- The paper introduces a multimodal architecture that fuses numerical, visual, and textual inputs to improve solar power forecasting accuracy.
- It employs vision-language models and graph-based attention to capture complex temporal and spatial dependencies in dynamic weather.
- Experimental results on PV stations in China demonstrate significant performance gains and robust handling of modality-specific uncertainties.
Solar-VLM: Multimodal Vision-LLMs for Augmented Solar Power Forecasting
Introduction
Accurate photovoltaic (PV) power forecasting is pivotal for integrating renewables into power grids, mitigating intermittency, and reducing operational risk. Recent advances in ML and DL have improved univariate and multivariate time series forecasting, yet most frameworks remain limited in modality and fail to comprehensively model the complex dependencies in PV generation, especially under highly dynamic atmospheric conditions. "Solar-VLM: Multimodal Vision-LLMs for Augmented Solar Power Forecasting" (2604.04145) addresses these limitations by presenting a unified architecture that fuses temporal, visual, and textual information at multiple PV sites.
Figure 1: Overview of the proposed model.
Framework and Methodological Innovations
Multimodal Representation Learning
Solar-VLM integrates numerical (historical NWP/LMD/PV data), visual (satellite cloud imagery), and textual (structured weather and sensor description) modalities via dedicated encoders. Temporal features are extracted through a patch-based encoder, employing locality/globality via memory enhancement and transformer self-attention. The visual pipeline leverages Qwen-based frozen vision backbones to extract spatiotemporal cloud-cover representations from sequences of satellite images, while textual representations are distilled via Qwen-VLM’s frozen text encoder, structured around a prompt-based schema from station context and weather statistics.
Cross-Site Joint Modeling
The architecture models spatial dependencies in two stages (Figure 2). First, a graph learner (GAT over a KNN adjacency) operates on temporal encodings, capturing spatial correlations through message passing with geographical priors. The patch-level temporal features undergo GAT-based refinement before fusion. Second, after multimodal fusion at the site level, a cross-site attention module flexibly propagates information across the network by allowing each site's representation to attend over those at other sites, facilitating long-range dependency capture in heterogeneous multimodal space.
Figure 2: Overview of the proposed two-stage cross-site joint modeling strategy.
Modality and Prediction Fusion
A per-site MLP fuses the concatenated feature embeddings from all modalities. Two prediction heads are employed: one on the cross-site attention output and another on standalone temporal encodings; these are adaptively fused with data-driven gating, ensuring that prediction is robust to modality-specific uncertainty or missing data.
Experimental Results
Dataset and Protocol
Experiments utilize eight PV stations in Hebei, China, with 14 numerical variables (recorded at 15-minute intervals), PNG-format satellite image sequences (128×128) per site, and algorithmically structured textual weather descriptions. Baselines include classical sequence models (LSTM), efficient transformers (Informer, FEDformer, TimesNet, TimeLLM), and recent multimodal approaches (SUNSET, TimeVLM). Forecast horizons vary from 45 minutes (T=3) to 24 hours (T=96), and evaluation employs MSE, MAE, and R2.
Main Quantitative Findings
Solar-VLM achieves state-of-the-art performance across all horizons and metrics. At T=24, the model achieves an MSE of 0.186 (vs. 0.304 for TimeVLM), MAE of 0.221 (vs. 0.317), and R2 of 0.930. Gains intensify with longer horizons: at T=48, Solar-VLM reports MSE = 0.232 and MAE = 0.286 (vs. 0.361 and 0.337 for TimeVLM). Both the mean and variance of error are consistently minimized, evidencing both accuracy and reliability.
