- The paper demonstrates that human detection of LLM-generated news is no better than chance across various models.
- It employs a dual-axis continuous judgment approach to separate source attribution from authenticity assessment with fine-grained analysis.
- The findings suggest that system-level defenses like cryptographic provenance are critical to countering synthetic misinformation.
Human Perception of LLM-Generated News: Analysis via Dual-Axis Continuous Judgment
Introduction
The study "Can Humans Tell? A Dual-Axis Study of Human Perception of LLM-Generated News" (2604.03755) presents a rigorous investigation into humans' ability to discern the origin and authenticity of news fragments authored by LLMs versus humans. The authors introduce JudgeGPT, a web-based experimental platform that innovatively decouples source attribution and perceived authenticity using independent continuous rating scales. The methodological advances and empirical findings challenge prevailing assumptions about user-side detection as an effective countermeasure to LLM-facilitated misinformation, with implications for digital content provenance and design of trust-support interventions.
Experimental Methodology
JudgeGPT systematically addresses key limitations observed in prior human-subject studies by utilizing three continuous 0–100 axes for participants’ judgments: source attribution (certainty of human vs. machine authorship), authenticity (judgment of legitimacy vs. fakery), and topic familiarity. This design avoids the confounding of veracity and source present in binary, real-vs.-fake paradigms and enables fine-grained statistical analysis, including parametric correlation assessment and participant clustering.
Stimuli are constructed within a 2×2 factorial framework, crossing origin and veracity. LLM-generated text is produced by the controlled RogueGPT framework, leveraging six distinct models spanning both proprietary (GPT-4, GPT-3.5, GPT-4o) and open-weight architectures (LLaMA-2 13B, Gemma 7B, Mistral 7B). Careful curation ensures factual consistency, mitigating conflations between stylistic recognition and hallucination detection. The sample is heavily skewed toward machine-generated fragments, prioritizing within-AI model analysis, and a demographically narrow (educated, predominantly European) participant pool is acknowledged.
Data collection yields 2,318 judgments spanning 1,054 participants, each providing informed consent and demographic context. Presentation order and model assignment are randomized, and the platform logs ratings, response times, and participant-level covariates.
Figure 1: The JudgeGPT interface, featuring independent slider ratings for source attribution, authenticity, and self-assessed topic familiarity.
Key Findings
Machine-Generated Text is Indistinguishable from Human Authorship
Contrary to the intuitive confidence often expressed regarding human ability to recognize synthetic text, the study finds no statistically significant difference in perceived source or authenticity between human-written and machine-generated fragments across all tested models (Welch’s t-test, p=.38, Cohen’s d=0.04). Participant judgments cluster around chance, confirming durable indistinguishability.
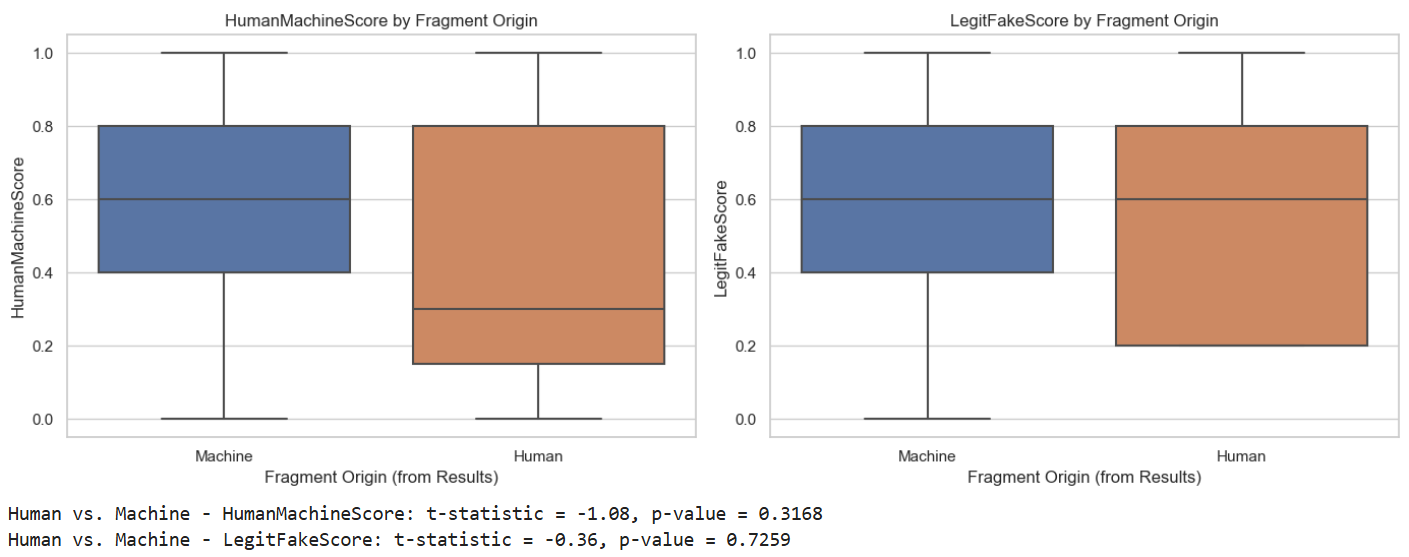
Figure 2: Overlapping distribution plots for source and authenticity, showing no significant separation between human- and machine-generated text.
