- The paper presents a framework for multi-task RL that jointly recovers low rank reward representations and optimal policies.
- It combines reward-free exploration with SVD-based estimation to derive provable bounds on sample complexity and cumulative regret.
- Empirical results in control and grid maze environments confirm its efficiency over conventional baselines.
Provable Multi-Task Reinforcement Learning with Low Rank Rewards: A Representation Learning Framework
Introduction
The paper "Provable Multi-Task Reinforcement Learning: A Representation Learning Framework with Low Rank Rewards" (2604.03891) presents a framework for Multi-Task Representation Learning in Reinforcement Learning (MTRL-RL). The central premise involves multiple linear MDPs sharing the state-action space and transition kernel, but exhibiting distinct reward functions. The crucial structural assumption is that the reward matrices admit a low-rank latent embedding, facilitating joint representation learning across tasks.
The authors' methodology circumvents conventional assumptions—such as Gaussian feature distributions, incoherence, or access to optimal solutions—by embracing more generic policy-dependent feature distributions. This perspective aligns with practical RL scenarios where idealized assumptions are frequently violated, thus enhancing the applicability of their results.
The paper formalizes the multi-task RL setting with T tasks, each corresponding to an MDP (S,A,{Rht}h=1H,{Ph}h=1H) sharing states, actions, and transitions. The reward for each task-adaptive policy is parameterized linearly via
Rht(s,a)=⟨θht,ψ(s,a)⟩
with feature embeddings ψ(s,a)∈Rd and reward parameters θht. The reward matrices Θh (of shape T×d) are assumed to be rank r≪d,T.
The learning objective is joint estimation of reward parameters and construction of ϵ-optimal policies Π^⋆(t) for each task. The critical technical goal is robust low-rank recovery of (S,A,{Rht}h=1H,{Ph}h=1H)0 and corresponding regret guarantees.
Algorithmic Framework
The MTRL-RL algorithm operates in four stages:
- Stage 1: Reward-Free RL – Data-collection policies are obtained without reward access, guaranteeing broad state-action exploration.
- Stage 2: Exploration Policy Construction – The reward-free policies are refined to maximize feature informativeness, ensuring that collected trajectories yield well-conditioned covariance matrices.
- Stage 3: Low-Rank Reward Matrix Estimation – Leveraging the exploration policy, samples are used for joint low-rank estimation via SVD-based techniques, unlike baselines relying on independent or random exploration.
- Stage 4: Policy Construction – Estimated rewards inform (S,A,{Rht}h=1H,{Ph}h=1H)1-optimal policy synthesis for each task, exploiting the learned latent structure.
Theoretical Results
Rigorous sample complexity and regret analyses are provided. The key technical contributions include:
- Low-Rank Recovery under Generic Features: Provable bounds are established for reward matrix estimation error and latent subspace distance, even absent Gaussianity or incoherence.
- Sample Complexity: For estimation error bounded by (S,A,{Rht}h=1H,{Ph}h=1H)2 and subspace distance (S,A,{Rht}h=1H,{Ph}h=1H)3, the number of required samples (S,A,{Rht}h=1H,{Ph}h=1H)4 scales as (S,A,{Rht}h=1H,{Ph}h=1H)5, reflecting the impact of feature dimensionality and latent spectral properties.
- Regret Bound: Leveraging the learned shared structure, the cumulative regret across (S,A,{Rht}h=1H,{Ph}h=1H)6 episodes and (S,A,{Rht}h=1H,{Ph}h=1H)7 tasks satisfies
(S,A,{Rht}h=1H,{Ph}h=1H)8
highlighting direct dependence on estimation error and dimensionality.
