- The paper presents a comprehensive cognitive memory system integrating biologically-inspired forgetting with a mathematically principled, quantization-aware retrieval approach (FRQAD).
- It introduces a seven-channel retrieval architecture that significantly boosts multi-hop and adversarial query performance while ensuring robust session continuity.
- The system employs local vector storage and an automatic memory lifecycle management pipeline, demonstrating high retrieval fidelity and efficient mixed-precision operations.
SuperLocalMemory V3.3: A Cognitive, Quantization-Theoretic Approach to Local Agent Memory
Introduction and Context
SuperLocalMemory V3.3 (SLM V3.3) addresses the so-called session amnesia endemic to current AI coding agents, which lack persistent, cross-session memory and computationally plausible cognitive processes. Unlike predecessors such as Mem0, Letta/MemGPT, or Zep that primarily expose text-based vector storage with basic retrieval, SLM V3.3 implements the entire cognitive memory taxonomy via a fully local, mathematically principled architecture. It operationalizes sensory through implicit memory transitions, achieving autonomy from cloud LLMs and introducing persistent, self-regulating memory suitable for agentic AI.
System Architecture
SLM V3.3 is composed of distinct Interface, Engine, and Storage layers (Figure 1). The Interface layer exposes access via Model Context Protocol (MCP), a CLI with daemon serve mode, a web dashboard, and auto-cognitive hooks for Claude Code. The Engine introduces seven parallel cognitive retrieval channels, Ebbinghaus-cycle lifecycle management, advanced quantization, and code knowledge graph integration. The Storage layer employs SQLite + sqlite-vec for high-performance, local vector operations.
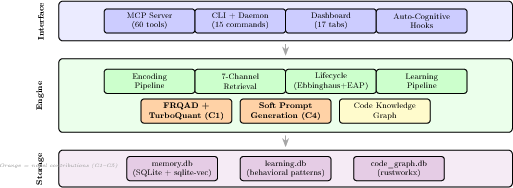
Figure 1: SLM V3.3 system architecture delineating novel cognitive, quantization, and storage mechanisms.
Key architectural advances include:
- Daemon serve mode, achieving a substantial 32× cold-start speedup.
- Integration of a language-agnostic code knowledge graph for context-aware code retrievals.
- A modular pipeline for observation, learning, consolidation, and forgetting that is fully automatic and fail-silent.
Fisher-Rao Quantization-Aware Distance and TurboQuant Integration
A cornerstone contribution is the Fisher-Rao Quantization-Aware Distance (FRQAD), which unifies information geometry and embedding quantization for similarity search. FRQAD models quantized embeddings as parameters of Gaussian manifolds where quantization noise inflates variance, then computes the exact Fisher-Rao geodesic (Atkinson-Mitchell form) to deliver provably correct preference for high-fidelity representations.
Empirical results on 18,840 mixed-precision query-fact pairs affirm that FRQAD achieves 100% accuracy in preferring float32 over 4-bit quantized embeddings; cosine similarity, in contrast, achieves 85.6% (Figure 2). This eliminates a longstanding source of erroneous retrievals in mixed-precision memory stores.
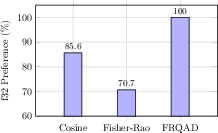
Figure 2: Mixed-precision retrieval preference: FRQAD delivers perfect fidelity in ranking full-precision over quantized facts, outperforming cosine and standard Fisher-Rao measures.
The persistent memory store leverages TurboQuant, a data-oblivious vector quantization algorithm, adapted (LT2E) for mixed-precision, long-lifetime embeddings. At 4- and 2-bit compression, recall and cosine fidelity demonstrate graceful degradation, with over 68% recall@10 preserved in realistic scenarios.
Ebbinghaus Adaptive Forgetting, Quantization Coupling, and Lifecycle Dynamics
SLM V3.3 is the first in this domain to implement mathematical forgetting curves for agent memory, integrating Ebbinghaus-style exponential retention, modulated by access frequency, importance, confirmation, and emotional salience. Critically, the system couples memory fading to progressive embedding quantization (Active→32-bit, Warm→8-bit, Cold→4-bit, Archive→2-bit), realigning geometric similarity to cognitive salience.