Model-Agnostic Detection Failure
Detection inability persists irrespective of the generative model. The analysis of scores for each tested LLM reveals no model-specific identifiability. Outputs from LLMs as lightweight as 7B parameters (Gemma, Mistral) are as opaque to human detection as those from cutting-edge systems (GPT-4o), indicating the erosion of distinctive synthetic cues even at moderate model scales.
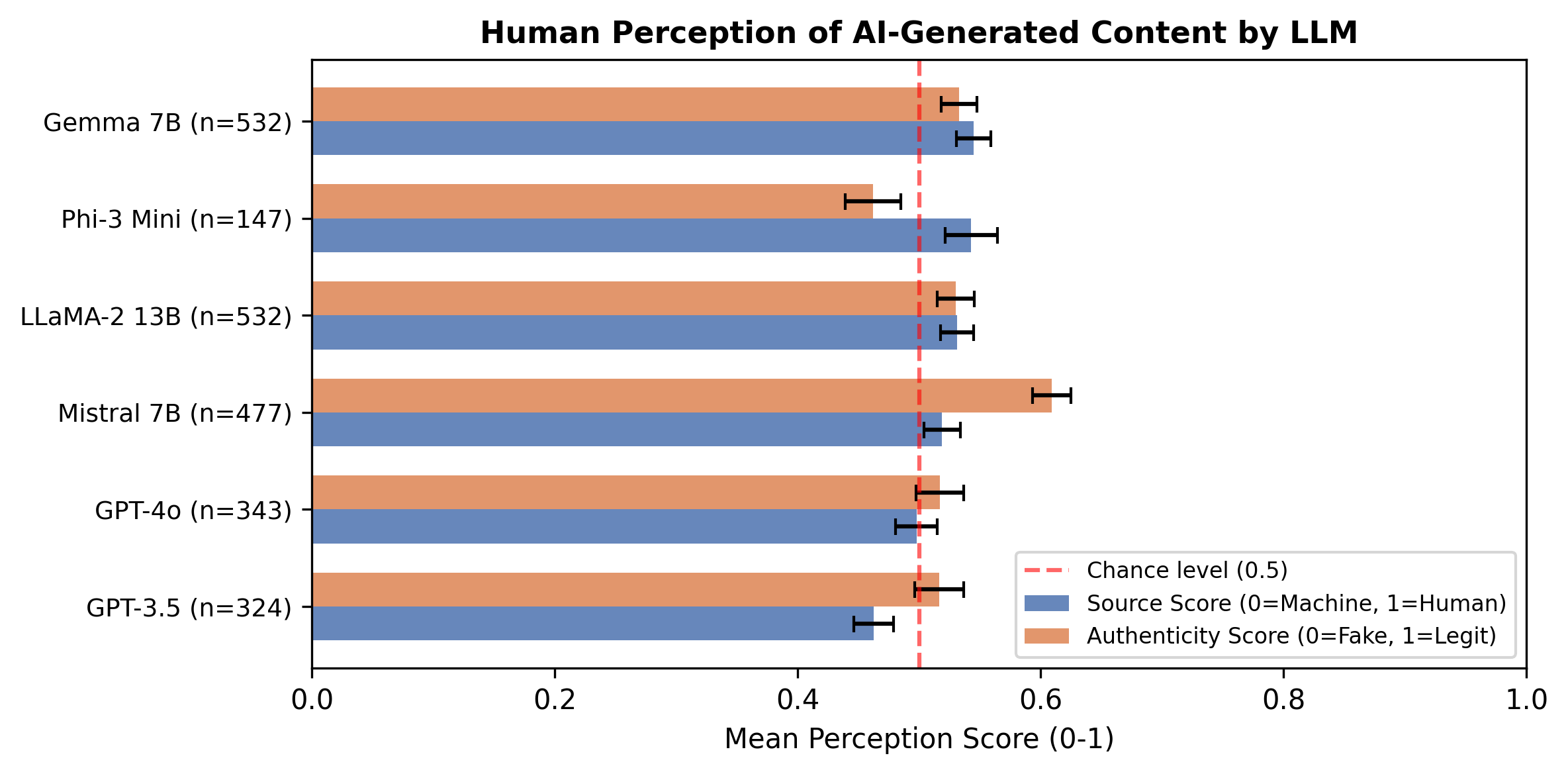
Figure 3: Source and authenticity mean ratings for each LLM model; all fall around chance discrimination levels.
Participant covariates yield insight into detection variance. Self-reported topic familiarity and fake news sophistication exhibit a positive correlation with higher judgment accuracy (r=.35, p<.001), indicating some potential for analytical skill development to enhance resilience against synthetic content. Political orientation, in contrast, associates weakly and non-significantly with detection efficacy, hinting that ideological alignment exerts minimal direct influence in the context of balanced, non-partisan news stimuli.
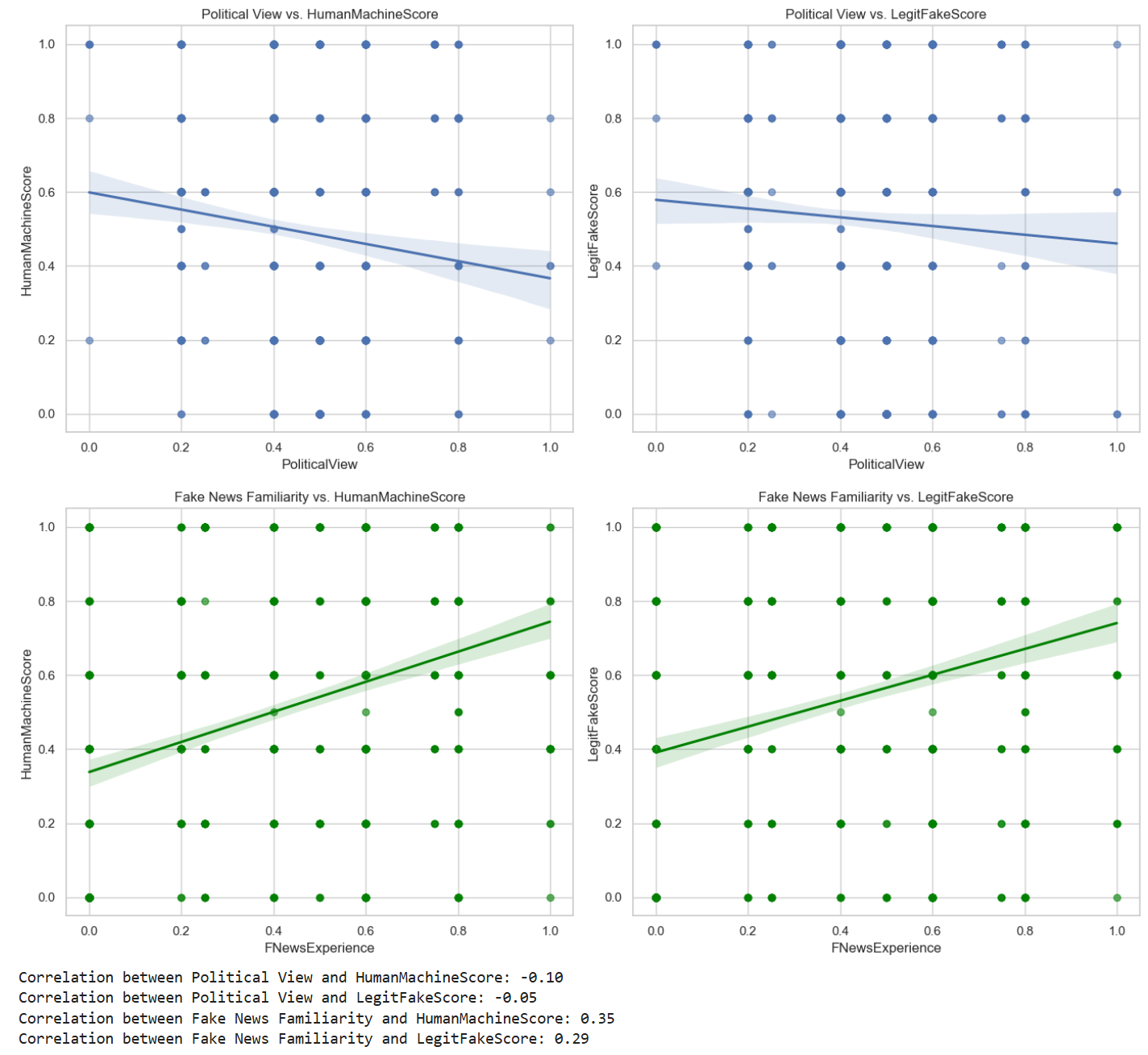
