DINO-VO: Learning Where to Focus for Enhanced State Estimation
Abstract: We present DINO Patch Visual Odometry (DINO-VO), an end-to-end monocular visual odometry system with strong scene generalization. Current Visual Odometry (VO) systems often rely on heuristic feature extraction strategies, which can degrade accuracy and robustness, particularly in large-scale outdoor environments. DINO-VO addresses these limitations by incorporating a differentiable adaptive patch selector into the end-to-end pipeline, improving the quality of extracted patches and enhancing generalization across diverse datasets. Additionally, our system integrates a multi-task feature extraction module with a differentiable bundle adjustment (BA) module that leverages inverse depth priors, enabling the system to learn and utilize appearance and geometric information effectively. This integration bridges the gap between feature learning and state estimation. Extensive experiments on the TartanAir, KITTI, Euroc, and TUM datasets demonstrate that DINO-VO exhibits strong generalization across synthetic, indoor, and outdoor environments, achieving state-of-the-art tracking accuracy.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces DINO-VO, a system that helps a robot or camera figure out how it’s moving just by looking at a video from a single camera. This is called “monocular visual odometry” (VO). The main idea is to teach the computer to focus on the most useful parts of each image—like buildings or roads—so it can track its movement more accurately and reliably in many different places, from indoor rooms to outdoor streets.
The big questions they asked
The authors set out to answer a few simple—but important—questions:
- Can a VO system learn which parts of an image are most helpful for estimating motion, instead of picking them randomly?
- Can combining what things look like (appearance) with how far they are (geometry) make tracking better?
- Can we build an end-to-end system (trained all together) that works well across many different scenes without lots of manual tweaking?
How does DINO-VO work?
Think of the system as a careful explorer that looks at a scene, picks the best clues, and steadily updates its guess of where it is and where it’s going.
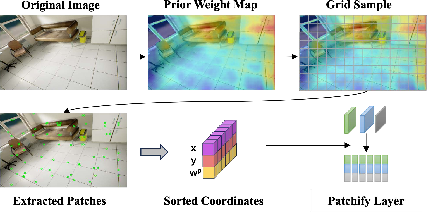
Choosing where to look: Adaptive Patch Selector
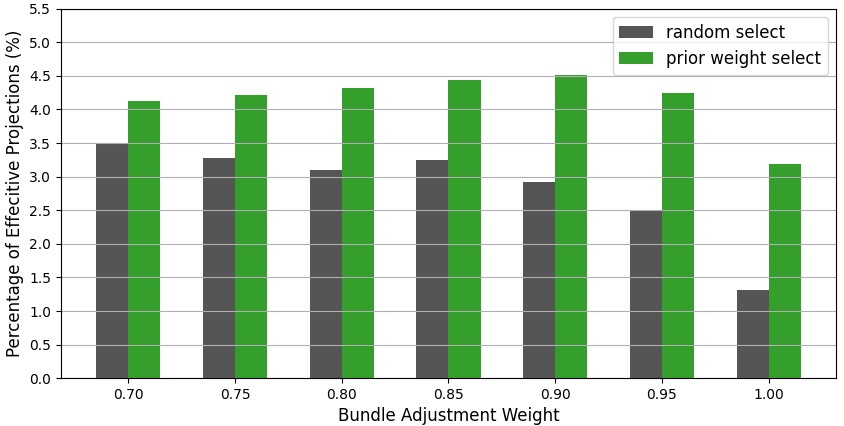
- An image is divided into many small squares called “patches.” Not all patches are helpful—patches of empty sky or blank walls often don’t help track motion.
- DINO-VO uses a learned “prior weight map,” which is like a heatmap that says, “these spots are promising.” It picks the top patches across the image (spread out so they aren’t all bunched together).
- This is better than older systems that picked patches randomly and often wasted effort on unhelpful areas.