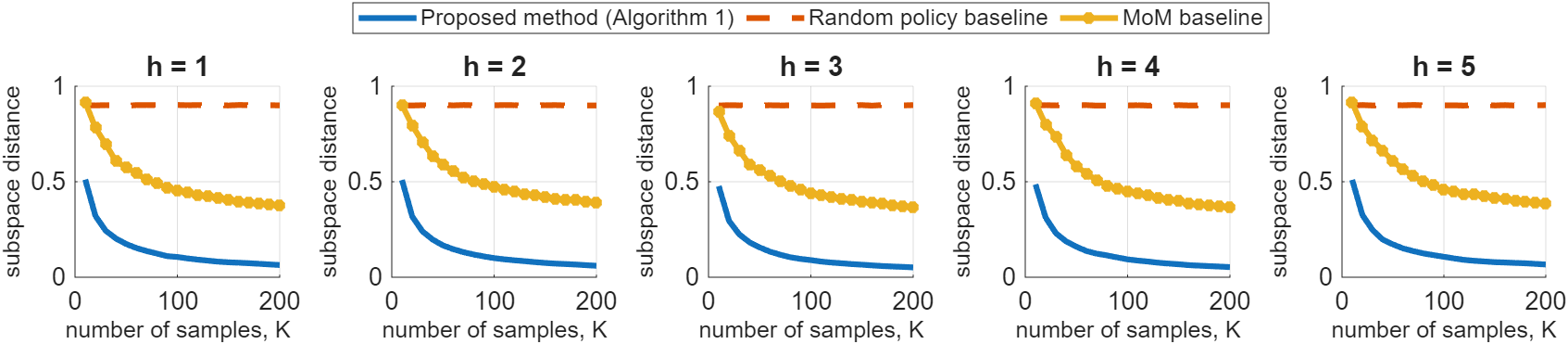
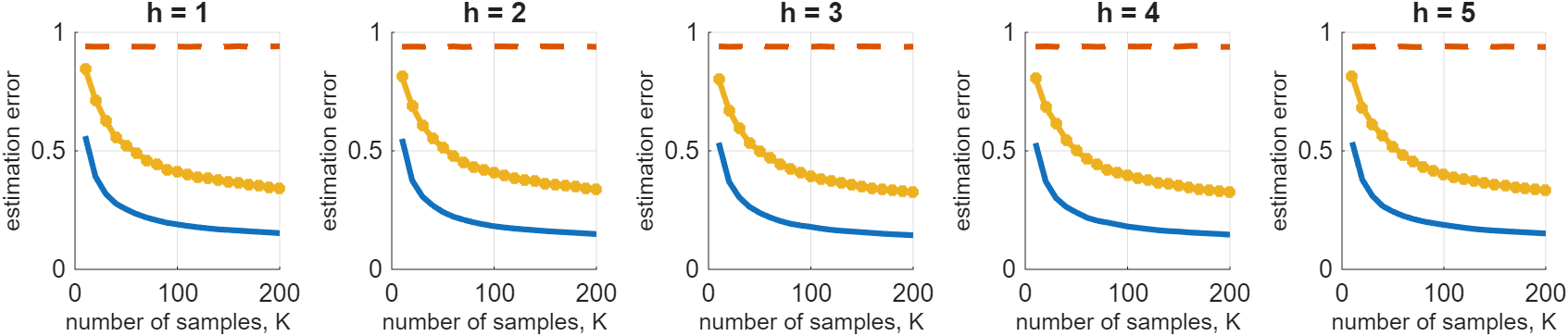
Figure 1: Subspace distance decays rapidly as the number of samples (S,A,{Rht}h=1H,{Ph}h=1H)9 increases, demonstrating efficient low-rank adaptation (Rht(s,a)=⟨θht,ψ(s,a)⟩0).
Numerical Analysis
Empirical validation is provided in simulated control and grid maze environments, using metrics of subspace distance, reward parameter estimation error, and cumulative regret. The algorithm decisively outperforms baselines:
- Random Policy Baseline: Uniform random exploration yields degenerate feature distributions, undermining low-rank recovery.
- MoM Baseline: Empirical moment estimators perform poorly without intentional exploration policy design.
- Independent Task Baseline: Neglecting shared structure leads to suboptimal sample utilization and higher regret.
