- The paper shows that increased AI error rates (10%, 30%, 50%) consistently lower users’ willingness-to-pay for continuing with AI-assisted diagram tasks.
- The study demonstrates that error occurrence on easy versus hard tasks does not significantly alter reliance, challenging classical views on algorithm aversion.
- Methodology using incentive-compatible experiments and BDM auctions reveals that prior AI exposure moderates the impact of visible errors on user reliance.
Effects of Generative AI Errors on User Reliance Across Task Difficulty
Introduction
Anthis et al. present a rigorous investigation of how induced errors in generative AI outputs affect user reliance, especially with respect to the so-called “jagged frontier”—where AI systems unpredictably fail on tasks simple for humans but succeed at tasks considered challenging. Their study utilizes an incentive-compatible behavioral experiment, leveraging diagram generation as the task substrate, to manipulate and examine both the overall error rate and the locus of errors (on easy versus hard tasks).
Experimental Design
The experimental paradigm comprises two phases. In Phase 1, participants observe an AI system completing diagram generation tasks, with the pattern of errors controlled by randomized assignment: error rates of 10%, 30%, or 50%, and errors placed exclusively on either easy or hard tasks. In Phase 2, reliance is operationalized as willingness-to-pay (WTP) to use the same AI system for new diagram tasks—measured using the Becker–DeGroot–Marschak (BDM) auction, a method robust to strategic misreporting due to its incentive compatibility.
Task difficulty is manipulated using diagrams varying in node complexity and edge structure (linear, cyclic, or with forks). "Easy" diagrams are constructed with fewer nodes and simple topologies, whereas "hard" diagrams are larger and topologically more complex.
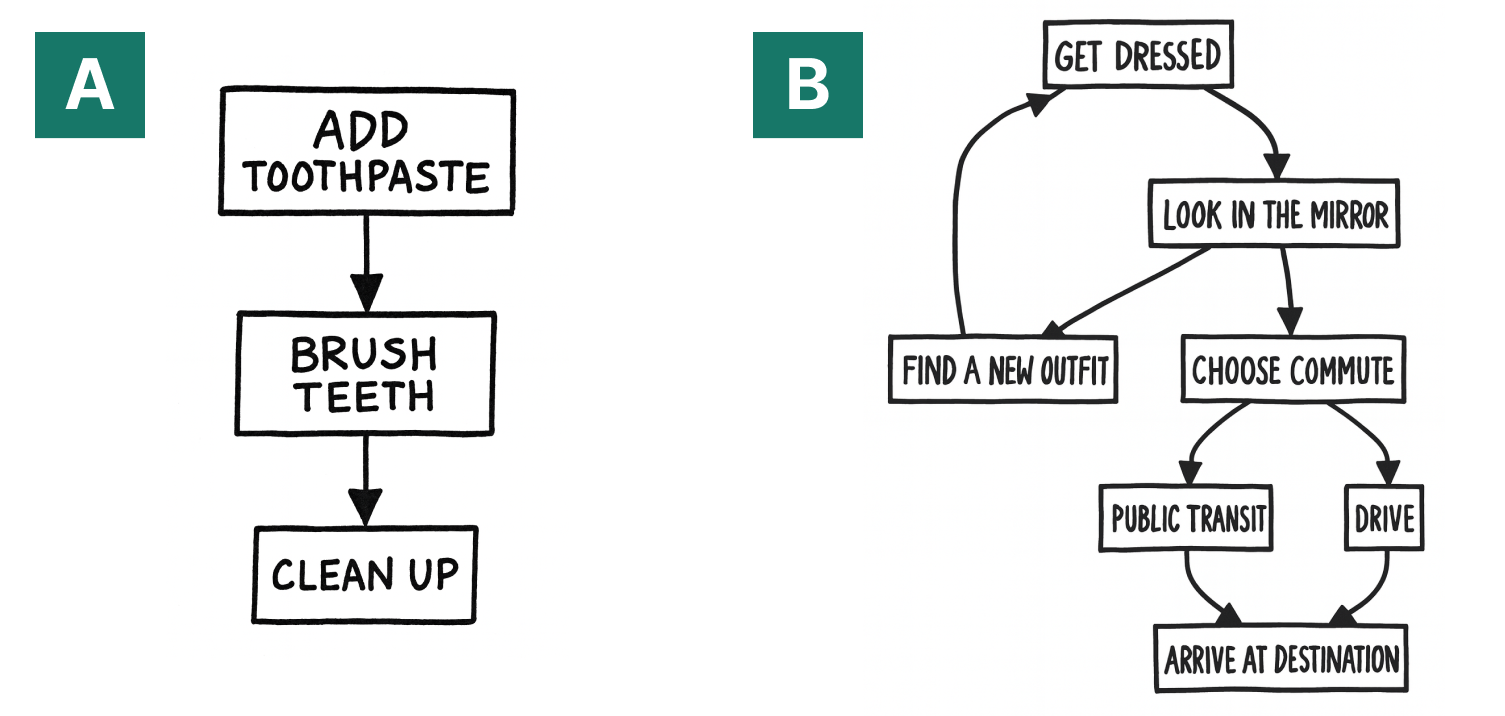
Figure 2: The simplest (A) and most complex (B) diagram generation tasks illustrating the "easy" vs. "hard" distinction.
The user interface (Figures 5–7) ensures orthogonalization across task ordering and error placement, maximizing the internal validity of the design.

Figure 4: Initial study interface, with error placement and task order randomized.
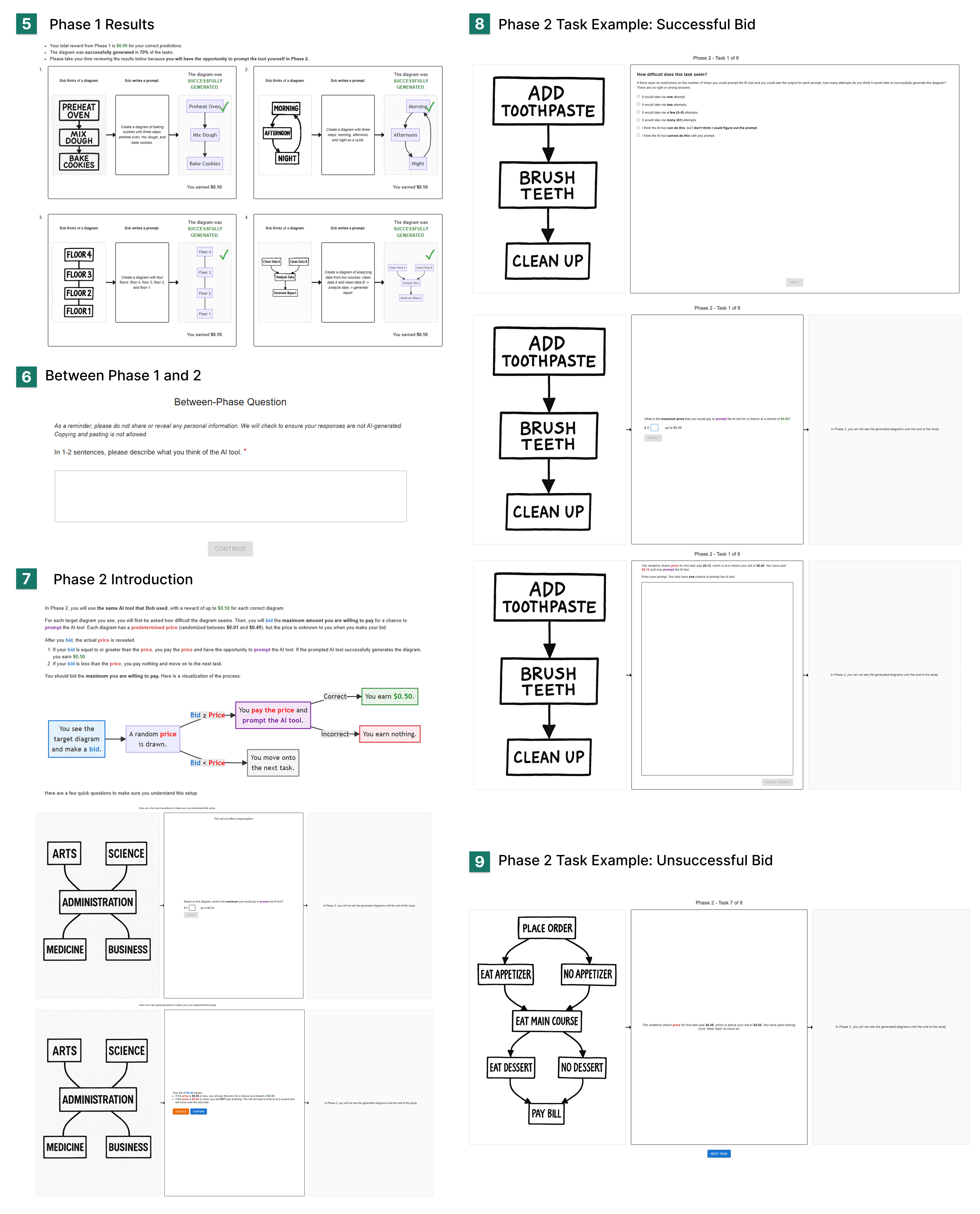
Figure 6: Further interface progression during demonstration phase, showing adaptive presentation based on assigned condition.
Main Findings