Seeing both appearance and geometry: Multi-task Feature Extractor
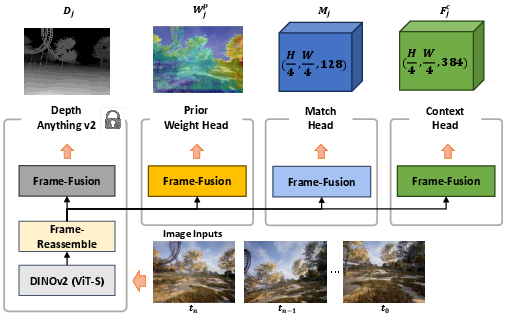
- The system uses a powerful pre-trained vision model (based on DINOv2 and Depth Anything v2) that has learned a lot about images from tons of data.
- From each input image, it extracts:
- Matching features: to find the same patch in other frames.
- Context features: extra information about the scene.
- Inverse depth (how far things are): to handle scale and distance.
- Prior weight map: a score telling which pixels are likely to be useful.
- Using one shared backbone for all these tasks keeps the system fast and memory-friendly.
Fine-tuning the path: Differentiable Bundle Adjustment
- After picking patches, the system tries to line them up across frames to figure out the camera’s path.
- It uses a built-in optimization step (bundle adjustment) that adjusts the camera positions and patch depths to best fit what it sees. “Differentiable” means this step is part of the learning process, so the whole system can improve together.
- Using the depth prior helps start with a good sense of distance, making the optimization more stable and accurate.
Learning to pick good patches: Distillation
- During training, there’s a “teacher” inside the system that estimates how useful each patch actually was after optimization (posterior weight).
- The patch picker (student) learns from these results to predict good patches ahead of time (prior weight), so at test time it can quickly choose smart patches without heavy computation.
Keeping distances consistent: Depth rescaling
- Depth predictions can have different scales in different scenes (e.g., how “big” the world looks).
- The system applies a simple rescaling step to keep depths consistent, which helps make the tracking stable.
What did they find?
The researchers tested DINO-VO on several well-known datasets:
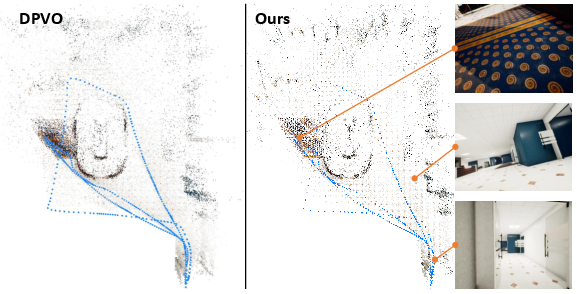
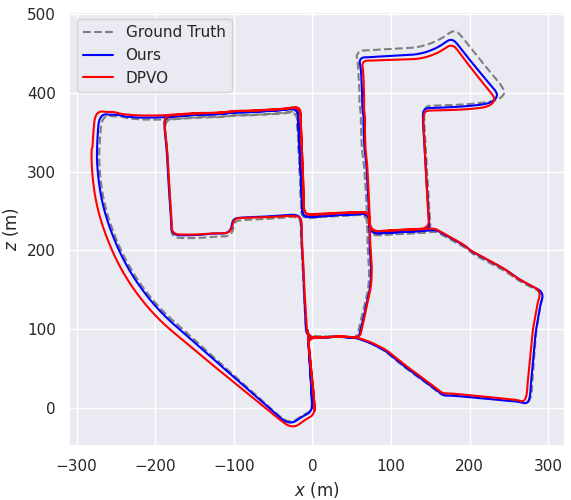
- TartanAir (synthetic, varied environments): DINO-VO achieved state-of-the-art average accuracy and especially improved performance in outdoor scenes.
- KITTI (outdoor driving): With loop closure enabled (a standard add-on that corrects drift over long drives), DINO-VO reached strong overall accuracy. Even without it, it improved over prior learning-based baselines.
- TUM-RGBD (indoor): DINO-VO had the lowest average tracking error among compared methods, showing robustness to blur and motion.
- EuRoC (indoor drone flights): It delivered consistently strong performance across sequences.
Why this matters:
- The new patch selection strategy picked more “high-weight” (actually useful) patches, which made motion estimates more accurate and maps more informative.
- The multi-task features and depth priors improved stability and generalization across very different environments.