Figure 4: Regression analyses: political view (top) shows minimal effect; fake news familiarity (bottom) correlates with improved judgment accuracy.
User Personas: Skeptics vs. Believers
Clustering of individual-level mean scores uncovers the existence of two user archetypes: "Skeptics," who deploy a low-trust default across content, and "Believers," who are more trusting regardless of origin or authenticity. The separation is statistically robust (silhouette coefficient = .41), highlighting the heterogeneity in trust strategies and suggesting that single-mode intervention policies are insufficient.
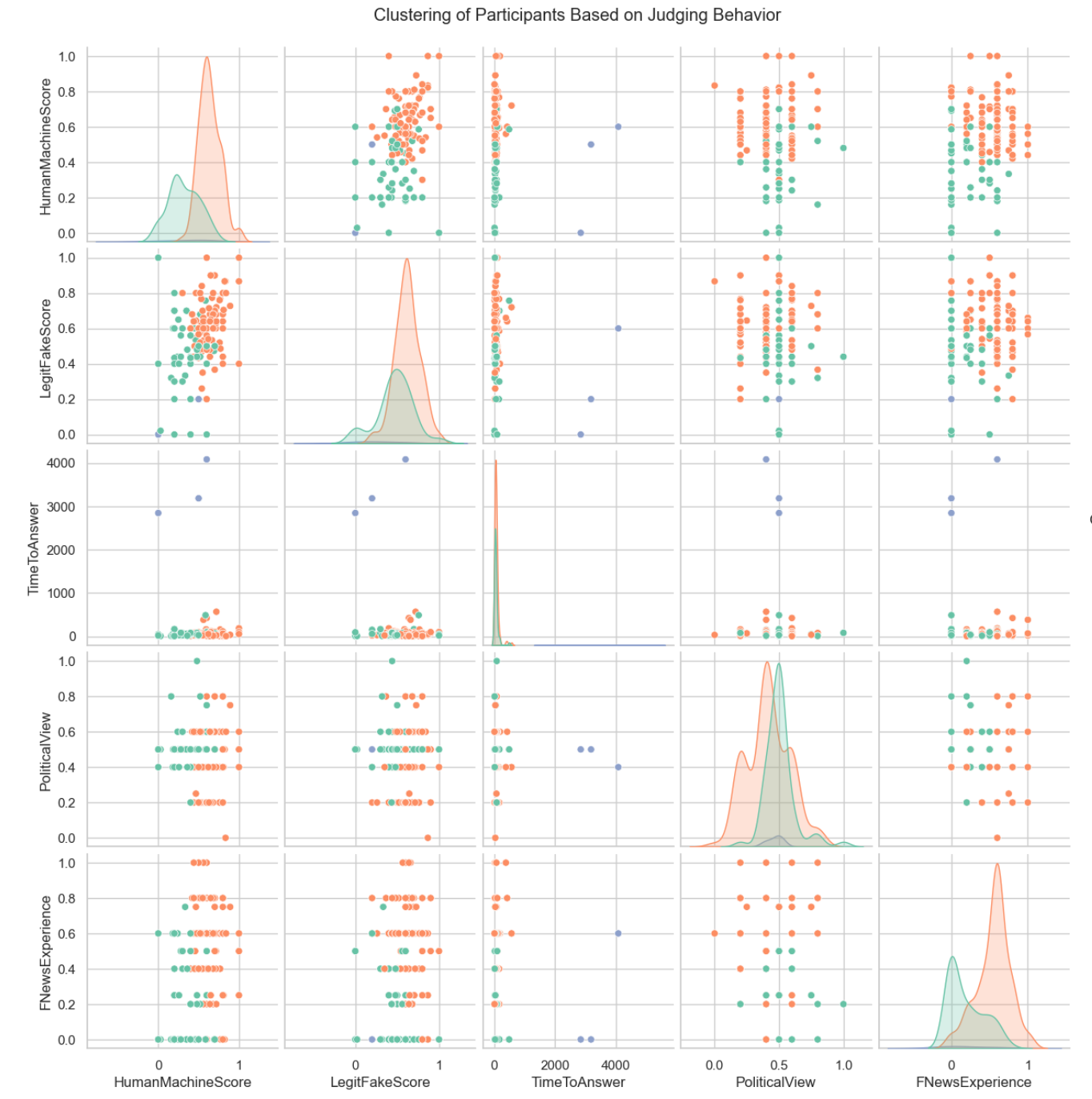
Figure 5: Participant-level mean scores exhibit clear bifurcation into Skeptic and Believer clusters.
Cognitive Fatigue in Sequential Evaluation
Temporal analysis reveals that accuracy improves over the initial 15–20 judgments due to possible learning or adaptation effects, but deteriorates sharply beyond approximately 30 items, attributed to cognitive fatigue. Participants increasingly default to labeling content as fake with prolonged exposure, suggesting significant limitations in the sustainability of attention-dependent user-facing detection paradigms.
