- The paper presents a RAG-based agentic AI system that automates multiple-choice coding question generation with human expert intervention.
- It employs a dual-agent architecture with a Generator (GPT-4.1) and a Validator (GPT-5-mini) that use deterministic arithmetic and sandboxed code execution.
- System evaluations show precision rates from 79.9% to 98.6%, ensuring technical reliability while highlighting challenges in distractor quality.
CODE-GEN: A Human-in-the-Loop, RAG-Based Agentic AI System for Multiple-Choice Question Generation
System Architecture and Agentic Workflow
CODE-GEN operationalizes recent advances in RAG and agentic AI to construct a dual-agent, tool-augmented pipeline for the automated generation and validation of multiple-choice coding comprehension questions. The architecture is explicitly human-in-the-loop: instructors provide course-specific materials, which are indexed and segmented using a domain-tailored chunking strategy that preserves semantic coherence for instructional alignment. Upon user query, the system retrieves contextually relevant exemplars via a FAISS-accelerated nearest-neighbor search, constraining LLM output to maximize alignment with specified learning objectives.
A Generator agent (GPT-4.1) synthesizes question items, leveraging deterministic arithmetic evaluation and producing full MCQ artifacts: stem, code, options, and explanatory feedback. The Validator agent (GPT-5-mini), independently parameterized, audits question quality across seven MCQ-specific pedagogical dimensions, with access to both deterministic arithmetic evaluation and a sandboxed Python runner for scalable and secure code execution verification.
Figure 1: CODE-GEN implements an end-to-end RAG-augmented dual-agent workflow, supporting role-specialized generation and validation steps.
Such architectural separation enables independent optimization of generative and evaluative capabilities. Prompts enforce role separation, explicit criteria, and JSON-conformant output for downstream parsing and analysis. The web-based UI further integrates seamless SME-in-the-loop evaluation of both the generated items and tool-based validations.
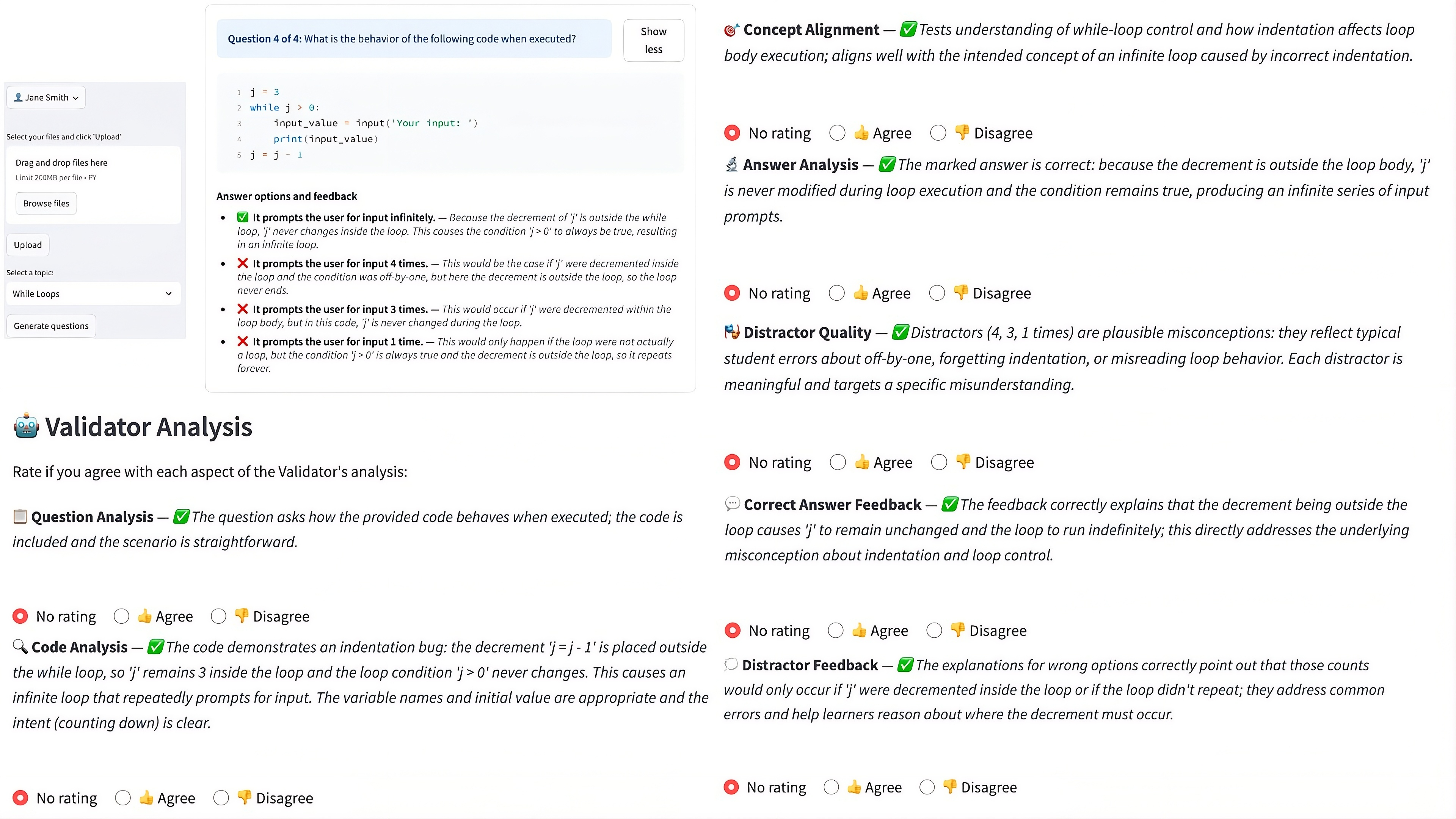
Figure 2: The web interface surfaces MCQ item details and per-dimension validator assessments for streamlined SME review and adjudication.