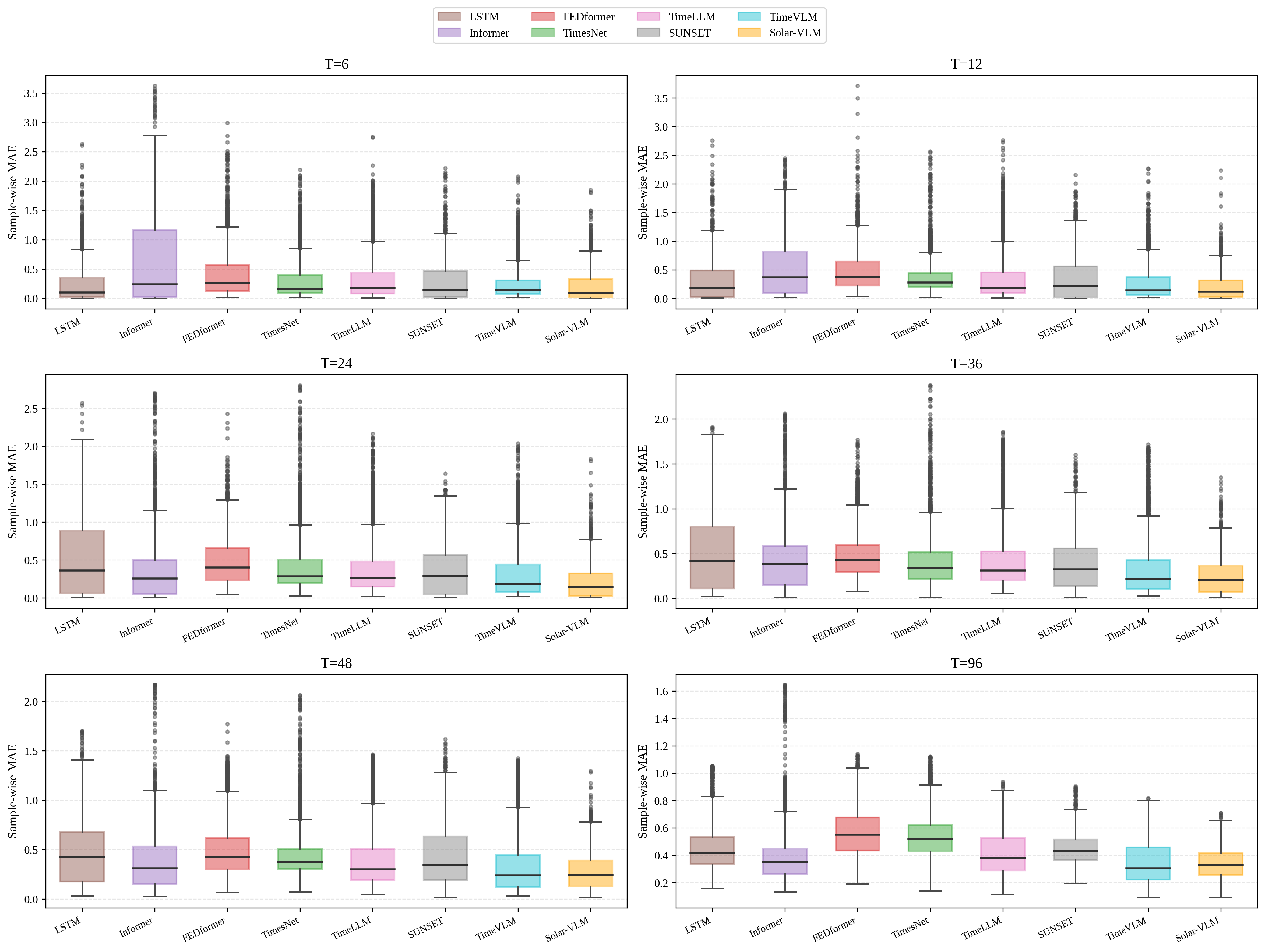
Figure 3: MAE boxplots for different models at different forecasting horizons.
In visual inspection, Solar-VLM’s predicted curves most closely follow ground truth trajectories across all sites and horizons, especially during transients and peak shifts, outperforming other models under both normal and anomalous meteorological conditions.