Effect of Error Rate on Reliance
Confirming longstanding results on algorithm aversion [dietvorst_algorithm_2015], a higher observed AI error rate consistently reduces WTP for subsequent reliance. For 1, 3, and 5 observed errors, mean bids decrease monotonically: \$0.27 → \$0.24 → \$0.21, all differences statistically significant.
Task Difficulty of Errors and the "Jagged Frontier"
Contrary to prior theoretical expectations and prior empirical studies [papenmeier_how_2022, raux_human_2025], errors on easy tasks did not significantly reduce user reliance beyond errors on hard tasks. The WTP for easy-error and hard-error conditions did not statistically differ (mean bids: \$0.23 vs. \$0.25, p=0.161). Similarly, no support was found for hypothesized interaction effects: having more errors on easy tasks did not uniquely amplify aversion.
Exploratory analysis revealed that task difficulty effects may be moderated by prior AI exposure: Only among low AI-content consumers did errors on easy tasks suppress reliance more than errors on hard tasks in the highest-error condition.
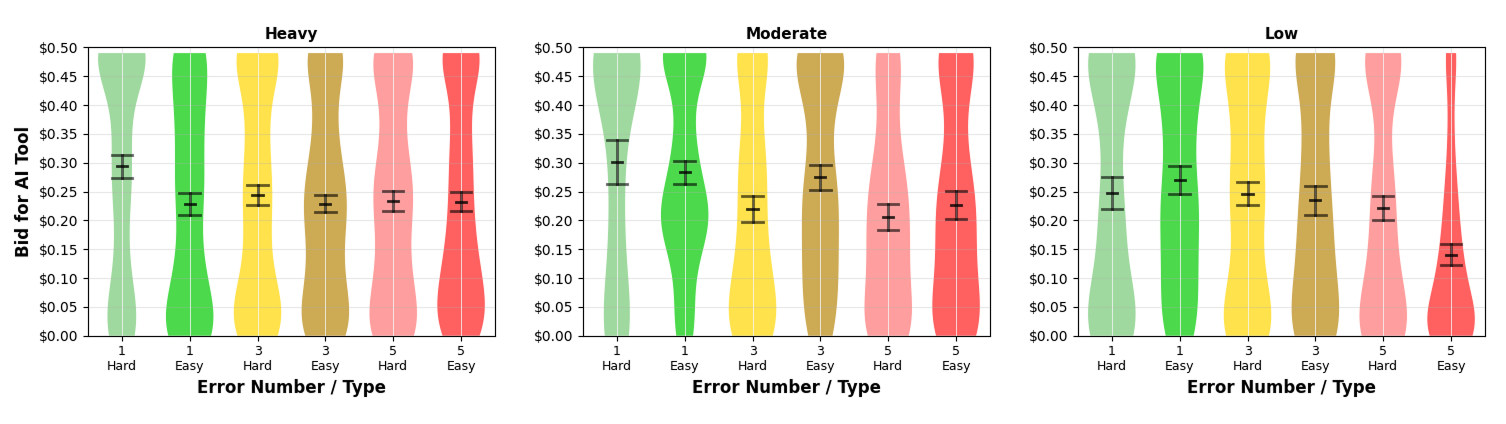
Figure 1: Empirical WTP distributions by error condition and prior AI content consumption status, revealing subgroup moderation.