- The whole system runs in real time.
Why it matters
DINO-VO shows that teaching a VO system “where to look” makes a big difference. By focusing on the most informative parts of images and combining appearance with geometry, it becomes more accurate and reliable across many different places—without constant manual tuning. This can help robots, drones, and AR/VR devices navigate better in the real world, indoors and outdoors, and it points toward smarter, more general-purpose visual navigation systems in the future.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper advances monocular VO with an adaptive patch selector and multi-task feature extractor. However, several aspects remain underexplored or uncertain. The following points identify concrete gaps for future work:
- Differentiability of selection: Despite being termed “differentiable,” the inference-time patch selection uses hard top-k/argmax within grid cells, which is non-differentiable. How would soft top-k/Gumbel or continuous relaxation affect training stability, selection quality, and final VO accuracy?
- Calibration of prior weights: The prior-weight head is trained via distillation from posterior weights, but there is no analysis of calibration (e.g., reliability diagrams, ECE). Are the predicted weights well-calibrated across datasets and motion regimes, and do they correlate with true marginal contributions to BA?
- Distillation target definition: The distillation target is the max posterior weight among a few projections; this conflates selection with projection count/visibility. Would alternative targets (e.g., average/robust aggregation over projections, Shapley-like marginal contribution to residual reduction, or listwise ranking losses) yield better selectors?
- Sensitivity to selection hyperparameters: The uniform grid size, number of patches N, and selection radius r are fixed and not ablated. How do these parameters trade off accuracy, runtime, and robustness? Can N and r be adaptively scheduled based on scene texture, motion, or uncertainty?
- Interaction with global modules: Loop closure and proximity are only optionally added (Ours*). How does the patch selector influence loop closure detection, place recognition, and global BA? Is there an optimal selection policy for global modules distinct from local BA?
- Depth prior dependence and failure modes: The system relies on Depth Anything v2 (frozen) to mask infinite depths and guide patch selection/initialization, yet depth priors are known to fail in adverse conditions (nighttime, adverse weather, specular/transparent surfaces, repetitive textures). What is the performance impact when the depth prior is wrong, and can the system detect and down-weight unreliable depth (e.g., via depth confidence)?
- Absolute scale and scale drift: Evaluations are scale-aligned ATE; no analysis of metric scale accuracy or long-term scale drift is provided. Does the heuristic inverse-depth rescaling ensure consistent metric scale over long trajectories, and how does it behave across different environments?
- Pure rotation and low-parallax robustness: The method still shows elevated errors in sequences with dominant rotation and low translation (e.g., EuRoC V203). What additional priors (e.g., epipolar constraints, planar scene priors) or sensors (e.g., IMU) are needed to handle degenerate motion?
- Dynamic scenes and motion segmentation: There is no explicit mechanism to detect and suppress moving objects. Does the selector inadvertently pick patches on dynamic regions? How does performance change on dynamic benchmarks, and can learned motion segmentation or robustifying losses improve stability?
- Photometric and environmental robustness: Training is on synthetic data; robustness to illumination changes, HDR conditions, low light, strong exposure variations, and lens artifacts (e.g., glare) is not evaluated. Which augmentations or invariant features improve generalization to these conditions?
- Camera model and rolling-shutter effects: The system assumes a pinhole model with known intrinsics. Handling of rolling-shutter distortions, calibration errors, and fisheye/wide-angle lenses is unaddressed. How does performance degrade under RS, and can RS-aware BA be integrated?
- Differentiable BA stability and gradient flow: The paper does not analyze numerical stability, conditioning, or gradient quality through the sparse BA layer. What damping/regularization is optimal, and how do second-order choices (e.g., Gauss-Newton vs. LM) affect learnability and convergence?
- Use of external priors during optimization: Depth priors are only used for selection and initialization, not as soft constraints within BA. Would inserting depth factors (with learned uncertainties) into BA improve convergence and scale consistency?
- Multi-task interference and backbone freezing: The ViT-S backbone is frozen to save VRAM and domain-shift issues are mentioned, but the degree of task interference among matching, context, depth, and prior-weight heads is not studied. Does partial fine-tuning or adapter-based tuning improve performance without overfitting?