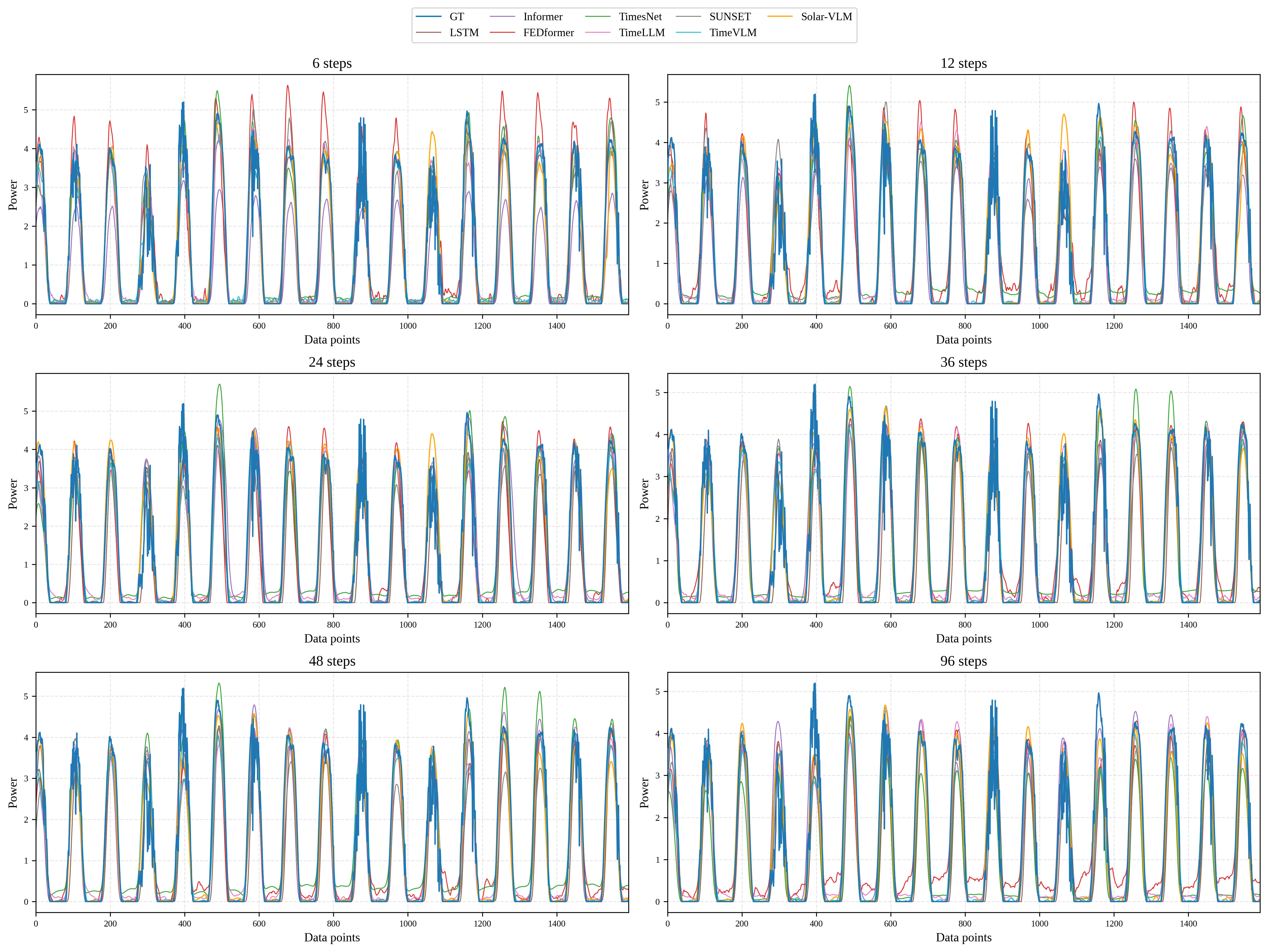
Figure 4: PV power prediction curves of compared models against the ground truth on the test set at different forecasting horizons.
Ablation Study
Systematic component removal underscores the necessity of each module. Excluding the cross-site attention head yields the most degradation (MSE = 0.301, MAE = 0.296), confirming the importance of adaptive cross-site interaction beyond local graph structure. The absence of either the text or vision modality significantly reduces performance, supporting the claim that Solar-VLM's multimodal pipeline is not simply additive but synergistic, with semantic and contextual cues from structured text and visual imagery crucial for disambiguating conditions with complex meteorological regimes.
