- The paper demonstrates that integrating the Multi-Scale Fovea module into the SemBA framework achieves human-level semantic scanpath similarity while drastically reducing computational cost.
- Methodology involves generating a multi-resolution pyramid of concentric crops that emulate the human retina’s peripheral distortion without retraining existing detectors.
- Experiments on COCO-Search18 show a 17.6x speed-up with DETR, processing fewer than 6% of input pixels while maintaining robust attention prediction performance.
Cost-Efficient Multi-Scale Fovea for Semantic-Based Visual Search Attention
This paper addresses a fundamental bottleneck in semantic-based visual attention systems: the computational cost incurred by processing high-resolution visual inputs through deep object detectors. While object detectors such as YOLOv11 and DETR have demonstrated substantial efficacy in extracting rich top-down semantic cues, their performance is constrained by input dimensionality—high-resolution images require significant computational resources and are incompatible with rapid, biologically inspired attention mechanisms.
Inspired by the exponential density roll-off observed in the human retina, the authors propose the Multi-Scale Fovea module, which efficiently subsamples the visual field to emulate biological eccentricity effects. The Multi-Scale Fovea is embedded into the semantic-based Bayesian attention (SemBA) framework, aiming to maximize both computational efficiency and scanpath prediction accuracy in goal-directed visual search, while retaining anatomical proportions of the human fovea.
Figure 1: Illustration of the proposed Multi-Scale Fovea mechanism; concentric, multi-resolution crops are downsampled to emulate peripheral distortion and exponential density roll-off.
Semantic-Based Bayesian Attention: SemBA
SemBA leverages pre-trained deep object detectors to iteratively extract semantic information during scanpath generation. It constructs and updates semantic belief maps for each cell in an image grid via Dirichlet distributions, incorporating categorical scores from object detectors. The framework avoids reliance on human-generated scanpath data, asserting that attention is stimulus-driven, and instead fuses semantic information across multiple fixations using subjective logic fusion rules.
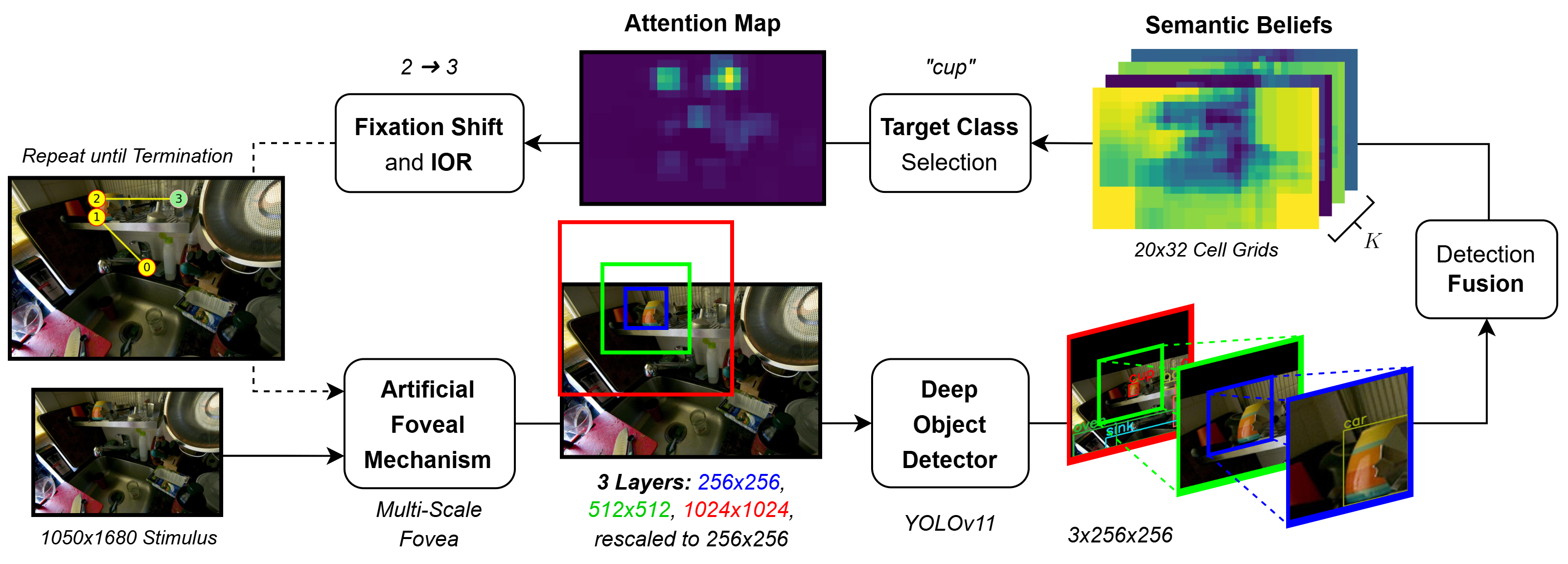
Figure 2: Schematic representation of SemBA, highlighting the stepwise extraction and fusion of semantic data using the Multi-Scale Fovea and object detection modules.