- Search range and patch size design: The 7×7 correlation window and patch size p are fixed without ablation. Are larger learned search ranges or multi-scale correlations beneficial, especially for fast motions or larger baselines?
- Runtime and resource profiling: Real-time claims are made without reporting FPS, latency breakdown, and memory usage per module. What is the throughput on embedded hardware, and where are the primary bottlenecks?
- Robustness to occlusion and viewpoint change: There is no quantitative evaluation of how the selector and matcher handle self-occlusion, disocclusion, and large viewpoint changes. Can occlusion-aware costs or visibility prediction improve BA robustness?
- Reinitialization and failure analysis: The paper lacks systematic characterization of failure modes (e.g., when tracking is lost) and reinitialization behavior. Under what conditions does the system diverge, and can the selector be used to trigger or guide recovery?
- Evaluation breadth and metrics: Only ATE (scale-aligned) is reported. Relative pose error (RPE), rotation vs. translation error decomposition, long-term drift, re-localization success, and map quality metrics (e.g., point distribution density, repeatability) are not analyzed.
- Sparse-to-dense mapping extensions: The approach yields sparse maps but does not explore densification leveraging the depth prior. Can the selector guide sparse-to-dense refinement or hybrid mapping (e.g., semi-dense/dense) without sacrificing real-time performance?
- Domain adaptation of depth: The depth backbone is frozen to avoid domain shift, yet that prevents adaptation to new environments. Can lightweight on-the-fly adaptation (e.g., test-time training, entropy minimization, or confidence-guided fine-tuning) enhance depth reliability and, in turn, VO performance?
- Prior-weight head training schedule: The head is frozen for the first 5k iterations; no study of schedule sensitivity is provided. Do different warm-up lengths or alternating update schemes improve learning stability and final accuracy?
- Hyperparameter selection for negative mining: The distillation process keeps only one-tenth of non-zero weights below 0.1 as negatives; this is heuristic. Is there a principled way (e.g., curriculum learning or hard-negative mining) that improves selector generalization?
- Robustness to intrinsics errors: The pipeline assumes known K. How sensitive is the system to small calibration errors, and can joint intrinsics refinement be included without destabilizing training?
- Open-source and reproducibility: Several implementation details of the hidden state updater and BA (e.g., damping, linear solver choice) are not specified, and code availability is not stated. Releasing code and full training scripts would enable the community to validate and extend the method.
Practical Applications
Immediate Applications
Below are near-term, deployable uses that can leverage DINO-VO’s end-to-end monocular visual odometry, adaptive patch selection, and depth-prior–aided differentiable bundle adjustment.
- Monocular VO module for GPS-denied navigation in ground and aerial robots (Robotics, Drones)
- What to build: A ROS2 node offering real-time odometry, map, and pose for AMRs, UAVs, UGVs.
- Workflows: Fuse with wheel odometry or IMU; plug into nav2/move_base for localization and path following.
- Assumptions/Dependencies: Calibrated monocular camera; consistent frame rate; moderate compute (GPU/edge AI recommended); loop-closure optional for longer missions; challenging lighting/dynamics may require IMU fusion.
- Cost-down localization retrofit for warehouse AGVs/AMRs (Logistics, Manufacturing)
- What to build: Replace or complement LiDAR with monocular VO for aisle navigation and docking.
- Workflows: VO + fiducial/AprilTag anchors for drift correction; periodic map alignment.
- Assumptions/Dependencies: Adequate texture and lighting; safety requires redundancy (e.g., IMU, wheel odometry); loop closure or landmarks reduce drift on long routes.
- Visual fallback/localization redundancy for low-speed autonomous shuttles and delivery robots (Automotive, Last-mile Delivery)
- What to build: Visual odometry as a redundant channel alongside GNSS/IMU for reliability in urban canyons or parking structures.
- Workflows: Sensor fusion stack (EKF/UKF) incorporating VO; health monitoring that switches to VO when GNSS drops.