Experimental results confirm the theoretical prediction that intentional, reward-free exploration is pivotal for robust representation learning and policy performance.
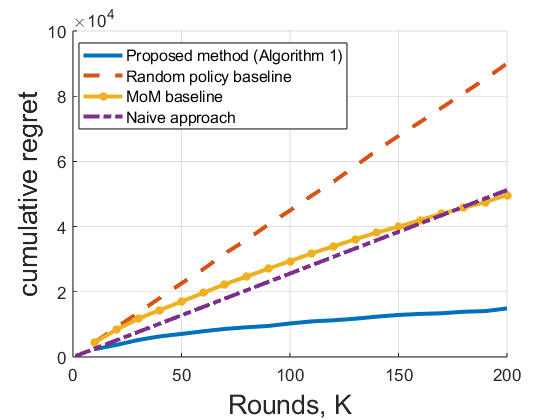
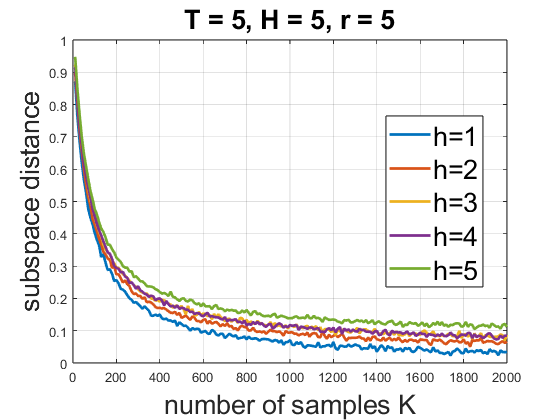
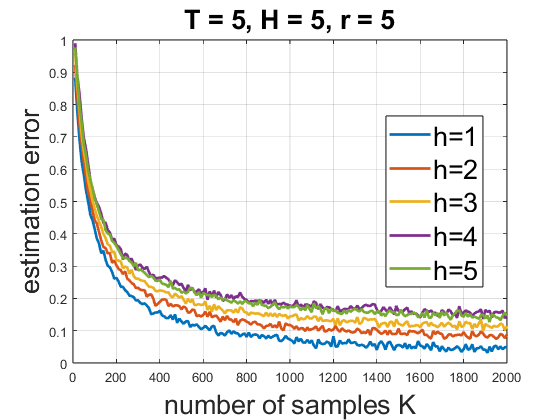
Figure 2: Estimation error trends as a function of samples reveal fast convergence in reward parameter recovery, favoring joint low-rank MTRL-RL.
Practical and Theoretical Implications
Practically, the proposed framework enables efficient learning in multi-agent or multi-objective settings with intrinsic reward correlations, such as autonomous fleets and industrial automation. Theoretically, the main impact lies in demonstrating effective low-rank matrix recovery in RL under realistic, policy-dependent feature distributions, a departure from restrictive assumptions in prior literature.
The method's provable guarantees and empirical performance suggest that joint task representation learning is essential for scalable, high-dimensional RL applications. Furthermore, the approach provides a foundation for extending multi-task RL to environments where policies must adapt dynamically to varied and complex rewards.
Future Directions
Future developments may focus on:
- Extending to Nonlinear MDPs: Incorporating nonlinear reward or transition structures, possibly via kernel or deep latent embeddings.
- Integration with Model-Free Algorithms: Embedding the representation learning pipeline within high-performance model-free RL algorithms like PPO/DQN.
- Scaling to Large Task Collections: Optimized architectures for large-scale multi-task RL with greater heterogeneity and richer reward correlation structures.
Conclusion
The paper introduces a multi-task RL framework exploiting low-rank reward structures to jointly recover task representations and optimal policies, achieving rigorous sample-efficiency and regret bounds without restrictive idealizations. The results underscore the centrality of reward-aware exploration and demonstrate the critical role of representation sharing in real-world multi-task RL.