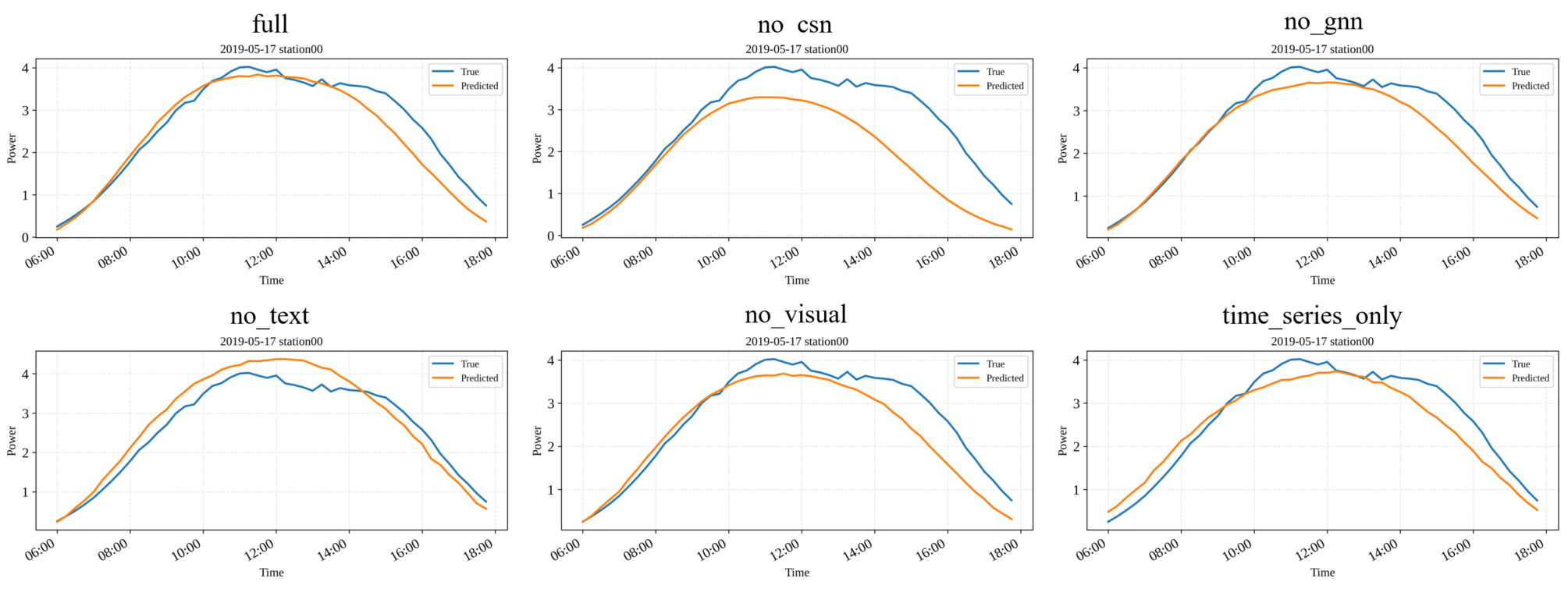
Figure 5: Forecasting results of different ablation variants on a representative cloudy day.
