- The paper introduces a hardware extension that enables deterministic user-level interrupt delivery using CAM-based IID lookup and shadow register banking to achieve 11-cycle latency.
- It demonstrates over 50× reduction in worst-case interrupt latency and >60× jitter improvement compared to traditional kernel-mediated approaches.
- The design enforces strict spatial and temporal isolation, supporting secure user-level integration in microkernel architectures for critical cyber-physical system deployments.
Deterministic User-Level Interrupts in Real-Time Processors via Hardware Extension
Introduction and Motivation
This work addresses the fundamental challenge of achieving deterministic, low-latency, user-level interrupt handling in real-time embedded systems that require strong temporal and spatial isolation of software components. The increasing complexity and compositional diversity in cyber-physical systems (CPS)—notably in autonomous vehicles, medical devices, and industrial controllers—demand strong compartmentalization. Traditionally, to guarantee minimal interrupt latency, device interrupts must execute in a privileged kernel to avoid the overhead of user-kernel transitions, undermining both security (attack surface, fault containment) and system certification. Prior hardware extensions (e.g., Intel UIPI, RISC-V N extension) opportunistically deliver interrupts directly to user-mode only if the destination process is scheduled; otherwise, they fall back to unpredictable, high-latency kernel mediation. This bimodal behavior is incompatible with hard real-time requirements where worst-case latency, not average-case, determines system correctness.
Hardware Extension Architecture
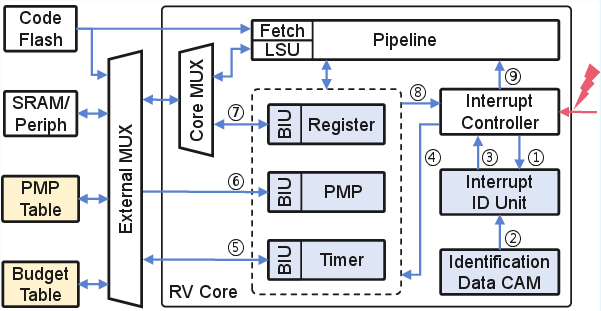
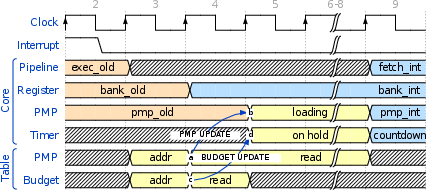
The proposed hardware extension, implemented on a RISC-V RV32IM base core, introduces a datapath and memory-backed microarchitectural units to support fully deterministic, secure user-level interrupt delivery regardless of the process's scheduling state. The architecture consists of the following key components:
The extension supports seamless integration into modern single-address-space microkernel architectures, with hardware APIs abstracted as hardware-managed "threads" scheduled via system-level calls.
Design Space Exploration and Implementation
A suite of five implementation variants (V1–V5) is explored to quantify the latency–area–power trade-off:
The area and power overheads are rigorously reported, with V5 representing an absolute upper bound of 2% on total SoC die area (45 nm node) and around 4% increase in dynamic power—well within practical bounds for modern CPS use cases.
API Integration and Software Abstraction
A kernel API enables user processes to program user-level handlers through a secure registration flow, mapping interrupt IDs to handler entry points, policies, and PMP/budget domains. Interrupts are autonomously handled by hardware, and the entire workflow is backward compatible, with negligible kernel source modifications.
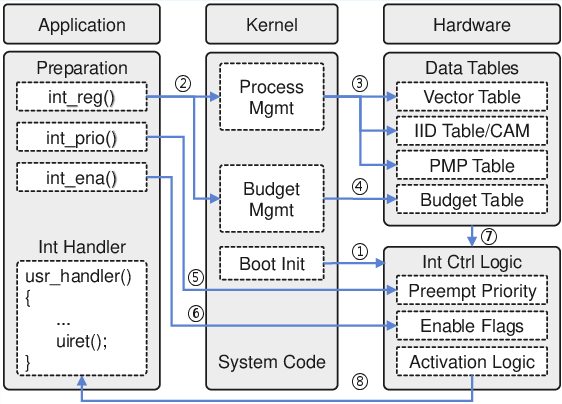
Figure 3: User-level interrupt API and the software-hardware workflow, showing handler registration and activation steps.