- Assumptions/Dependencies: Highly dynamic scenes may reduce VO stability; regulatory frameworks require safety cases; VIO preferred in motion-blur/high-speed conditions.
- Improved indoor AR experiences on mobile devices (Software, AR/VR)
- What to build: A VO plugin that emphasizes informative patches (e.g., edges, corners) to reduce drift on blank walls and glossy floors.
- Workflows: Integrate into ARCore/ARKit pipelines or independent AR SDKs; pre-alignment for room-scale AR.
- Assumptions/Dependencies: On-device compute limits; model compression/quantization may be needed; camera intrinsics must be known.
- Construction and AEC progress tracking with monocular body-worn/robot cameras (Construction, AEC)
- What to build: A workflow that estimates trajectories and sparse maps from helmet/drone videos for coverage analysis and progress verification.
- Workflows: VO trajectory alignment to BIM/GIS; automated drift correction via fiducials or loop closure.
- Assumptions/Dependencies: Motion blur and repetitive patterns can affect accuracy; occasional loop closures or anchors recommended.
- Infrastructure inspection in feature-scarce environments (pipelines, tunnels, culverts) (Energy/Utilities, Infrastructure)
- What to build: VO for crawlers/drones that prioritizes rivets/edges and rejects sky/blank surfaces, improving stability in long corridors.
- Workflows: Onboard VO for real-time localization; offline sparse map for defect geotagging.
- Assumptions/Dependencies: Adequate illumination; vibration control; environmental robustness (dust/water); compute at the edge.
- Video stabilization and camera-motion analytics for post-production (Media/Entertainment)
- What to build: A plug-in that uses VO trajectories for advanced stabilization and shot analysis.
- Workflows: Batch processing in NLEs; export stabilized footage plus camera paths for VFX.
- Assumptions/Dependencies: Rolling-shutter artifacts and heavy blur may require correction models; compute-time budgets for post-production.
- Pre-alignment for SfM/photogrammetry pipelines (Mapping/Surveying)
- What to build: Use VO to provide initial camera poses for COLMAP/Metashape to speed convergence and reduce outliers.
- Workflows: VO for sequential video frames; feed initial poses and sparse tracks to downstream bundle adjustment.
- Assumptions/Dependencies: Remaining scale ambiguity addressed later; loop closures/dense matching still needed for global consistency.
- Security/Facility patrol robots in GNSS-denied indoor environments (Security, Facilities Management)
- What to build: Reliable VO that focuses on informative structures (door frames, signage) for robust patrolling and anomaly geotagging.
- Workflows: VO + periodic map maintenance; integration with access-control or sensor systems.
- Assumptions/Dependencies: Dynamic obstacles/people handling; privacy governance for video capture; resilience to lighting changes.
- Low-cost SLAM education kits and benchmarking (Education, Academia)
- What to build: Course labs and open-source benchmarks showcasing end-to-end VO, patch selection, and depth-prior integration.
- Workflows: Reproducible pipelines on open datasets (TartanAir, EuRoC, TUM); ablations on patch selectors and BA.
- Assumptions/Dependencies: GPU recommended for real-time; dataset licenses and consistent training/testing splits.
- Agriculture row-following and orchard navigation with monocular cameras (Agriculture)
- What to build: VO-assisted guidance that focuses on canopy/row edges to maintain path in repetitive vegetation scenes.
- Workflows: Combine VO with row/line detection; map-based coverage analytics.
- Assumptions/Dependencies: Wind-driven dynamics and specular leaves can affect texture; IMU fusion beneficial; consistent daylight or auxiliary lighting.
- Assistive indoor navigation prototypes for visually impaired users (Healthcare/Assistive Tech)
- What to build: Monocular VO on a smartphone or wearable for short-range positioning in familiar buildings.
- Workflows: Haptic/audio cues driven by VO; lightweight anchors at key locations for drift mitigation.
- Assumptions/Dependencies: Safety-critical; robust real-time on-device inference required; drift control via opportunistic loop closure.
Long-Term Applications
These opportunities require additional research, scaling, and/or engineering before widespread deployment.