Multi-Scale Fovea: Design and Mechanism
The Multi-Scale Fovea module generates a multi-resolution pyramid of concentric crops around a focal point, where each layer's side length doubles relative to the previous. All layers are subsequently downsampled to the base layer's resolution, intensifying peripheral distortion. The central layer (foveal region) maintains maximum acuity. Semantic detections from each layer are mapped back to the original coordinate system for probabilistic fusion, closely mirroring the uncertainty gradients in human peripheral vision.

Figure 3: Comparison of field-of-view topologies—full resolution (baseline), Laplacian Foveation, FOVEA magnification, and Multi-Scale Fovea.
Critically, this approach obviates the need for detector retraining on foveal input topologies by preserving geometric properties, enabling seamless integration with existing detection models.
Experiments are conducted on COCO-Search18, evaluating scanpath prediction on target-present scenes with metrics such as Sequence Score (SS), Fixation Edit Distance (FED), and their semantic analogs. The Multi-Scale Fovea module is compared against Laplacian Foveation and FOVEA magnification, utilizing DETR, YOLOv11, and RT-DETR detectors.
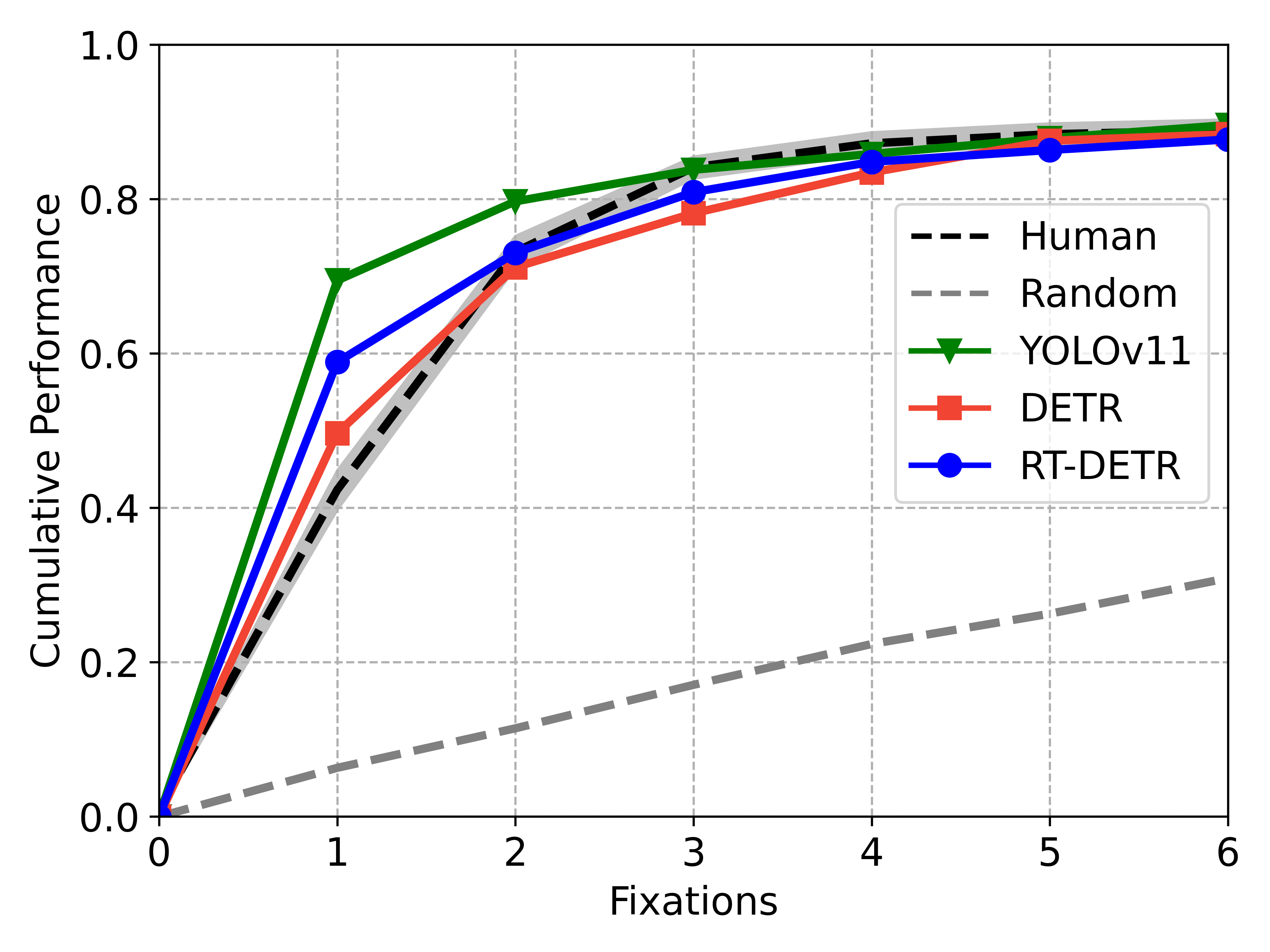
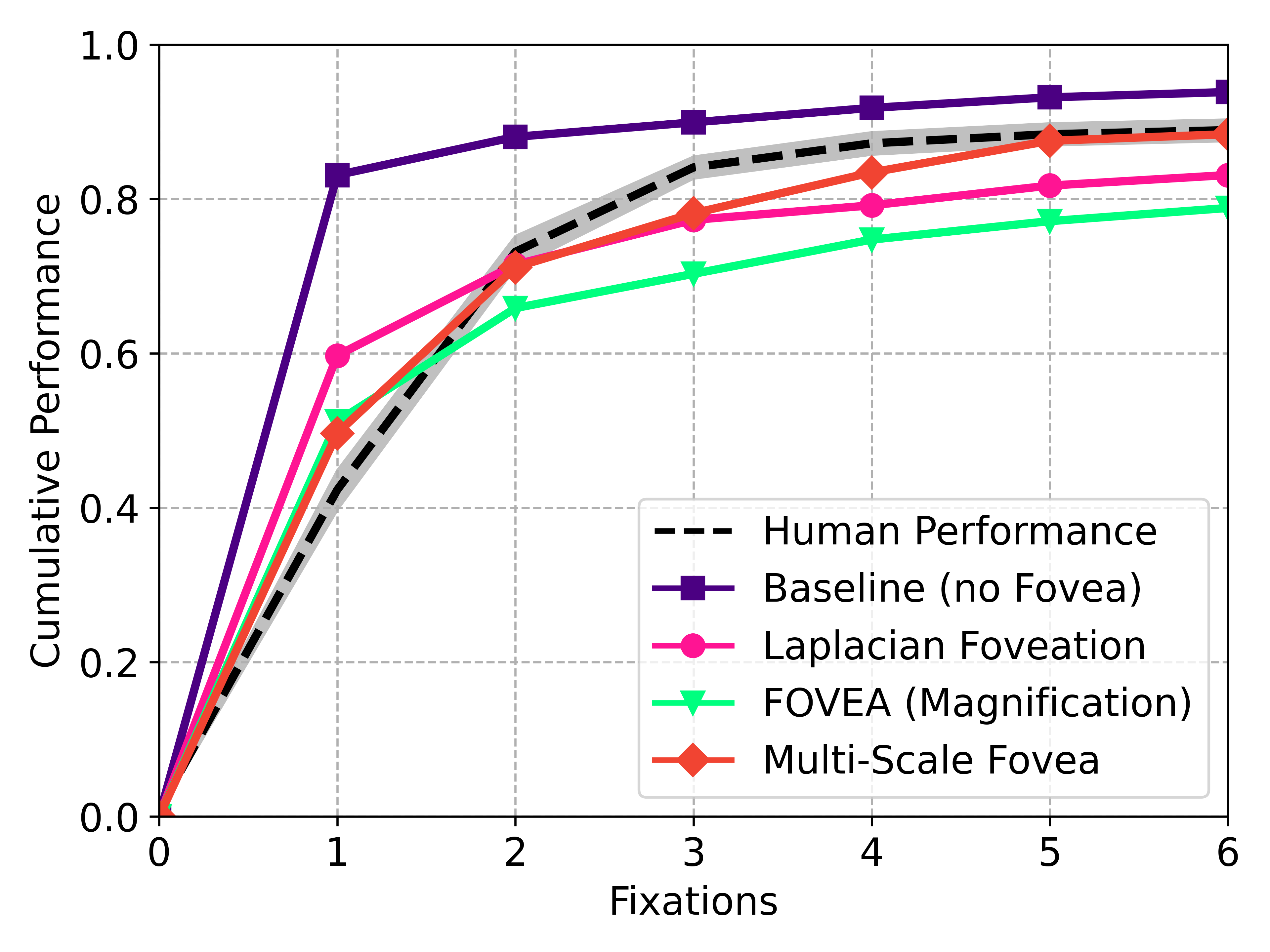
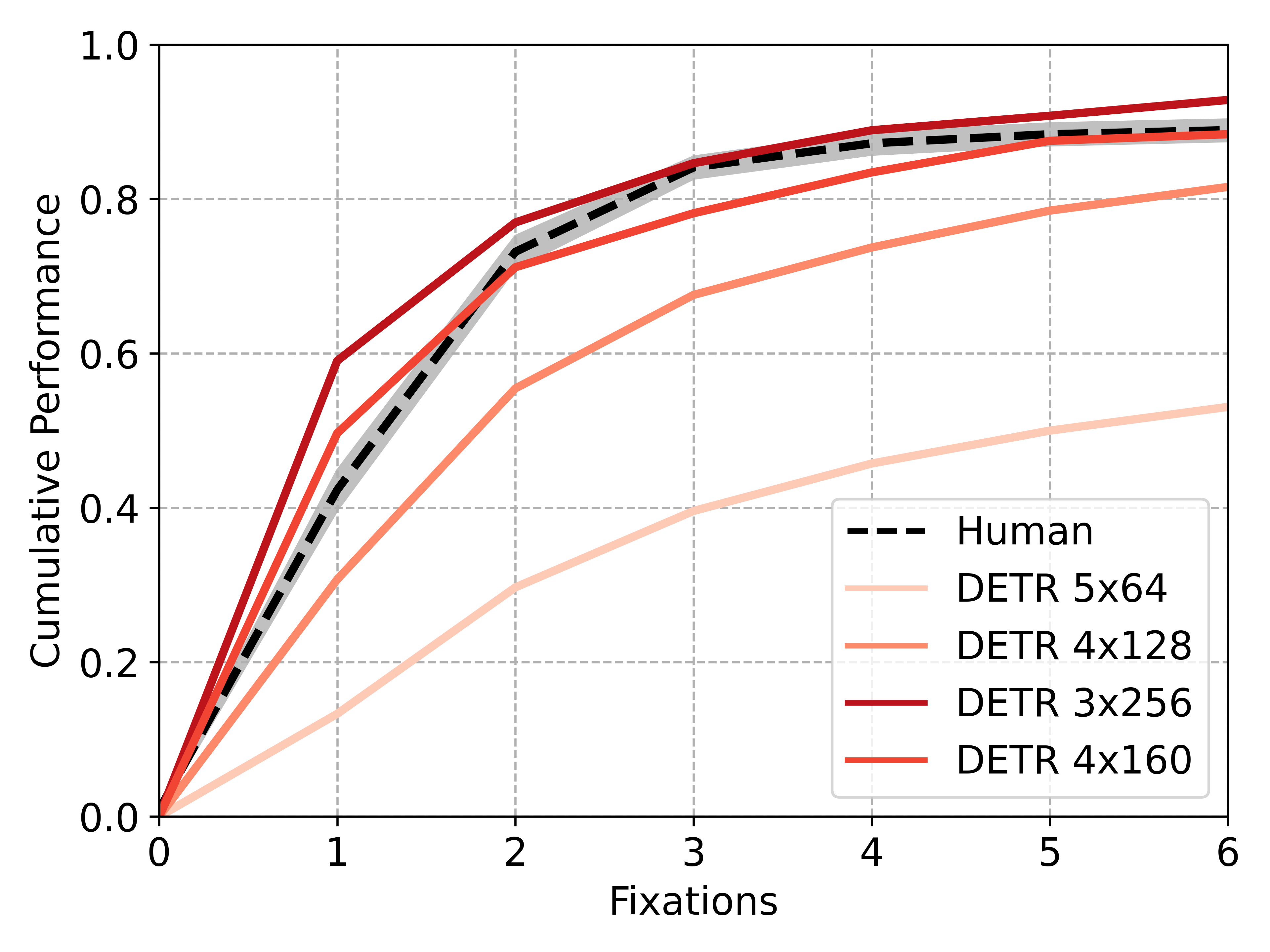
Figure 4: Cumulative task performances on visual search for humans, random selection, and SemBA with various object detectors, foveal systems, and Multi-Scale Fovea configurations.
Numerical highlights include:
- SemBA with Multi-Scale Fovea matches or exceeds human consistency in semantic sequence similarity (SemSS, SemFED), outperforming IVSN and rivaling state-of-the-art models that are trained with human fixation data.
- The Multi-Scale Fovea (4×160 configuration), covering ≈5.0∘ of visual angle, achieved a notable computational cost reduction: with DETR, per-iteration runtime dropped from 10.37s to 0.59s—a 17.6x speed-up; YOLOv11 saw a modest improvement due to its architectural efficiency.
