- The paper introduces a provable SVD-based denoising algorithm that recovers true nearest neighbor structures under Gaussian noise in high-dimensional, low-rank data.
- It leverages subspace estimation via SVD and a data-splitting technique to achieve (1+ε)-approximation guarantees when noise is bounded by O(1/k^(1/4)).
- Empirical validations on MNIST and GloVe datasets underscore its advantages over random projection methods in preserving intrinsic data geometry.
Provable Denoising of Nearest Neighbor Data by SVD: An Analysis
Problem Context and Motivation
The paper "SVD Provably Denoises Nearest Neighbor Data" (2604.03831) addresses the nearest neighbor search (NNS) problem in high-dimensional scenarios where data is sampled from an unknown low-dimensional subspace and subsequently corrupted by high-dimensional Gaussian noise. Traditional random projection-based methods (e.g., Johnson–Lindenstrauss Lemma and LSH) are optimal for worst-case data but are often outperformed in practice by data-aware projections such as PCA, especially with subspace-structured data. Prior works lacked sharp theoretical guarantees for these spectral methods under high noise.
The core question is: When is it possible to reliably recover the true nearest neighbor structure from noisy, high-dimensional data, and can SVD-based dimension reduction provably enable robust NNS in regimes where other methods fail?
Main Results
The authors propose and analyze a simple SVD-based algorithm that processes noisy data in the semi-random model (data from a k-dimensional subspace of Rd, perturbed by Gaussian noise of variance σ2). Their key contributions are:
