- The paper introduces frax, a pure-Python library that leverages vectorized Featherstone-style dynamics to achieve rapid kinematics and dynamics computations.
- The paper demonstrates a novel ancestor mask approach that harnesses full parallelism on CPUs, GPUs, and TPUs, outperforming existing Python bindings by 2-3x on CPU.
- The paper highlights frax’s utility in high-frequency control and optimization pipelines while outlining future expansions like richer collision geometry support.
frax: Fast Robot Kinematics and Dynamics in JAX
Introduction and Motivation
The paper "frax: Fast Robot Kinematics and Dynamics in JAX" (2604.04310) introduces frax, a modern, high-performance Python library for robot kinematics and dynamics built using JAX. frax directly addresses key limitations of existing libraries: most are written in C++ yielding performance at the expense of Python-based automatic differentiation (AD) and hardware portability, or focus strongly on either CPU or GPU, but not both. frax reconciles these gaps by providing a pure-Python interface, rigorous vectorized implementations for both kinematics and dynamics, seamless support for JIT-compilation, and first-class compatibility with CPUs, GPUs, and TPUs.
The library directly implements featherstone-style rigid-body dynamics, supporting manipulators, humanoids, and extensible multi-body systems. It is positioned for research scenarios requiring high-frequency controllers, optimization-based planning, and those leveraging AD for differentiable computing.

Figure 1: frax enables high-performance kinematics and dynamics computations with AD and efficient control/planning pipelines, demonstrated here with a Franka Panda manipulator performing collision and singularity avoidance under optimization-based control.
Vectorized Rigid-Body Dynamics Algorithms
frax departs from traditional loop-based recursive approaches (e.g., RNEA, CRBA) by adopting fully vectorized formulations. The primary technical innovation is the ancestor mask U, which encodes kinematic tree relationships into matrix operations. All branch traversals, summations, and inertial contributions are realized through broadcasted tensor/matrix operations, fully exposing parallelism for compilation backends. Only forward kinematics retains a minimal sequential component, and in some cases can be completely unrolled as an associative scan.
This restructuring increases per-instance computational complexity from O(n) to O(n2) (for n DOF), but enables XLA to optimize and parallelize computations, yielding significant real-world performance benefits on both CPUs and massively parallel architectures.
The implementation also allows efficient and differentiable computation of kinematic and dynamic quantities. AD is supported natively for both gradients and Jacobian-vector products (JVPs), providing an efficient pathway to implement safety filters, CBF constraints, and optimization pipelines without the development burden of hand-derived analytical derivatives.
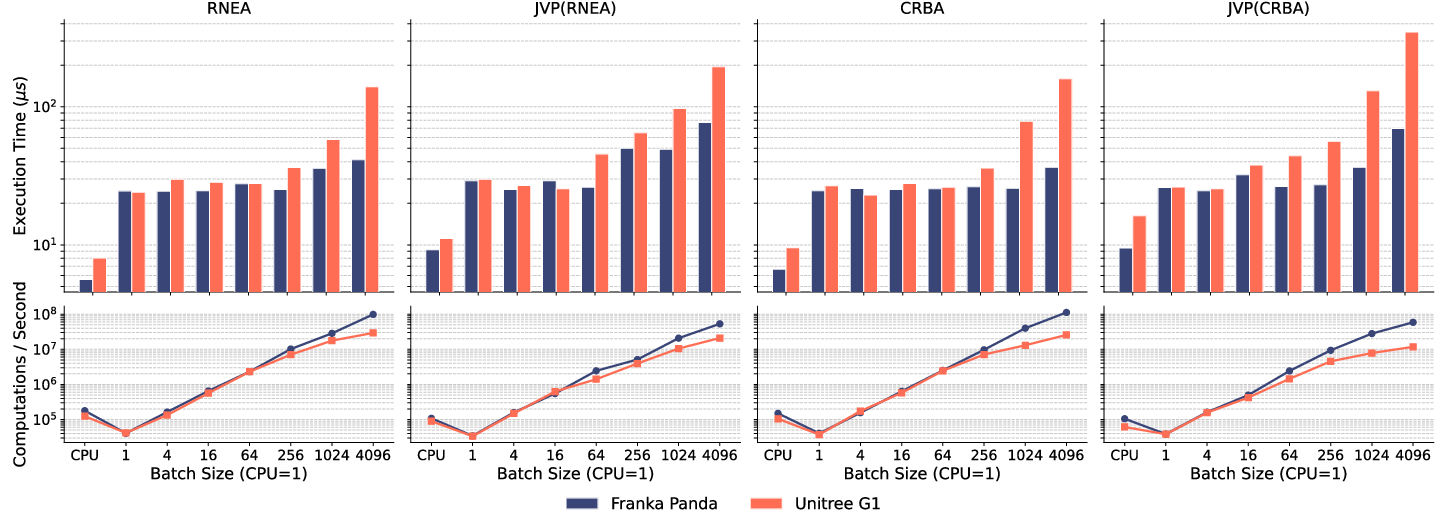
Figure 2: Through vectorization and batch-optimized dynamics methods, frax exhibits high throughput on CPU and GPU across a wide range of batch sizes, including seamless calls to JAX’s AD (jax.jvp).
