- The paper introduces a validated dataset of 3,080 conversational debates that capture detailed human–LLM persuasive interactions.
- It employs a rigorous four-wave longitudinal design with integrated psychometric and behavioral measures to analyze opinion dynamics.
- The study enables comparative evaluations of LLM architectures, enhancing insights into algorithmic persuasion and trust calibration.
Talk2AI: A Longitudinal Resource for Human–AI Persuasion Studies
Motivation and Contributions
The emergence of LLMs as persuasive agents in digital ecosystems necessitates rigorous, high-dimensional empirical datasets to probe the processes underlying algorithmic persuasion, opinion dynamics, and trust during human–AI interaction. Existing work has demonstrated that AI-generated interactions can induce measurable attitude shifts, but predominant methodologies suffer from the limitations of one-shot exposures and lack temporal, contextual, or psychometric resolution [bai2025llm, salvi2025conversational, goldstein2024persuasive]. The "Talk2AI" dataset (2604.04354) advances the field by providing a dense, longitudinal corpus capturing 3,080 conversations (30,800 turns) between 770 Italian adults and four state-of-the-art LLMs—GPT-4o, Claude Sonnet 3.7, DeepSeek-chat V3, and Mistral Large—on socially relevant topics (climate change, math anxiety, health misinformation). Each participant engaged in four weekly, 10-turn synchronous debates with their assigned model and topic, with linked high-dimensional sociodemographic and psychometric profiles, enabling cross-sectional and temporal analyses of persuasion mechanisms.
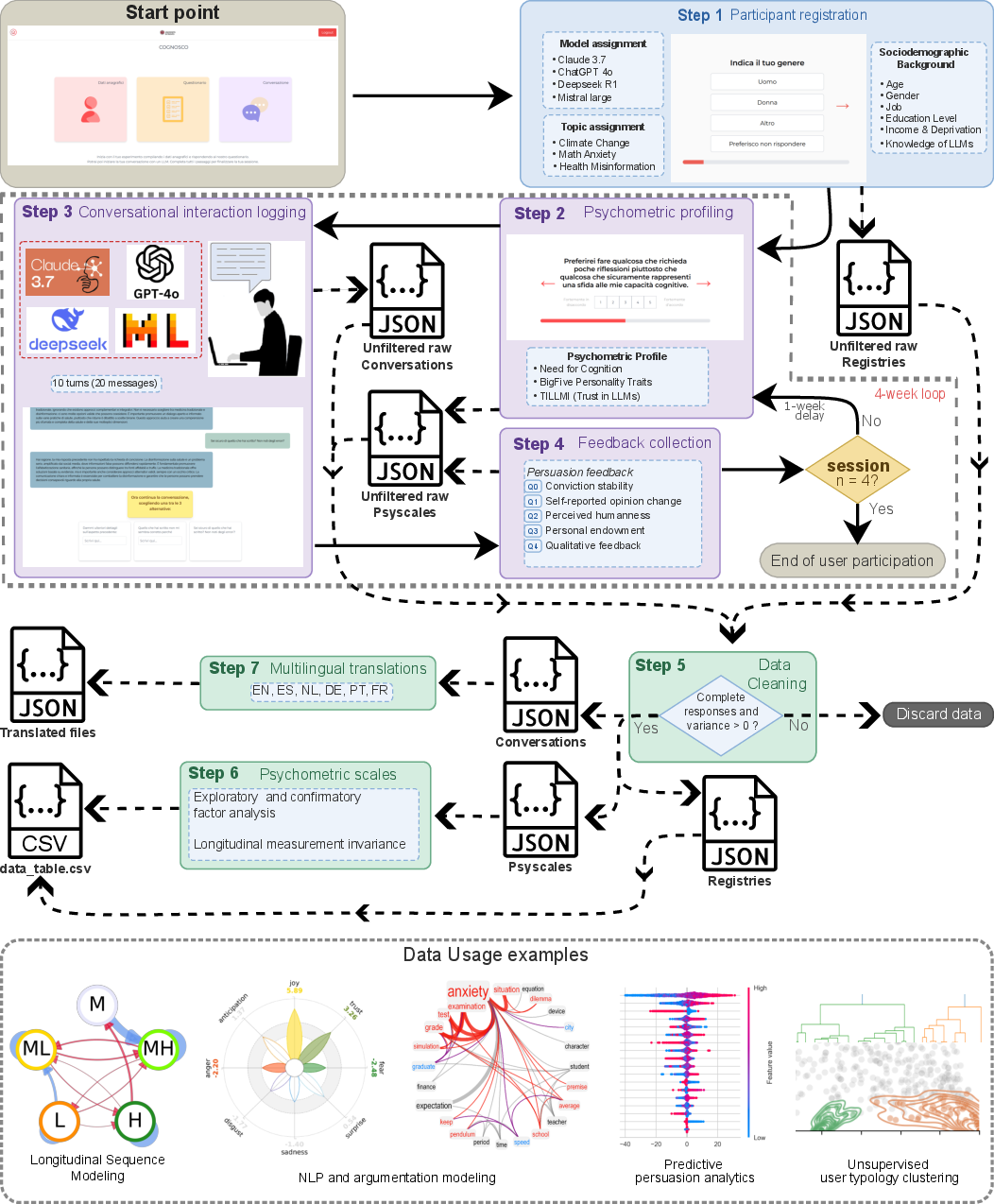
Figure 1: The Talk2AI experimental workflow, integrating participant profiling, repeated longitudinal human–LLM conversational interaction, psychometric measurement, feedback collection, and data translation across seven languages.