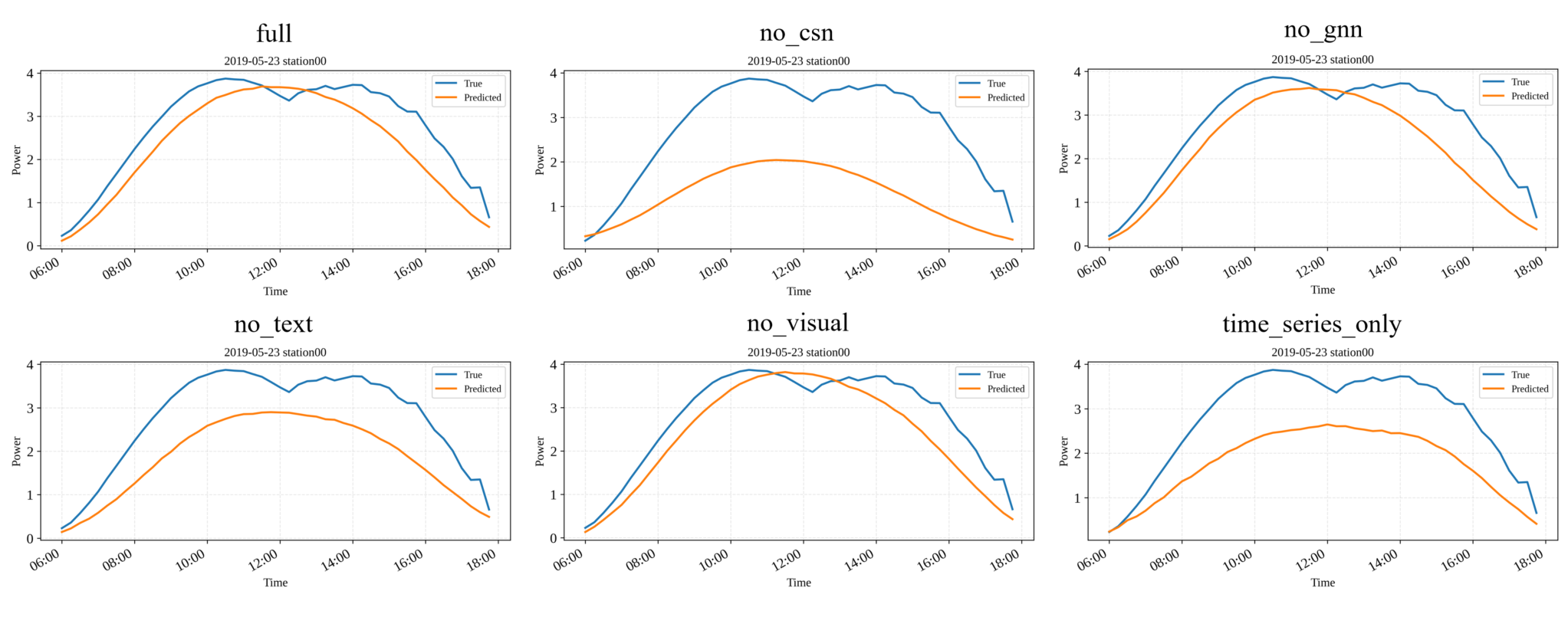
Figure 6: Forecasting results of different ablation variants on a representative sunny day.
Sensitivity Analysis
Robustness analysis of hyperparameters reveals several practical insights (Figure 7). Increasing the historical data window L improves performance up to a tipping point (best at L=192); however, overly large L introduces redundancy/noise, reducing generalization. Patch length (T=30), visual sequence length (T=31), and graph neighborhood size (T=32) display similar non-monotonic dependencies, indicating the importance of calibration for optimal spatiotemporal context capture without overfitting local statistics.
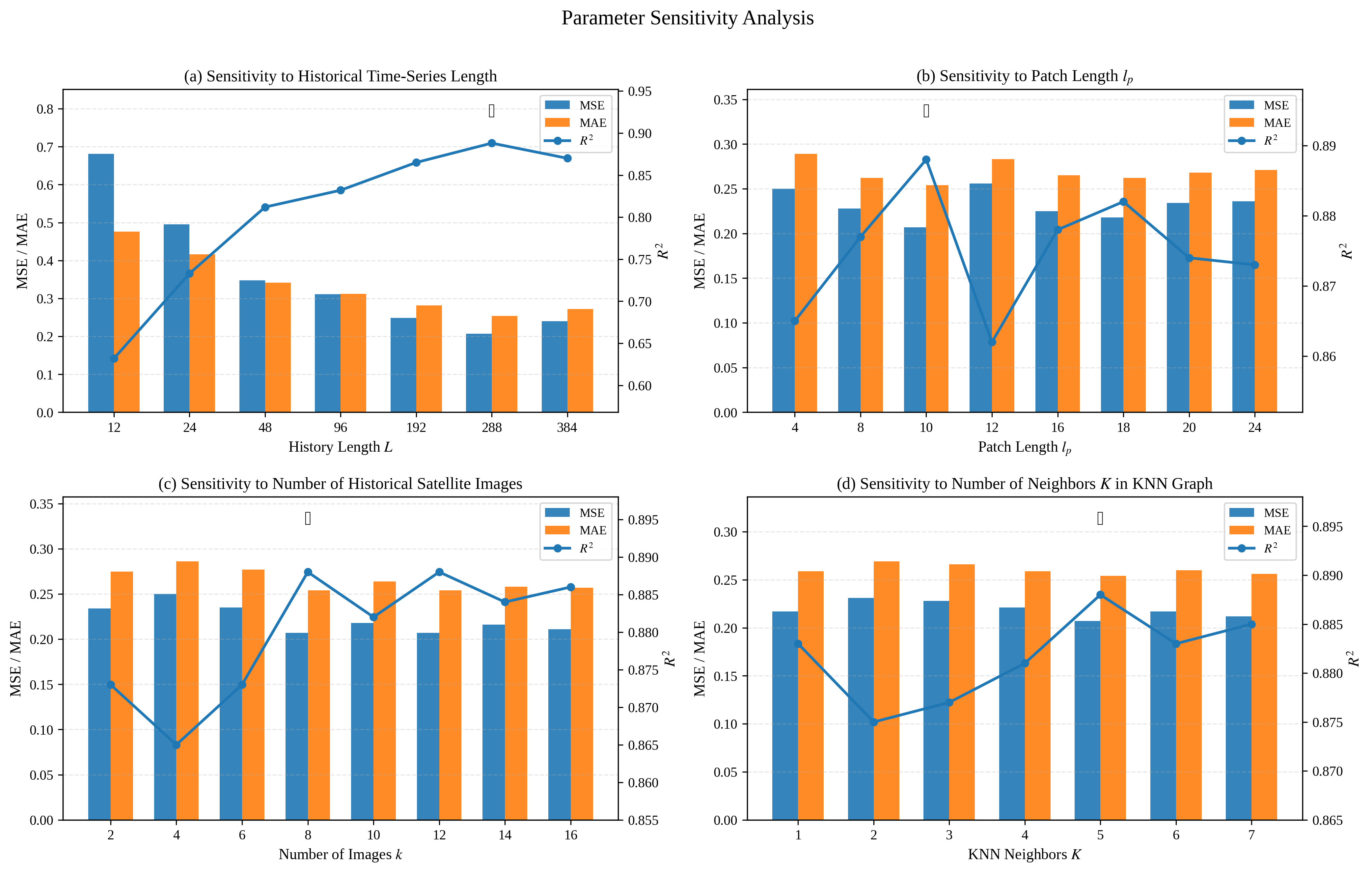
Figure 7: Sensitivity analysis of key hyperparameters.
Theoretical and Practical Implications
Solar-VLM empirically validates that large-scale pretrained VLM backbones (Qwen) significantly enhance downstream structured forecasting in energy domains when augmented with heterogeneous data (satellite, text, timeseries) and adaptive cross-site modules. The design provides a template for general multimodal, multi-site forecasting under spatiotemporal correlation, extending beyond PV (e.g., wind, temperature extremes, hydropower) under dynamic weather.
On the practical front, the system's modular encoders and interpretable pipeline (e.g., graph attention with geographical KNN, explicit context prompts for textualization) facilitate both transfer learning and rapid deployment for new sites, including possible adaptation to low-shot settings if further pretraining or retrieval augmentation is performed.
Outlook and Future Work
While Solar-VLM sets a new benchmark for multi-site, multimodal PV forecasting, several avenues remain. Few-shot adaptation, transfer under non-stationary climates, and expansion to probabilistic forecasting are promising. Further, openly available code and structured textual prompt templates offer a reproducible foundation for subsequent work in AI-augmented energy forecasting architectures.
Conclusion
Solar-VLM establishes a unified multimodal and spatial framework for PV power forecasting, leveraging vision-LLMs, structured prompt engineering, and GNN-based spatial modeling. Empirical evidence demonstrates clear performance advantages over existing methods, with the framework’s design principles likely extensible to other multimodal and multi-site time series forecasting domains.

