- The paper introduces a debiased machine learning framework that adjusts for runtime confounding to ensure valid conformal prediction intervals for counterfactual outcomes.
- It combines plug-in and weighting estimation strategies with DML to achieve root-n convergence and robust interval coverage under systematic covariate shifts.
- Empirical results on synthetic and semi-synthetic data demonstrate that the proposed methods outperform naive approaches by maintaining near-nominal coverage even with unobserved confounders.
This paper addresses the challenge of quantifying uncertainty in counterfactual predictions under runtime confounding—scenarios where only a subset of the necessary confounders is observed in the target population during deployment. The motivation arises from decision-support applications, such as individualized treatment effect estimation in precision medicine or personalized marketing, where counterfactual models are trained in a data-rich source population but must be applied to a target population with systematic covariate and confounder shortfalls. Existing conformal prediction approaches are limited by the assumption that all confounders are measured both at training and runtime, leading to miscoverage and invalid inference when this condition is violated.
The authors formalize the runtime confounding problem as a distributional shift involving two covariate sets: a fully observed subset V available in both populations, and an augmented set =(V,U), with U unobserved at runtime. They aim to develop procedures for conformal prediction that guarantee valid prediction interval coverage for counterfactual potential outcomes Y(a) in the target population, explicitly handling the absence of some confounders in the population of interest.
The presented framework extends conformal prediction approaches for counterfactuals and individual treatment effect (ITE) estimation under covariate shift [lei2021conformal, yang2024doubly, alaa2023conformal], transfer learning-based causal inference [shyr2025multi, bica2022transfer], and data fusion strategies [degtiar2023review, graham2024towards]. The principal technical distinction is the explicit accommodation of runtime confounding within the conformal prediction paradigm, leveraging both modern semiparametric efficiency theory and debiased/multiply-robust machine learning. Importantly, the approach requires only that V captures all source-target systematic shifts in Y(a), thereby relaxing the conventional requirement for complete confounder measurement in the target population.
The methodology synthesizes (i) identification and adjustment for dual sources of covariate shift (across treatment levels and populations), (ii) plug-in and weighted estimation strategies, and (iii) efficient, multiply-robust estimators via efficient influence curve (EIC) theory. The procedure is formally grounded in the following core assumptions: treatment positivity, consistency, unconfoundedness (in the source), and source-target exchangeability given V. Violations of these assumptions, such as unmeasured confounders or mismatched sources and targets, can invalidate inference; the paper provides additional discussion and graphical representations of plausible and non-plausible settings.
Central to the conformal prediction construction is the conformity score Ra(Y,V), suitable for settings with partial covariate observability. The authors derive new identification functionals for the required quantiles of these scores in the target population, showing that both regression-based (g-computation) and weighting-based (inverse probability with dual shift-correcting weights) approaches are justified. For quantile regression-based conformity scores under runtime confounding, they present new loss functions involving composite weights accounting for both treatment and sampling mechanisms.
Debiased Machine Learning and Efficiency Results
Plug-in and standard weighting approaches are shown to be consistent but can converge at slow rates when high-dimensional flexible nuisance models are fit. The main technical innovation is the adaptation of DML/semiparametric efficiency theory, providing a multiply-robust estimator for the score quantile via the EIC. This estimator enjoys root-n convergence under mild rate conditions, with the coverage error of prediction intervals shrinking at the parametric rate even when machine learning models are used, contingent on at least one regularized estimator in each of two pairs (ma,κ) and =(V,U)0 converging consistently.
The DML estimator is implemented in a split conformal prediction algorithm, avoiding computational intractability of repeated nuisance model re-fitting by localizing EIC estimation around an =(V,U)1-consistent pilot estimate, as prescribed in recent semiparametric theory [kallus2024localized].
Empirical Results
The empirical study includes both synthetic and semi-synthetic experiments, systematically evaluating interval coverage and efficiency under a controlled degree of runtime confounding, source-target sample size ratios, and varying sample sizes.


Figure 1: Experiment results demonstrate empirical coverage and interval length for different sample sizes, highlighting effect of runtime confounding (10 unmeasured confounders) on method performance.
Across all scenarios, the DML and weighted conformal approaches achieve empirical coverage close to the target rate (e.g., 90%), with DML intervals generally as narrow or narrower than their competitors. By contrast, naively ignoring runtime confounding yields severe miscoverage, especially as the number of unmeasured confounders or sample size increases. Stratified analysis by counterfactual outcome and runtime confounding severity further substantiates the robustness of the proposed strategies.