- Fully integrated visual-inertial odometry (VIO) with learned loop closure and global optimization (Robotics, Automotive)
- Potential: Combine DINO-VO with IMU and learned place recognition for end-to-end, globally consistent navigation.
- Dependencies: Robust training across dynamics, failure recovery, certification for safety-critical use.
- Dense real-time 3D mapping by coupling DINO-VO with NeRF/3D Gaussian Splatting (AEC, Digital Twins, Entertainment)
- Potential: Use high-quality patch selection and VO poses to drive dense, photorealistic mapping for site twins and virtual production.
- Dependencies: Significant compute; memory management; handling dynamic content; real-time rasterization on embedded platforms.
- On-device/mobile deployment through model compression and distillation (Software, AR/VR, Consumer)
- Potential: Quantized/accelerated ViT-S + heads running on NPUs for smartphones/AR glasses.
- Dependencies: Hardware heterogeneity; latency/thermal budgets; legal/usage constraints on pre-trained depth models.
- Camera-only navigation for low-speed vehicles in controlled environments (Policy, Automotive, Micromobility)
- Potential: Regulatory frameworks around monocular-only navigation for specific geofenced zones (campuses, warehouses).
- Dependencies: Safety cases, fail-operational design, standardized tests; drift handling via infrastructure markers.
- Multi-robot collaborative SLAM using shared patch-importance maps (Robotics, Swarm Systems)
- Potential: Robots exchange compact feature/importance summaries to speed joint mapping and reduce bandwidth.
- Dependencies: Time synchronization, robust comms, consensus on scale and map frames.
- Privacy-preserving mapping and analytics (Policy, Security, Consumer)
- Potential: Store only sparse features/trajectories and discard raw images to reduce privacy risk while retaining utility.
- Dependencies: Policy acceptance, demonstrable anonymization, traceability for audits; balance between utility and privacy.
- Continual/self-supervised adaptation to new domains (Academia, Industry R&D)
- Potential: Online fine-tuning of patch selector and depth priors to handle novel textures, lighting, or sensors.
- Dependencies: Catastrophic forgetting safeguards, fast adaptation without ground truth, on-device learning constraints.
- Facility-wide digital twin maintenance via routine monocular patrols (Facilities, Manufacturing)
- Potential: Automated change detection and asset tracking with frequent VO-based scans aligned to a master twin.
- Dependencies: Reliable loop closure and alignment; scalable map storage and versioning; integration with CMMS.
- Hazardous-environment inspection at scale (nuclear, offshore, deep underground) (Energy, Public Safety)
- Potential: Ruggedized monocular VO for low-light, high-radiation areas where other sensors are impractical.
- Dependencies: Radiation/EMI-tolerant hardware, extreme lighting mitigation, robust thermal envelopes.
- Standards and benchmarks for learning-based VO/SLAM with patch-selection metrics (Policy/Standards, Academia)
- Potential: Formal test suites that quantify feature/patch utility and generalization across indoor/outdoor domains.
- Dependencies: Community consensus, dataset curation, reproducible baselines and metrics.
Cross-cutting Assumptions and Dependencies
- Camera calibration and image quality: Accurate intrinsics and manageable motion blur are critical.
- Compute envelope: The paper demonstrates real-time on an RTX-class GPU; embedded deployment may require pruning/quantization.
- Scale handling: Monocular VO has inherent scale ambiguity; DINO-VO mitigates with depth priors and rescaling but long-term consistency still benefits from loop closure/anchors.
- Environment variability: Texture-poor, low-light, or highly dynamic scenes may need sensor fusion (IMU, wheel odometry) and robust illumination.
- Data and licensing: Usage of pre-trained models (e.g., Depth Anything v2) must respect licenses; synthetic-to-real generalization is strong but may still need domain adaptation in edge cases.
Glossary
- 3D Gaussian Splatting (3DGS): A point-based scene representation that models surfaces as spatial Gaussians enabling fast differentiable rendering and mapping. Example: "3DGS~\cite{kerbl20233d} based SLAM systems~\cite{li2026artdeco, li2025constrained, deng2025best3dscenerepresentation, deng2025gaussiandwm3dgaussiandriving, deng2024compact}, such as SplaTAM~\cite{keetha2024splatam}, Gaussian Splatting SLAM~\cite{matsuki2024gaussian}, Photo-SLAM~\cite{huang2024photo}, and RTG-SLAM~\cite{peng2024rtg}, combined the fully differential feature of volumetric rendering and fast rasterization speed of 3DGS."