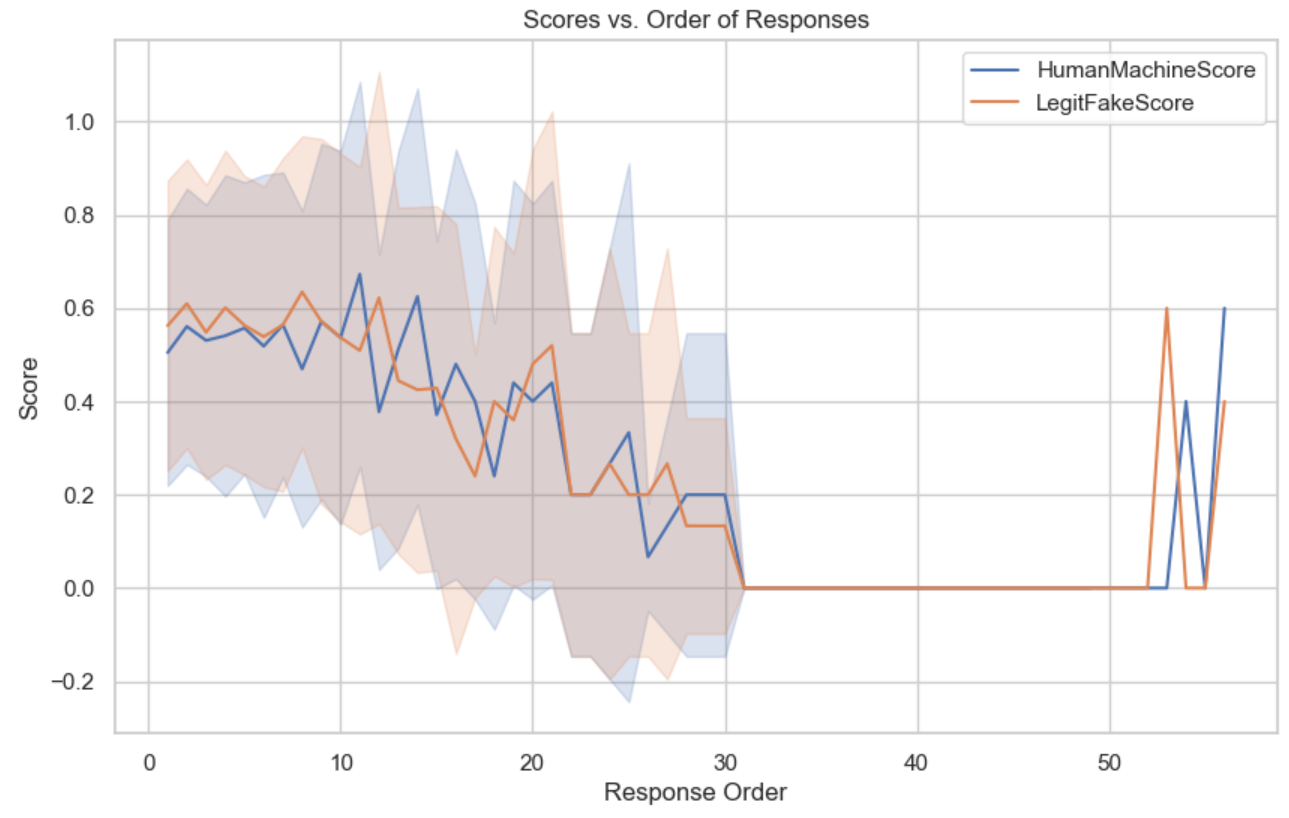
Figure 6: Rolling mean analysis shows an early improvement in scores followed by decline, reflecting learning and subsequent cognitive fatigue.
Practical and Theoretical Implications
The evidence decisively undermines the premise that user-level detection of synthetic news is viable at web scale. The rapid generalization of easily undetectable synthetic text across open and proprietary LLMs implies that adversaries do not require access to proprietary or large-scale models. The relatively greater efficacy of analytical skill development (vs. ideological orientation) implies some margin for educational interventions, but only within sharp practical limitations due to cognitive fatigue and baseline trust heterogeneity.
From a systems perspective, these findings focus attention on content provenance: cryptographic watermarking and provenance infrastructure (e.g., C2PA) become central to the defense against seamless information disorder. The user personas detected argue strongly for web trust indicator adaptivity, rather than single-threshold or uniform strategies.
