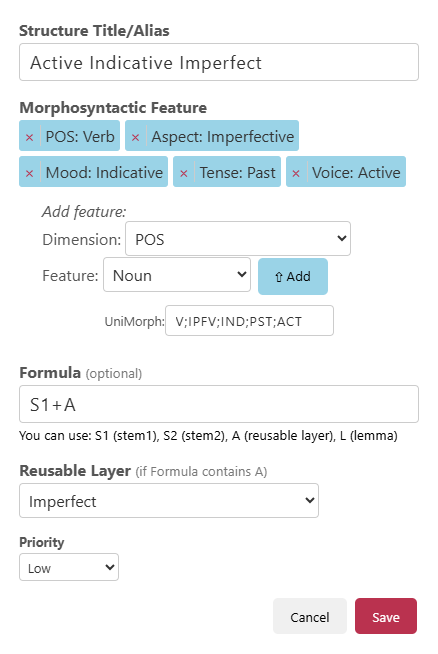
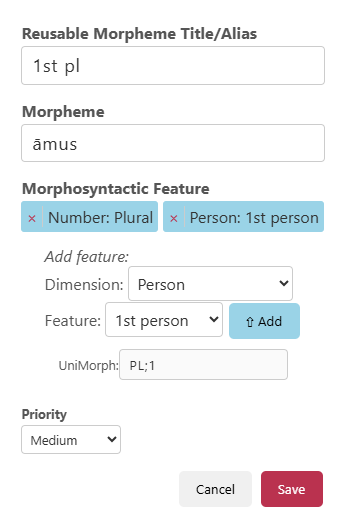
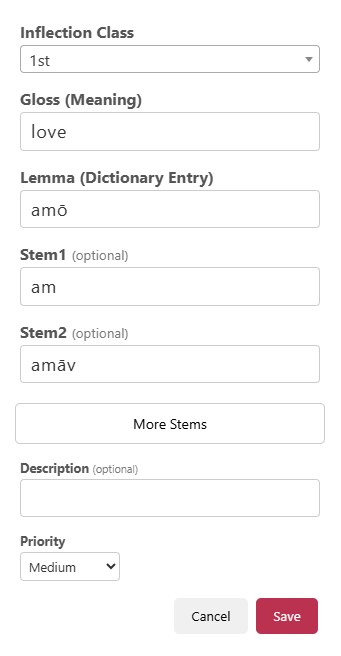
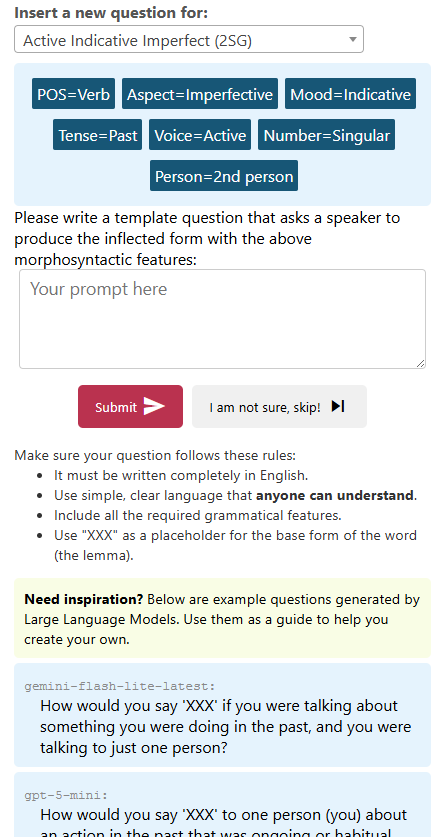
Figure 2: Paradigm structures as core to inflectional system representation, with explicit support for reusable structural layers and morphosyntactic features.