Evaluation and Numerical Results
Latency Determinism
Comprehensive evaluation on an FPGA platform demonstrates that all hardware extension variants outperform software-only and contemporary opportunistic hardware (Intel UIPI/RISC-V N). For inactive processes, all baseline methods exhibit catastrophic worst-case degradation (e.g., kernel mediation: >800 cycles, INTEL-style: bimodal with low best-case but high worst-case). All extension variants maintain their minimal latency regardless of process activity.
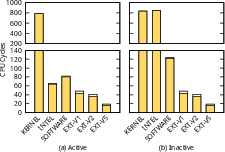
Figure 4: Raw interrupt latency (CPU cycles) for various schemes; extension V5 achieves consistently low latency under all execution contexts.
Industrial Application Metrics
The paper evaluates canonical CPS workloads—pulse train output (PTO) generation and Modbus-RTU co-location—with hard jitter and throughput requirements.
- PTO Frequency and Jitter: The extension supports an order-of-magnitude higher sustainable PTO frequencies and >60× jitter reduction at frequency ranges critical for robotics and industrial control, compared with kernel-based handling.
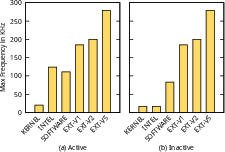
Figure 5: Maximum achievable Pulse Train Output (PTO) frequency across evaluated interrupt delivery mechanisms.
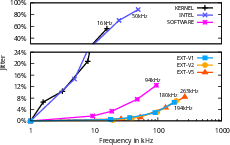
Figure 6: Normalized jitter as a function of PTO frequency, demonstrating minimal timing variance for hardware extensions even under process interleaving.
- Task Colocation & Load Isolation: During high-rate Modbus interrupts, best-effort background recognition workload throughput is preserved with less than 15% performance loss for V5 at 1 Mbps, versus 52% loss for software mediation.
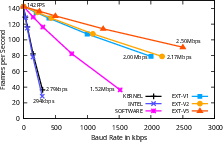
Figure 7: Achievable FPS for a background task as a function of foreground Modbus-RTU baud rate; hardware extensions maintain high throughput under heavy interrupt load.
Isolation and Security
All variants enforce strict spatial/temporal isolation: attempts at illegal memory access or budget overrun by handlers result in immediate, automatic preemption by hardware, safeguarding kernel and co-resident processes against attack or denial-of-service conditions. Only minimal kernel code is needed to leverage this architecture, enabling deployment within existing microkernels with negligible SLoC increase.
Implications and Future Perspectives
The research extends the user-level interrupt model from opportunistic, best-effort acceleration to true, deterministic hard real-time delivery for user-level domains, without compromising security via expanded kernel attack surface. Practically, this re-enables real-time system consolidation and third-party/untrusted component integration without sacrificing worst-case response times or requiring extensive re-certification.
From a theoretical perspective, the work delineates the minimal microarchitectural primitives required for worst-case latency isolation in a modern SASOS, providing a template for future RISC-V or ARM IP extensions. The paper briefly notes the feasibility of porting analogous mechanisms to MMU-based systems, suggesting future work towards deterministic isolation in more general-purpose, possibly multicore, architectures.
Conclusion
The presented hardware extension achieves deterministic, secure user-level interrupt delivery in real-time processors with strong worst-case guarantees. Strong numerical results include over 50× reduction in worst-case latency, >60× jitter improvement, and negligible SoC area/power penalty, all while maintaining strict compartmentalization. The architecture is suitable for industrial, automotive, and safety-critical embedded CPS deployments and opens a path to principled consolidation of untrusted code in safety/security-critical real-time systems (2604.04015).