The authors benchmark frax against established robotics and physics libraries, including Pinocchio, MuJoCo, BRAX, and MJX, both at their native interfaces and via Python bindings. On CPU, frax outperforms Python-based bindings of Pinocchio and MuJoCo by a factor of 2-3x for common controller pipelines, very nearly matching C++ native implementations. On GPU, frax’s throughput equals or surpasses MJX and BRAX, scaling to millions of dynamics evaluations per second without code modification.
Key claims and observed results include:
- On Python-based CPU controllers, frax is 2-3x faster than Pinocchio or MuJoCo Python bindings.
- On GPU, frax achieves performance on par with leading JAX-based simulators (MJX/BRAX), with notably lower compilation overhead (1-2s vs. 6-12s).
- frax supports batch dynamics computations across thousands of parallel instances, achieving over 108 computations/sec on large batches.
These findings reinforce the efficiency and flexibility of vectorized designs for both online control and high-throughput batched computations, making frax suitable for both robot deployment scenarios and research requiring massive parallelization.
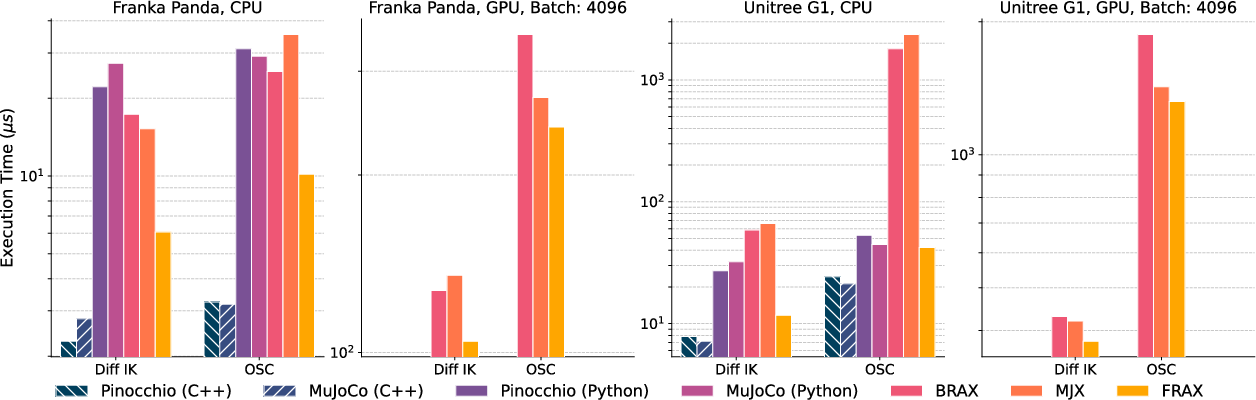
Figure 3: Compute time for controllers constructed with frax and competitors; frax achieves strong CPU performance, outperforming Python bindings and closely matching C++ speeds, and matches GPU throughput with leading JAX-based simulators.
Practical Implications and Flexibility
Beyond raw performance metrics, frax’s architecture has several practical implications for robotics research:
- Unified Cross-Platform Deployment: Researchers can prototype on CPU, scale to GPU/TPU for large-scale training, and deploy controllers to hardware with no change in code structure.
- First-Class AD/Optimization Support: By embracing JAX and vectorization, frax removes friction for gradient-based planning, model-predictive control, and differentiable reinforcement learning.
- Robust Prototyping and Real-Time Viability: With native support for common robots (Franka, Unitree G1) and URDF parsing, controllers developed in frax can be run at kHz rates, facilitating rapid experimentation and transfer to real-world systems.
- Python-Native Research Pipeline: frax removes the overhead associated with Python-to-C++ bindings and incompatibility with AD, which persist in legacy libraries.
Limitations and Directions for Future Work
frax’s focus on minimality and high-performance means it presently omits features present in superset libraries like Pinocchio or MJX. Notably, it lacks global IK solvers, generalized collision geometry support beyond spheres/planes, and simulator environments for RL (as found in MJX/BRAX). The paper proposes extensions in three primary areas:
- Broadening collision geometry types (capsules, boxes, ellipsoids),
- Implementing additional algorithms, including ABA and analytical derivative routines,
- Expanding native support for diverse robot topologies, particularly legged robots (quadrupeds).
Due to its blend of performance, differentiability, and hardware agnosticism, frax is positioned as an enabling tool for applications ranging from real-time control to parallel nonlinear planning and model-based RL.
Conclusion
frax advances the state-of-the-art in robot kinematics and dynamics libraries by leveraging full vectorization and JAX’s differentiated/compiled execution. It delivers superior performance for Python-based robotics research, matching or exceeding established C++ and JAX-native libraries in speed and flexibility. frax's design choices, especially vectorization and tight integration with modern AD toolchains, are likely to influence future development of robotics research infrastructure, promoting rapid prototyping, cross-device compatibility, and seamless use of AD for complex control and optimization. Anticipated future developments will focus on richer geometry support, new dynamic algorithms, and broader applicability across robotic morphologies.