Linguists' resource submissions are depicted through annotated conjugation exemplars, enhancing the transparency of the inflectional modeling process:
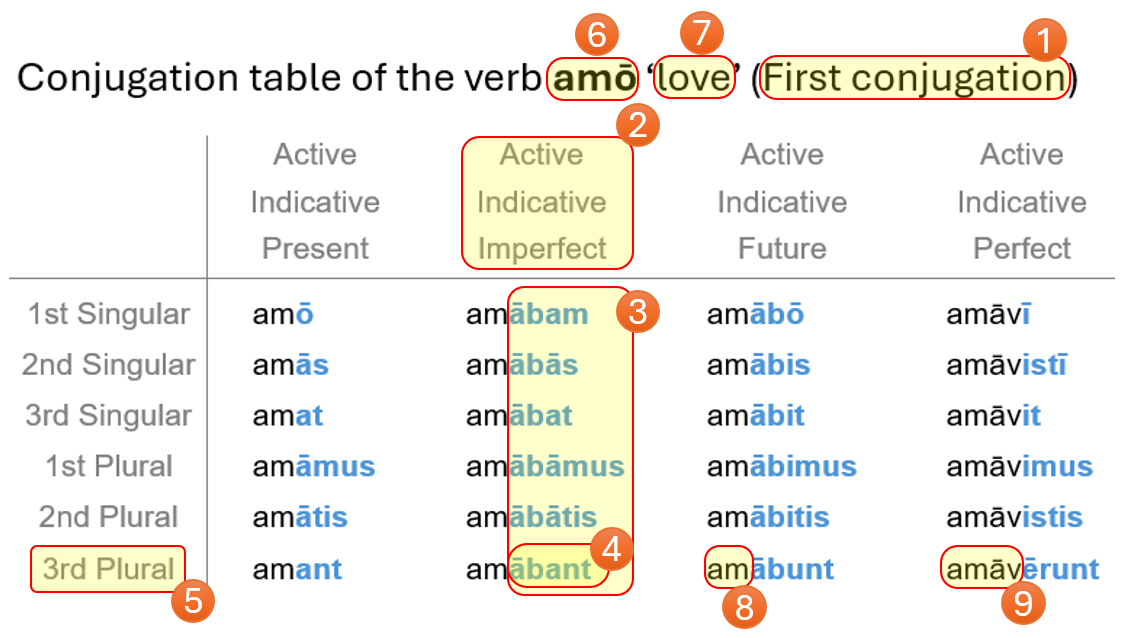
Figure 3: Example of a Latin verb conjugation table annotated with CommonMorph terminology, including inflection classes, paradigm structures, reusable layers, morphemes, features, lemma, gloss, and alternate stems.
Speakers, regardless of their formal expertise, interact via adaptive panels: experts can edit or verify bulk paradigms, while non-experts receive simplified, contextually-generated prompts designed to elicit specific forms. The interface automatically prioritizes "most informative" forms per active learning selection; disagreements across speaker submissions are flagged for adjudication. Question templates abstract away grammatical terminology, supporting broader participation.
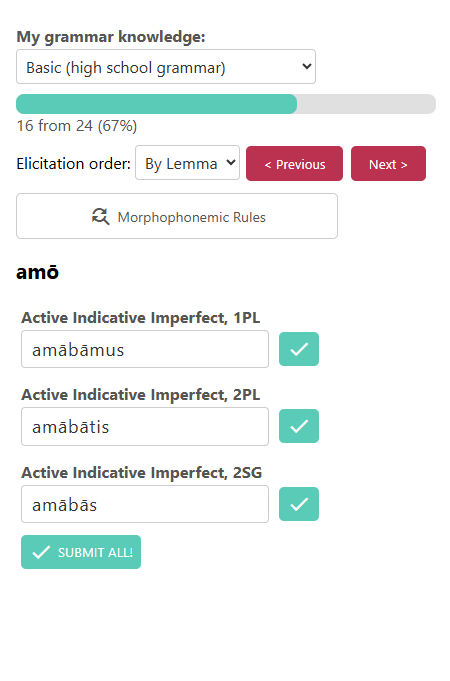
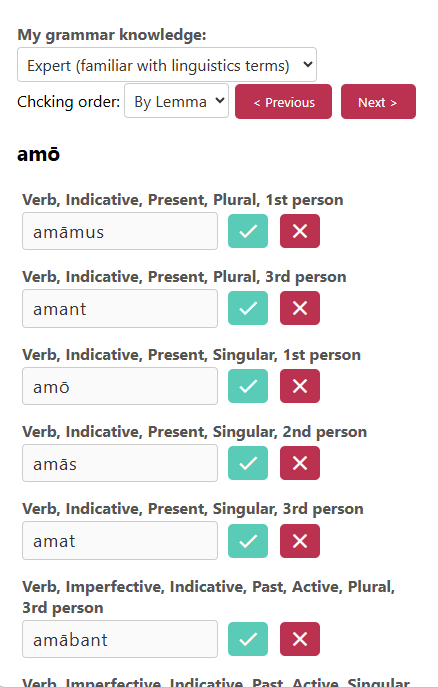
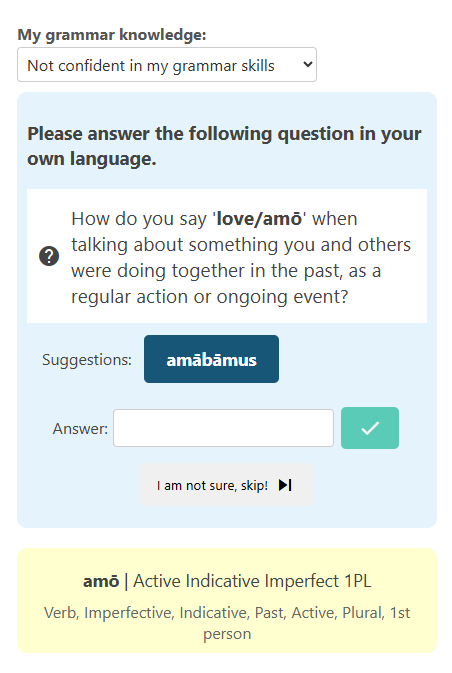
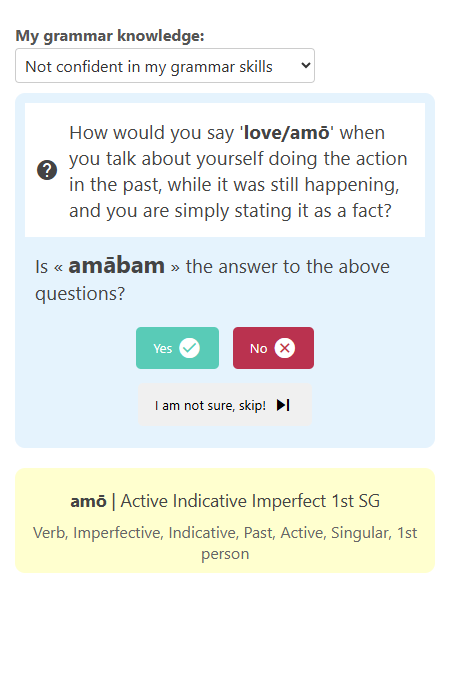
Figure 4: Eliciting expert speakers and facilitating validation through a user interface adaptable to speaker expertise.