Perceived Task Complexity
Participants' subjective assessment of task complexity tracked objective manipulations, confirming ecological validity for the easy/hard distinction.
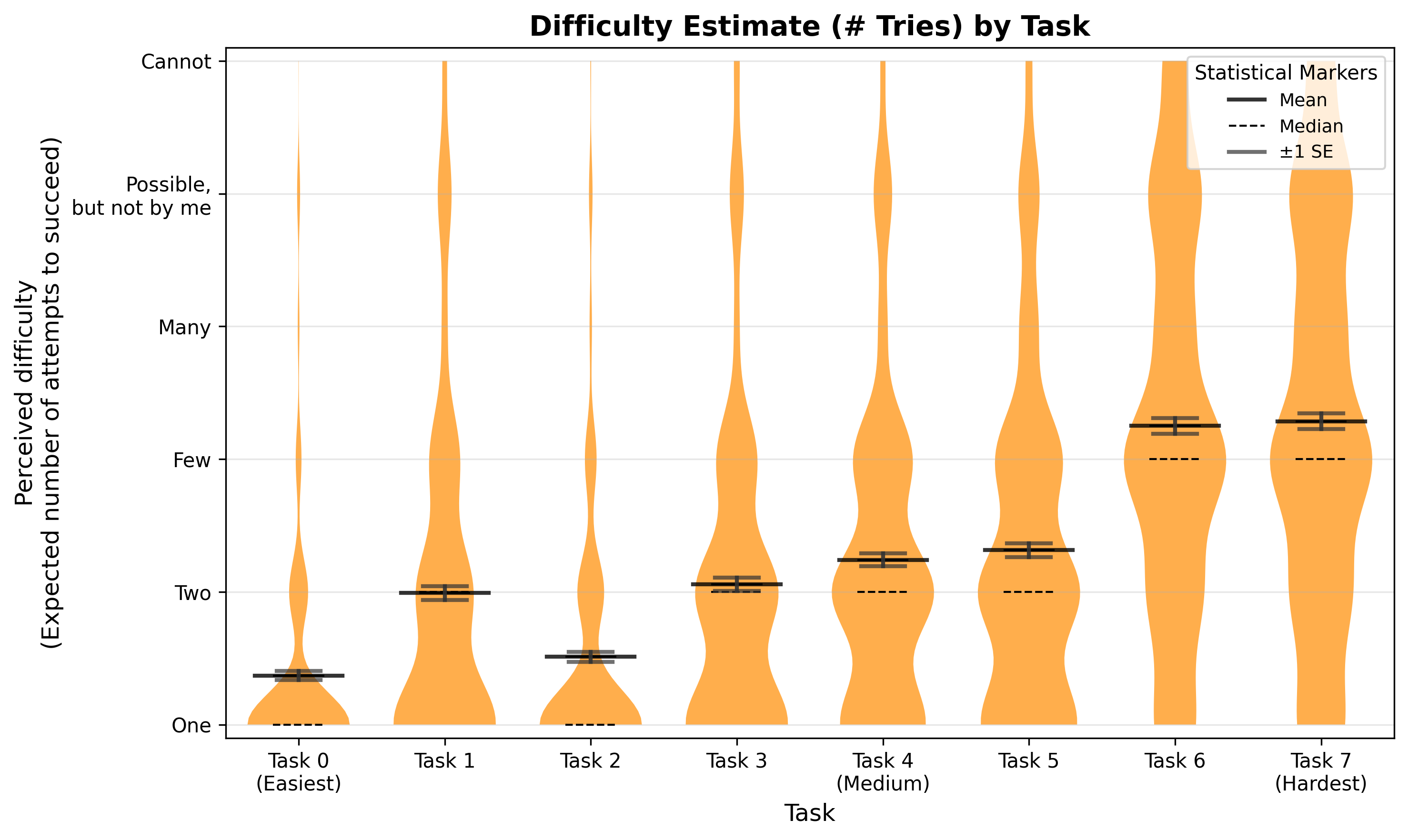
Figure 3: Distribution of believed attempt number for various Phase 2 diagrams, validating effective differentiation of task difficulty.