The dual-axis methodology represents a formal advance, allowing disambiguation of authenticity perception from origin detection and supporting deeper diagnostic analysis of human factors in misinformation spread. Theoretical ramifications include formalizing the concept of an "Indistinguishability Threshold" as a point where LLM output becomes statistically undetectable by unaided human cognition.
Limitations and Directions for Future Work
While the methodology is robust, the demographic limitation (highly educated, European participants) constrains generalizability. The lack of real-world social context, limited range of veracity manipulation, and reliance on self-reported political orientation further delimit scope. Future research should expand to broader participant populations, employ longitudinal field trials (e.g., browser extension contexts), and balance the base rate of human vs. machine content to probe anchoring effects and base-rate adaptation.
Open research directions also include refinement of provenance signaling, more granular analysis of learning/fatigue trajectories, and the design of dynamic, persona-sensitive trust interventions.
Conclusion
Across 2,318 dual-axis human judgments of LLM-generated versus human-written news, the study establishes that humans are unable to reliably distinguish source or authenticity, regardless of model or scale. Analytical skill outperforms ideological orientation as a mediator of detection accuracy, with severe attrition from cognitive fatigue and highly individual trust strategies constraining the efficacy of user-level countermeasures. The results decisively recommend a shift to system-level defenses, notably cryptographic provenance and adaptive trust frameworks, and position dual-axis continuous assessment as a new standard for empirical research on human-AI text indistinguishability.
References
Loth, A., Kappes, M., Pahl, M.-O. (2026). Can Humans Tell? A Dual-Axis Study of Human Perception of LLM-Generated News. (2604.03755)
For further details regarding dataset accessibility and platform implementations, see the linked Zenodo repositories and open-source resources provided by the authors.