- Only the Multi-Scale Fovea, not other foveal systems, surpassed human consistency in semantic scanpath similarity metrics, with fewer than 6% of the original input pixels processed.
Ablation studies confirm performance sensitivity to foveal parameter selection—the best trade-off between accuracy and cost is found at biologically congruent scales (4×160).
Theoretical and Practical Implications
This work demonstrates that artificial attention systems can achieve high scanpath prediction fidelity and cost efficiency by structurally mimicking biological foveation. Multi-Scale Fovea's compatibility with geometric input properties enables off-the-shelf deployment in real-time applications (e.g., humanoid robotics), without retraining burdens. It further substantiates the hypothesis that semantic attention patterns can be accurately modeled without human scanpath data, supporting the stimulus-driven nature of attention.
From a theoretical perspective, the results reinforce the effectiveness of hierarchical visual subsampling for uncertainty modeling in peripheral vision and provide a principled pathway for the intersection of efficient computation and biological plausibility.
Future Directions
Potential extensions include:
- Adaptation of Multi-Scale Fovea to broader tasks such as free-viewing and visual question answering.
- Exploration of dynamic foveal sizes and layer compositions for maximizing accuracy under varying visual contexts.
- Integration with multimodal attention frameworks and active robotic vision for enhanced real-time environmental parsing.
Conclusion
The Multi-Scale Fovea module, integrated within the SemBA framework, achieves substantial computational savings and human-level semantic scanpath prediction accuracy, validating artificial foveal mechanisms as a practical and theoretically sound architecture for semantic attention in visual search. The method's ability to closely approximate human consistency without dependence on scanpath training data indicates promising future applicability in biologically inspired AI systems.