- Algorithmic Guarantee: For noise σ=O(1/k1/4), applying SVD and projecting onto the top-k subspace suffices to recover the accurate NN structure of the uncorrupted data, with provable (1+ε)-approximation guarantees.
- Information-theoretic Thresholds: If σ≫1/k1/4, it is information-theoretically impossible to recover the NN structure irrespective of the algorithm; this matches the upper bound, demonstrating optimality.
- Spectral Sensitivity: The required σ bound depends both on k and the minimal singular value sk(B) of the latent data matrix, with Rd0 governing spectral stability.
- Decoupled Subspace Estimation: The analysis leverages a split of the dataset into two halves, projecting each half onto the subspace learned from the other, ensuring statistical independence critical for tight probabilistic bounds.
- Empirical Validation: Experiments on MNIST (images) and GloVe (word vectors) validate the theoretical predictions, showing SVD-based NNS outperforms naïve noisy-NNS, with robustness to large ambient dimensions and increased noise.
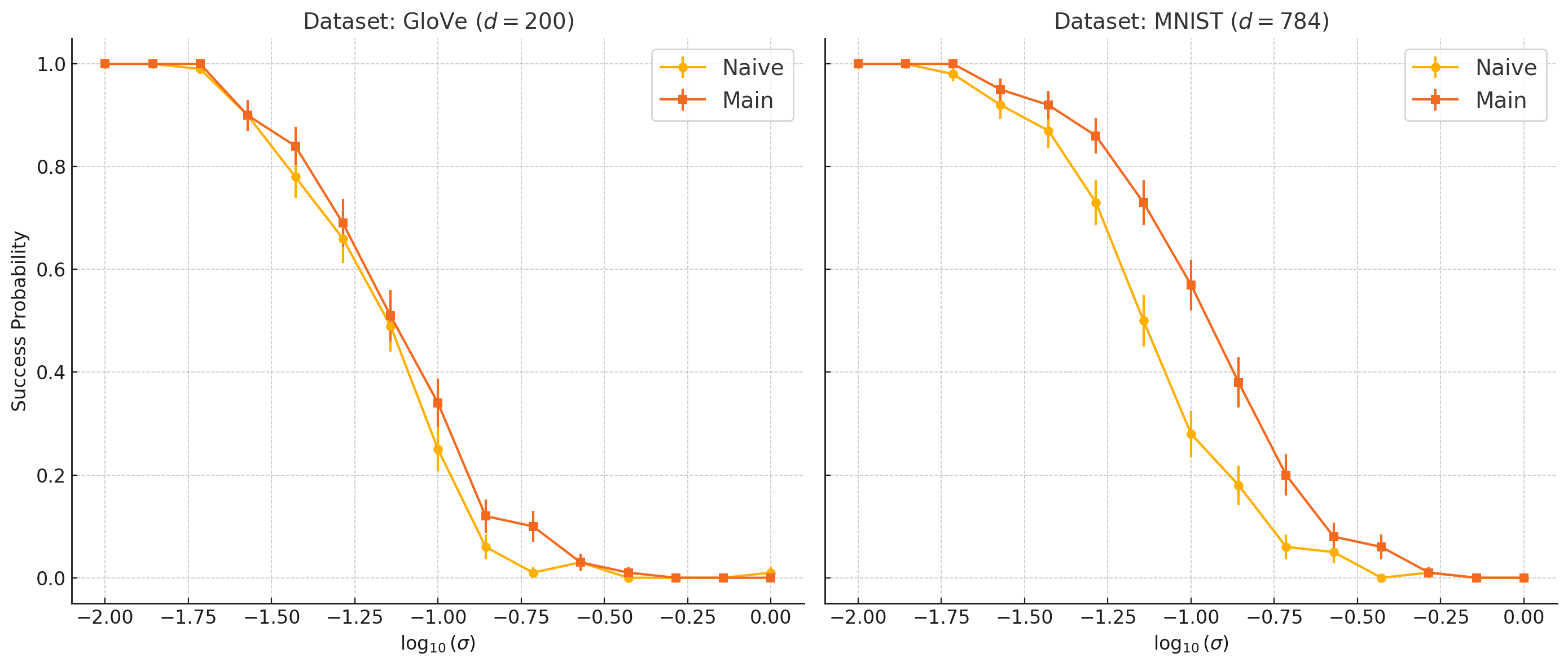
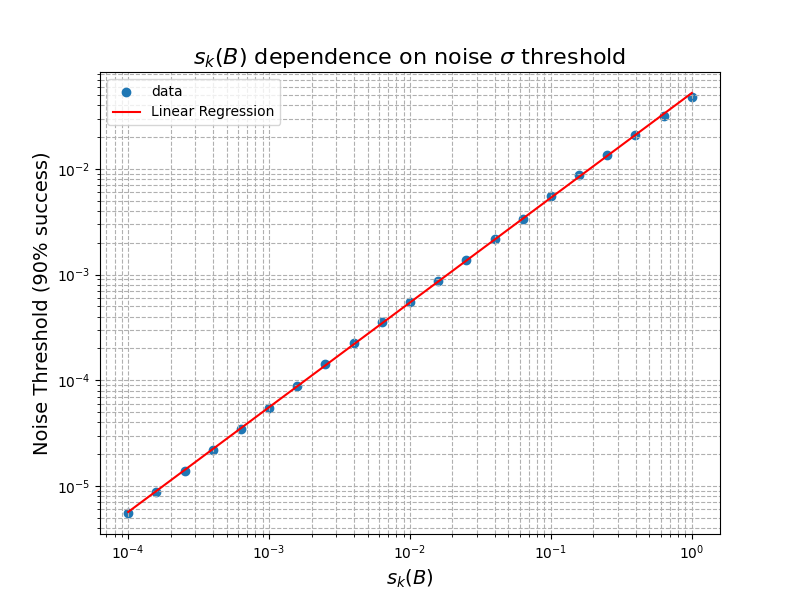
Figure 1: Performance comparison on two real-world datasets (left) and analysis of the noise threshold’s dependence on the singular value Rd1 (right).
Theoretical Framework and Algorithm
Given a set of noisy observations Rd2 (Rd3 is latent subspace data, Rd4 is i.i.d. Gaussian noise), the algorithm works as follows:
- Split Rd5 into two halves (each containing Rd6 data points + the query);
- For each half, compute the top-Rd7 singular vectors (SVD) to estimate subspace;
- Project points of one half (and the query) onto the subspace learned from the other half;
- Compute distances in the projected space; output the minimum as the approximate NN.