- Absolute Trajectory Error (ATE): A standard metric for camera trajectory accuracy measuring deviation from ground truth after alignment. Example: "We use the ATE RMSE (Absolute Trajectory Error Root Mean Squared Error) metric with scale alignment (in meters) for camera tracking,"
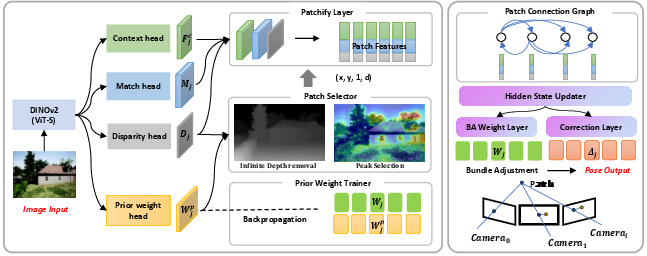
- Adaptive Patch Selector: A learnable module that selects informative image patches for optimization to improve VO/SLAM accuracy and efficiency. Example: "The Adaptive Patch Selector selects high-weight patch features for bundle adjustment."
- AdamW: An optimizer variant combining Adam with decoupled weight decay, widely used in deep learning training. Example: "using the AdamW optimizer with an initial learning rate of 8e-5,"
- Area Under the Curve (AUC): Aggregate performance measure (often for error-threshold curves) summarizing accuracy across thresholds. Example: "Our method achieves an AUC of 0.85,"
- Bipartite patch graph: A graph connecting patch nodes to frame nodes to encode their projection relationships for optimization. Example: "We construct a bipartite patch graph by connecting a patch to every frame within a distance from ,"
- Bundle Adjustment (BA): Nonlinear optimization jointly refining camera poses and scene structure using reprojection errors. Example: "a differentiable bundle adjustment (BA) module that leverages inverse depth priors,"
- DBoW: A bag-of-words approach for visual place recognition and loop detection in SLAM. Example: "and DBoW~\cite{galvez2012bags} for loop closure detection,"
- Dense Bundle Adjustment Layer: A learned differentiable module performing BA over dense correspondences within an end-to-end SLAM. Example: "and a Dense Bundle Adjustment Layer to evaluate the pose difference,"
- Depth Anything v2: A pre-trained monocular depth estimation model providing depth priors for geometry-aware learning. Example: "we incorporate the pre-trained monocular depth estimation model, Depth Anything v2\cite{depthanything},"
- DINOv2: A self-supervised vision transformer backbone yielding strong, general-purpose visual features. Example: "The ViT-S version of DINOv2\cite{oquab2024dinov2} serves as our feature extraction backbone,"
- Direct method: A VO/SLAM approach optimizing image intensities directly rather than extracted features. Example: "LSD-SLAM~\cite{lsdengel2014} used a direct method by optimizing pixel intensities"
- Distillation: Training strategy where one model (student) learns signals from another model (teacher) to transfer knowledge. Example: "we perform distillation from the hidden state updater to our prior weight head"
- DPT head: Dense Prediction Transformer head used to produce dense outputs (e.g., depth) from transformer features. Example: "rather than utilizing four full DPT heads~\cite{dpthead}."
- Extended Kalman Filter (EKF): A state estimation technique linearizing nonlinear dynamics for recursive filtering. Example: "employed an Extended Kalman Filter (EKF) for optimization in the backend."
- Factor graph: A graphical model expressing optimization problems where variables and factors (constraints) are nodes. Example: "to optimize the pose in the factor graph."