Learning Framework and Suggestion Model
CommonMorph implements a progressive suggestion pipeline, transitioning from cold-start rule-based heuristics, to neural sequence-to-sequence LSTM models, to few-shot LLM prompting via APIs (e.g., Gemini-2.5-Flash, GPT-5-mini) as data volume increases. The platform aggregates and tags suggestions from all sources, presenting them in an ensemble view with confidence indicators.
The active learning component iteratively prioritizes forms for annotation based on model uncertainty, maximizing information gain under annotation cost constraints. Particularly during low-data regimes, LLM-based few-shot prompts, auto-generated using prior verified forms, substantially reduce manual discovery of new inflectional forms, despite coverage and orthographic limitations present in mainstream LLM data for highly endangered languages.
Comprehensive case studies spanning eight languages and dialects across four families (Italic, Germanic, Iranic, Semitic, Bantu, Turkic) validate the generality of the platform’s typological support. The methodology accommodates stem allomorphy, nonconcatenative root-and-pattern morphology (Arabic), agglutination (Turkish with vowel harmony), reduplication, and complex stem management.
Numerical evaluation uses Character Error Rate (CER) over 3,000 samples per variety to assess suggestion model quality, an operational proxy for required manual corrections. Linguist-initiated rules and explicit morphophonological encoding yield strong improvements in zero-resource contexts (e.g., Turkish: linguist rules CER=31.7%, +morphophonology CER=2.97%). Neural model CER decreases monotonically as training data expands, reflecting effective benefit from active learning prioritization. LLM-based suggestions yield CERs as low as 0.21–0.5% on resource-rich languages but degrade on fully diacritized or low-coverage dialects—articulating the non-universality of LLM transfer even for morphosyntactic inflection.
User surveys report mean satisfaction/ease-of-use scores above 4.7/5, minimal onboarding time, and demonstrate pedagogical benefit in language awareness, supporting the argument for participatory, hybrid human-ML workflows.
Theoretical and Practical Implications
The CommonMorph project empirically validates a hybrid, participatory documentation paradigm. The platform’s open-source and UniMorph-aligned design synergizes with computational linguistic workflows, facilitating further NLP advances such as morphological segmentation, cross-lingual transfer, and low-resource IGT generation. Iterative resource improvement is streamlined by supporting expert revision and broad-based community feedback, promoting data quality and ownership. The separation of interface roles and support for context-independent elicitation question generation directly addresses the expertise bottleneck in endangered language documentation.
From a theoretical perspective, CommonMorph operationalizes the integration of typologically informed rule-based knowledge with data-driven uncertainty sampling, providing an instantiation of human-in-the-loop active learning at global scale. The case studies expose both the limits and benefits of current LLM capabilities for granular morphological prediction, highlighting the continued need for linguist-contributed inductive bias in extremely low-resource morphosystems.
Limitations and Future Directions
While CommonMorph achieves significant reduction in manual effort and error rate, the system's dependency on initial linguist input remains a limiting factor in “true” zero-resource settings. The effectiveness of LLM suggestions strongly correlates with the match between training domain and target dialect, indicating the need for improved cross-lingual adaptation or on-demand fine-tuning.
Future expansions include:
- Automated extraction of inflectional patterns and rules from grammars and dictionaries for bootstrapping (§ see [virk-etal-2020-dream] for corpus development approaches)
- Extension beyond morphology to phonological and syntactic domains for holistic documentation
- Incorporation of audio-based elicitation to accommodate non-literate language communities and languages lacking orthographic standards
Conclusion
CommonMorph advances the state of participatory language documentation by integrating modular expert-led workflows, flexible speaker elicitation, and an active-learning-driven suggestion engine that leverages rule-based, neural, and LLM-based modeling. The platform’s open, interoperable architecture and broad typological applicability substantiate its utility for rapidly expanding multi-lingual morphological resources and support a replicable model for collaborative language data preservation and computational modeling.