Figure 2: Empirical performance stratified by counterfactual outcome confirms coverage and efficiency across both =(V,U)2 and =(V,U)3.
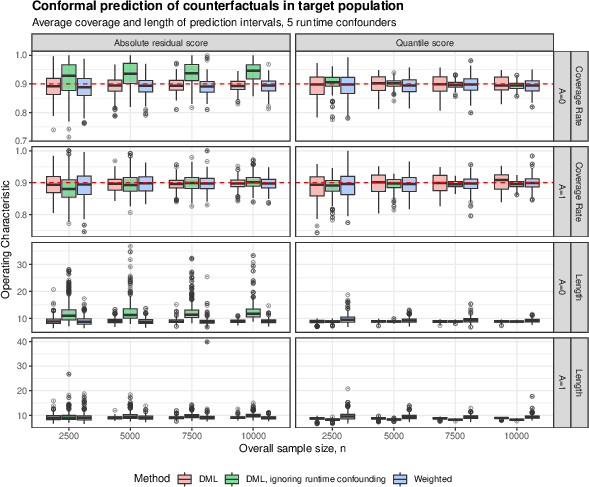
Figure 3: The procedure remains robust to varying numbers of true runtime confounders (here, 5 confounders), maintaining nominal coverage rates as =(V,U)4 increases.

Figure 4: With 15 runtime confounders, the advantage of properly accounting for runtime confounding is further accentuated; naive procedures show increasing miscoverage.
In semi-synthetic settings based on the ACIC NSLM database, the DML and weighted approaches similarly maintain valid coverage, while unadjusted approaches exhibit miscoverage exacerbated by quantile-based conformity scoring or under severe confounding scenarios.

Figure 5: On semi-synthetic ACIC challenge data, both proposed methods achieve valid coverage and efficient intervals regardless of sample size, substantially outperforming methods that ignore runtime confounding.
Complementary analyses varying =(V,U)5 and additional sensitivity checks corroborate the method's robustness.
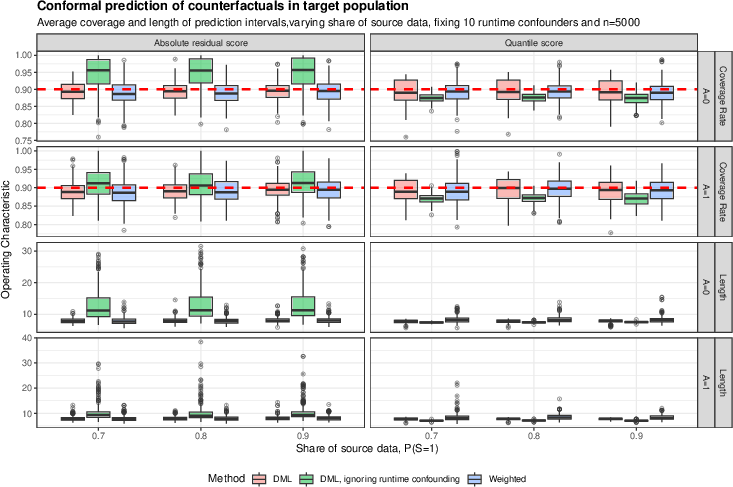
Figure 6: Empirical performance versus =(V,U)6 indicates that both DML and weighting strategies are robust to varying proportions of source data.
Discussion and Implications
The paper establishes that appropriately adjusting for both runtime confounding and population shift is essential for inference-valid conformal prediction intervals on counterfactual outcomes. The multiply-robust DML approach provides formal guarantees (asymptotic coverage, root-=(V,U)7 convergence, model-multiple robustness) under practical assumptions, with strong empirical validation.
Practically, this work enables deployment of data-driven DSTs in settings where runtime confounding is unavoidable, such as when privacy, cost, or logistics restrict the measurement of confounders at runtime. Theoretically, the results position semiparametric DML as fundamental to assumption-lean, efficient counterfactual prediction with quantifiable uncertainty.
Potential extensions include the development of formal sensitivity analysis to violations of exchangeability and unconfoundedness, support for continuous treatments and time-to-event outcomes, and adaptation to strict privacy constraints or federated/multi-source environments.
Conclusion
This paper presents a computationally and statistically efficient framework for conformal prediction of counterfactual outcomes under runtime confounding, advancing the state-of-the-art in both method development and theoretical understanding at the intersection of causal inference, machine learning, and uncertainty quantification. The proposed debiased machine learning and weighted conformal procedures deliver valid and efficient interval coverage under minimal assumptions, robust to practical complications inherent in modern deployment scenarios. These advances further enable the use of counterfactual DSTs and causal machine learning systems in real-world settings characterized by incomplete covariate information at deployment.