- FAST corners: A fast corner detection algorithm commonly used for feature-based tracking. Example: "The tracking thread used FAST corners~\cite{rosten2006machine} for pose estimation,"
- Fusion layers: Lightweight heads that fuse multi-scale backbone features to produce task-specific outputs. Example: "all of our extractor heads in Fig.\ref{fig:system} are four Fusion layers"
- Hidden state updater: A recurrent module maintaining and updating latent states to output weights and flow corrections. Example: "are then fed into the hidden state updater to estimate a posterior weight"
- Inverse depth: Representing depth as its reciprocal to improve numerical stability in monocular geometry. Example: "leverages inverse depth priors,"
- Keyframe-based camera tracking: Tracking paradigm that selects representative frames (keyframes) to stabilize estimation and mapping. Example: "an entirely learned system for dense keyframe-based camera tracking and depth map estimation."
- Loop closure: Detecting revisited places to correct drift via global pose graph optimization. Example: "and introduced a loop closure detection thread."
- Monocular depth estimation: Predicting per-pixel scene depth from a single RGB image. Example: "the pre-trained monocular depth estimation model, Depth Anything v2"
- Neural Radiance Fields (NeRF): An implicit neural scene representation enabling differentiable view synthesis and mapping. Example: "NeRF~\cite{mildenhall2021nerf} based SLAM systems"
- Optical flow: The apparent motion field of pixels between images, used for correspondence and motion estimation. Example: "to estimate the optical flow"
- ORB features: Binary features (Oriented FAST and Rotated BRIEF) used for robust feature-based SLAM. Example: "It used ORB features~\cite{orb} for tracking"
- Patchify layer: An operator that slices feature maps into fixed-size patches for local matching and correlation. Example: "is the matching feature of the patch extracted from by patchify layer,"
- Posterior weight: The confidence weight predicted after data association, used to weight residuals in BA. Example: "to estimate a posterior weight "
- Prior weight map: A predicted per-pixel importance map guiding which patches to select before optimization. Example: "the prior weight head predicts prior weight map for frame ."
- RAFT: A deep network (Recurrent All-Pairs Field Transforms) for high-accuracy optical flow estimation. Example: "By using RAFT-like approaches~\cite{teed2020raft} to estimate the optical flow"
- Rasterization: Converting geometric primitives to pixels; here emphasizing speed advantages in Gaussian splatting. Example: "fast rasterization speed of 3DGS."
- Reassemble Layers: Decoder layers that upsample/rearrange transformer tokens into multi-scale feature maps. Example: "share the same Reassemble Layers of Depth Anything v2~\cite{depthanything},"
- Scale alignment: Aligning estimated trajectories to ground truth scale before error computation. Example: "Results are reported as the ATE with scale alignment,"
- Scale ambiguities: The indeterminate metric scale inherent to monocular geometry without additional priors. Example: "These depth priors help mitigate scale ambiguities and improve mapping accuracy and system stability."
- Self-attention selection mechanism: An attention-based approach to score and pick informative patches/features. Example: "We implemented a self-attention selection mechanism using a multi-task feature extractor"
- Simultaneous Localization and Mapping (SLAM): Estimating a sensor’s pose while building a map of the environment. Example: "Visual Odometry is a foundational technology in robotics and autonomous systems, closely intertwined with Simultaneous Localization and Mapping (SLAM)."
- Sparse Bundle Adjustment Layer: A differentiable layer performing BA over a sparse set of patch correspondences. Example: "The Sparse Bundle Adjustment Layer performs bundle adjustment to optimize the pose in the factor graph."
- Sparse optical flow: Flow computed only at selected points/patches to reduce memory and compute versus dense flow. Example: "by using sparse optical flow instead of dense optical flow,"
- Visual Odometry (VO): Estimating camera motion from visual inputs without building a persistent global map. Example: "We present DINO Patch Visual Odometry (DINO-VO), an end-to-end monocular visual odometry system"
- ViT-S: The small variant of a Vision Transformer used as a lightweight backbone. Example: "The ViT-S version of DINOv2\cite{oquab2024dinov2} serves as our feature extraction backbone,"
- Volumetric rendering: Rendering technique integrating density and color along rays through a volume (e.g., NeRF). Example: "used all kinds of map encodings to realize volumetric rendering."
Collections
Sign up for free to add this paper to one or more collections.