CODE-GEN’s RAG pipeline is engineered for educational context specificity, utilizing structured chunking preserving docstrings and instructional intent, OpenAI embedding for vector representation, and FAISS IndexFlatL2 for performant retrieval. Injecting exemplars into the generator prompt reduces context hallucinations and optimizes for instructional and conceptual alignment, as validated by downstream expert assessment.
Arithmetic and program-execution limitations of LLMs are systematically mitigated through tool augmentation. Both Generator and Validator agents invoke deterministic evaluators for multi-step arithmetic expressions and sandboxed runners for Python code, providing reliable, non-stochastic corrections. This explicit tool mediation distinguishes CODE-GEN from non-augmented LLM-based MCQ generation pipelines and directly improves system reliability on dimensions dependent on computational or code-output verifiability.
A cohort of six domain-expert SMEs systematically adjudicated 288 CODE-GEN-generated MCQ items, resulting in 2,016 human-AI judgment pairs across seven pedagogical dimensions. The evaluation protocol treats SME ratings as ground truth, enabling the calculation of Validator agent sensitivity and specificity for each criterion. SME disagreement required explicit rationale, supporting qualitative failure analysis.
System-level analysis demonstrates precision rates from 79.9% to 98.6% depending on dimension. For concept alignment, the pipeline achieves 98.6% SME-validated success; question stem clarity and code validity follow at 97.9% and 95.5%, respectively. False positive rates remain at or below 3.1% for technical or form-based criteria. Correct answer validity and feedback quality also exceed 92% human-validated concordance.
Figure 3: Human-validated success rates by evaluation dimension, demonstrating high system-level reliability for explicit, computation-verified criteria.
Contrarily, distractor quality yields the lowest human-validated success (79.9%), reflecting the persistent limitations of LLMs in synthesizing pedagogically meaningful distractors that target real student misconceptions. Distractor feedback quality also lags, suggesting high risk of shallow or mechanistic rationales in the absence of deeper instructional modeling.
Qualitative SME disagreement analysis reveals that coverage and clarity dimensions benefit directly from RAG grounding and tool assurance, while pedagogical depth (e.g., distractor plausibility, instructional feedback) still requires expert judgment. False negatives frequently expose limitations in Validator schema-tracking, such as index-value mappings or output-classification inconsistencies. These constitute tractable yet non-trivial failure modes, implicating the need for continued prompt and system refinement.
Implications and Comparative Perspective
CODE-GEN demonstrates that RAG-based agentic architectures, reinforced by appropriate tool augmentation, provide robust first-line automation for technical and context-aligned MCQ generation in programming education. The empirical separation between verifiable, rule-based criteria and criteria requiring deep pedagogical insight supports a principled human-AI division of labor: automated agents can scale generation and validation, but instructional validity and the targeting of common misconceptions remain fundamentally dependent on expert intervention.
The system addresses key limitations in prior LLM-generated MCQ pipelines, including hallucination, context drift, and arithmetic/code execution errors. The explicit integration of tool calling for deterministic sub-tasks reflects prevailing trends in high-accuracy educational LLM applications (2604.03926, Han et al., 2024). However, as with parallel human-AI collaborative pipelines in MCQ generation and feedback (Lee et al., 2024, Chen et al., 2024), CODE-GEN's results indicate that full pedagogical automation remains elusive, especially in multi-faceted instructional domains.
In practical terms, CODE-GEN provides high-throughput, scalable MCQ item generation and triage for large question banks, with clear recommendations for targeted human review at critical pedagogical bottlenecks. The system and its validation framework provide a template for the development and rigorous measurement of future RAG-augmented, agentic AI educational systems.
Future Directions
The presented architecture is not fundamentally domain-limited; analogous pipelines can be ported to other knowledge areas (e.g., mathematics, data science). The aggregated SME-AI rating dataset provides a rich resource for RLHF or validator fine-tuning informed by real pedagogical failure modes. Extension to more expressive multi-agent coordination (e.g., iterative generation-critique-regeneration loops) (Cao et al., 8 May 2025), advanced misconception modeling, and integration of student answer traces for dynamic distractor calibration are viable avenues to close the remaining AI-human gap. Systematic exploration of schema-tracking, richer negative-sample generation, and prompt-based schema validation could further attenuate Validator classification inconsistencies.
Conclusion
CODE-GEN operationalizes an effective RAG-based agentic pipeline for MCQ generation and validation that is robust across technical and form-centric criteria, but less reliable for deep pedagogical judgment and misconception modeling. The work establishes clear design patterns for scalable, reliably validated, AI-assisted educational content generation, and provides actionable design insights for maximizing human-AI complementarity in instructional assessment pipelines (2604.03926).