Over 30 simulated days, hot and cold memories diverge by a factored 6.7× in strength and retention (Figure 3). The interplay of Bayesian trust-weighted decay ensures that low-confidence memories are rapidly eliminated, underpinning robust long-term knowledge hygiene.
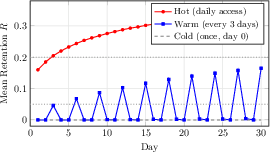
Figure 3: Ebbinghaus-based retention dynamically modulates both retrieval strength and embedding precision, enforcing structured, tiered forgetting.
Memory lifecycle is formally grounded in Riemannian Langevin/Fokker-Planck dynamics, demonstrating ergodicity and convergence under compound forgetting and consolidation potentials.
Seven-Channel Cognitive Retrieval
SLM V3.3 generalizes retrieval beyond flat similarity search to a seven-channel architecture: semantic KNN (vector), BM25, entity graph traversal, bi-temporal (recency), spreading activation (SYNAPSE-style associative energy), consolidated gists, and Hopfield pattern-replay. Weighted Reciprocal Rank Fusion, complemented by ONNX cross-encoder reranking, drives zero-LLM retrieval to 70.4% on the LoCoMo benchmark.
A salient effect is the substantial improvement on multi-hop (+23.8pp) and adversarial (+12.7pp) tasks, compared to the previous baseline (Figure 4), though precision dips for single-hop queries due to channel fusion complexity.
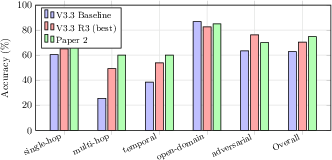
Figure 4: LoCoMo per-category results show marked gains in multi-hop and adversarial queries, validating the multi-channel architecture at scale.
Memory Parameterization: Realizing Implicit Cognitive Tiers
SLM V3.3 operationalizes the long-term implicit tier—absent from all competitive implementations—via soft prompt generation. Semantic patterns mined from consolidated episodic traces are directly injected as natural language soft prompts at session initiation, offering agent configuration independently of retrieval or gradient-based adaptation. This mechanism is API- and provider-agnostic, maintaining agent flexibility beyond the constraints of LoRA or other adapter methods.
Zero-Friction Auto-Cognitive Pipeline
The system is install-and-forget for the end developer: installation triggers full lifecycle automation—recall, observe, learn, consolidate, parameterize, and forget—across all sessions, with immediate compatibility for Claude Code. No manual memory management is necessary; all hooks are fail-silent and invertible.
Evaluation and Comparative Analysis
Benchmarks confirm strong empirical performance:
- FRQAD delivers perfect ranking of quantized embeddings.
- Ebbinghaus quantization coupling achieves substantial selectivity between memory classes.
- Zero-friction pipeline ensures 100% session continuity.
- LoCoMo zero-cloud mode yields 70.4% overall, with pronounced gains in complex (multi-hop/adversarial) queries.
In comparison to open-source and commercial systems, SLM V3.3 is the only system implementing forgetting, quantization, parameterization, code graph integration, and a seven-channel retrieval stack efficiently without cloud dependencies.
Limitations and Directions for Future Work
Notable limitations include the cold-start requirement for adaptive retrieval learning, inherently lower expressivity of natural language soft prompts versus full fine-tuning, expected fidelity loss at extreme compression (2-bit), and a regression in single-hop retrieval due to increased fusion noise. Future extensions may include query-dependent routing, hyperbolic (Poincaré ball) embeddings for structure-rich knowledge, and automatic calibration of forgetting schedules.
Conclusion
SuperLocalMemory V3.3 establishes a comprehensive, mathematically sound foundation for local-first, cognitive memory in AI agents. By pioneering information-geometric quantization-aware retrieval, biologically inspired lifecycle management, multi-channel retrieval, and seamless parameterization, the system closes the cognitive memory gap present in production agentic frameworks. These advances democratize robust, privacy-preserving memory for local, zero-LLM agents, with immediate practical and theoretical implications for lifelong learning AI.
The system is available on GitHub, npm, and PyPI under the Elastic License 2.0.