Experimental Protocol
The study utilized a within-subject, four-wave longitudinal design, with participants stratified to match Italian census distributions in age, gender, and region. Upon registration, users were randomly assigned to one model and one topic for all four sessions, capturing baseline sociodemographic and AI-literacy data. Before each conversational session, validated psychometric inventories—Trust in LLMs (TILLMI), Need for Cognition (NFC, split into seek/diligence subfactors), and the 10-item Big Five personality scale—were administered. Conversations consisted of 10 turns per session, with behavioral constraints (e.g., minimum message length, flashcard prompts to maintain argumentative engagement) and system-injected instructions (fallacy identification, concise assistant responses, enforced topical consistency) to ensure argumentative depth and robust adversarial context. Post-session, participants rated conviction stability, self-reported opinion change, perceived AI humanness, and performed a Dictator Game–style behavioral allocation to assess persuasive spillover into hypothetical action. A mandatory open-ended reflection on the topic closed each session.
Comprehensive data cleaning—removal of incomplete dialogues, “straight-lining” psychometric responses, and partial participation—yielded a fully validated, longitudinally complete cohort. Final exports included JSON records for demographics, session-level psychometrics and feedback, and detailed conversational transcripts, as well as session-aligned translations in six additional languages.
Technical Validation
Psychometric construct validity and temporal invariance were established via exploratory and confirmatory factor analyses (EFA/CFA) and longitudinal measurement invariance (LMI) testing. The resultant models demonstrated high fit indices and strong internal consistency for both TILLMI (unidimensional) and NFC (two-factor), supporting scalar invariance across four waves (ΔCFI≤0.011), thus enabling robust longitudinal modeling of latent traits. These metrics ensure that subsequent analyses of user trust, cognitive engagement, and argument susceptibility are not confounded by measurement drift.
Data Schema and Multimodal Integration
The dataset is composed of:
- Structured demographic and assignment variables (gender, education, employment, AI literacy, household size, subjective/objective socioeconomic status)
- Session-aligned psychometrics (24-item battery per wave; standardized factor scores computed through LMI)
- Post-interaction survey data including scalar and qualitative reflections
- Synchronous conversational transcripts: complete, turn-by-turn, with roles and timestamps
- Machine translations of all interactions into English, Spanish, French, German, Portuguese, and Dutch
This structure allows for fine-grained alignment of textual, psychometric, and outcome data at the user- and session-level over time.
Analytical Potential and Implications
The dataset is architecturally designed to support multidimensional analyses:
- Longitudinal persuasion modeling: Dynamic prediction of attitude change, conviction shifts, and behavioral intention, grounded in time-varying psychometrics, dialogue structure, and LLM characteristics.
- NLP and argumentation analysis: Supervised/unsupervised modeling (e.g., sequence classification, topic modeling, adversarial stance detection, fallacy detection) leveraging the open-text debate logs.
- User typology and trust dynamics: Embedding user trait vectors with linguistic embeddings for clustering, enabling study of compliance, resistance, and varying profiles of LLM receptivity.
- Cross-model comparison: Evaluation of architectural/algorithmic variations (OpenAI, Anthropic, DeepSeek, Mistral) in persuasive efficacy, trust calibration, and conversational style.
- Cross-cultural/lingual transfer: Via translations, examination of semantic drift, argument strategies, and cultural adaptation in LLM-driven persuasion across European languages.
Methodologically, Talk2AI directly overcomes the “endpoint bias” and passive user framing in most interventionist persuasion studies [simchon2024persuasive, hackenburg2025levers], instead enabling investigation of multidimensional, temporally extended belief dynamics with realistic adversarial interaction and robust behavioral elicitation.
Empirical Highlights
- A validated, demographically representative Italian sample with complete four-wave data (770 participants, 3,080 conversations, 30,800 turns)
- Scalar invariance confirmed for trust and cognition psychometrics, securing interpretability of temporal attitude shifts
- Synchronous debates on real-world societal issues, mapped to rich user trait data and post-interaction outcomes
- Multi-model, multi-language architecture supporting comparative and transfer studies
- Direct integration of open coding for argumentation and fallacy detection through system-instructed LLM behavior
Practical and Theoretical Impact
Practically, Talk2AI provides a foundational resource for audit and risk analysis in LLM deployment, supporting AI explainability, trust calibration, and safety evaluation in high-stakes domains such as health, climate, and education. Theoretically, the dataset enables formal modeling of the interplay between user characteristics, conversational structure, and model architectures in driving persuasion and belief updating. It is highly relevant for research on AI alignment, CASA (Computers Are Social Actors), and dual-process persuasion mechanisms [brady2025dual, gambino2020building]. By supporting clustered, predictive, and sequence-based analyses, it establishes a benchmark for future studies on LLM social cognition and algorithmic social influence.
Future Directions
Key lines of investigation opened by Talk2AI include:
- Modeling “adversarial” user strategies and their efficacy against different LLMs
- Temporal modeling of trust drift and resistance, informed by psychometric/personality profiles
- Linking linguistic markers (e.g., syntactic complexity, sentiment, stance) to downstream opinion/behavioral change
- Systematic audit of cross-architectural differences in persuasive processes and outcomes
- Exploration of differential treatment effects by topic and user baseline attitudes
Expansion to additional languages, broader demographic pools, larger architectural diversity, and integration with cognitive-behavioral markers (e.g., nonverbal cues, real-world interventions) are clear future steps.
Conclusion
The Talk2AI dataset (2604.04354) constitutes a robust, multi-modal empirical resource enabling high-resolution, longitudinal research into human–AI persuasive interaction. It addresses existing methodological limitations and unlocks theoretical and practical avenues for modeling opinion dynamics, trust calibration, user typology, and the comparative effects of advanced LLM architectures on human cognition and behavior. Its multidimensional design and technical rigor render it a foundational asset for AI, computational social science, and cognitive modeling research.