This cross-projection ensures that the signal directions are preserved while decorrelating the subspace extracted from a particular subset from the noise in the other subset, facilitating tight concentration bounds in the analysis (via Wedin’s and Davis–Kahan theorems on subspace perturbation).
Key theoretical claims:
- For Rd8, the squared projected distances approximate the true latent distances up to desired multiplicative error with high probability.
- A matching impossibility result (via KL-divergence analysis of mixture Gaussians in high dimensions) shows that for Rd9, even distinguishing the identity of nearest neighbors is impossible.
Empirical Insights
The experimental results corroborate the theoretical claims regarding the SVD threshold for noise tolerance. On GloVe and MNIST:
- For small σ20, all methods recover NNs reliably.
- For moderate σ21 exceeding random projection tolerances but not the SVD theory bound, the SVD approach consistently succeeds while naive NN fails.
- For σ22 past the σ23 threshold, recovery becomes impossible—delineating the sharp phase transition predicted theoretically.
The right panel of Figure 1 demonstrates the linear dependence of the critical noise threshold on σ24, as the theory predicts.
Comparison With Prior Work
Compared to Abdullah et al. 2014 (Abdullah et al., 2014), the SVD method here tolerates noise up to σ25 (vs. σ26 or stricter), a significant improvement in practical regimes with very large ambient σ27 and moderate intrinsic σ28. The trade-off is that the SVD method's guarantee depends on the spectrum (well-conditioning) of the data, whereas prior work was agnostic to σ29. For well-conditioned data, however, σ=O(1/k1/4)0 remains bounded below by a constant, so the improvement is substantial.
Performance is also compared with random projection/lsh-based approaches: as soon as σ=O(1/k1/4)1, nearest neighbor structure in noisy space no longer reflects the latent one, and only structure-aware methods like SVD can operate successfully.
Algorithmic and Practical Implications
- Dimensionality and Data Geometry: The algorithm crucially leverages the underlying low intrinsic dimension. For high-dimensional but rank-deficient datasets, SVD-based denoising is both theoretically justified and practically effective.
- Choice of k: The algorithm assumes knowledge of the true intrinsic rank σ=O(1/k1/4)2, but in practice one can select σ=O(1/k1/4)3 to capture most of the signal, using spectral decay heuristics.
- Runtime: The method is efficient: two SVDs, each on σ=O(1/k1/4)4 matrices, and projection steps. With appropriate randomized SVD algorithms, large datasets are tractable.
Theoretical Ramifications
This work provides a formal separation between the regimes where random projection-based NNS is optimal vs. where data-aware methods are theoretically justified under structured noise. It establishes the minimal conditions—signal-to-noise scaling with σ=O(1/k1/4)5 and σ=O(1/k1/4)6—under which information-theoretic recovery is possible, closing a gap between empirical success and rigorous analysis for spectral methods in NNS.
The use of high-dimensional random matrix theory and perturbation analysis of subspaces links advances in numerical analysis to robust algorithm design for data mining and learning tasks.
Future Directions
Open theoretical questions include:
- Can one achieve similar denoising guarantees without data splitting (i.e., using the same SVD subspace for all projections)?
- How do these results extend to more complex noise models (non-i.i.d. or heavy-tailed), structured corruptions, or manifold-structured data?
- What are the implications for kernel/feature map lifting, where the subspace is implicitly infinite-dimensional but low effective rank?
Practically, embedding such SVD denoising in end-to-end nearest neighbor engines or as preprocessing for downstream machine learning tasks could yield broad improvements in reliability under high noise.
Conclusion
This work rigorously establishes that SVD-based projections provably enable nearest neighbor recovery from semi-random noisy high-dimensional data, with sharp noise thresholds matching information-theoretic limits. The theory is supported by empirical results, delineating when and why PCA-type denoising outperforms oblivious random projection methods for practical NNS in modern high-dimensional settings. The dependence on intrinsic dimension and spectrum makes these findings broadly applicable to real data, while also motivating further study of structure-aware robust algorithms for learning over noisy observations.