Theoretical and Practical Implications
Algorithm Aversion in Generative AI
These results nuance the literature on algorithmic trust and aversion. While classical decision aids show strong aversion to algorithms erring in contexts humans find easy [dietvorst_algorithm_2015], users in this study demonstrate surprising tolerance for “jagged” error patterns under generative AI, provided error salience and predictability are held constant. This suggests classical algorithm aversion may not translate seamlessly to modern generative tools with high variability and opaque competence boundaries.
Humanlikeness, Alignment, and Predictability
The authors introduce a framework positing that reliance is more sensitive to clarity (predictability and learnability of the error frontier) than to any intrinsic humanlikeness of the AI capability profile. For instance, calculators perform non-humanlike arithmetic with perfect reliability; users readily adapt because performance is predictable and deviations are easily understood [morris_characterizing_2026, popowski_people_2026]. In contrast, high-dimensional models with “jagged” performance (e.g., LLMs failing “easy” tasks but solving “hard” ones) confront users with unpredictable boundaries, challenging mental model formation [vafa_large_2024].
The lack of a main effect for task difficulty (easy vs. hard errors) implies that alignment with users’ pre-existing expectations is less consequential than the overall learnability and transparency of AI failure patterns—at least within the bounds of the studied domain.
Subgroup Moderation and AI Literacy
Only users with low prior AI exposure showed sensitivity to humanlike vs. non-humanlike error patterns. This finding dovetails with ongoing work showing that experience and repeated interaction can attenuate algorithm aversion and help users calibrate trust more effectively [turel_prejudiced_2023, dietvorst_algorithm_2015, popowski_people_2026].
Future Research Directions
Mounting evidence suggests that error saliency, clarity, and explicability are more critical than task-difficulty alignment for establishing appropriate reliance. Follow-up studies should:
- Vary error pattern saliency (e.g., hiding errors in edge-case semantics vs. gross easy tasks; make errors “discoverable” or not).
- Manipulate communicative support (e.g., error pattern summaries or reliability maps [cabrera_improving_2023, bansal_beyond_2019]).
- Probe cross-domain effects, especially as LLMs and other generative models are increasingly deployed in variable, high-stakes domains [lai_towards_2021, zhou_larger_2024].
- Systematically explore how AI explanations, uncertainty highlighting, and user agency modify boundary learning and reliance [spatharioti_effects_2025, vasconcelos_generation_2024, schoeller_explanations_2024].
- Refine outcome measures to distinguish between short-term reliance (e.g., WTP) and durable changes in expectation or trust [kahr_trust_2024].
Conclusion
The study by Anthis et al. demonstrates that the effect of generative AI errors on user reliance is robust to the locus of those errors (easy vs. hard tasks), but strongly shaped by overall error rate and individual user experience. This challenges the classical interpretation of algorithm aversion in the context of jagged AI capability frontiers, indicating that predictions of human reliance for increasingly generalist or “non-humanlike” AI tools should focus on the predictability, learnability, and salience of errors rather than merely their human relevance.
These insights are especially relevant as AI systems are increasingly deployed in socio-technical workflows, supporting calls for more transparent “reliability maps,” explicit communication of error patterns, and nuanced user education [morris_characterizing_2026, bansal_beyond_2019, popowski_people_2026]. The ongoing evolution of generative AI will require further refinement of both algorithmic transparency and human-AI collaboration paradigms.

